Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
BigQueryで行う、 機械学習のための データ前処理
Search
hiroaki
December 18, 2019
Technology
2.7k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
BigQueryで行う、 機械学習のための データ前処理
hiroaki
December 18, 2019
More Decks by hiroaki
See All by hiroaki
機械学習を無理なく広告システムに導入する
hiroaki8388
2
6.4k
Pythonで、処理をより効率化するためのTips集
hiroaki8388
15
12k
Other Decks in Technology
See All in Technology
企業でAWS Organizationsを動かすための組織設計の考え方
nrinetcom
PRO
1
110
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
穢れた技術選定について
watany
17
5.4k
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
1
360
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
2
300
Type-safe IaC for Dart
coborinai
0
160
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
190
Network Firewallやっていき!
news_it_enj
0
170
AI時代の闇と光
tatsuya1970
0
110
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
130
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
390
DatabricksにおけるMCPソリューション
taka_aki
1
270
Featured
See All Featured
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
Un-Boring Meetings
codingconduct
0
350
Fireside Chat
paigeccino
42
4k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
YesSQL, Process and Tooling at Scale
rocio
174
15k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Typedesign – Prime Four
hannesfritz
42
3.1k
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Discover your Explorer Soul
emna__ayadi
2
1.2k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
300
Transcript
BigQueryで行う、 機械学習のための データ前処理 GCPUG Tokyo December 2019 長谷川大耀 (Fringe81)
自己紹介 長谷川大耀(@Hase8388) で 機械学習の開発やってます
BigQueryで機械学習が行えると何が嬉しい? • 大量のデータから、安く簡単にデータセットを構築できる • SQLで処理ができるので、誰でも簡単に実行可能 • BQMLで構築したモデルにシームレスにデータを流し込める 今回話すこと さらによりよいモデルを作るために、 BQ(ML)での前処理を行うための方法の紹介
話さないこと アルゴリズムの話など、モデル自体の仕組みの話
機械学習では、前処理がなぜ重要? 解くべきタスクの本質を、 より明らかな形として表現するデータに加工することで、 モデルの性能を更に引き出すことができる 1. 概観の把握 2. 特徴量の作成、変換 3. モデルにデータセットを流し込む
それぞれのフェイズで 代表的な関数+自分が好きな関数を紹介します
1. データの概観するための関数 • 分布の概観把握なども簡単にできる • 基本的な統計集約関数
より複雑な分析や可視化はJupyterで Jupyter上でBQの出力結果を DataFrameとして格納し、pandas/matplotlibなどで分析 google-cloud-bigqueryでJupyter上から接続 https://googleapis.dev/python/bigquery/latest/magics.html#module-google.cloud.bigquery.magics 誤ったクエリでの重課金を 防ぐために、課金される容量に 上限もつけれる
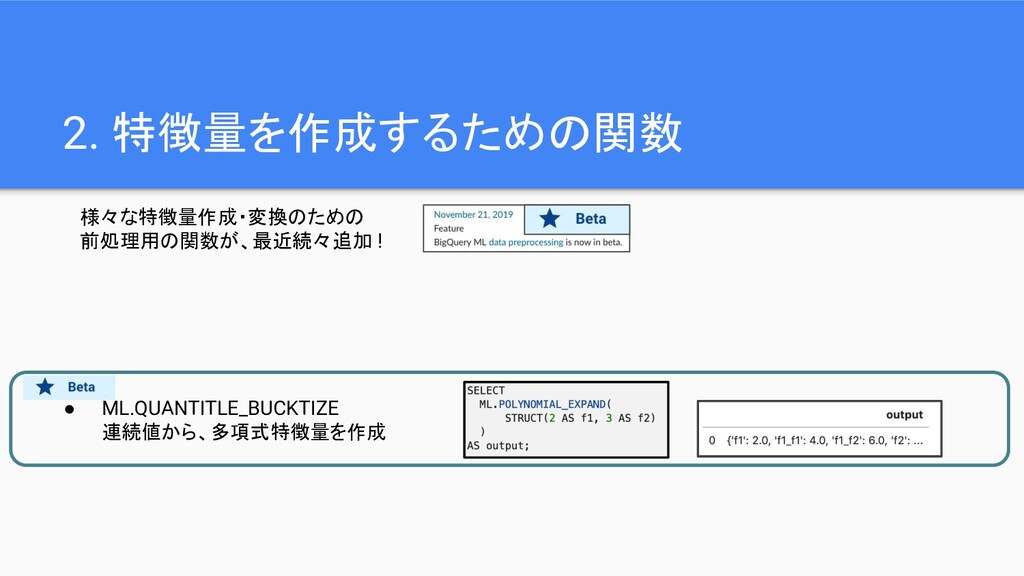
2. 特徴量を作成するための関数 様々な特徴量作成・変換のための 前処理用の関数が、最近続々追加 ! • ML.QUANTITLE_BUCKTIZE 連続値から、多項式特徴量を作成
