Gerçek zamanlı gelişmiş analiz yapabilmenize olanak verir • Kolayca dağıtık yapı kurabileceğiniz bir yapı sunar • Kendi içerisinde yüksek erişilebilirlik sunar • Full-text search yapabilmenizi sağlar • Döküman odaklı çalışır • Geliştirici dostudur ve Restful bir API arayüzü vardır. • Lucene tabanlıdır
kullanabiliriz. (Search API) • Günlüklerimizi (Logs) barındırmak ve içerlerinde arama yapmak için kullanabiliriz. (Logstash, Kibana) • Verilerimiz üzerinde neredeyse gerçek zamanlı analiz ve raporlar hazırlamak için kullanabiliriz. (Aggregations)
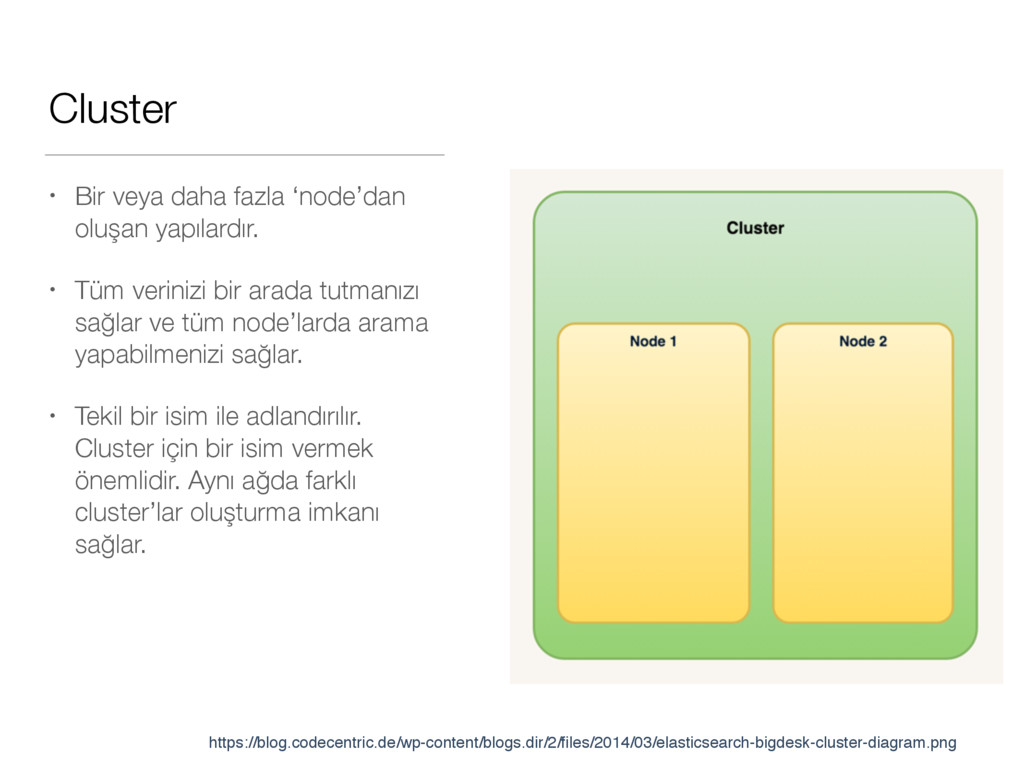
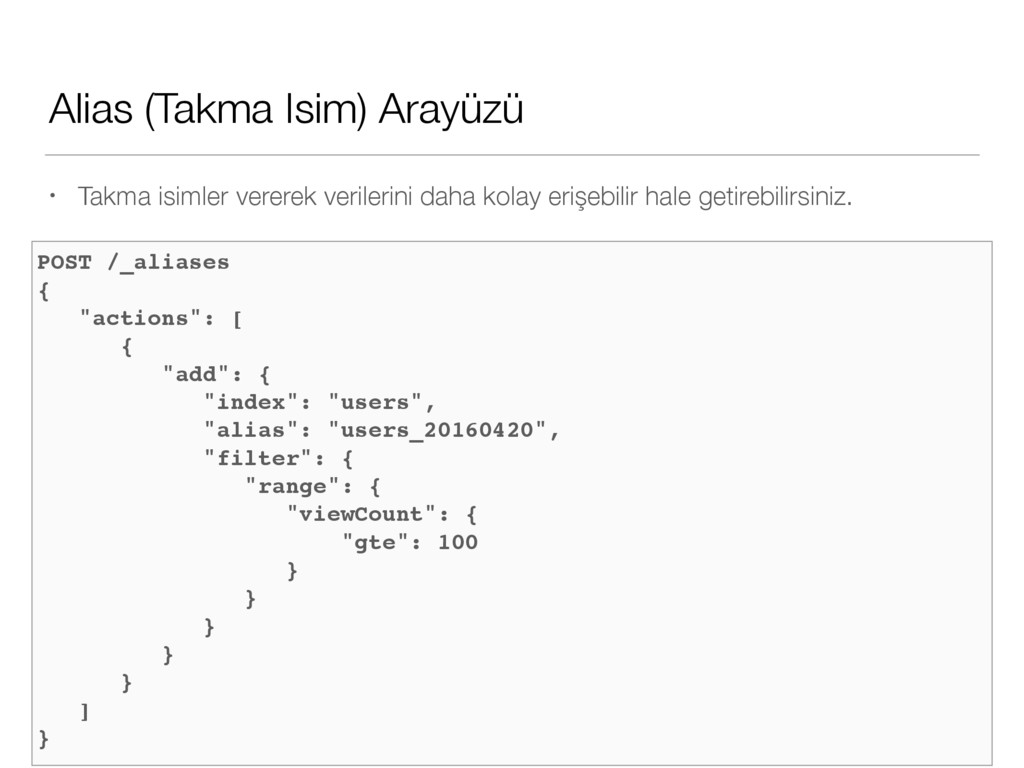
Tüm verinizi bir arada tutmanızı sağlar ve tüm node’larda arama yapabilmenizi sağlar. • Tekil bir isim ile adlandırılır. Cluster için bir isim vermek önemlidir. Aynı ağda farklı cluster’lar oluşturma imkanı sağlar. https://blog.codecentric.de/wp-content/blogs.dir/2/files/2014/03/elasticsearch-bigdesk-cluster-diagram.png
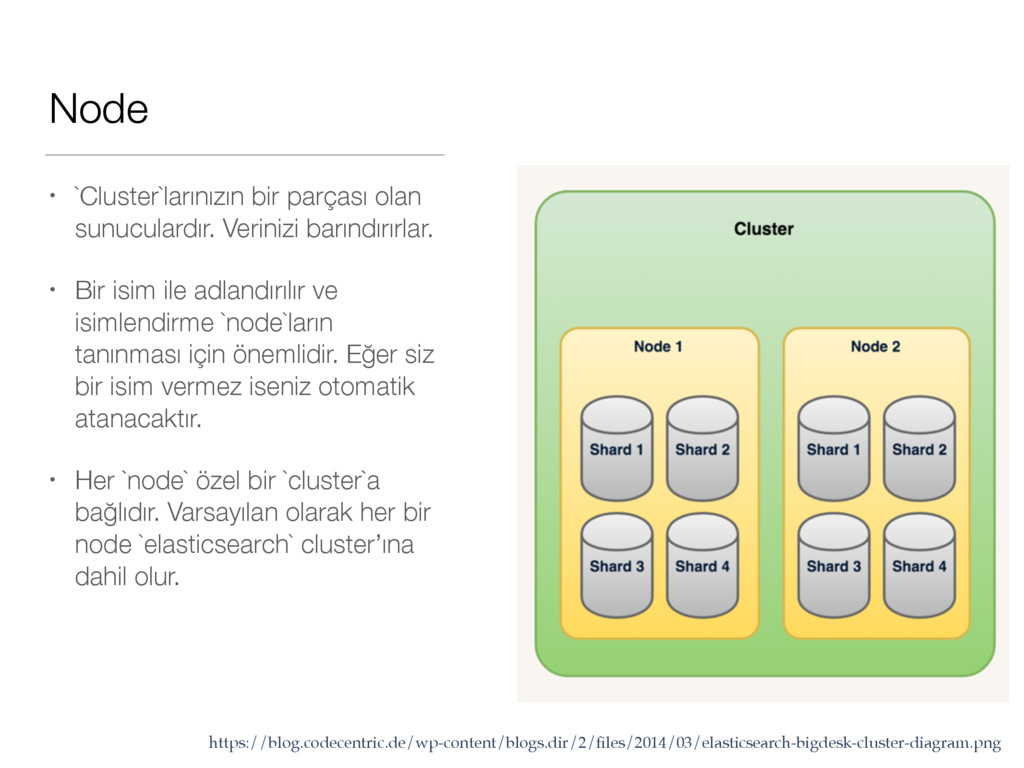
Bir isim ile adlandırılır ve isimlendirme `node`ların tanınması için önemlidir. Eğer siz bir isim vermez iseniz