A talk given at the Vilnius Ruby meetup group in Vilnius, Lithuania; originally developed by Yoav Abrahami, and based on the works of Kyle "Aphyr" Kingsbury:
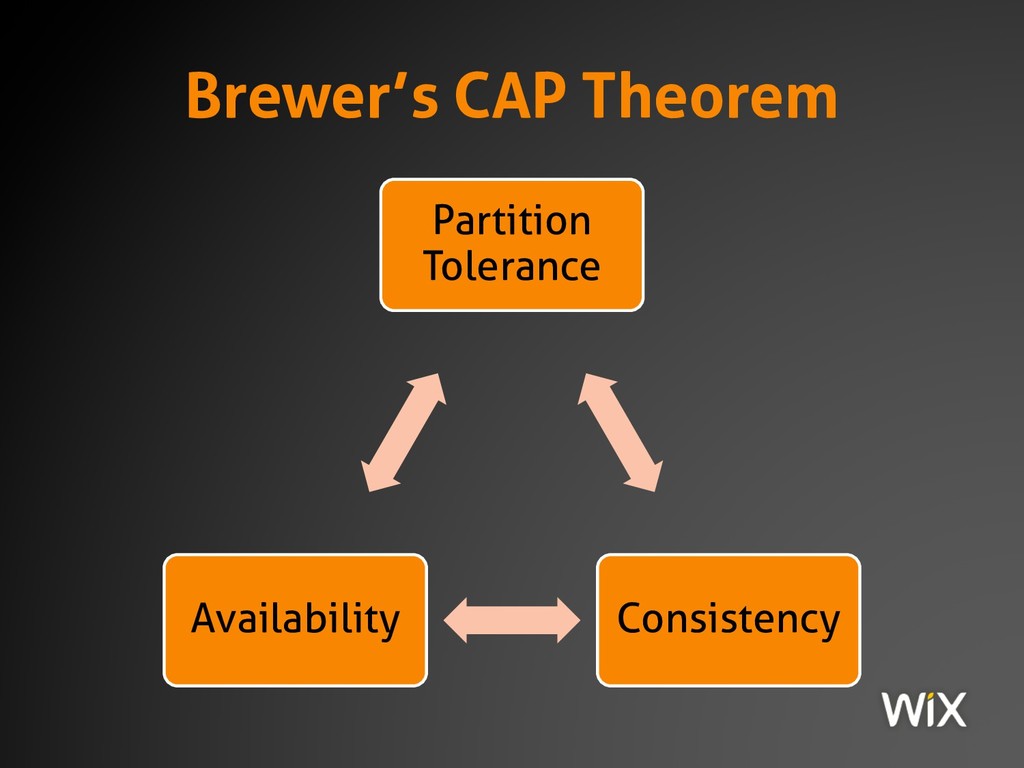
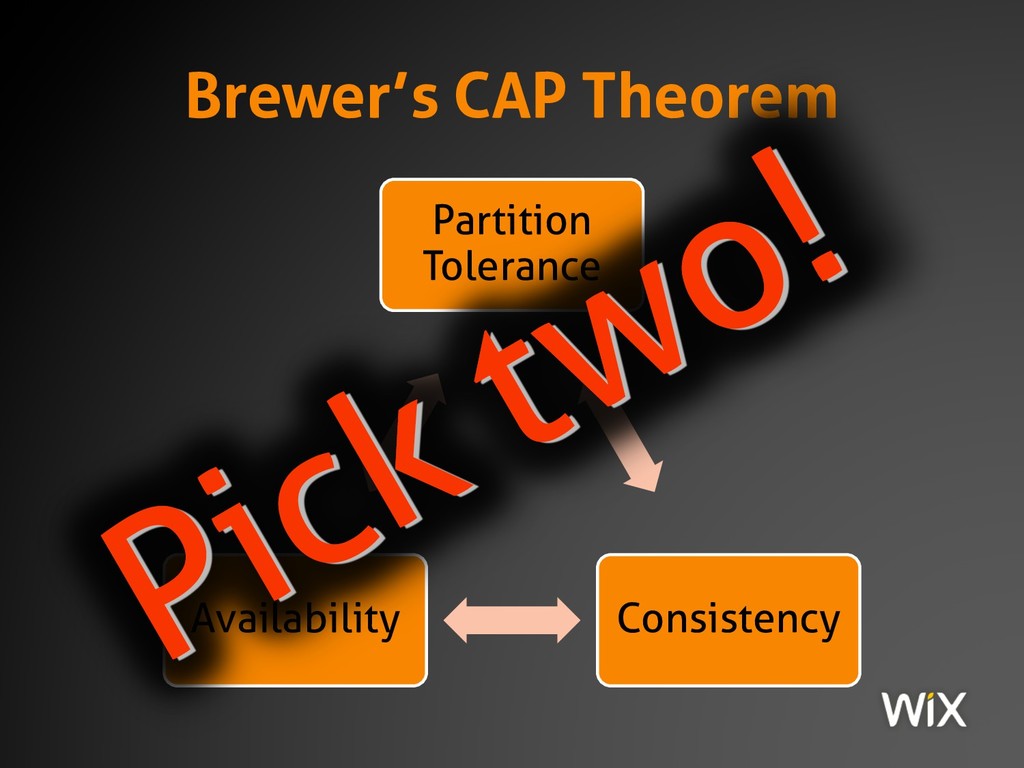
Consistency, availability and partition tolerance: these seemingly innocuous concepts have been giving engineers and researchers of distributed systems headaches for over 15 years. But despite how important they are to the design and architecture of modern software, they are still poorly understood by many engineers.
