Beyond Data: How containers are making the sharing and publishing of complete computational environments a possibility:
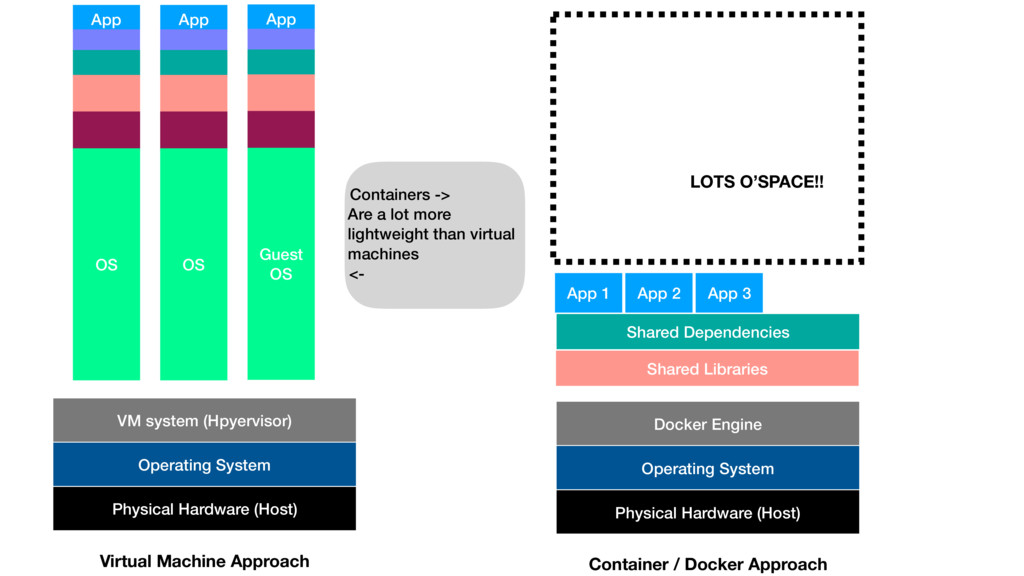
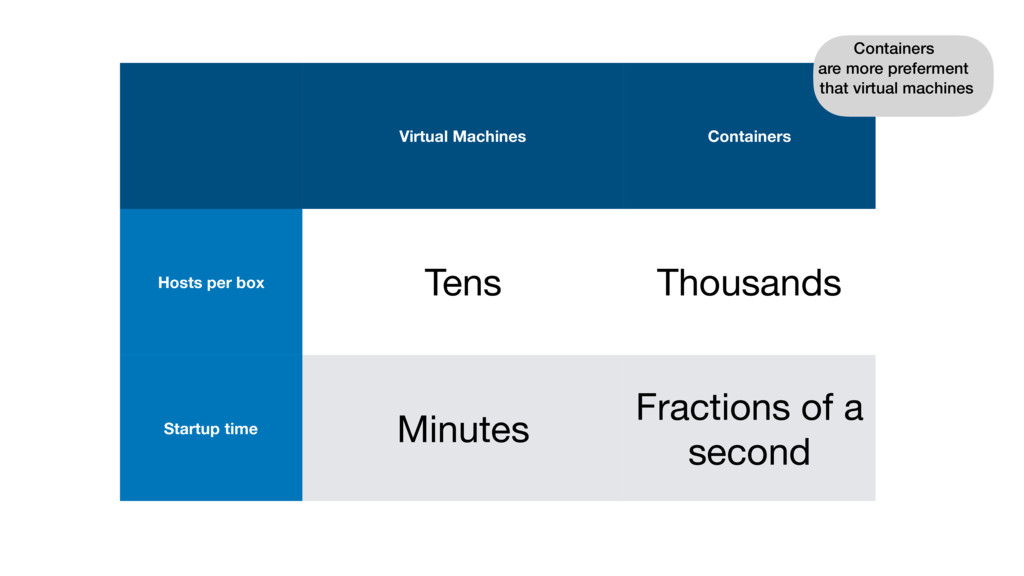
Funders have already begun to request data sharing from their researchers, and the publishing industry is responding with initiatives