GMM とは?
どんなときに GMM を使うか?
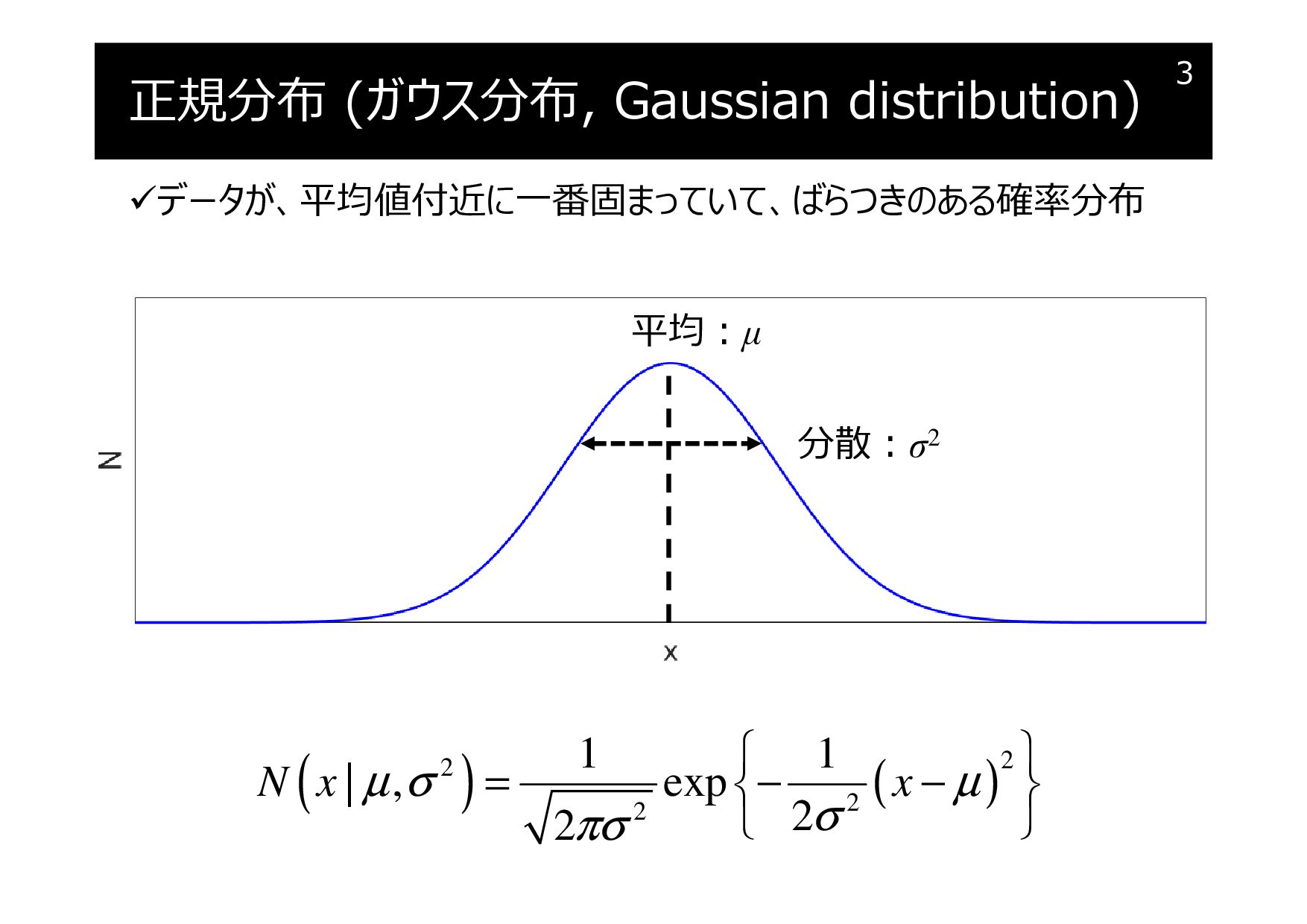
正規分布 (ガウス分布, Gaussian