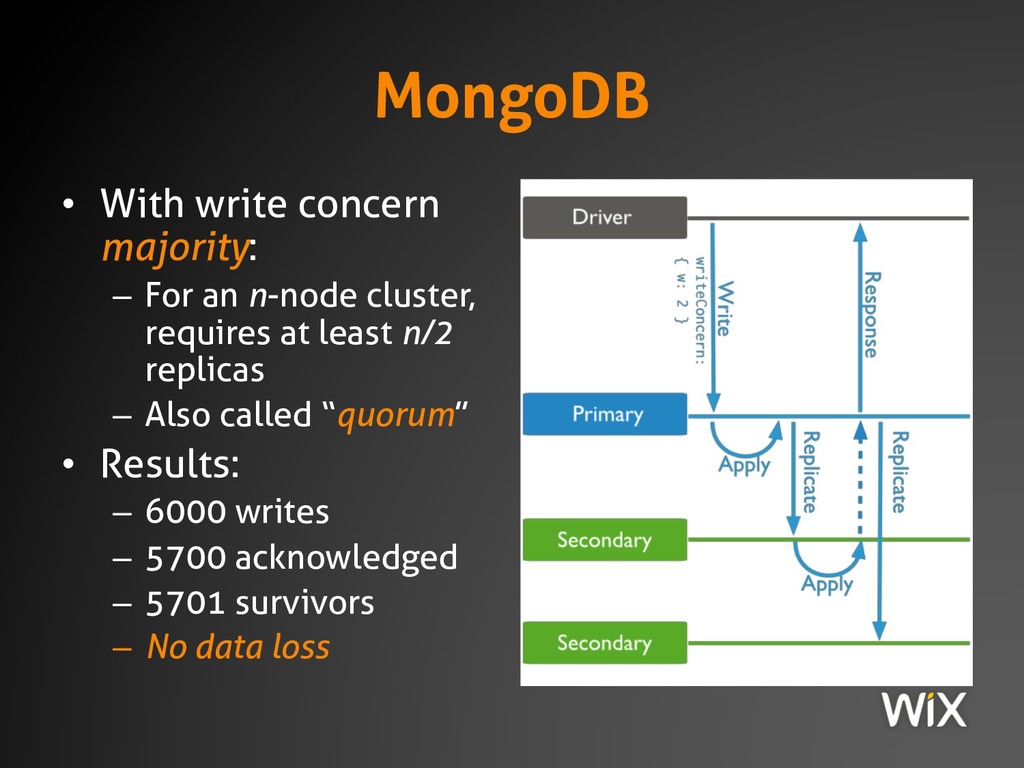
This session covers the definition and practical ramifications of the CAP theorem; you may think that this has nothing to do with you because you "don't work on distributed systems", or possibly that it doesn't matter because you "run over a local network." Yet even traditional enterprise CRUD applications must obey the laws of physics, which are exactly what the CAP theorem describes. Know the rules of the game and they'll serve you well, or ignore them at your own peril...