such as enabling data citation and linking publications to primary data. In this short talk we will ask what might come next? Data itself rarely emerges into the world complete, but often needs a series of computational steps for collection, cleaning and analysis. Up to now sharing of software has usually been a fairly static affair, but software can be a notoriously difficult to get running, with dependencies on operating systems and libraries and host systems. Container technology is making it possible to encapsulate software in a lightweight and robust way that allows sharing of computational environments. We will give an overview of this technology, look at how it is being currently used by researchers, and discuss possible future implications for the publishing industry, both in terms of how we think about core infrastructure, as well as how we might provide better services to authors and readers.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
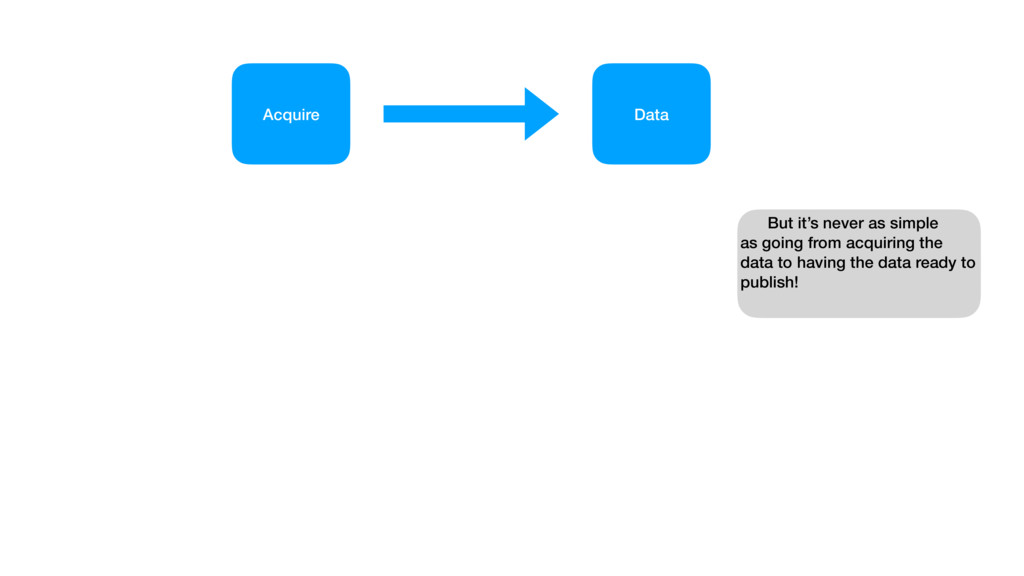{kind=link}