otomatik atanacaktır. • Her `node` özel bir `cluster`a bağlıdır. Varsayılan olarak her bir node `elasticsearch` cluster’ına dahil olur. https://blog.codecentric.de/wp-content/blogs.dir/2/files/2014/03/elasticsearch-bigdesk-cluster-diagram.png
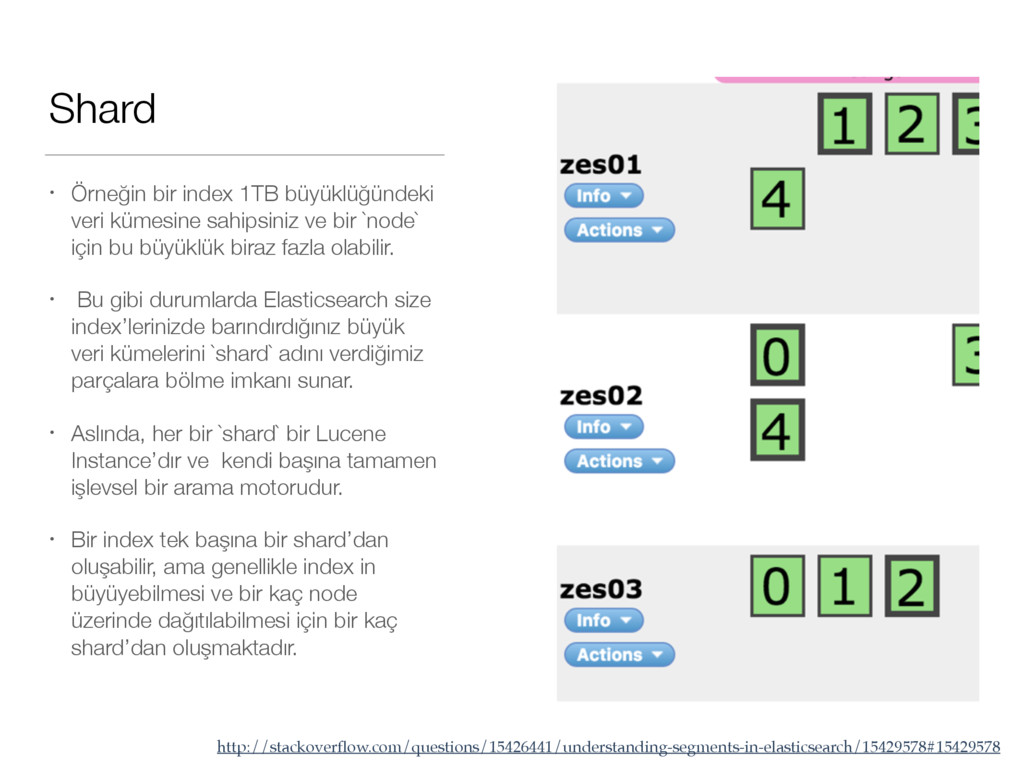
ve bir `node` için bu büyüklük biraz fazla olabilir. • Bu gibi durumlarda Elasticsearch size index’lerinizde barındırdığınız büyük veri kümelerini `shard` adını verdiğimiz parçalara bölme imkanı sunar. • Aslında, her bir `shard` bir Lucene Instance’dır ve kendi başına tamamen