障害発生から検知までの時 間 MTTI Mean Time To Identify 検知から原因特定までの時 間 MTTA Mean Time To Act 原因特定から対処開始まで の時間 MTTR Mean Time To Recover 対処開始から復旧完了まで の時間 障害発生 復旧完了 MTTR(復旧時間)= MTTD + MTTI + MTTA + 復旧作業 MTTR が長い原因は「復旧が遅い」とは限らない。検知が遅いのか、特定に時間がかかったのかを分解して初めて正しい改善策が見える。 次のスライドでは、今回のインシデントを各フェーズに分解して振り返る。 MTTD / MTTI / MTTA / MTTR とは
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
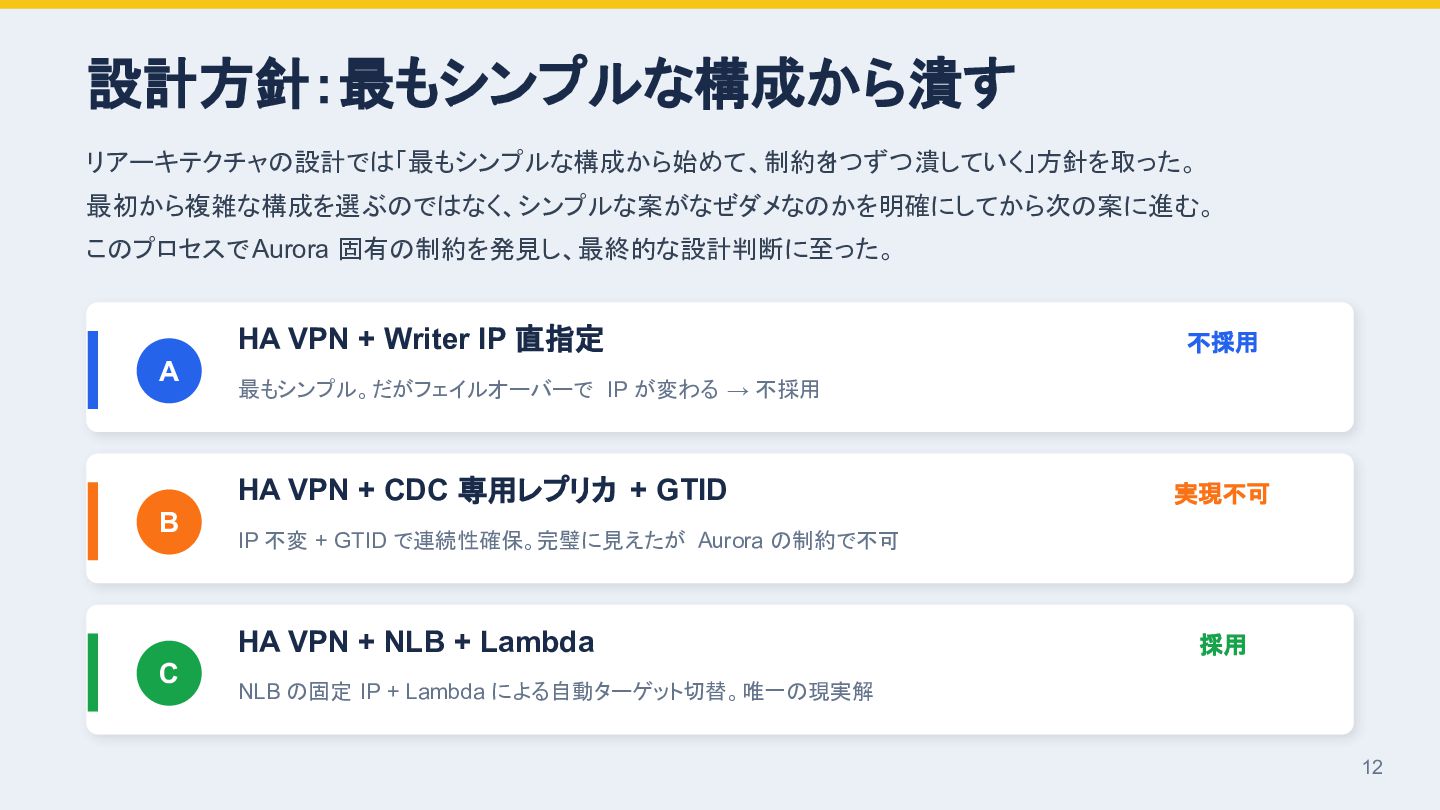{kind=link}
{kind=link}
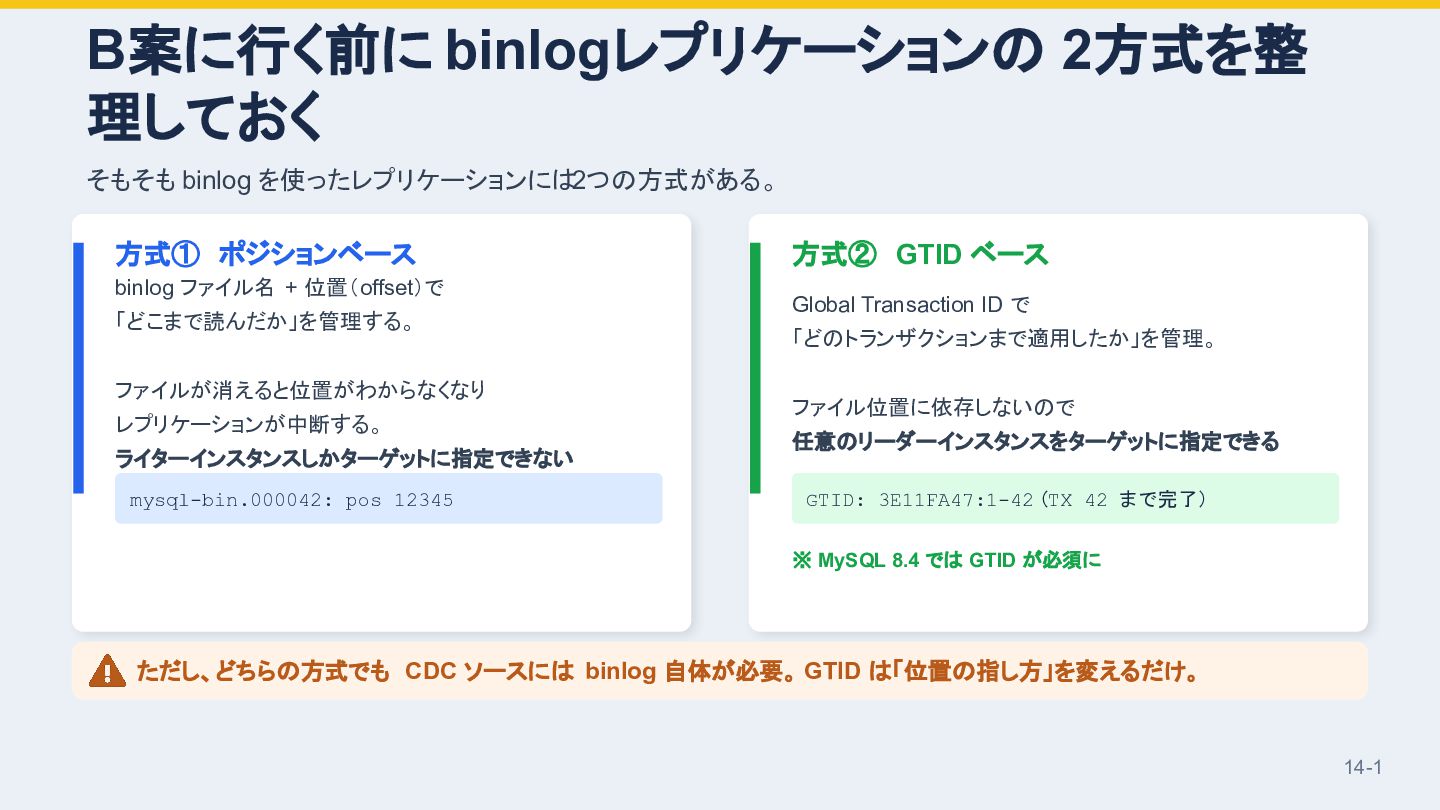{kind=link}
{kind=link}
