Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
機械学習を無理なく広告システムに導入する
Search
hiroaki
February 05, 2020
Technology
6.4k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
機械学習を無理なく広告システムに導入する
https://m3-engineer.connpass.com/event/159721/
の登壇資料
hiroaki
February 05, 2020
More Decks by hiroaki
See All by hiroaki
BigQueryで行う、 機械学習のための データ前処理
hiroaki8388
4
2.7k
Pythonで、処理をより効率化するためのTips集
hiroaki8388
15
12k
Other Decks in Technology
See All in Technology
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
0
210
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
240
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
450
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
3.2k
世界、断片、モデル。そして理解
ardbeg1958
1
130
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.7k
ガバナンスの「ちょうどいい落とし所」を探れ!開発スピードを妨げない運用判断の勘所 / SRE NEXT 2026
genda
1
260
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
2
4k
「早く出す」より「事業に効く」 ── 顧客の業務サイクルから逆算するAI時代の二重ループ開発と「変化の設計者」 / devsumi2026
rakus_dev
1
410
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
120
DMM.com 購入改善推進チーム におけるCodeRabbitを用いた レビューフロー改善の一例
ysknsid25
2
670
Featured
See All Featured
Are puppies a ranking factor?
jonoalderson
1
3.7k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Bash Introduction
62gerente
615
220k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Facilitating Awesome Meetings
lara
57
7k
Being A Developer After 40
akosma
91
590k
Transcript
機械学習を 無理なく広告システム に導⼊する MLOps勉強会 Fringe81 ⻑⾕川⼤耀
⾃⼰紹介 ⻑⾕川⼤耀(@Hase8388) で、機械学習の開発やってます 物理学(⼤腸菌)=> 広告配信(Scala)=> 広告配信(ML)
広告配信のビジネスモデル • ユーザー情報を元に、興味がありそうな広告を配信する • お⾦が⼊ってくるのは、広告をclickしたときなので、 よりユーザーが興味がある広告を優先的に表⽰すれば、それだけ 利益に繋がる
• ユーザー情報を元に、興味がありそうな広告を配信する • お⾦が⼊ってくるのは、広告をclickしたときなので、 よりユーザーが興味がある広告を優先的に表⽰すれば、それだけ 利益に繋がる 広告配信のビジネスモデル 機械学習でclickする確率(CTR)をより正確に予測すれば 売上に貢献しうる
もっと単純なロジックでも良いのでは? 機械学習にすることでメリットは⾮常に多い • メディアなどの傾向が変わってもすぐに柔軟に対応できる • 多くの情報(特徴量)を、より柔軟に予測に活⽤できる • 特徴量やパラメータなど、改善できる⾃由度が増える
今⽇話すこと 話さないこと • アルゴリズムのガッツリとした話 • 特定のライブラリ、フレームワークの話 など 機械学習を広告配信システム 上で安定的に動かすための 実装、運⽤⽅法
その上で機械学習システムを 確実に運⽤と改善を ⾏っていくための⼯夫
None
広告配信は、ビジネス上の制約も多い 配信側で、モデルを復元/予測を⾏う必要が あるため、配信側(アプリケーション側)のエンジニアと 密な連携が不可⽋ 配信側の開発を⾏うエンジニアと、 どのように齟齬なく、開発をおこなうか? 20ms以内に、最適な広告を決定 し、返却する必要がある
1. チーム間で開発前に認識合わせを⾏う • 懸念されるリスクを整理し、対策を考える • 正常/異常のパターンを洗い出し、どちら側で対応するかを決める • ex モデルのメトリクスがおかしい場合、ML側で更新を停⽌します •
配信側でできること/できないことの整理 • 仕様に落とし⽳がないかをチェック • ex xxGBまでは配信のメモリに乗せれるけど、それ以上だと厳しいです • それぞれチームでの⽤語についての認識を合わせる • ⼀番重要! 意味がズレると予測も当然ズレる • ex この数値、パーセンテージで表してるんじゃないの!?