işlevsel bir arama motorudur. • Bir index tek başına bir shard’dan oluşabilir, ama genellikle index in büyüyebilmesi ve bir kaç node üzerinde dağıtılabilmesi için bir kaç shard’dan oluşmaktadır. http://stackoverflow.com/questions/15426441/understanding-segments-in-elasticsearch/15429578#15429578
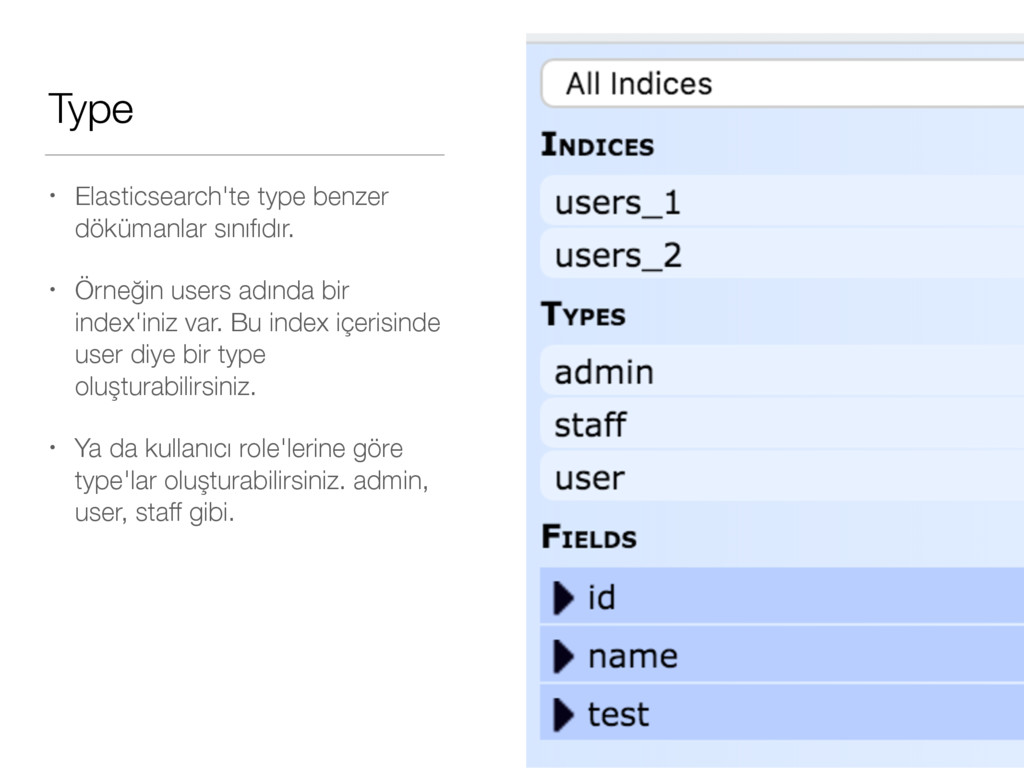
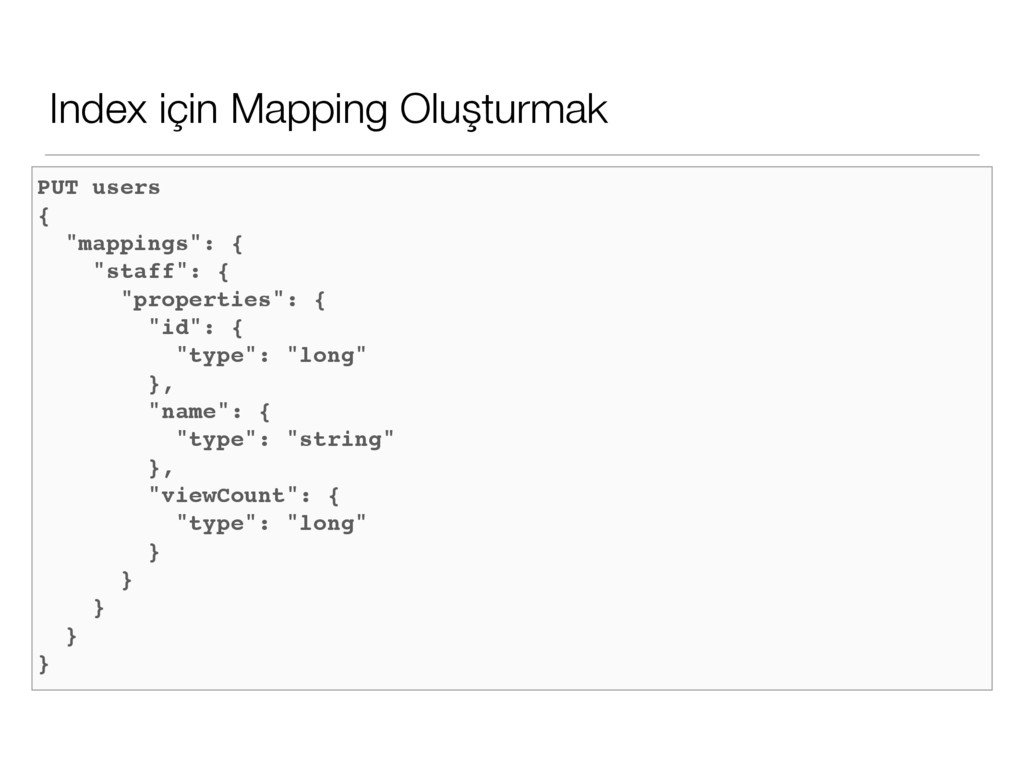
adında bir index'iniz var. Bu index içerisinde user diye bir type oluşturabilirsiniz. • Ya da kullanıcı role'lerine göre type'lar oluşturabilirsiniz. admin, user, staff gibi.
