ガウス過程による回帰 (GPR) とは?
GPRを理解するための大まかな流れ
説明に入る前に:GPRがとっつきにくい理由
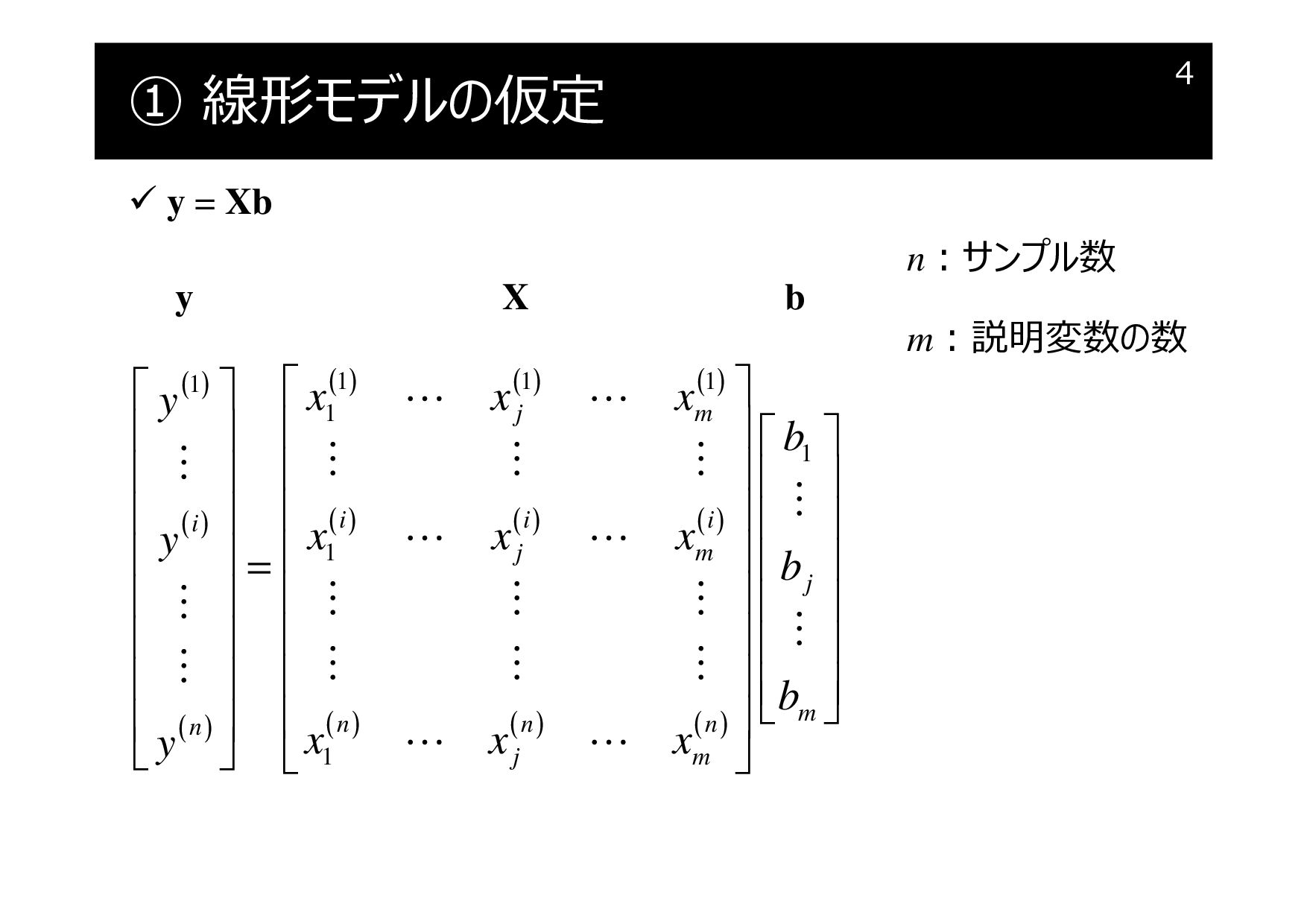
① 線形モデルの仮定
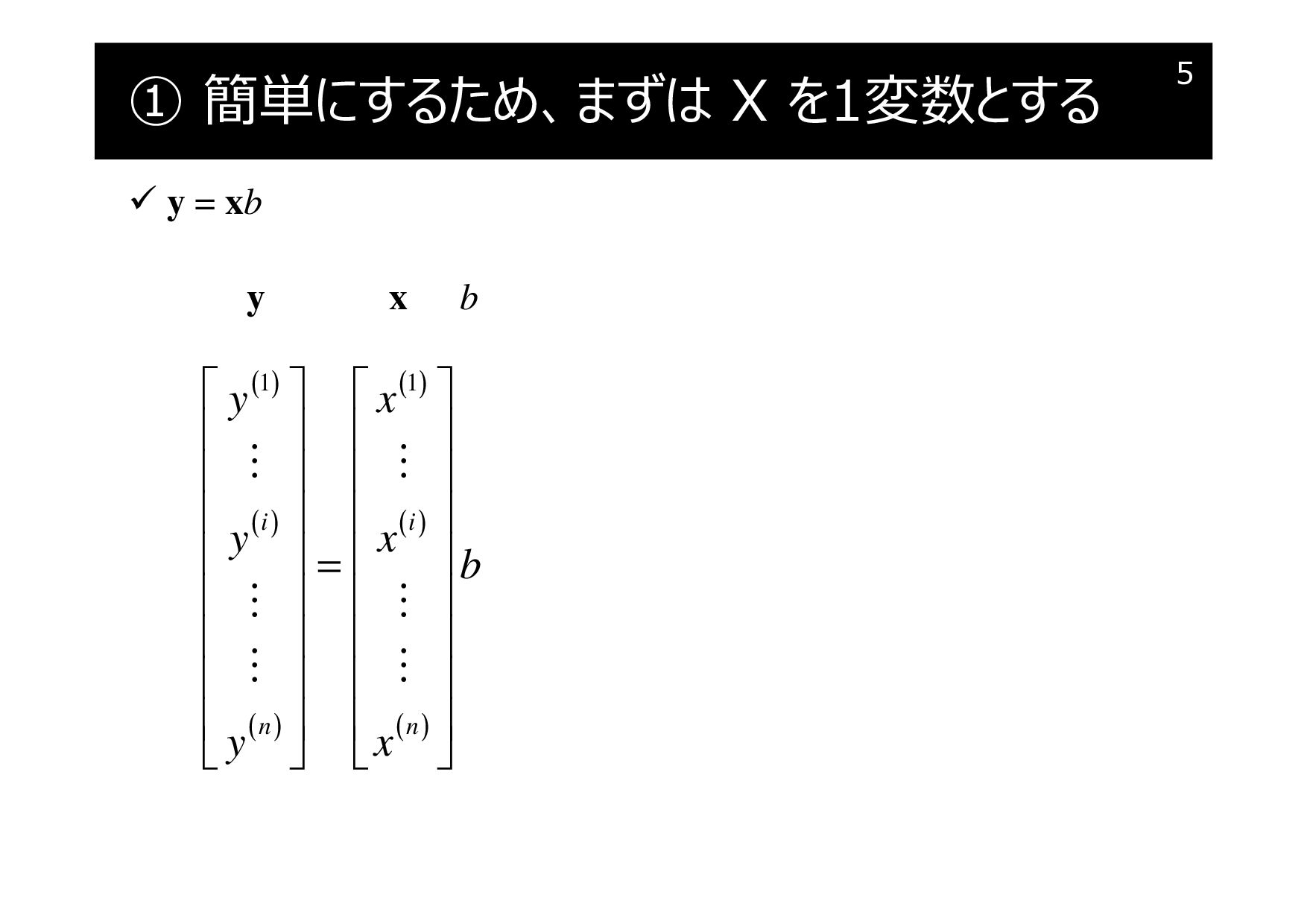