distribution)
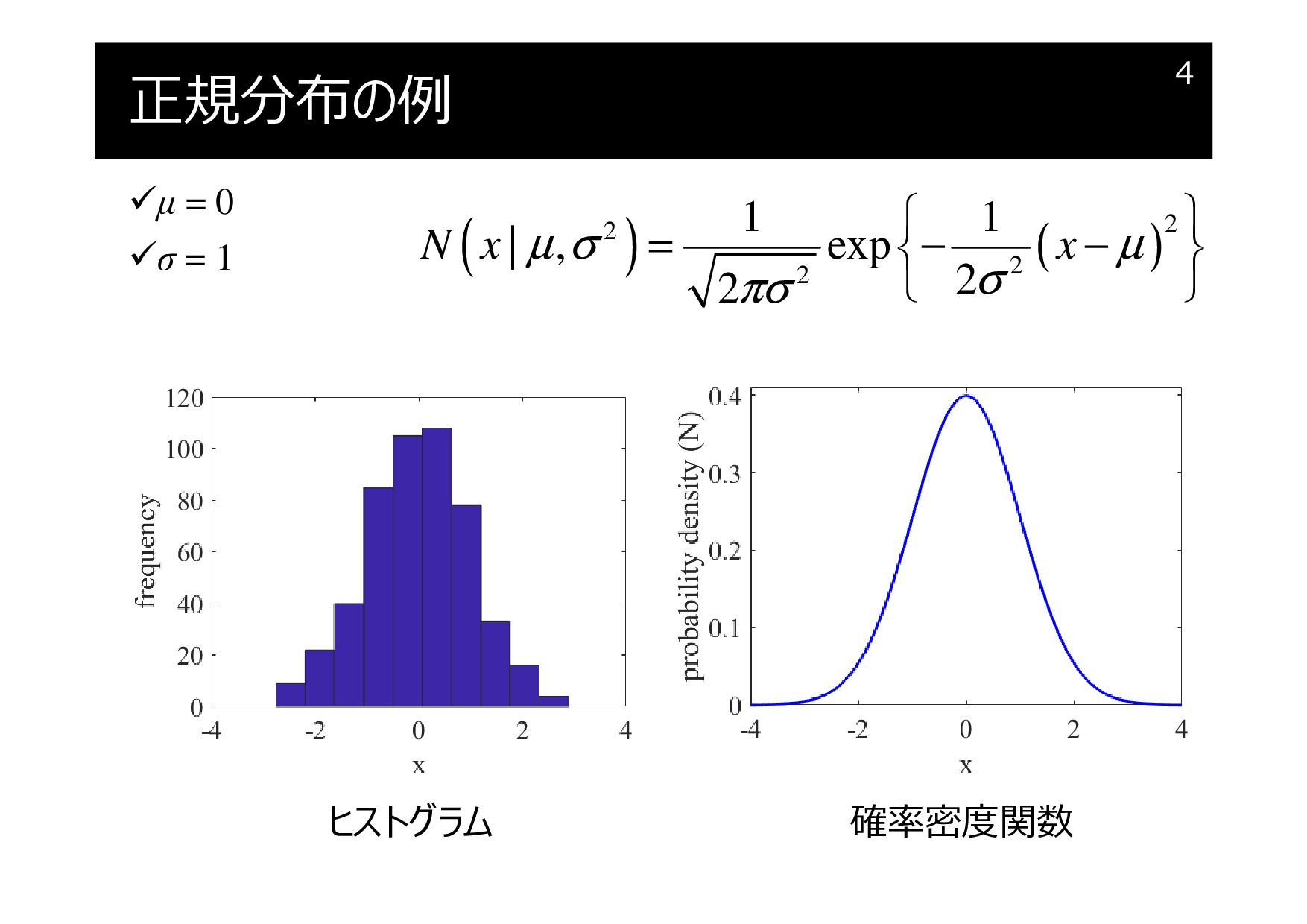
正規分布の例
多変量正規分布