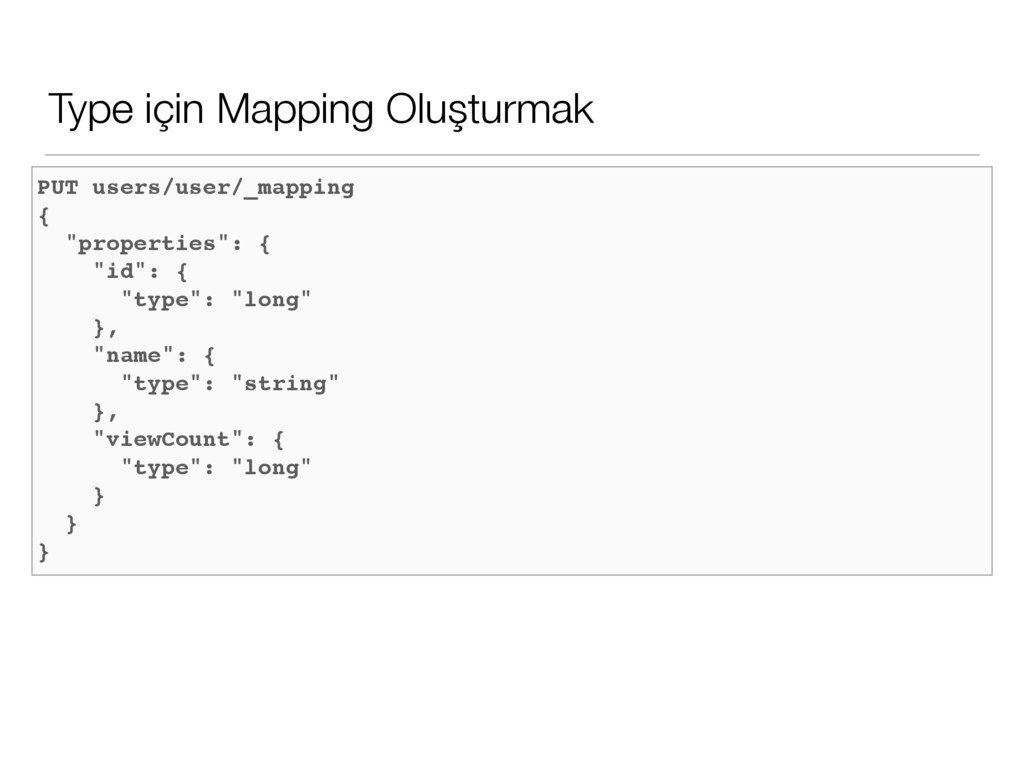
özelliklerinin neler olduğunu belirtirler. Hangi alanların `index`e alınacağı ya da alınmayacağını belirler. • Daha önce de bahsettiğimiz gibi Elasticsearch’te her index altında `Type`lar mevcuttur. Her bir type’a ait `mapping`ler vardır. http://lucene.apache.org/core/3_5_0/fileformats.html#Primitive Types
formatında olmasını önemsemez. Tüm değerler field-value tutulur ve opaque bytes olarak kabul edilir. • Type’ların Lucene tarafında direk olarak bir karşılığı yoktur. Lucene tarafında bu veriler saklanırken her bir dokümana meta data eklenir. Bu meta veri içerisinde _type diye bir alan vardır. Bu alana verinizin `Type` bilgisi yazılır. Biz özel bir `Type`a göre bir arama yaptığımızda Lucene tarafında _type alanında bir filtreleme yapar. • Lucene'de aynı zamanda mapping diye bir kavramda yoktur. Mapping’ler Elasticsearch'ün karışık JSON dökümanlarını Lucene'in beklediği bir yapıya sokmak için kullandığı bir ara katmandır.