① 簡単にするため、まずは X を1変数とする
② 回帰係数が正規分布に従うと仮定
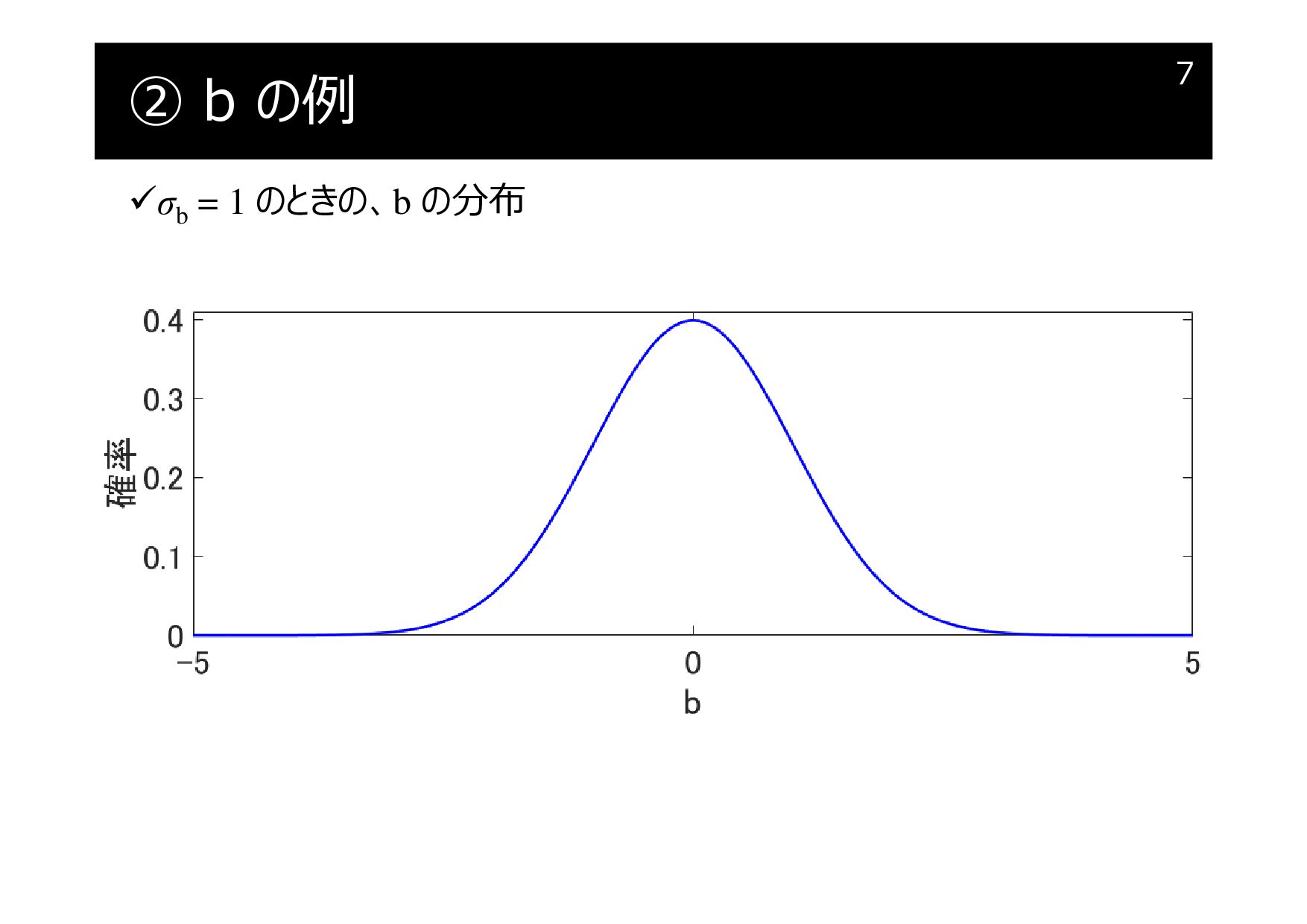
② b の例
② サンプル間の y の関係を考える
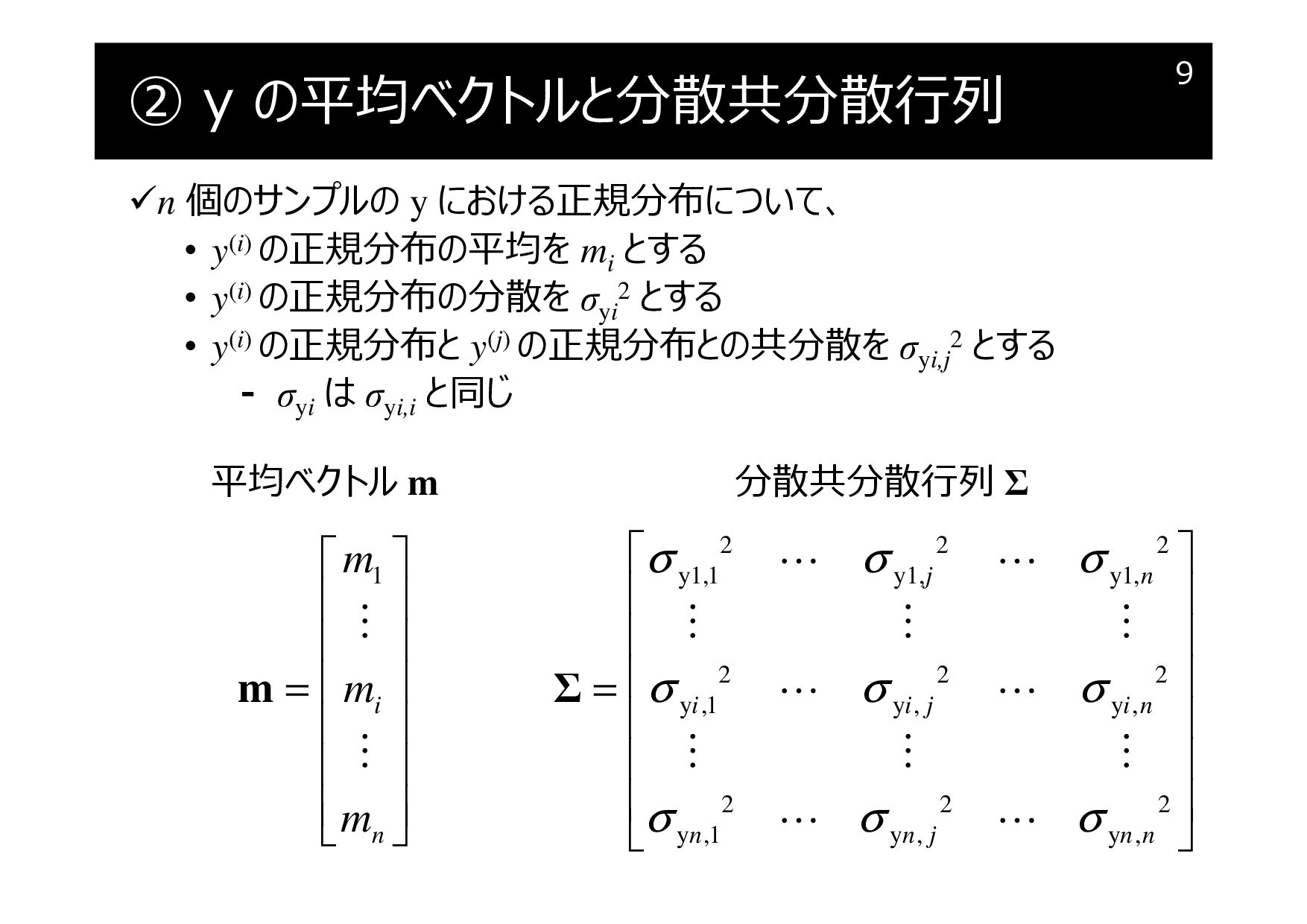