特に、ログに落とせる(せない)モノを確認 ML側でテストと検証を⾏いやすいように、 ログの仕様については予めシステム側のエンジニアと協議 • A/Bテストや、性能確認のために、必ず落としたい値 • 配信パフォーマンスや設計上、どうしてもムリな値 • メトリクス観点で、ロジックid, 予測値、clickしたか、落札額など
• テスト観点で、1000回に⼀回だけ、重み値、特徴量の種類、など 出⼒するログは、
2. それぞれの実装を相互レビュー • 配信側にMLがわかるエンジニア、ML側に配信サーバー がわかるエンジニア(私)がいたので相互レビュー • 詳細に確認したのは、 • 配信側エンジニア: 読み込む重みファイルのフォーマット
• ML側エンジニア: 予測計算の式と、ログのフォーマット 向こう側の、ここがズレてると死ぬ! という観点をお互い認識して、確認し合う
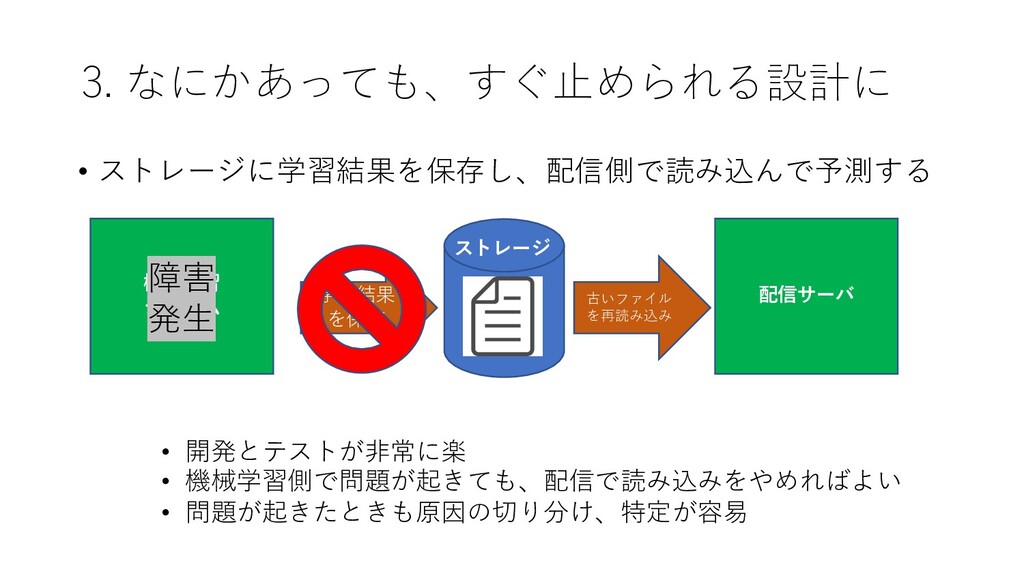
3. なにかあっても、すぐ⽌められる設計に • ストレージに学習結果を保存し、配信側で読み込んで予測する 機械学習 システム ストレージ • 開発とテストが⾮常に楽 •
機械学習側で問題が起きても、配信で読み込みをやめればよい • 問題が起きたときも原因の切り分け、特定が容易 学習結果 を保存 配信サーバ 読み込み
3. なにかあっても、すぐ⽌められる設計に • ストレージに学習結果を保存し、配信側で読み込んで予測する 機械学習 システム • 開発とテストが⾮常に楽 • 機械学習側で問題が起きても、配信で読み込みをやめればよい
• 問題が起きたときも原因の切り分け、特定が容易 配信サーバ 古いファイル を再読み込み 学習結果 を保存 障害 発⽣ ストレージ
さらに配信側の負荷をより減らすために モデルを復元するための、 重み値をすべて配信サーバーのメモリで持つ必要がある 巨⼤なファイルだとGCが⾛って、配信の処理が⽌まる そのため、精度を担保しつつ、 重みファイルの容量をなるべく⼩さくする必要がある
• カテゴリの数が⼤きい特徴量は使わない • モデルを数週間に⼀回、洗い替え • もう使われなくなったCreativeなどの重み値を削除する • ファイルの容量が閾値異常なら、エラーを吐く • (やらなかったけど)L1正則化で、影響が⼩さいカテゴリは消す
