This is an internal talk I delivered as guest speaker for Kongsberg Discovery.
Why and what for do we develop software — or technology in general? What is Continuous Integration really about? What value does the practice of Continuous Deployment bring? And which sociotechnical principles and practices can we rely on to get the most out of it?
I invite you to join me in these (and a few other) reflections — to share, humbly, my real-world experience with Continuous Deployment, including several real examples and some proposals on how to approach it.
I’ll talk about why simplicity (in both technology and business), teamwork, extremely small and safe steps, and fast feedback make all the difference. Let’s forget the technical buzzwords and focus instead on how Lean Software Development and Extreme Programming can be fantastic allies to achieve what truly matters: delivering value continuously, at a sustainable pace… and enjoying the process!
This talk isn’t just for programmers — it’s for anyone curious about exploring other ways of doing things, beyond the mainstream (with no evangelizing intent, only the wish to share experiences 😉).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
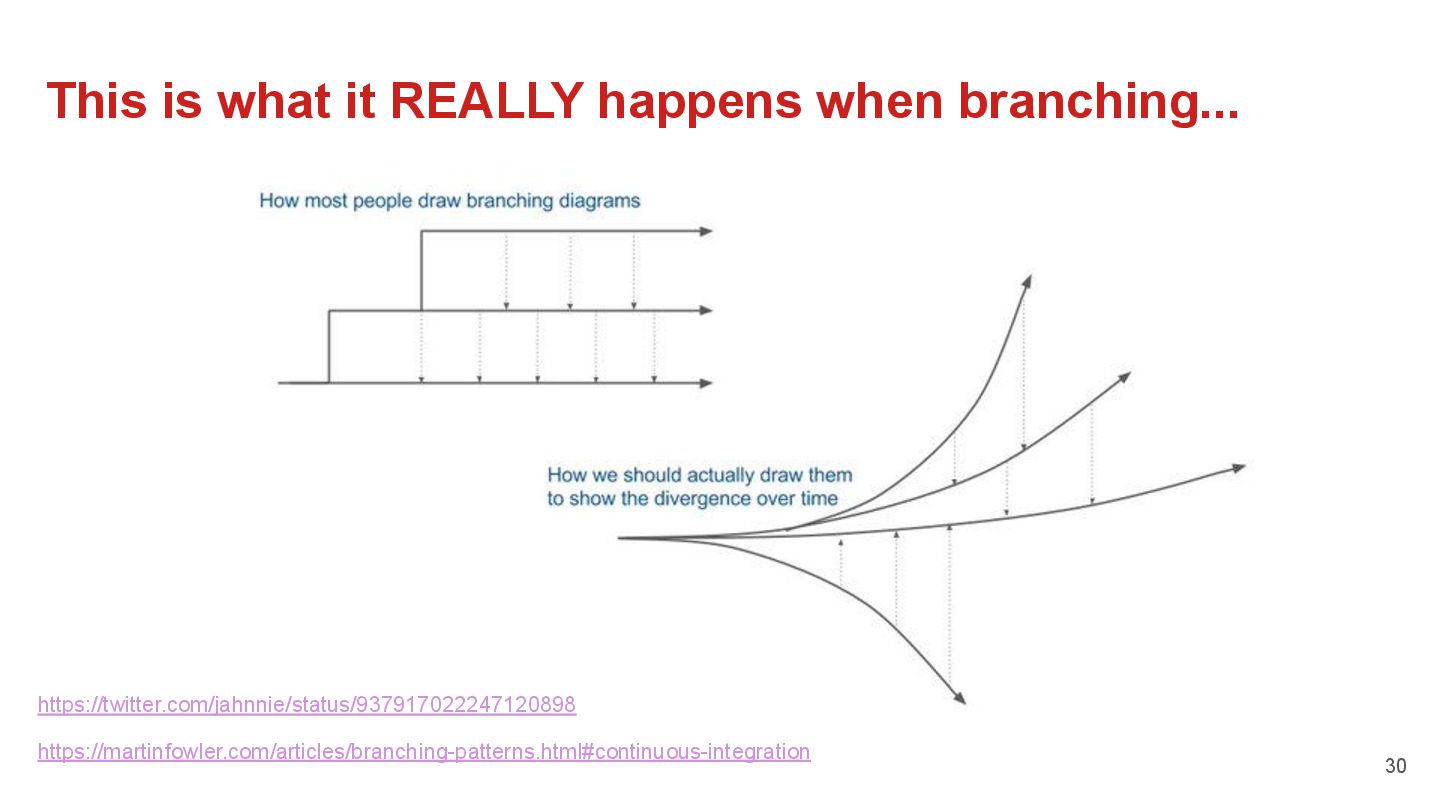{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
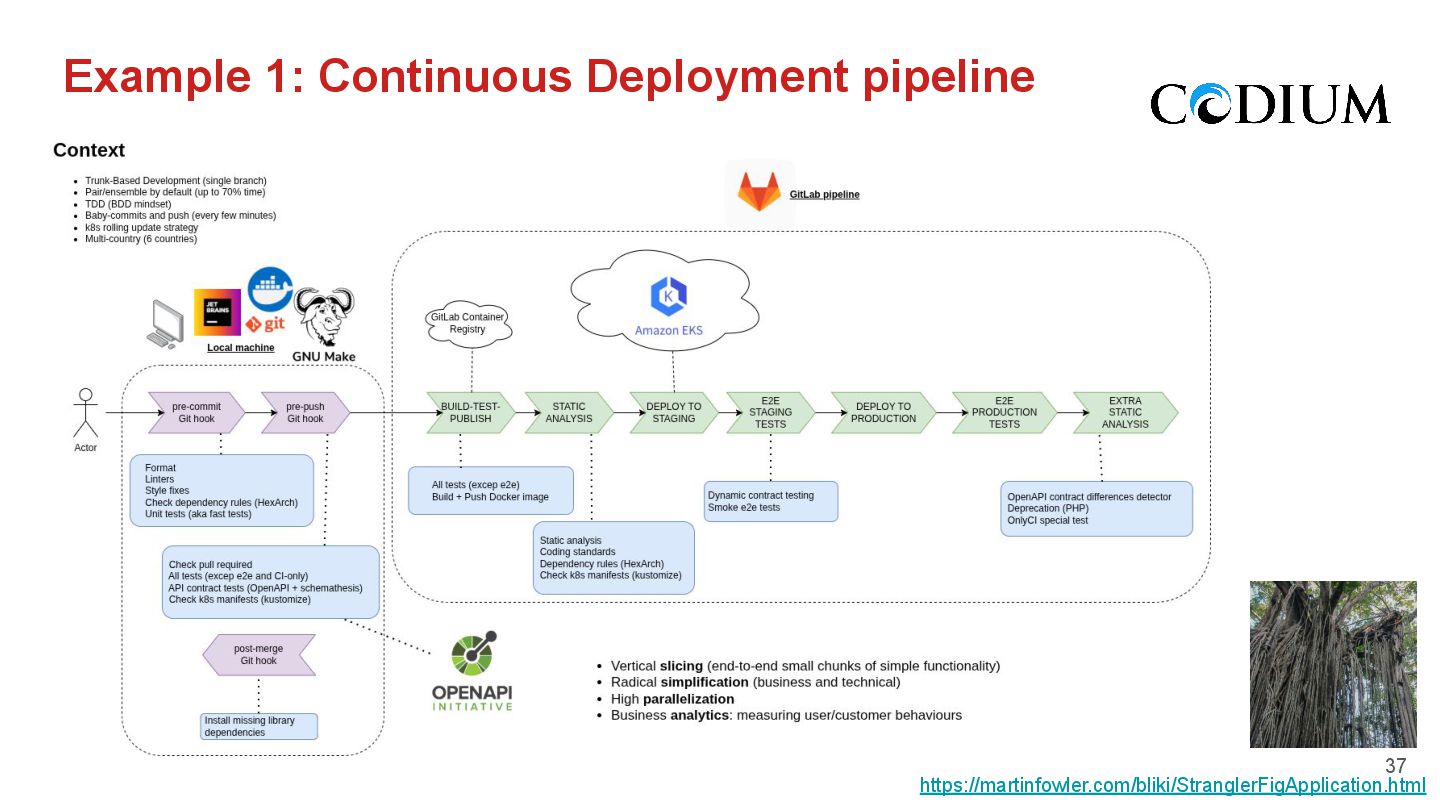{kind=link}
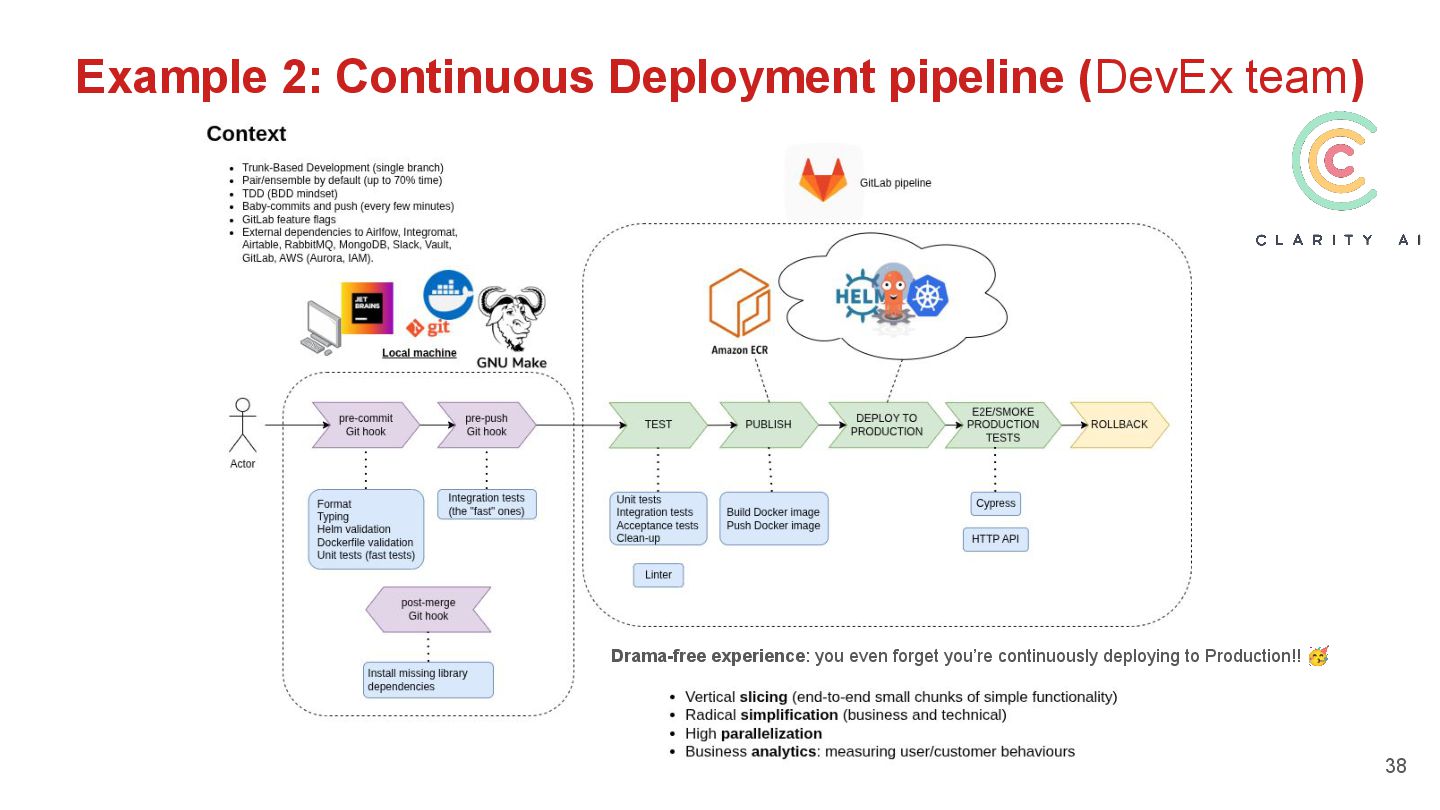{kind=link}
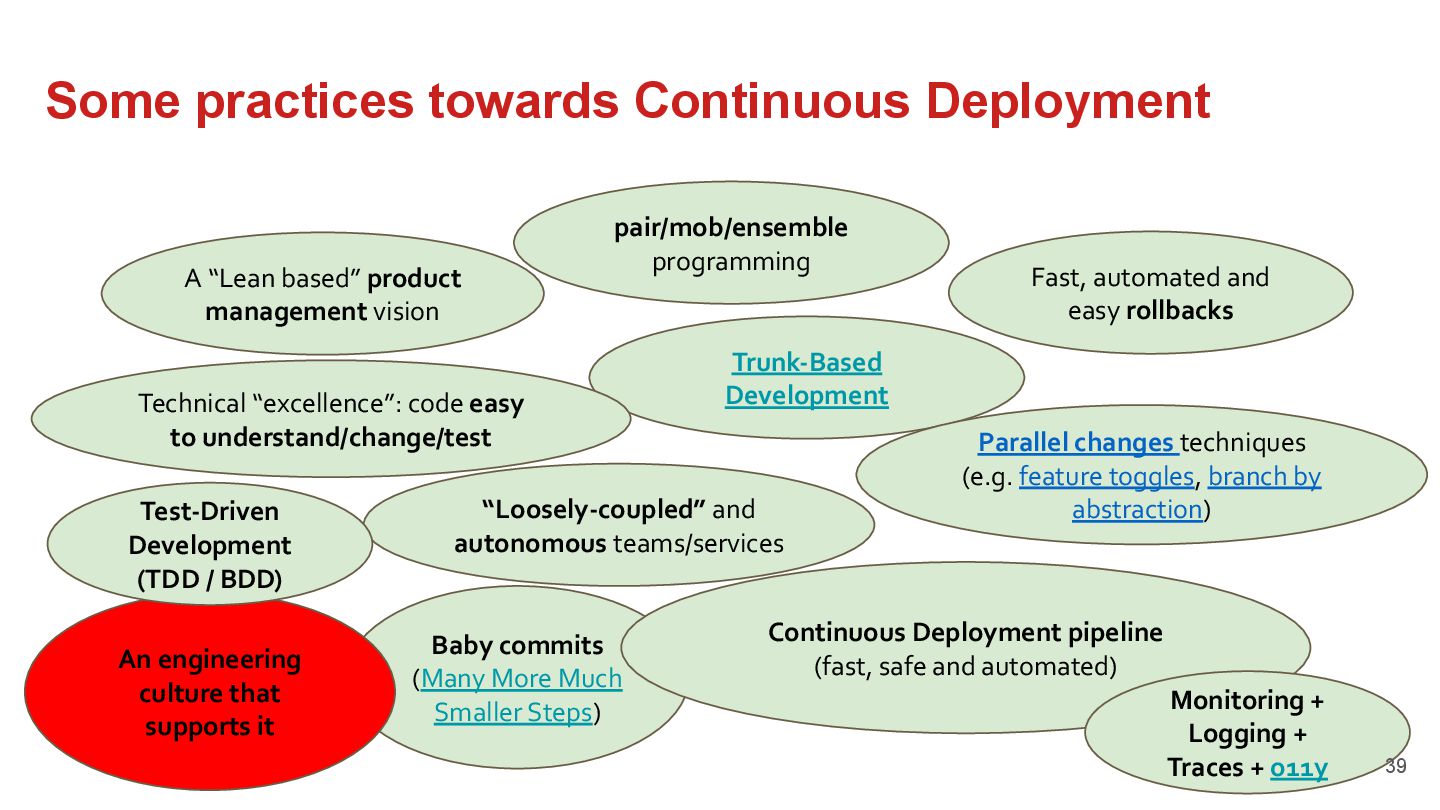{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}