② y の平均ベクトルと分散共分散行列
② 平均ベクトルと分散共分散行列の計算
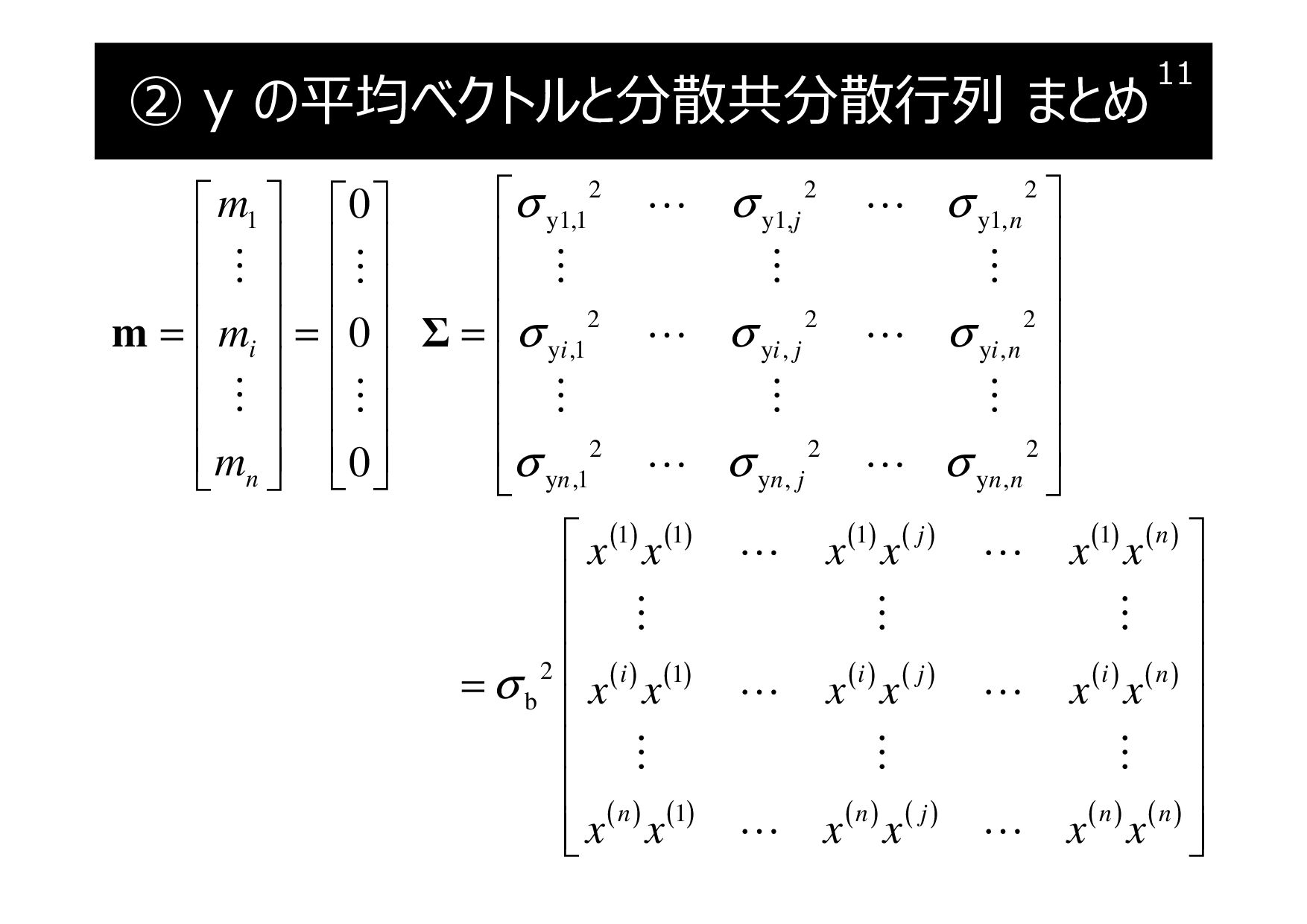
② y の平均ベクトルと分散共分散行列 まとめ
② 何を意味するか?
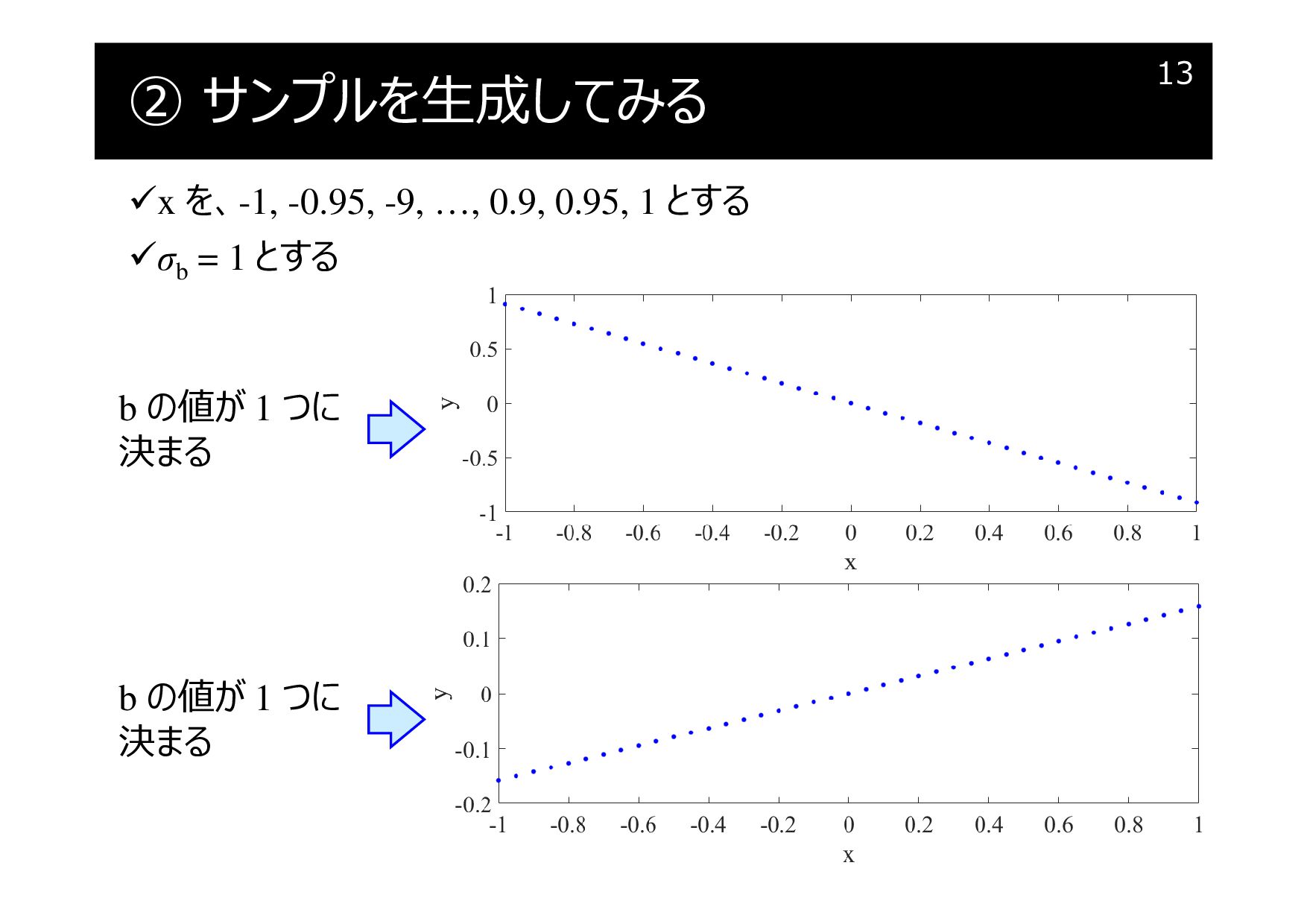