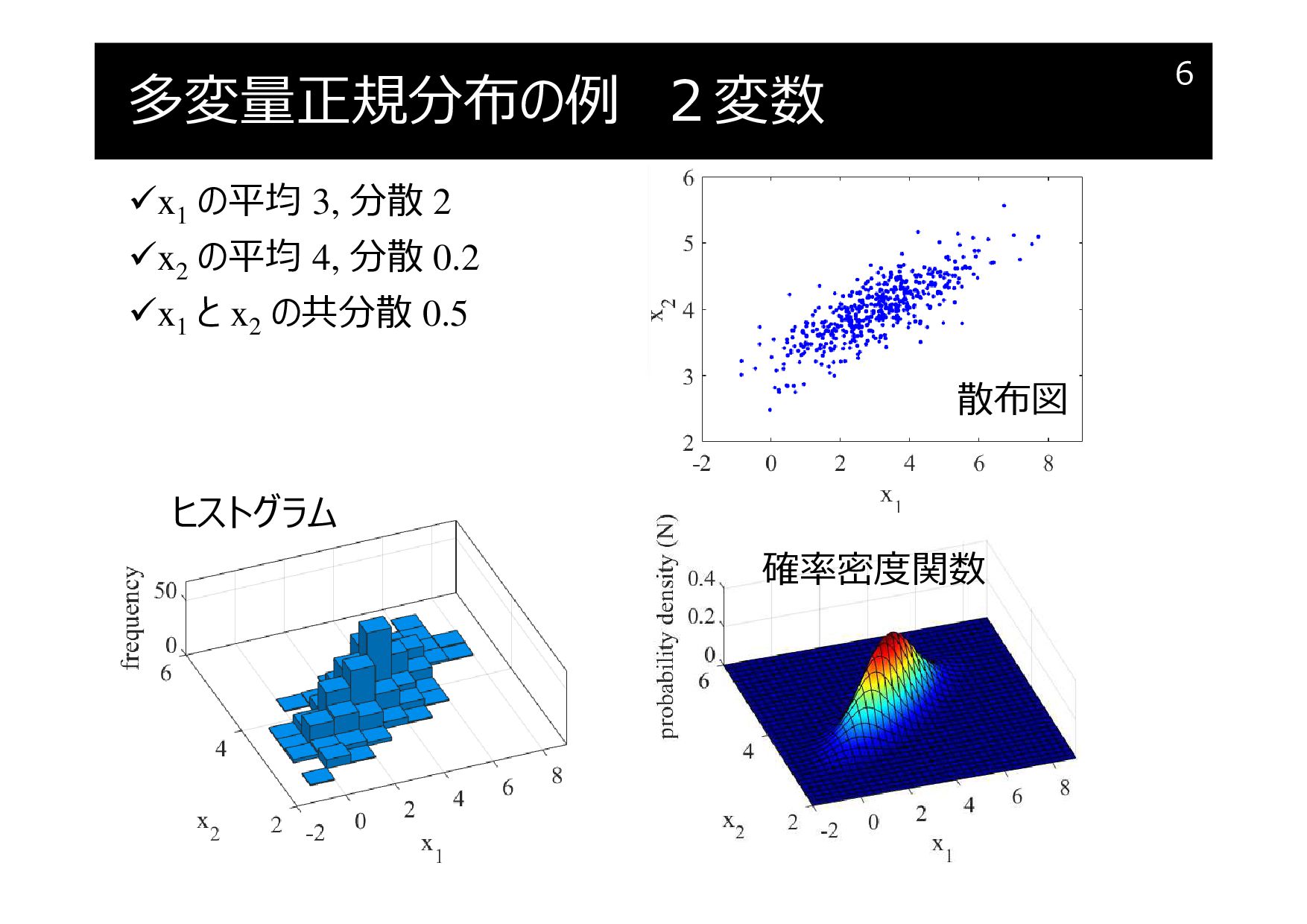
多変量正規分布の例 2変数
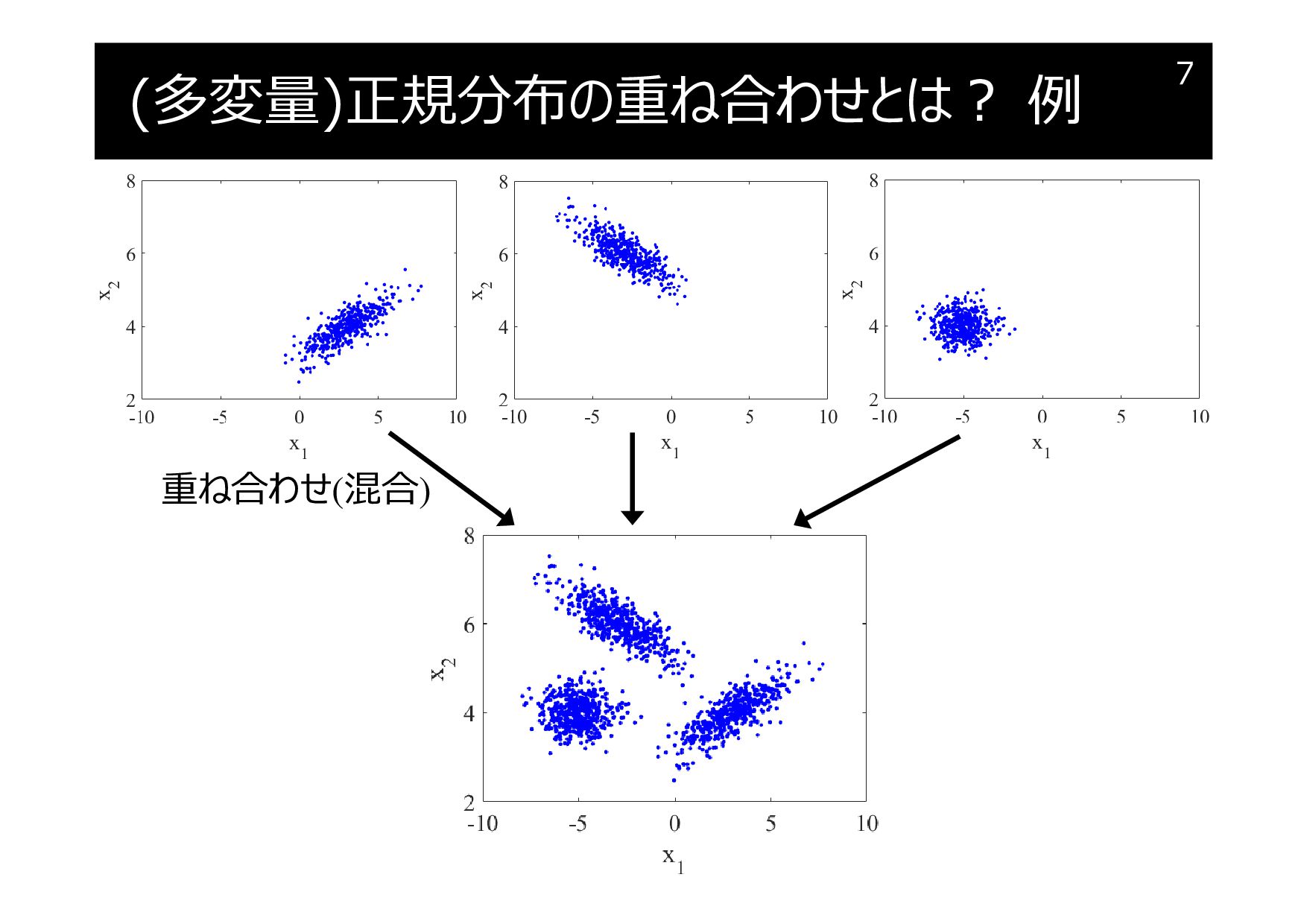