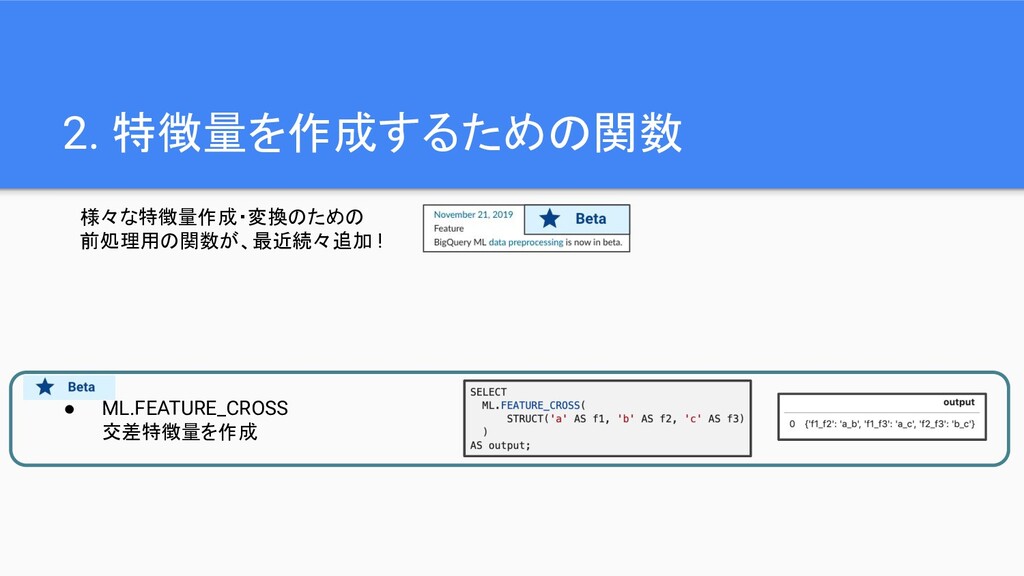
2. 特徴量を作成するための関数 様々な特徴量作成・変換のための 前処理用の関数が、最近続々追加 ! • ML.FEATURE_CROSS 交差特徴量を作成
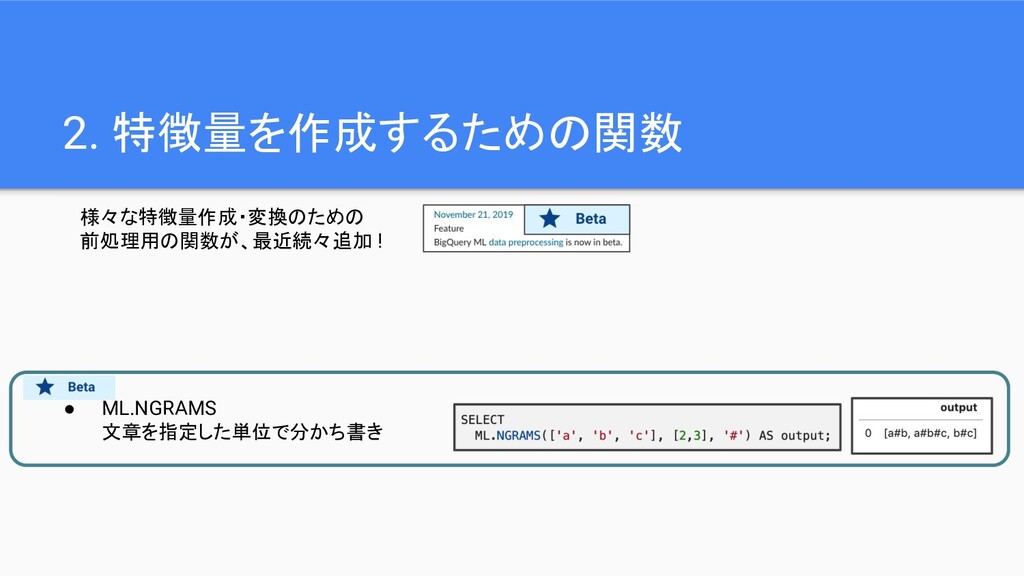
2. 特徴量を作成するための関数 様々な特徴量作成・変換のための 前処理用の関数が、最近続々追加 ! • ML.NGRAMS 文章を指定した単位で分かち書き
3. 特徴量を変換するための関数 特徴量の変換も、 短いクエリで簡単に実行可能 ! • IF 二値化
3. 特徴量を変換するための関数 特徴量の変換も、 短いクエリで簡単に実行可能 ! • ML.QUANTITLE_BUCKTIZE 連続値を指定した数の binに振り分ける
3. 特徴量を変換するための関数 特徴量の変換も、 短いクエリで簡単に実行可能 ! • ML.MIN_MAX_SCALER • ML.STANDARD_SCALER 正規化、標準化
ex. 地理情報をHash化する: ST_GEOHASH 地理情報をカテゴリとして扱うために Hash化するなら、ST_STGEOHASHが便利 ! Hash値を長くすればするほど、 より詳細な位置情報を表現できる
3. 前処理したデータをモデルに流し込む 課題: BQMLで作成したモデルにデータセットを流し込む その時、学習、予測、評価で、イチイチ同じ前処理を行うのはシンドい 学習 データ 前処理 評価 データ
前処理 予測 データ 前処理 モデル モデルを使う人が前処理のロジックを 知っている必要がある。つらい 学習時 予測時 重複!
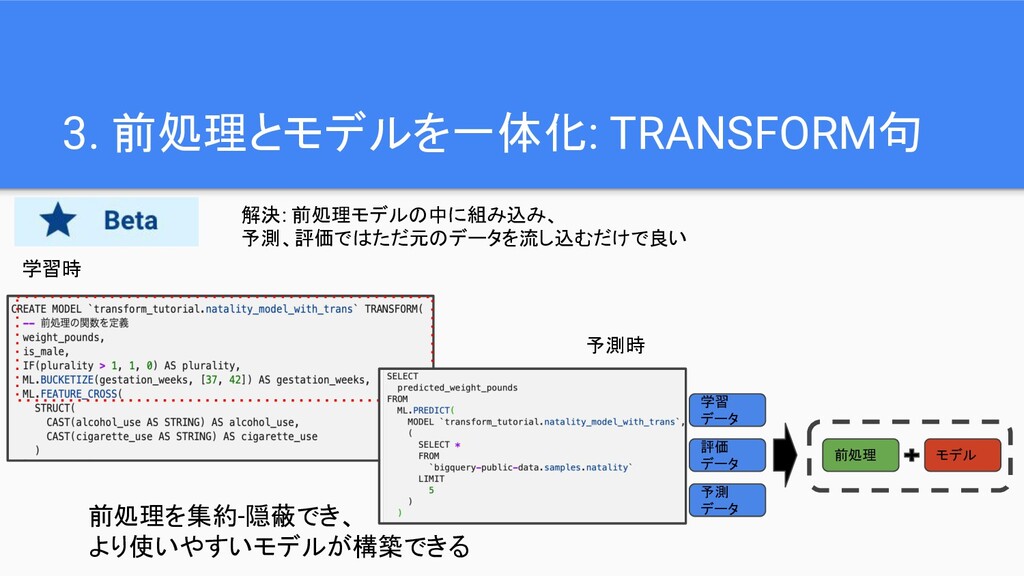
3. 前処理とモデルを一体化: TRANSFORM句 前処理を集約-隠蔽でき、 より使いやすいモデルが構築できる 学習 データ 評価 データ 前処理
予測 データ モデル 解決: 前処理モデルの中に組み込み、 予測、評価ではただ元のデータを流し込むだけで良い 学習時 予測時
最後に BigQuery(ML)を使うと、SQLだけで簡単に前処理とモデル構築が行える 新しい関数とアルゴリズムがどんどん追加されているので、今後がより楽しみ
エンジニアを積極採用中です ! Front-end Back-end Scala / Go Python JS /
Elm React / RN
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}