② サンプルを生成してみる
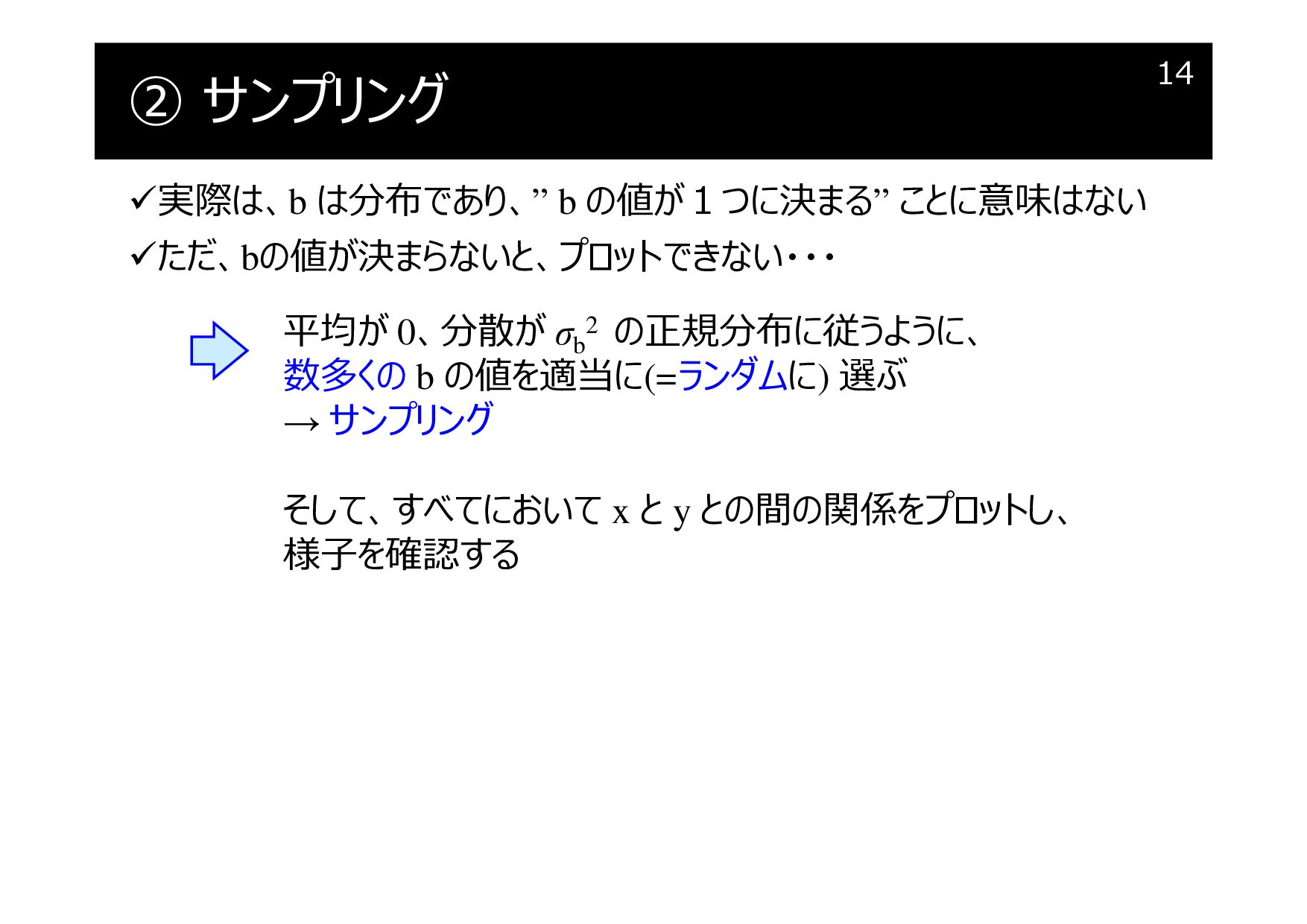
② サンプリング
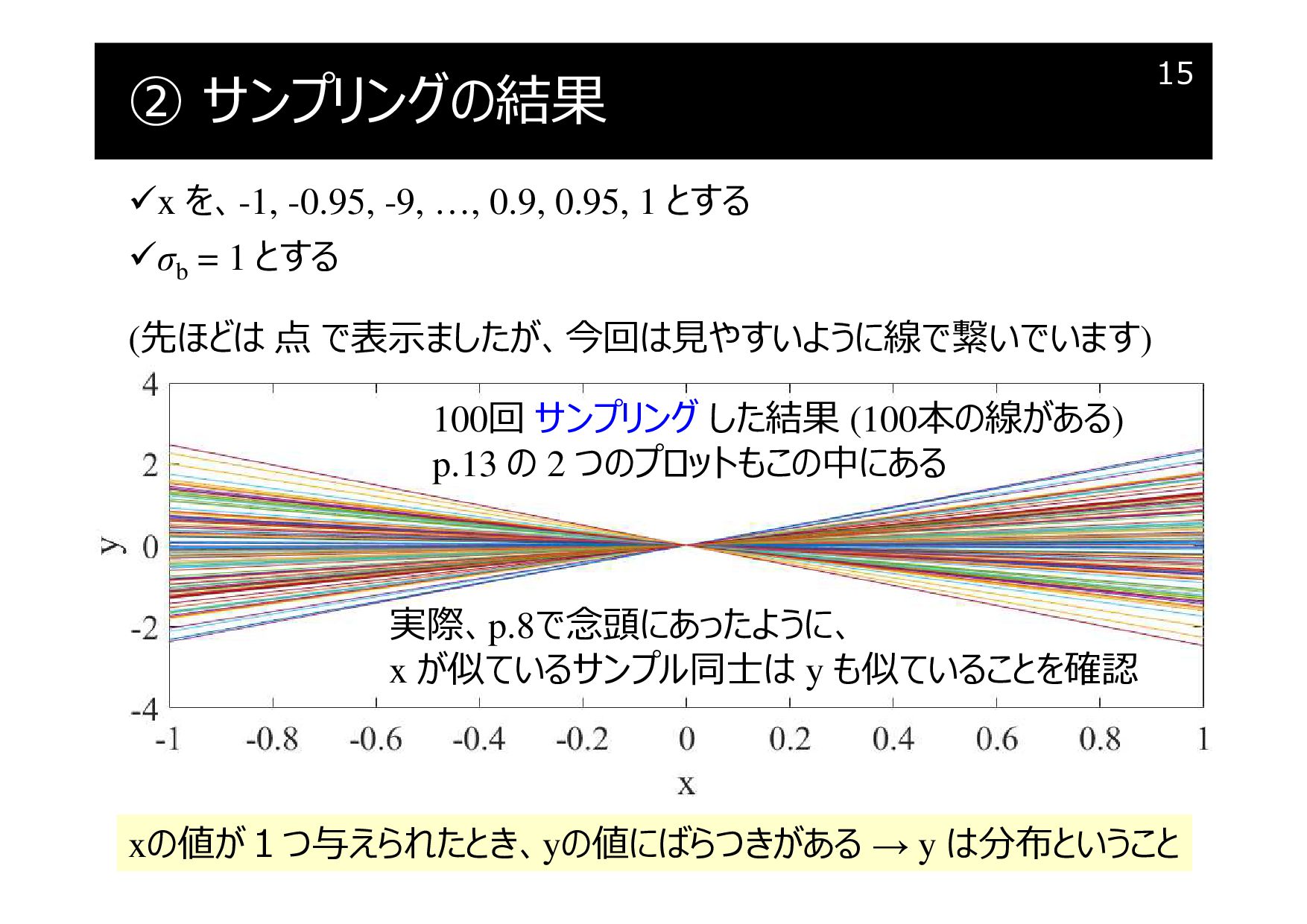
② サンプリングの結果
② 説明変数の数を複数に