さらに配信側の負荷をより減らすために
4. あと細々したコード上の⼯夫とか • 塵も積もればの精神で諸々⼯夫 • メモリの最適化、処理の効率化などなど • このあたりは、別のタイミングで発表したので、もしご興味あれば https://speakerdeck.com/hiroaki838 8/pythonde-chu-li-woyorixiao-lu-
hua-surutamefalsetipsji
機械学習システムとして、⾏いたい仕様 学習: ⼤量のログから、短時間で効率的な学習⽅法 改善: なるべくコードに⼿を⼊れず、簡単に本番にデプロイ
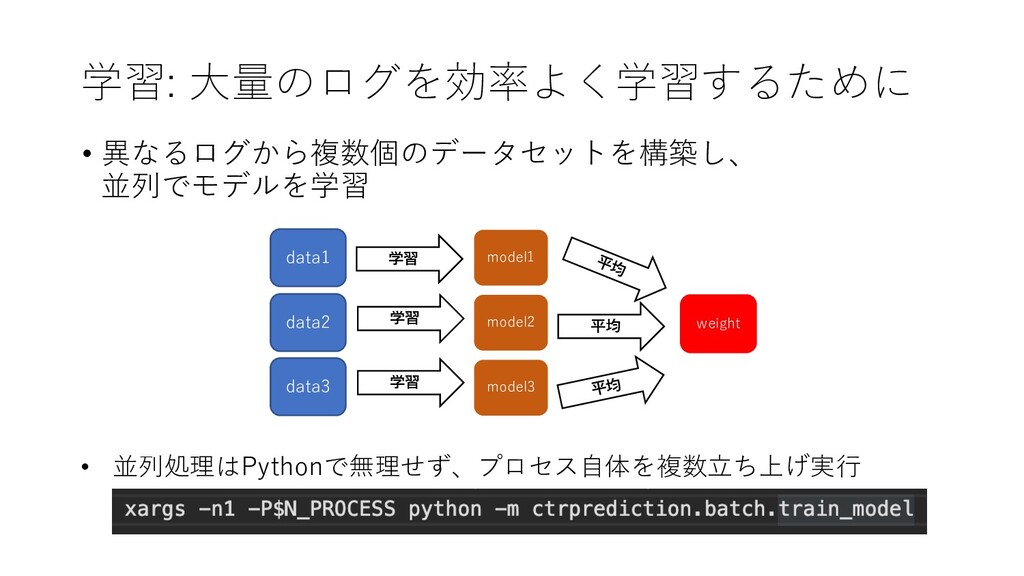
学習: ⼤量のログを効率よく学習するために • 異なるログから複数個のデータセットを構築し、 並列でモデルを学習 • 並列処理はPythonで無理せず、プロセス⾃体を複数⽴ち上げ実⾏ data1 model1 model3
data2 data3 model2 学習 学習 学習 weight 平均 平均 平均
改善: AWS Cloud Foramtion + Step Functions で素早くデプロイ • Cloud
Formationを利⽤し、⼀発で環境構築、更新 • インスタンスタイプなどの、実⾏環境を容易に変更可能 • Step Functionsで、job flowを定義 • 処理がどこまで実⾏されているかがConsole上から確認できる
おわりに • 広告配信のように 、MLとシステムが密になるなら、 • 設計段階から配信側と連携 • ここが⾷い違っているとヤバいポイントを予めお互い把握 • テストや責任範囲も明確にしておくとリリース後もスムーズ
• 機械学習モジュール⾃体は、 • ⼤量のログを効率的に(スケーラブルに)さばけるように⼯夫 • リリース後、なにか起きることを前提に、容易に修正できる設計
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}