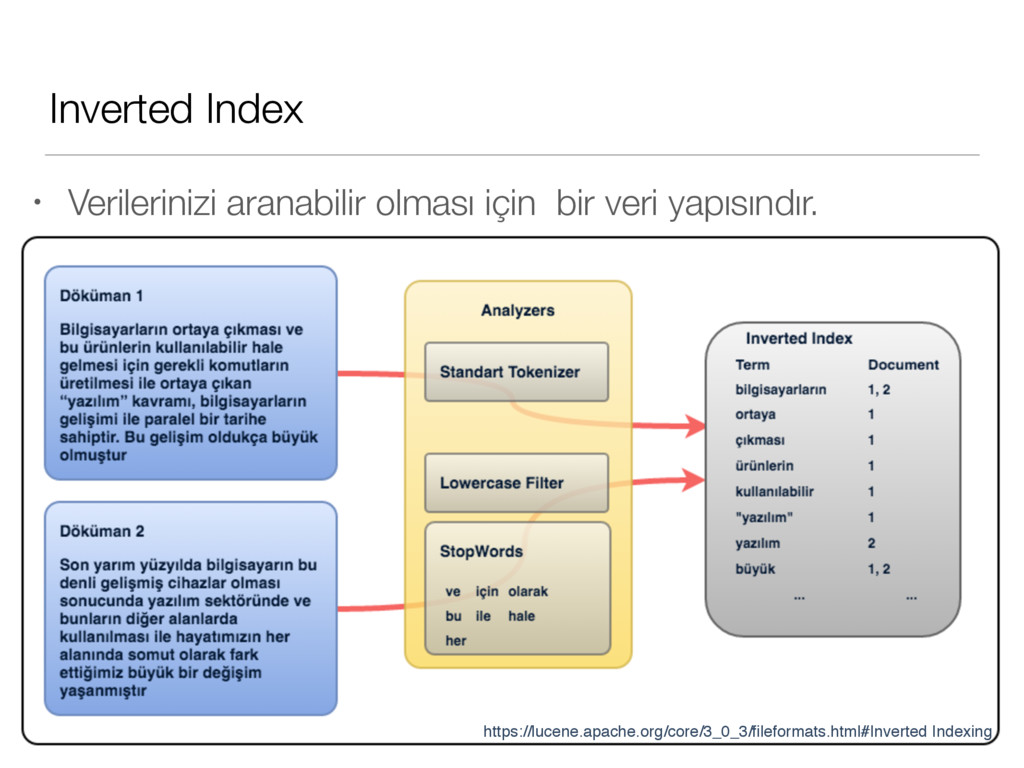
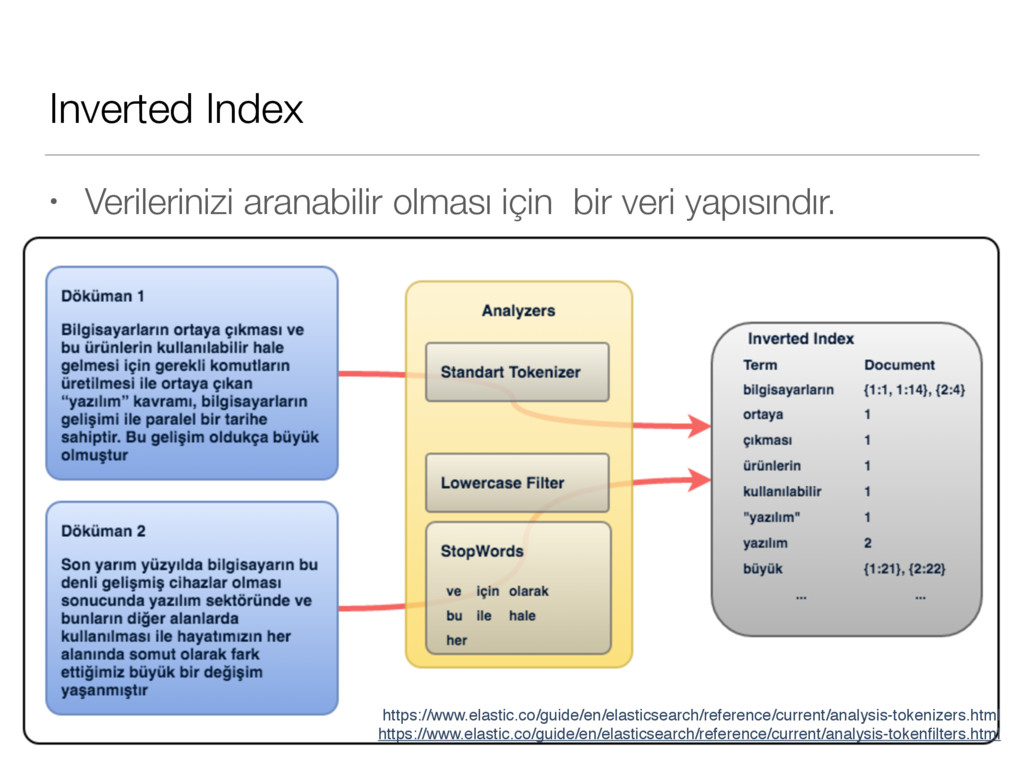
yapısındır. • Yeni bir döküman geldiğinde, döküman üzerindeki her bir alan `inverted index`e eklenir. Orijinal döküman da daha sonra geri verilebilmesi için saklanır. Daha sonra aramalar bu `inverted index` kısmında yapılır. • Bunu bir örnek ile gösterelim : Kaynak : https://lucene.apache.org/core/3_0_3/fileformats.html#Inverted Indexing Metin : http://www.emo.org.tr/ekler/7c6326a2cfccd2f_ek.pdf
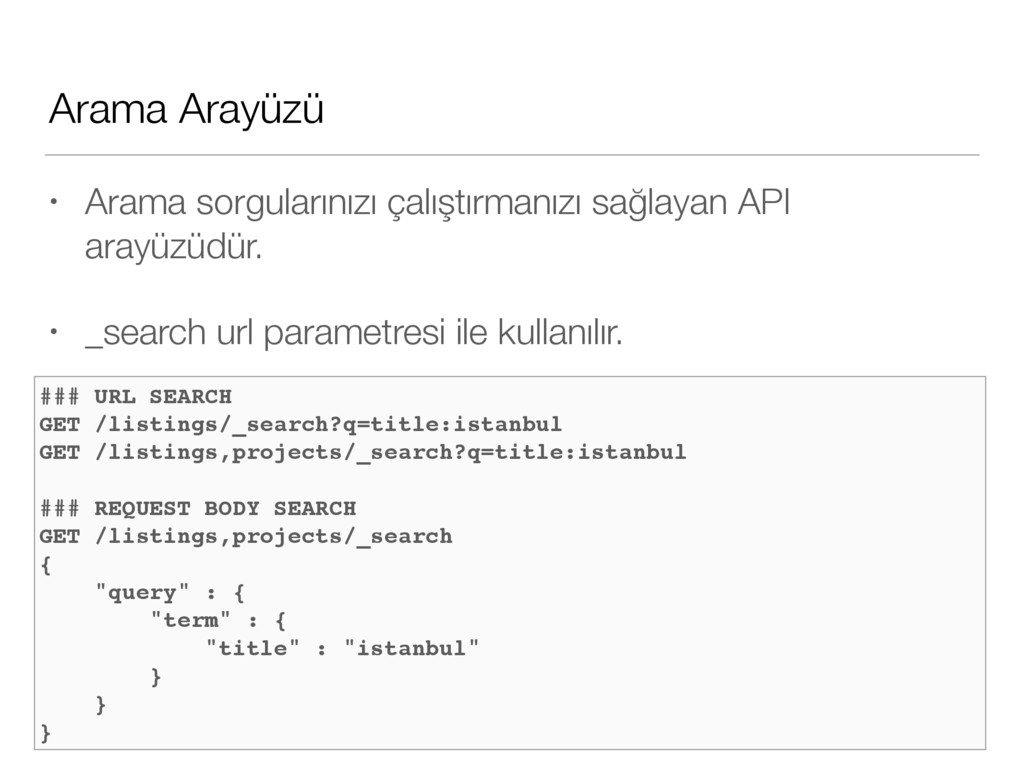
arayüzüdür. • Tekil bir döküman için Index, Get, Delete, Update API arayüzleri bulunmaktadır. • Aynı zamanda MultiGet ve Bulk API arayüzü ile aynı anda birden fazla döküman üzerinde işlem yapabilirsiniz. • 2.3 versiyonu ile birlikte