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
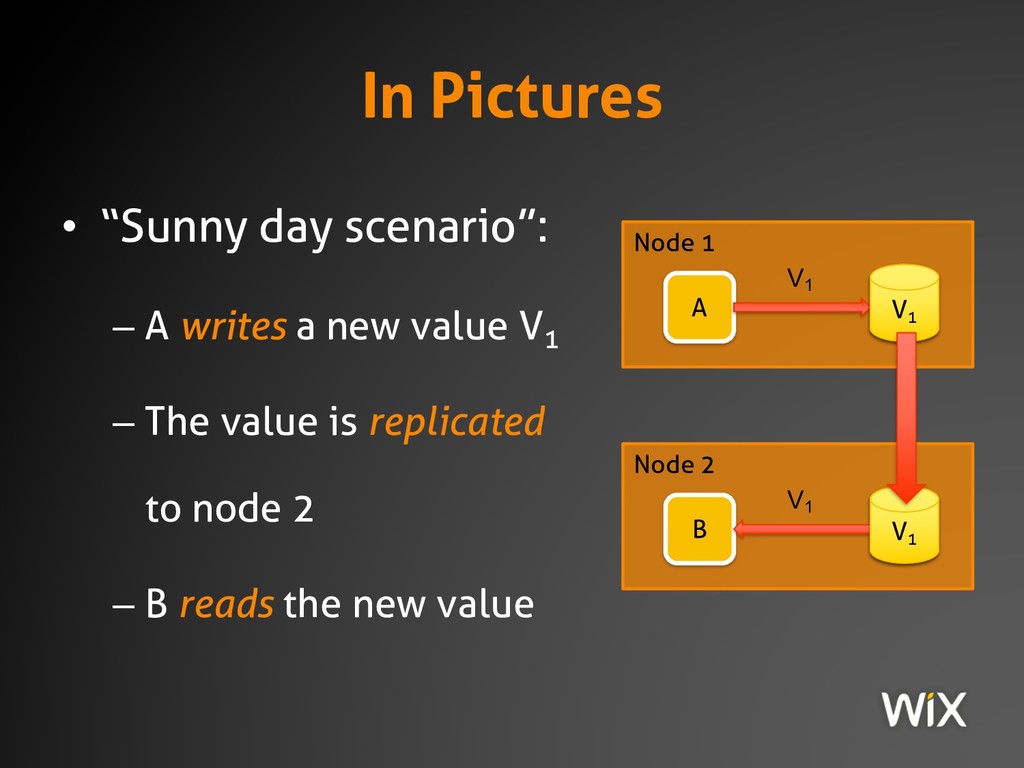{kind=link}
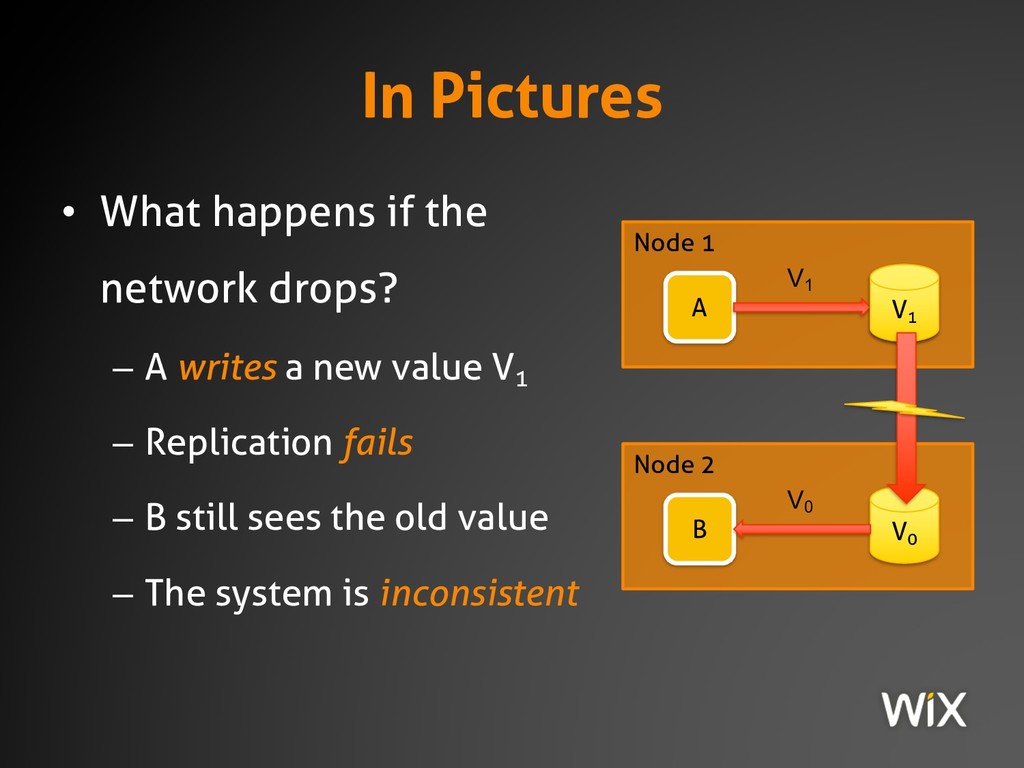{kind=link}