② yの平均ベクトルと分散共分散行列の計算
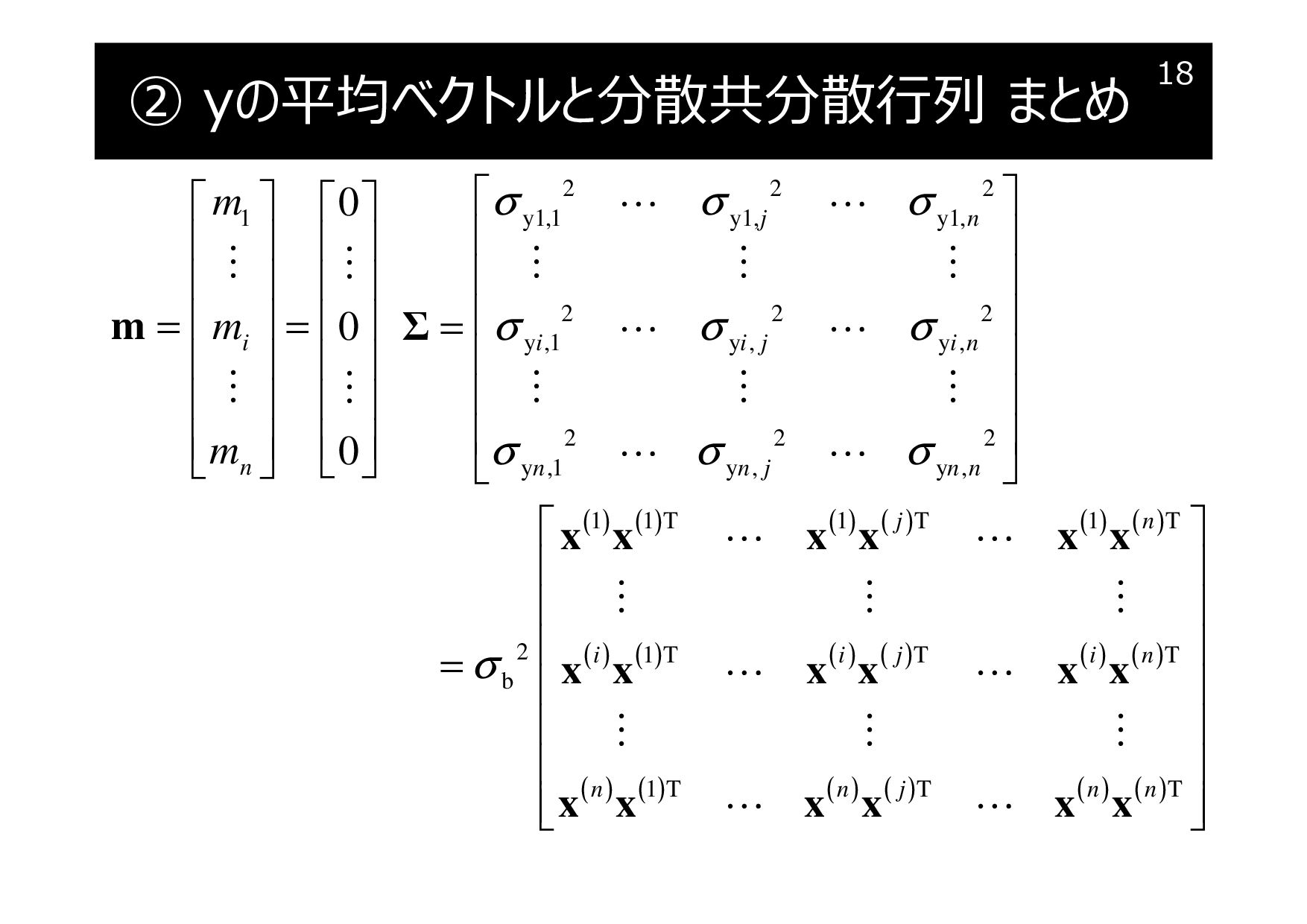
② yの平均ベクトルと分散共分散行列 まとめ
③ 非線形モデルへの拡張
③ カーネルトリック
③ カーネル関数の例
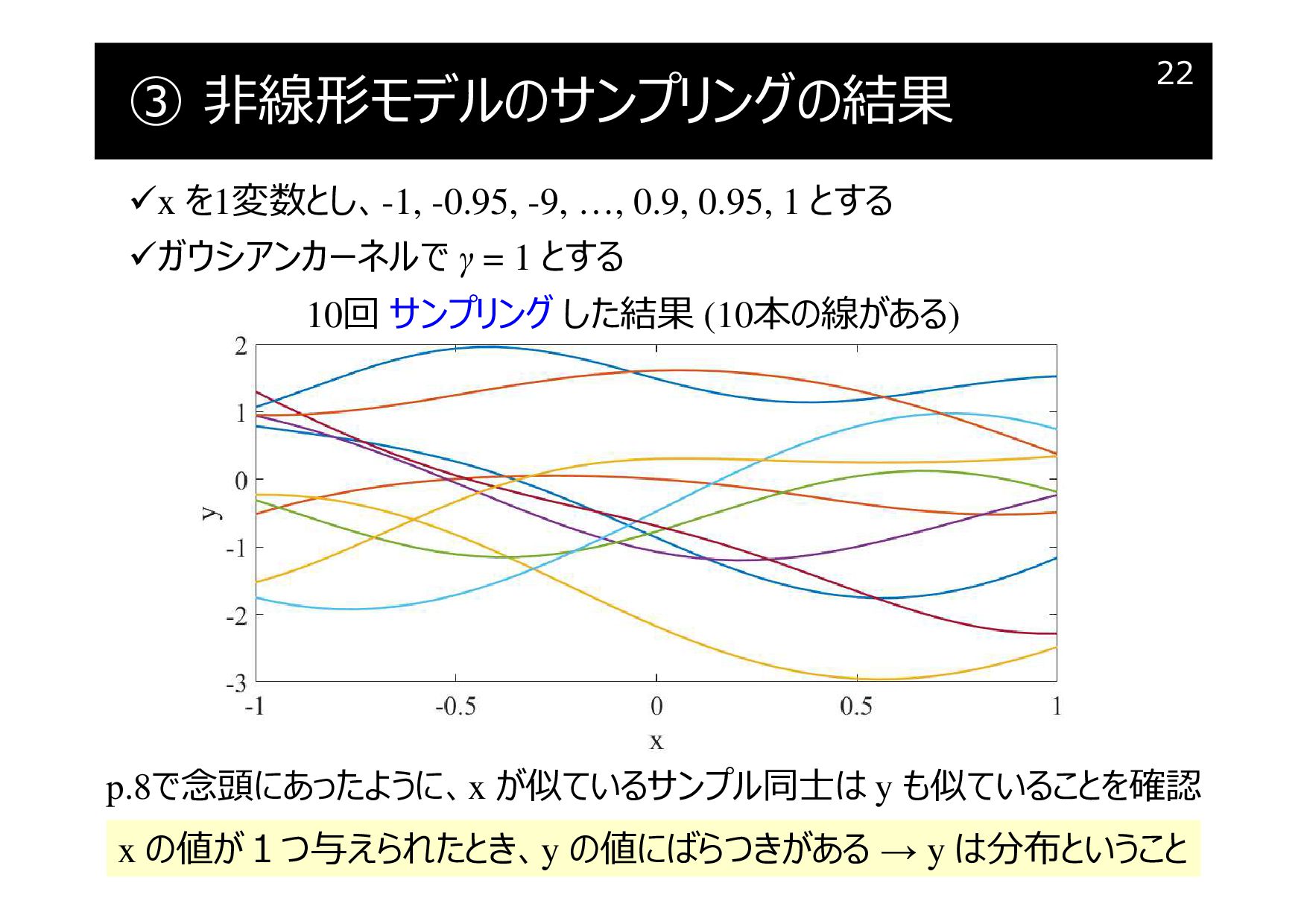