UpdateByQuery API arayüzü ile arama yaparak dökümanları güncelleyebilirsiniz. • 2.3 versiyonu ile birlikte ReIndex API arayüzünü kullanarak dökümanlarınızı farklı indexlere hızlıca taşıyabilirsiniz.
Tekil bir döküman için Index, Get, Delete, Update API arayüzleri bulunmaktadır. • Aynı zamanda MultiGet ve Bulk API arayüzü ile aynı anda birden fazla döküman üzerinde işlem yapabilirsiniz. ### SCRIPTED UPDATE POST /users/staff/1/_update { "script" : { "inline": "ctx._source.viewCount += viewCount", "params" : { "viewCount" : 1 } } } ### PARTIAL UPDATE POST /users/staff/1/_update { "doc" : { "name" : "Mustafa" } } https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-scripting.html#enable-dynamic-scripting
parametreleri ile eşleşiyor mu? • Score yok • Sadece evet/hayır sorusunu cevaplar • Belleklenebilir (Caching active) • Query => Bu döküman bu arama parametreleri ile en iyi nasıl eşleşir? • Bir score hesaplanır ve diğer dökümanlar ile bağlantılıdır
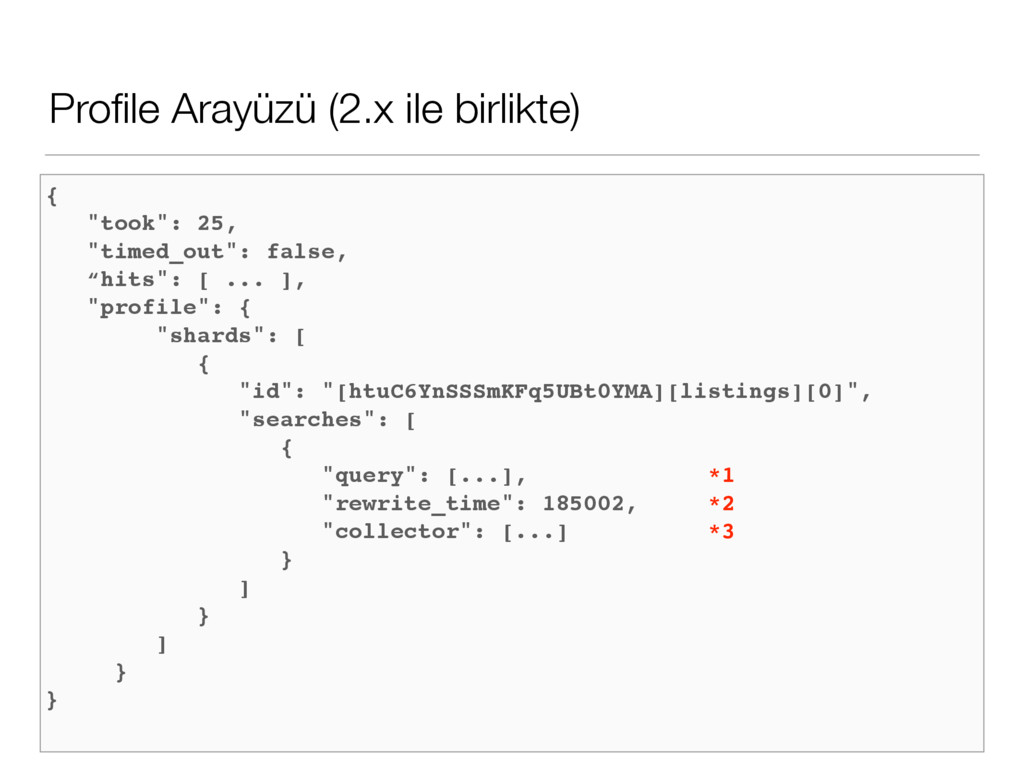
detaylı bilgi vermektedir. 2. Her bir profil için toplu zamanı gösterir 3. Lucene tarafında kullanılan Collectors’ları gösterir. https://www.elastic.co/guide/en/elasticsearch/reference/2.3/search-profile.html
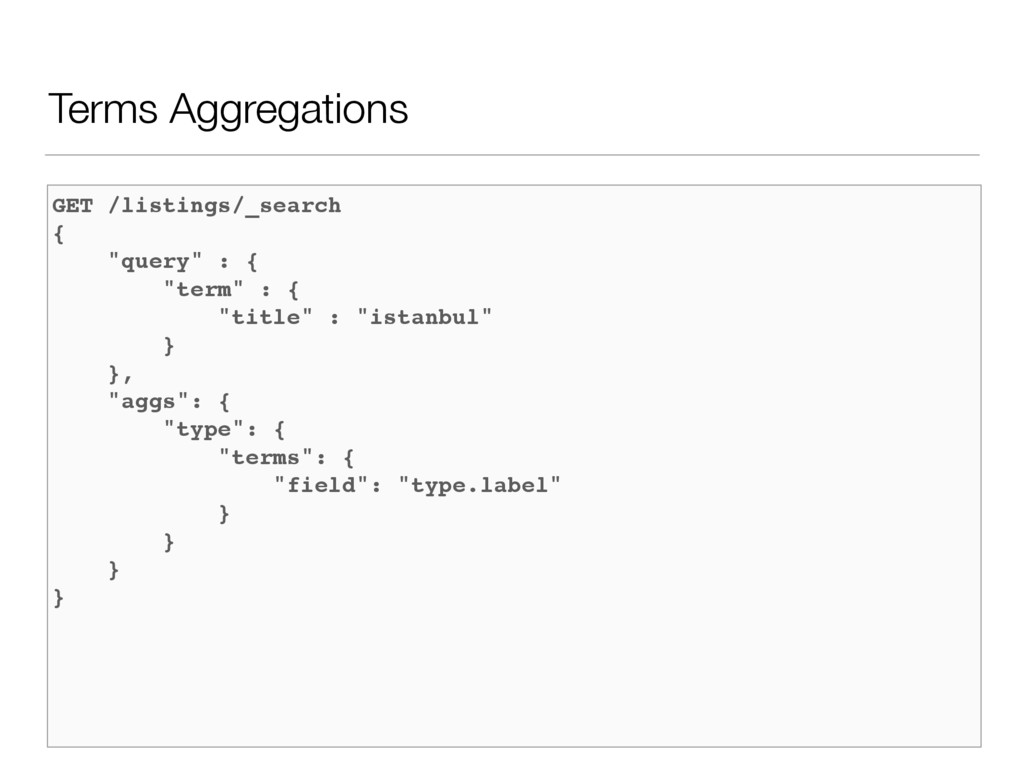
• Bucket Aggregation • Verileriniz sadece birleştirir ve bunlar üzerinden bilgi sunar. (Missing, Filter, Children, Terms, Date Histogram, Date Range, …) • Metrics Aggregation • Verileriniz üzerinde hesaplama yapar ve sonuçlarını sunar. (Avg, Cardinality, Extended Stats, Stats, Sum, Top Hits, …) • Pipeline Aggregation • Başka bir aggregation sonucundaki veriler üzerinde işlem yapar ya da verileri toplar. (Avg Bucket, Derivative, …)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}