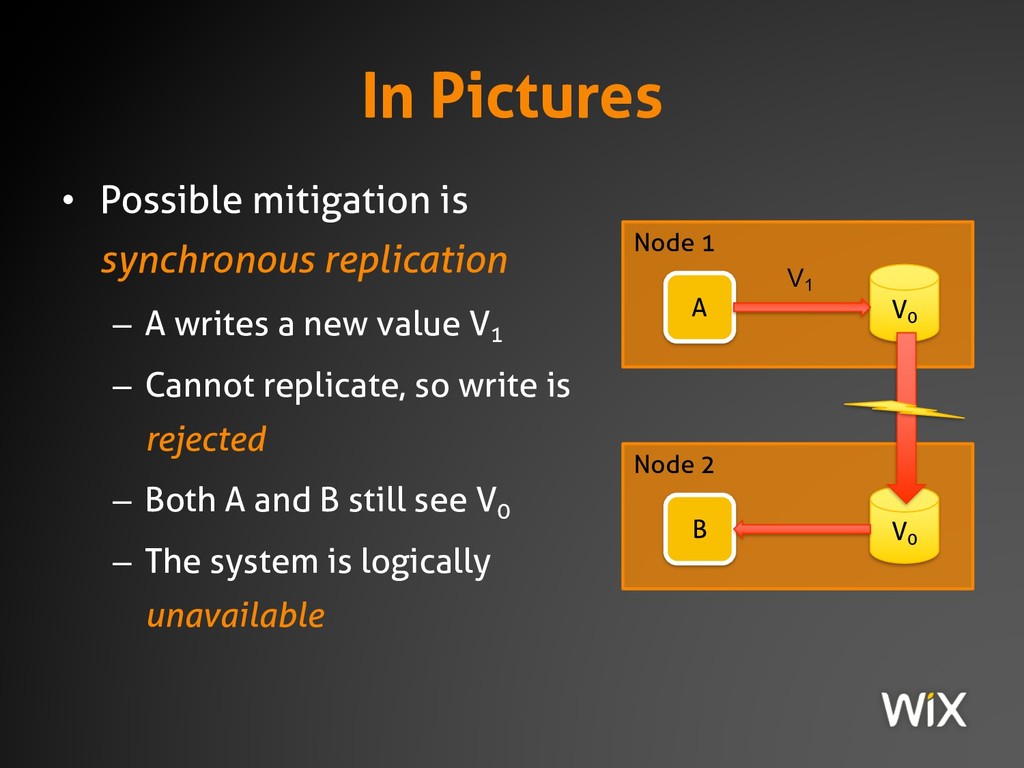{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
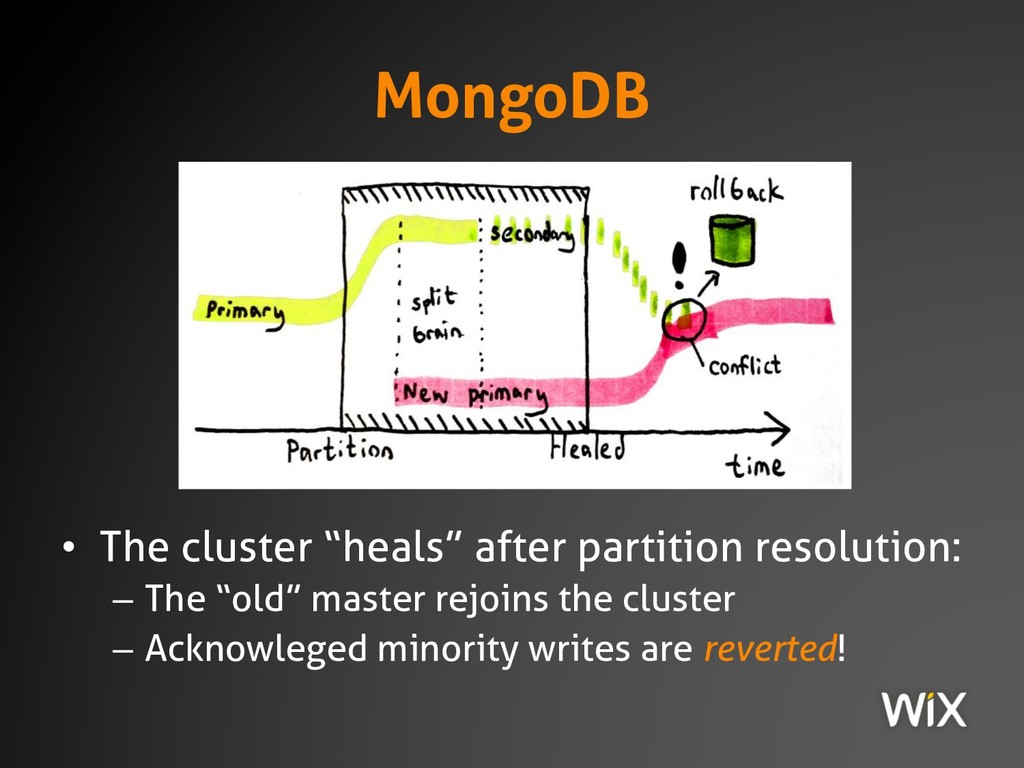{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![WE’RE DONE HERE! Thank you for listening [email protected] @tomerg http://il.linkedin.com/in/tomergabel](https://files.speakerdeck.com/presentations/9aa4dc39d7ed49b88fc11d24990a6cb9/slide_36.jpg){kind=link}