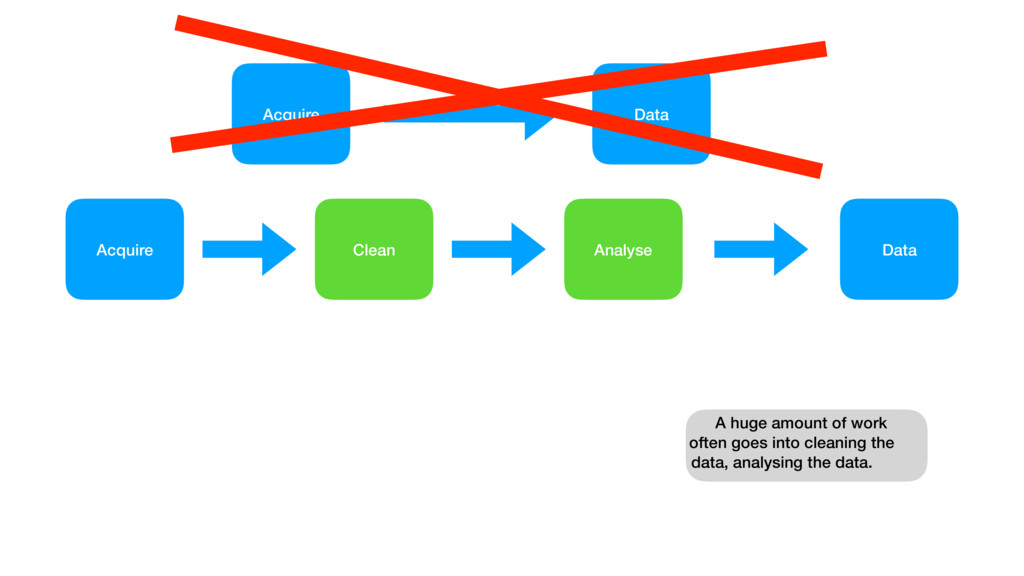{kind=link}
{kind=link}
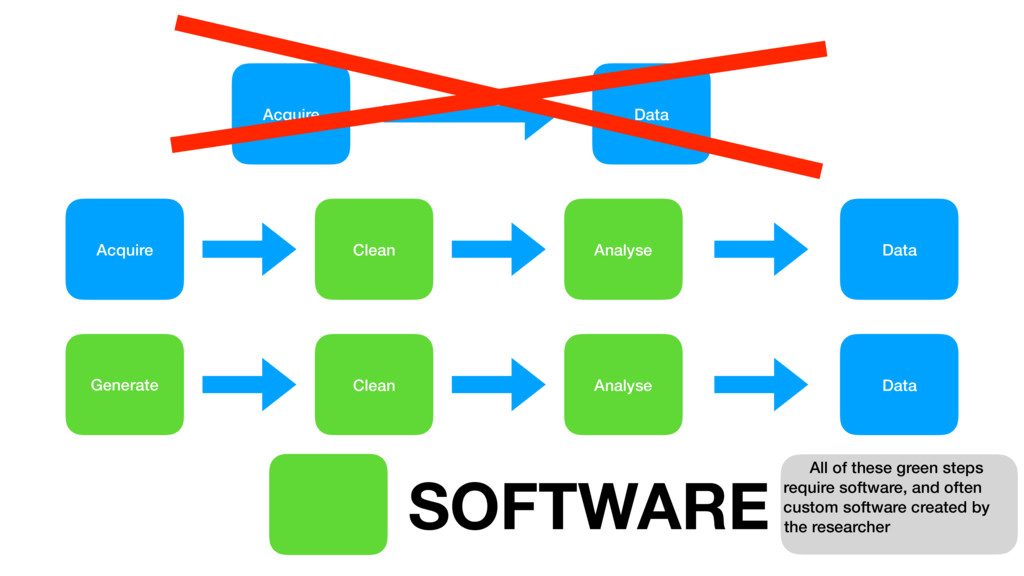{kind=link}
{kind=link}
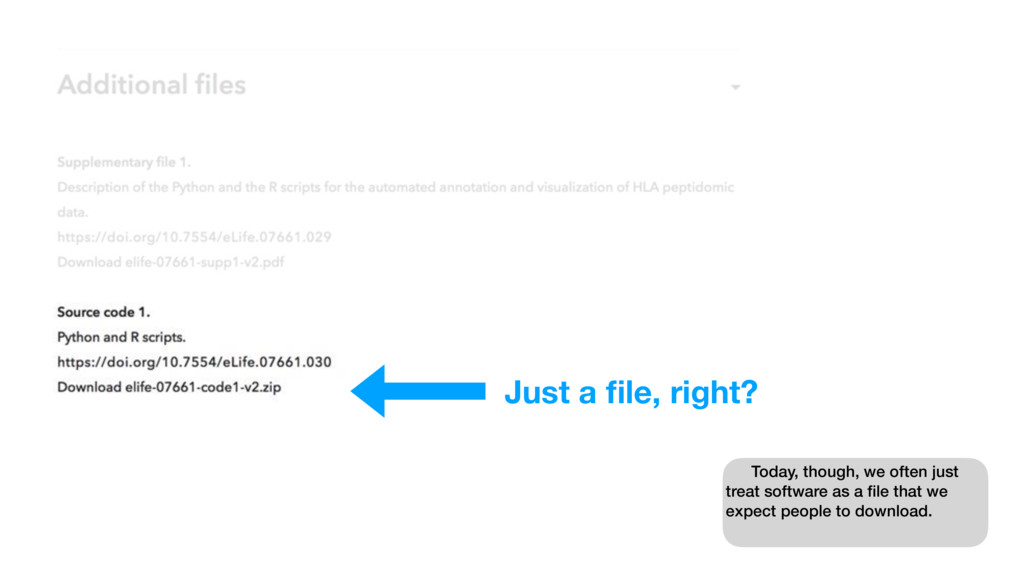{kind=link}
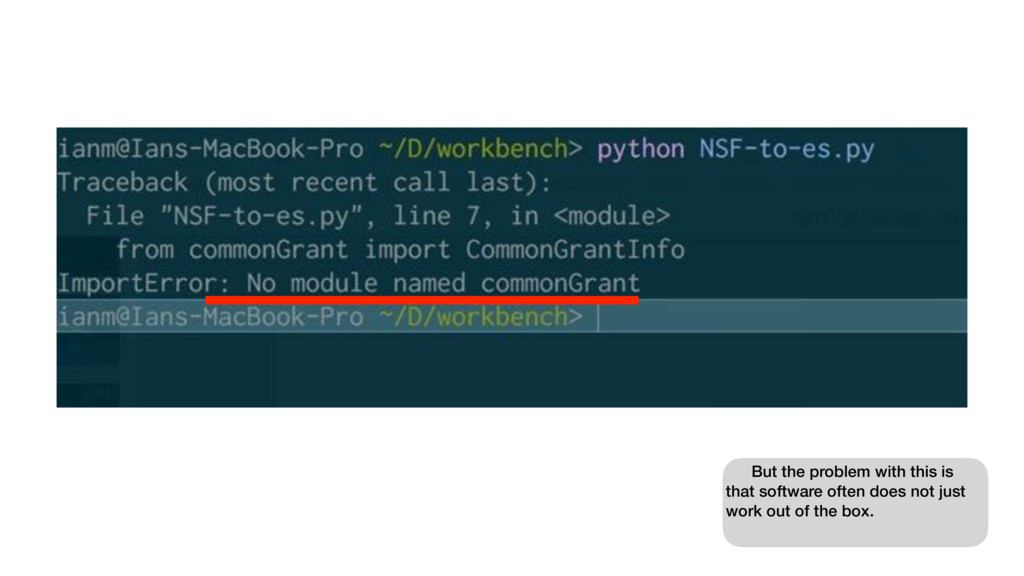{kind=link}
{kind=link}
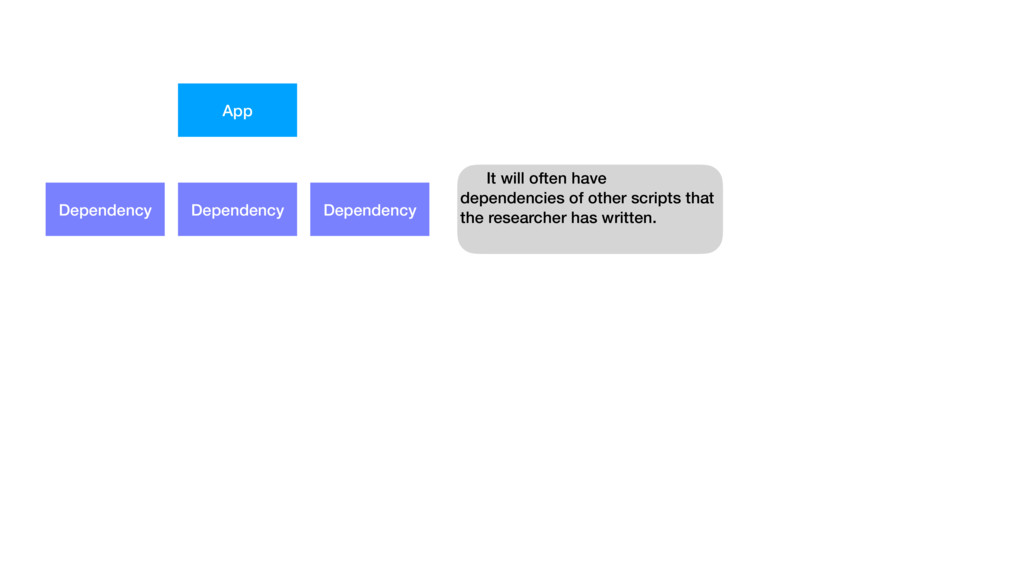{kind=link}
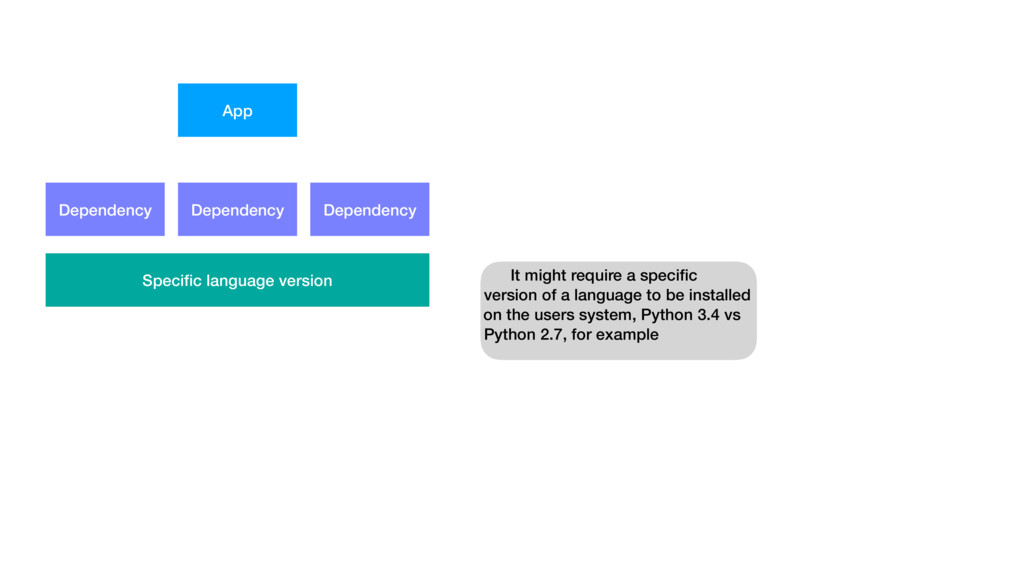{kind=link}