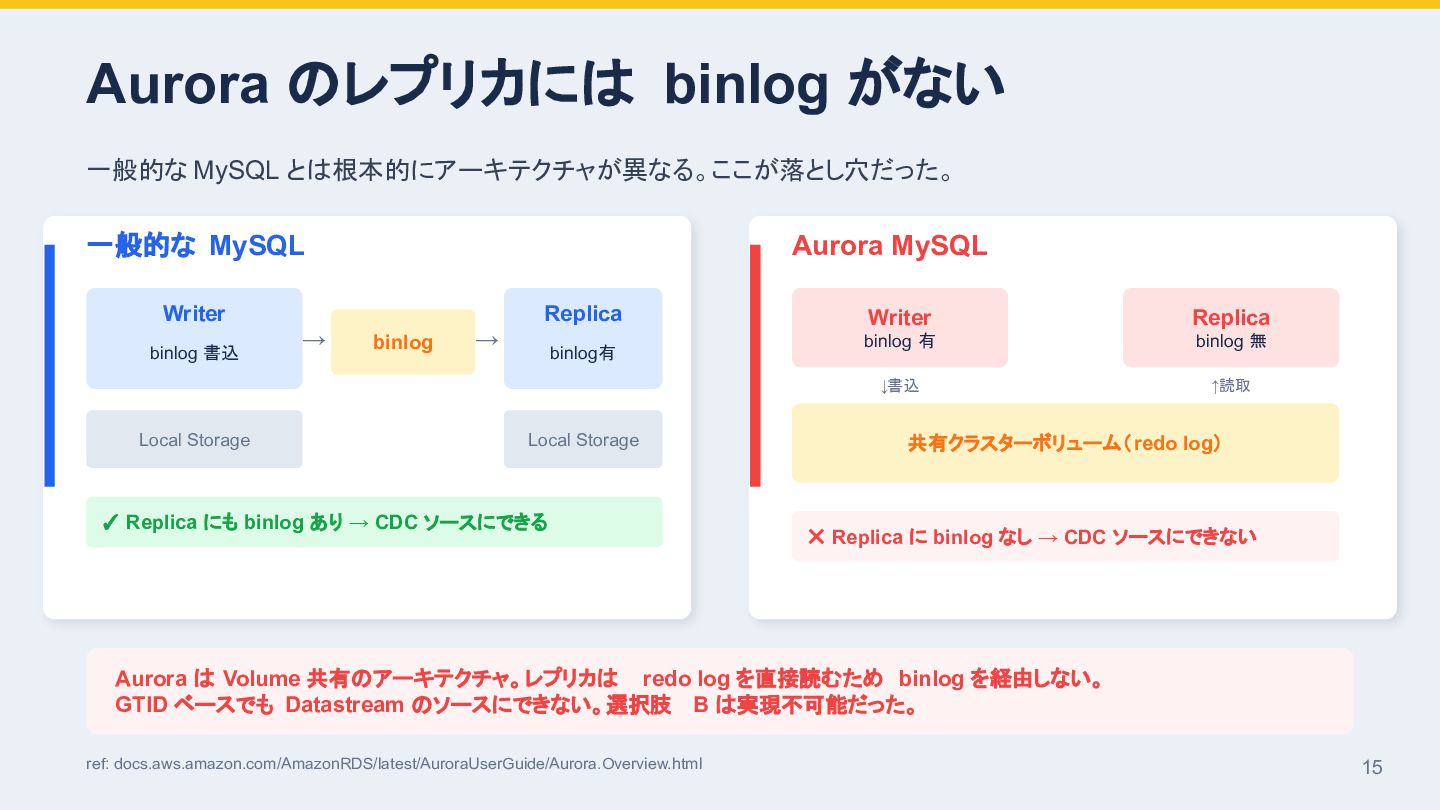{kind=link}
{kind=link}
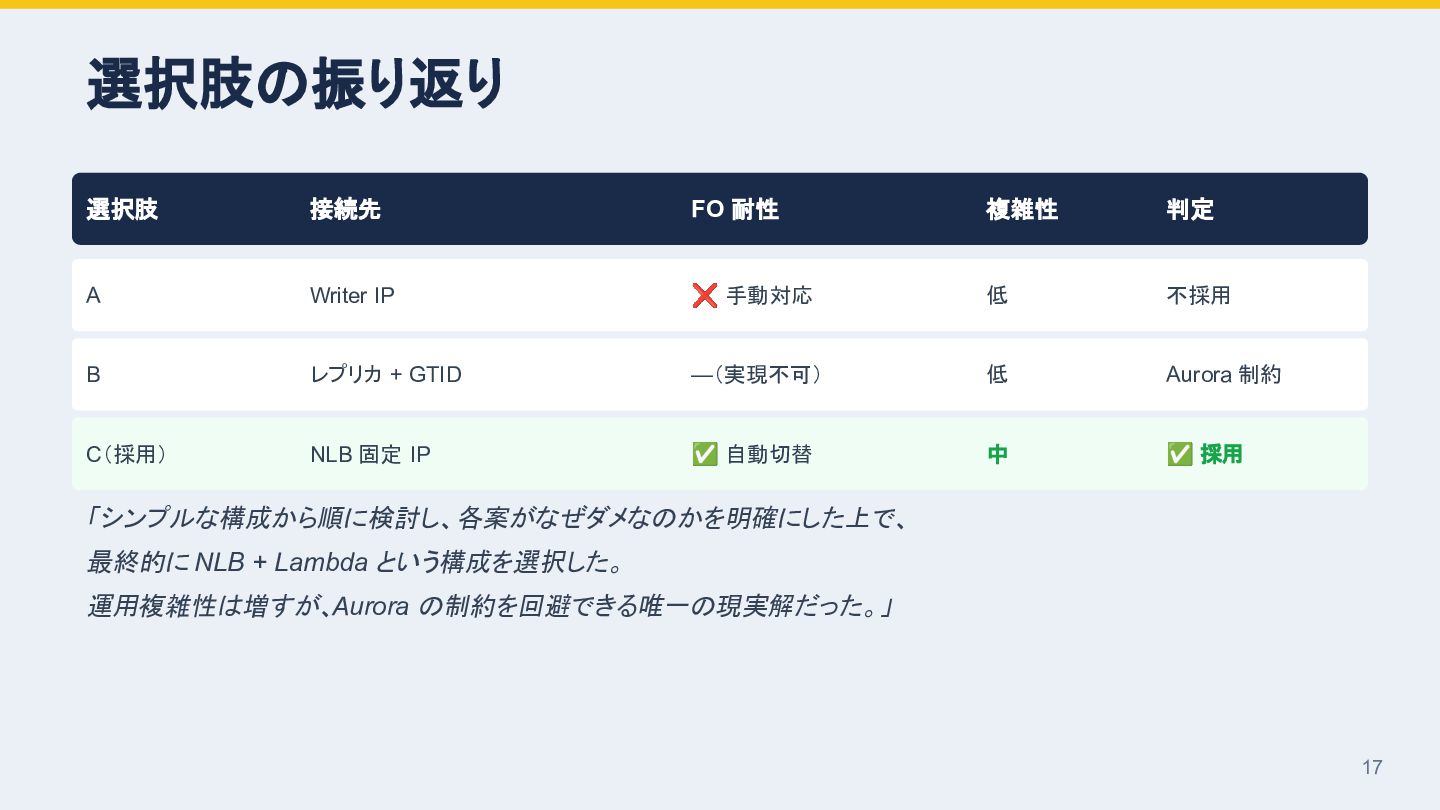{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}