(多変量)正規分布の重ね合わせとは? 例
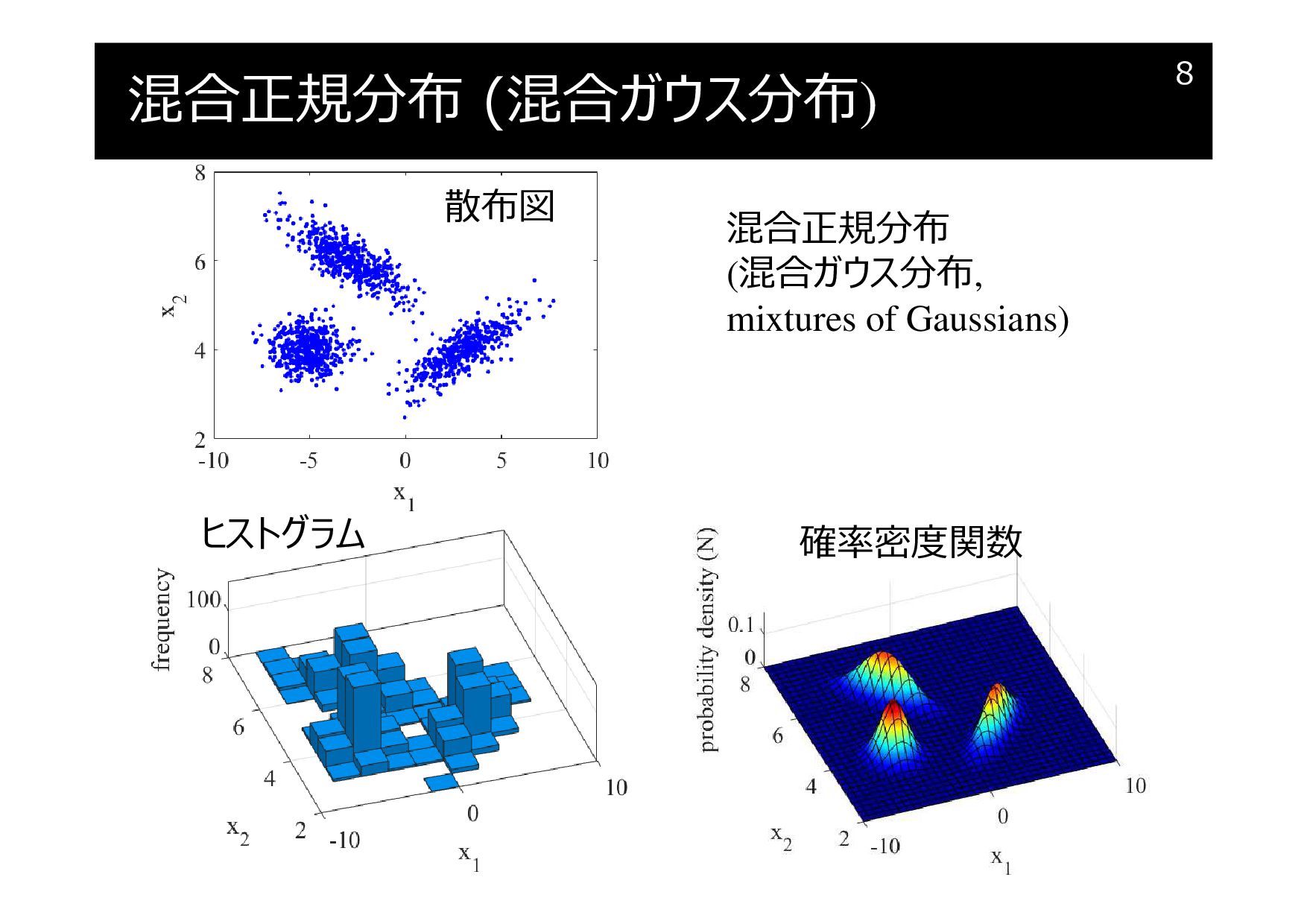