③ 非線形モデルのサンプリングの結果
④ y に測定誤差を仮定
④ yobsの平均ベクトル
④ yobsの分散共分散行列
④ yobsの分散共分散行列 まとめ
④ GPRのカーネル関数の特徴
④ GPRで使われるカーネル関数の例
④ GPRで使われるカーネル関数の例
④ GPRで使われるカーネル関数の例
⑤ 問題設定
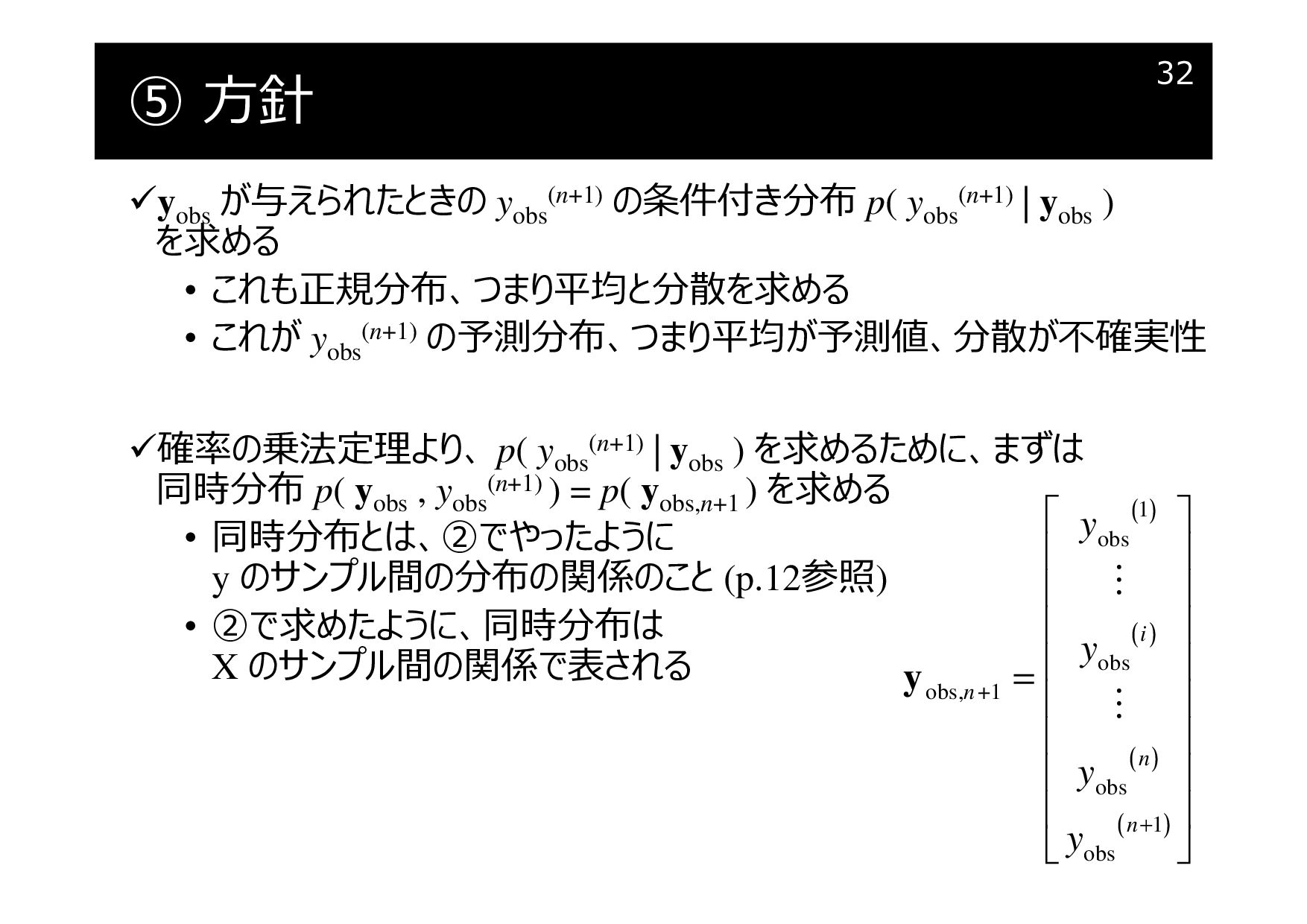
⑤ 方針
⑤ 方針 まとめ
⑤ 用いる関係式
⑤ 同時分布 p( yobs,n+1 )
⑤ 条件付き分布 p( yobs(n+1) | yobs )
GPRの使い方
精度 β