{kind=link}
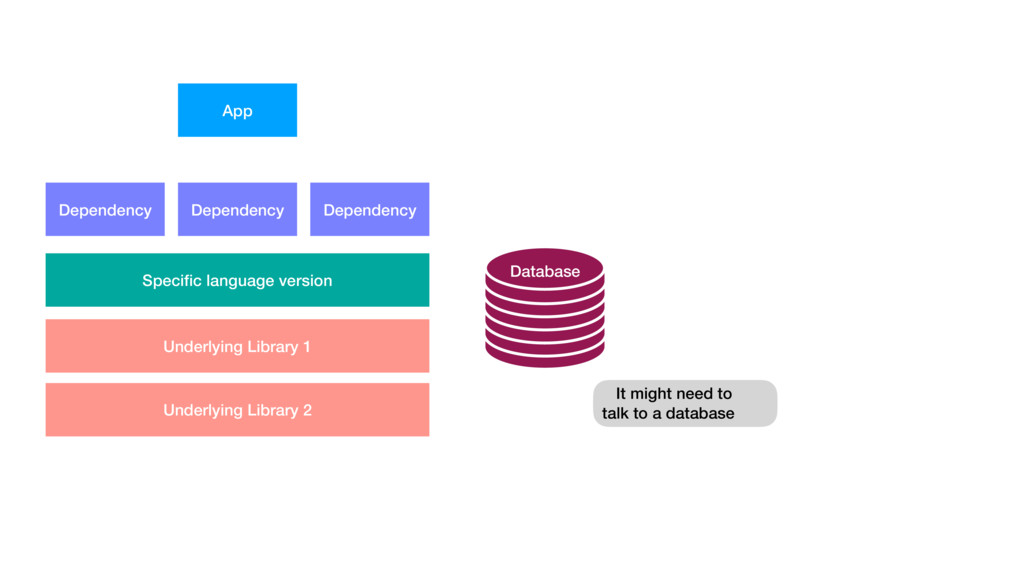{kind=link}
{kind=link}
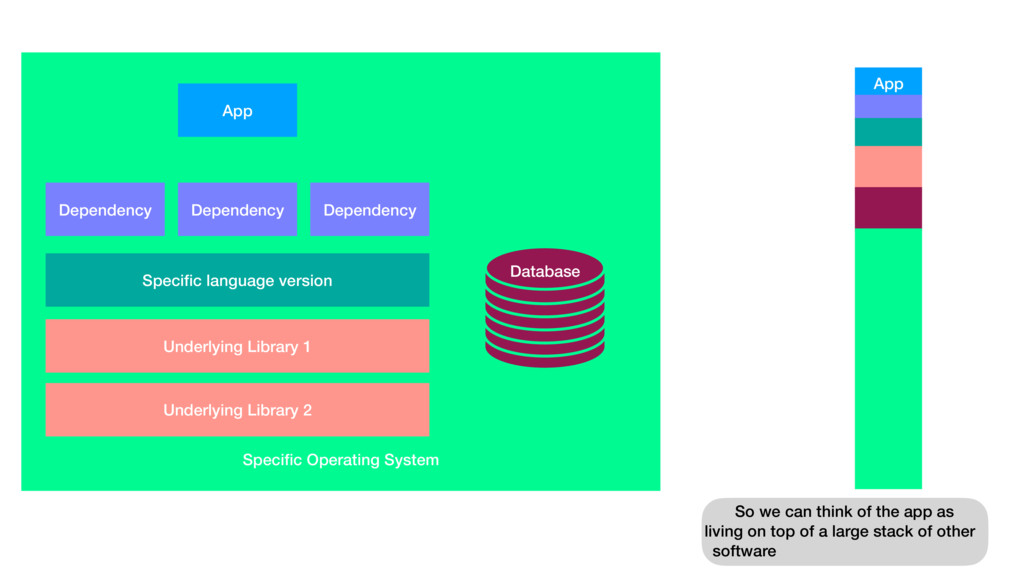{kind=link}
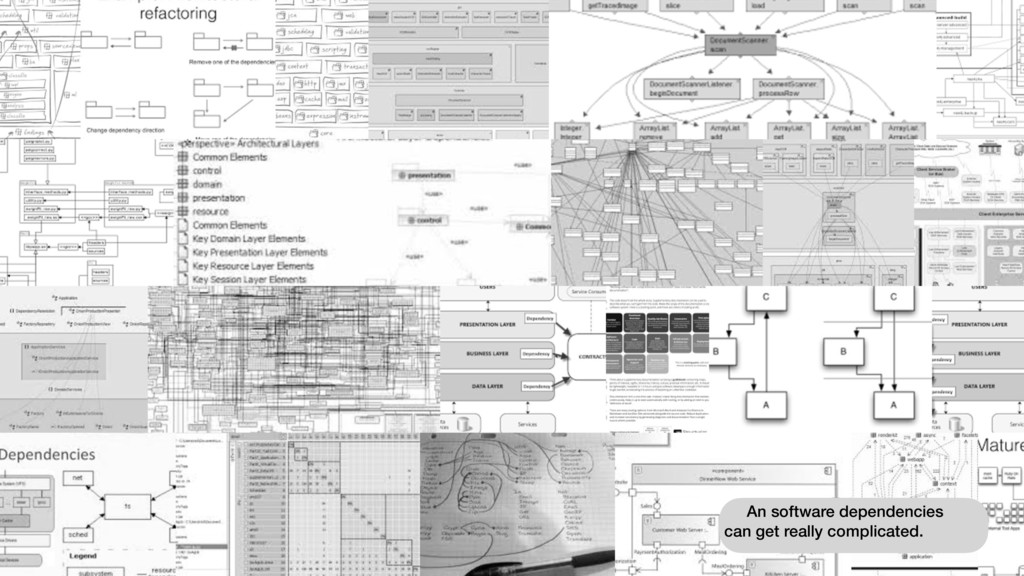{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
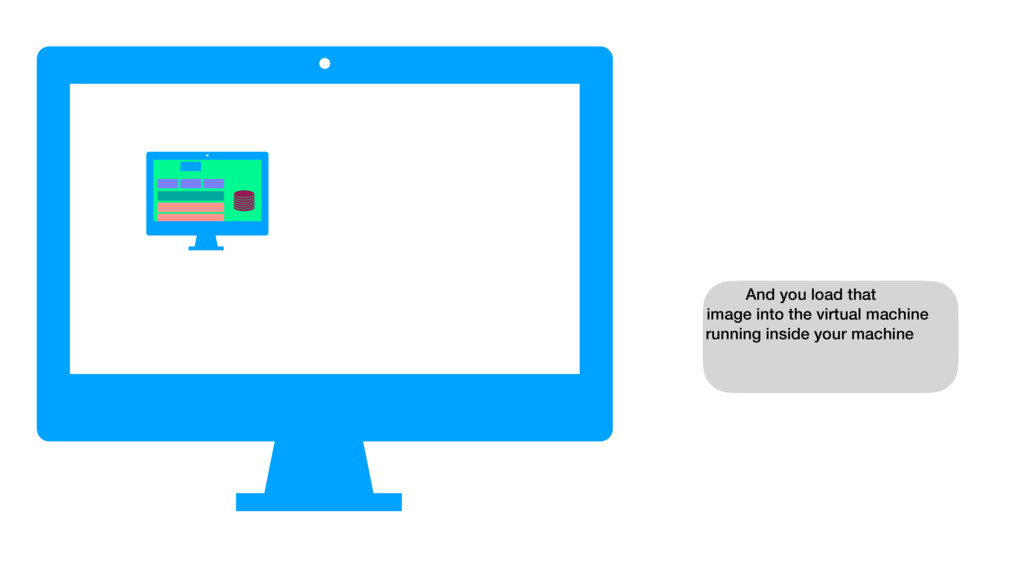{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}