混合正規分布 (混合ガウス分布)
混合正規分布 (混合ガウス分布) 式
GMM の方針
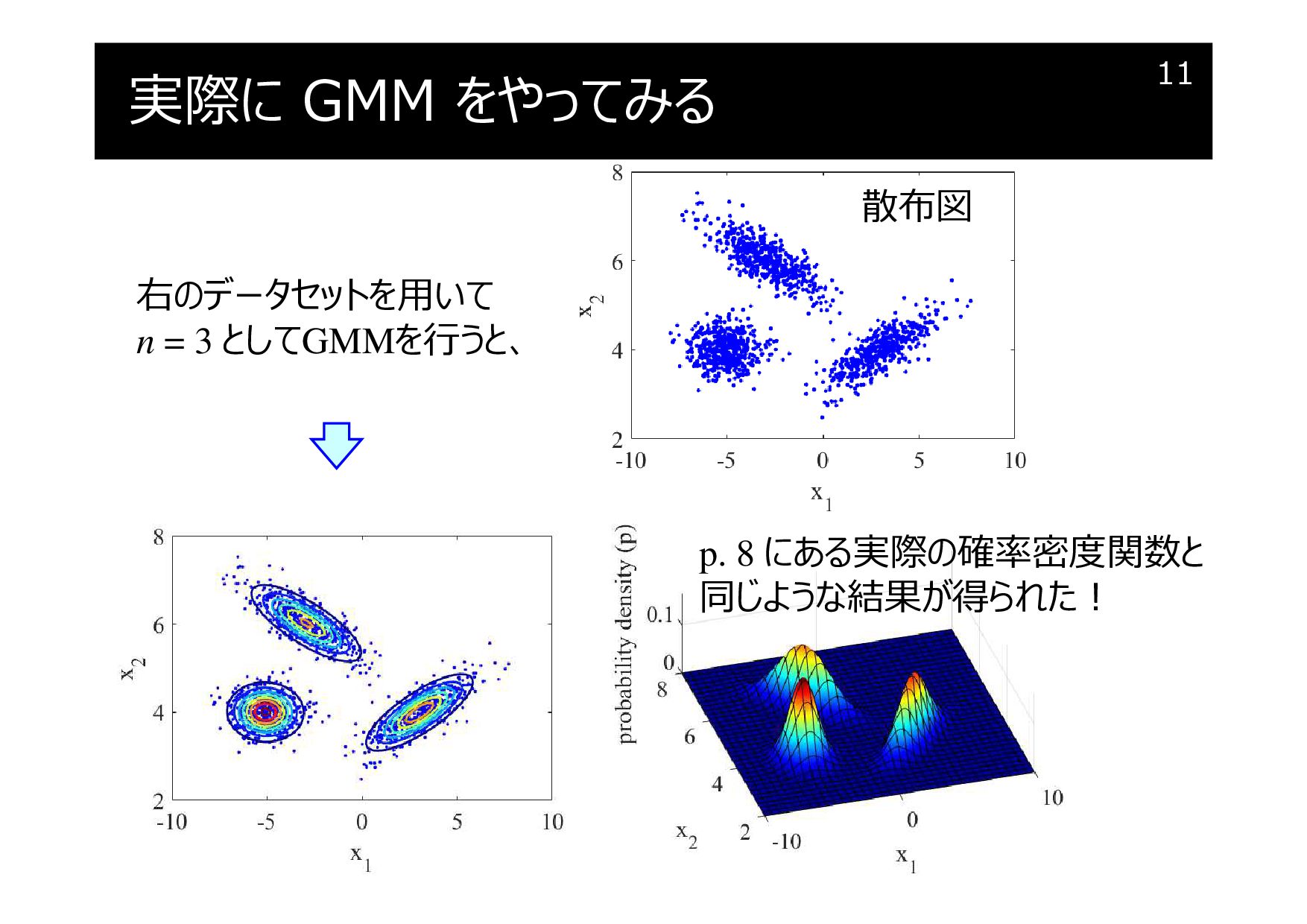