GPRの数値例
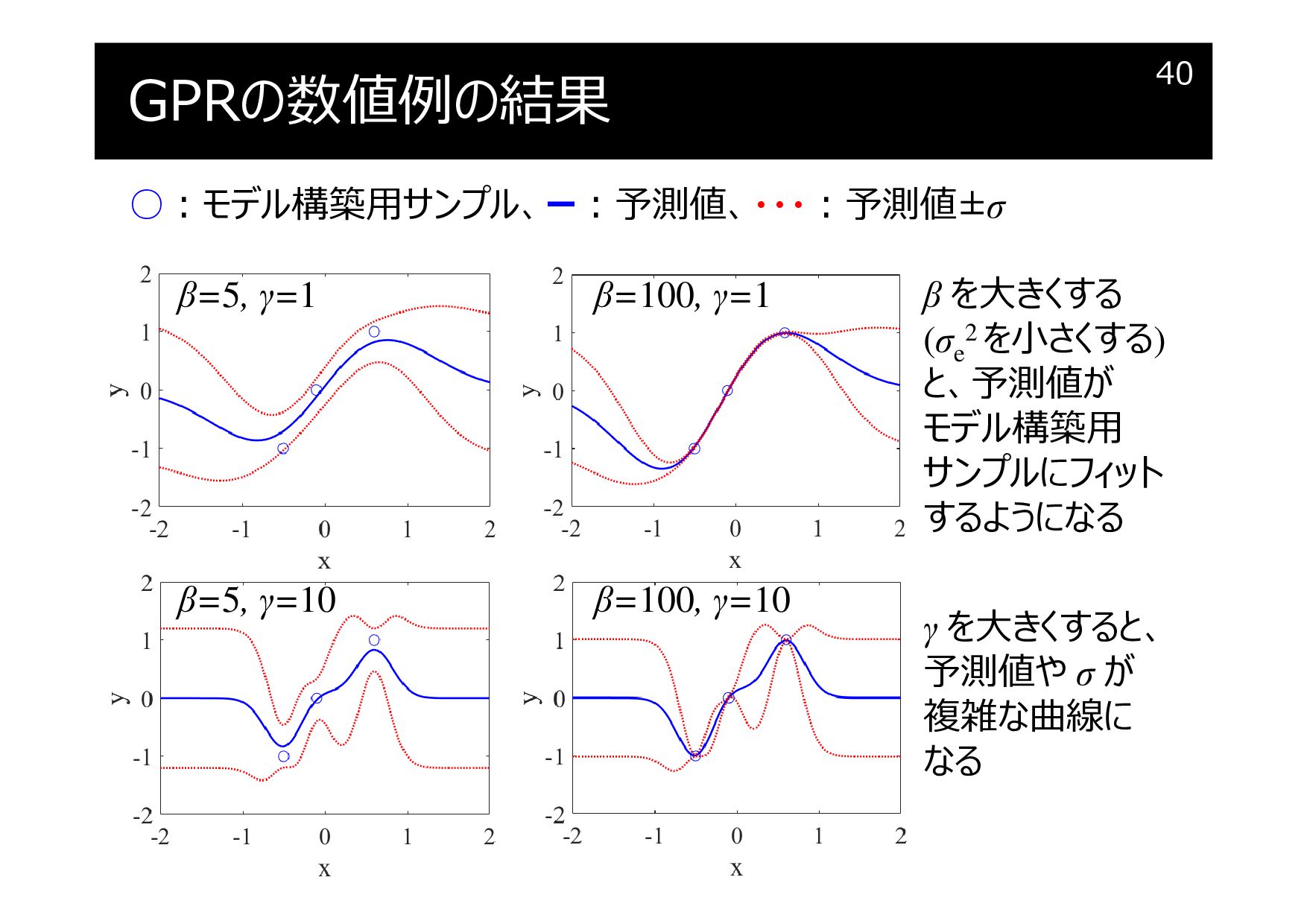
GPRの数値例の結果
ハイパーパラメータの決め方 1/2
ハイパーパラメータの決め方 2/2
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}