実際に GMM をやってみる
各サンプルがどのクラスターになるか考える 1/3
各サンプルがどのクラスターになるか考える 2/3
各サンプルがどのクラスターになるか考える 3/3
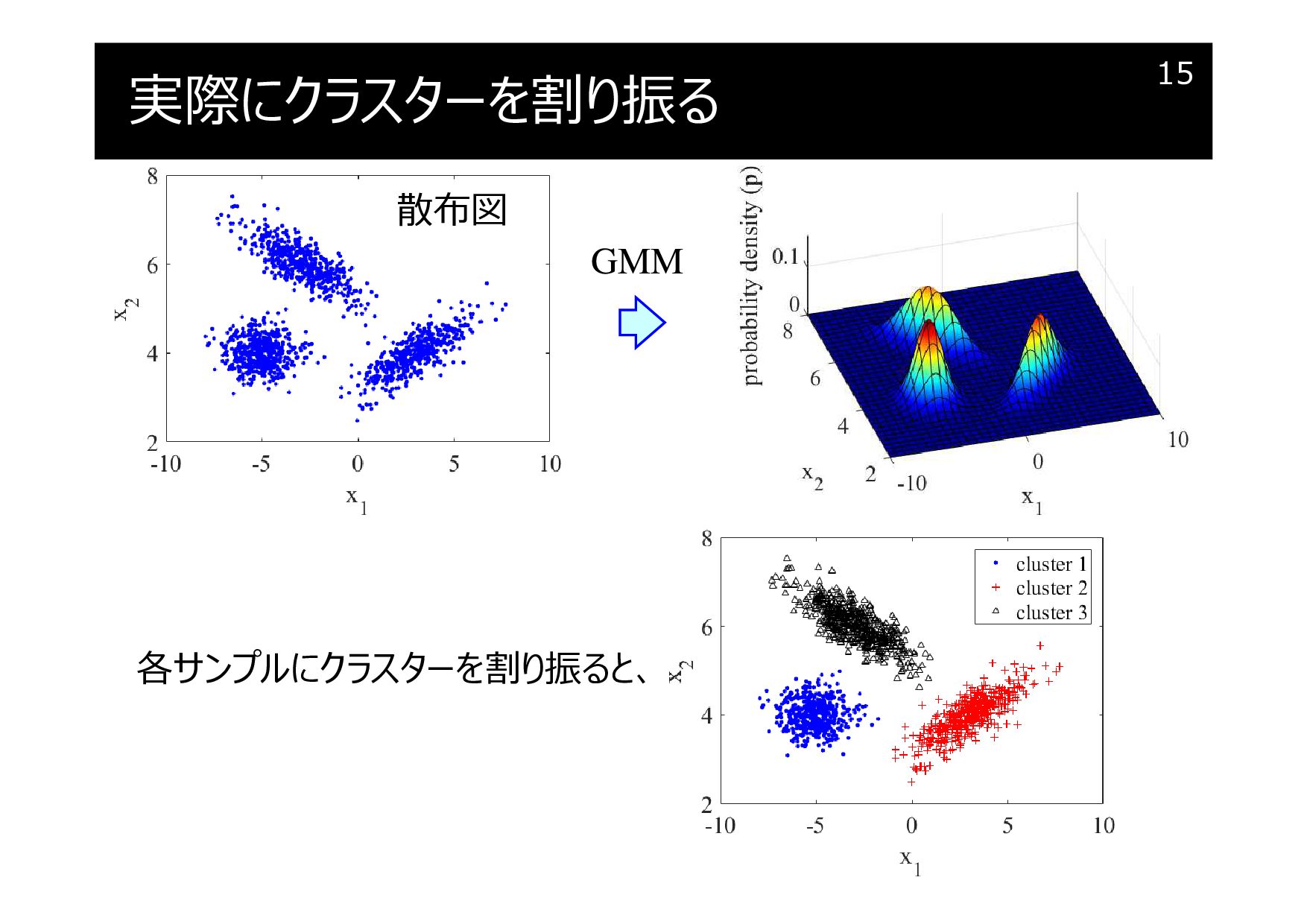
実際にクラスターを割り振る
クラスター数をどう決めるか?
ベイズ情報量規準 (BIC) を計算してみた
[補足] EM アルゴリズム 対数尤度関数
[補足] EM アルゴリズム 最大 → 極大
[補足] EM アルゴリズム μで微分
[補足] EM アルゴリズム 負担率
[補足] EM アルゴリズム μの計算
[補足] EM アルゴリズム Σ の計算
[補足] EM アルゴリズム π の計算
[補足] EM アルゴリズム π
[補足] EM アルゴリズム まとめ
参考文献
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[補足] EM アルゴリズム 対数尤度関数 18 GMM のパラメータ推定には、EM (Expectation-Maximization) アルゴリズムが用いられることが多い 対数尤度関数](https://files.speakerdeck.com/presentations/651f0b1afc5c402bba6ed93aed3af190/slide_18.jpg){kind=link}
![[補足] EM アルゴリズム 最大 → 極大 19 対数尤度関数が、μk , Σk](https://files.speakerdeck.com/presentations/651f0b1afc5c402bba6ed93aed3af190/slide_19.jpg){kind=link}
![[補足] EM アルゴリズム μで微分 20 対数尤度関数を μk で微分して 0 とすると、](https://files.speakerdeck.com/presentations/651f0b1afc5c402bba6ed93aed3af190/slide_20.jpg){kind=link}
![[補足] EM アルゴリズム 負担率 21 ( ) ( ) (](https://files.speakerdeck.com/presentations/651f0b1afc5c402bba6ed93aed3af190/slide_21.jpg){kind=link}
![[補足] EM アルゴリズム μの計算 22 ( ) ( ) (](https://files.speakerdeck.com/presentations/651f0b1afc5c402bba6ed93aed3af190/slide_22.jpg){kind=link}
![[補足] EM アルゴリズム Σ の計算 23 対数尤度関数を Σk で微分して 0](https://files.speakerdeck.com/presentations/651f0b1afc5c402bba6ed93aed3af190/slide_23.jpg){kind=link}
![[補足] EM アルゴリズム π の計算 24 πk について、Lagrange の未定乗数法より、 (](https://files.speakerdeck.com/presentations/651f0b1afc5c402bba6ed93aed3af190/slide_24.jpg){kind=link}
![[補足] EM アルゴリズム π 25 ( ) ( ) 1](https://files.speakerdeck.com/presentations/651f0b1afc5c402bba6ed93aed3af190/slide_25.jpg){kind=link}
![[補足] EM アルゴリズム まとめ ① μk , Σk , πk](https://files.speakerdeck.com/presentations/651f0b1afc5c402bba6ed93aed3af190/slide_26.jpg){kind=link}
![[補足] 変分ベイズ法 μ, Σ の事前分布 GMM のパラメータを変分ベイズ法で推定 → Variational Bayesian](https://files.speakerdeck.com/presentations/651f0b1afc5c402bba6ed93aed3af190/slide_27.jpg){kind=link}
![[補足] 変分ベイズ法 π の事前分布 π の事前分布としてディリクレ分布やディリクレ過程を導入 • ディリクレ分布 • ディリクレ過程](https://files.speakerdeck.com/presentations/651f0b1afc5c402bba6ed93aed3af190/slide_28.jpg){kind=link}
{kind=link}