네, 사용합니다. • 내용: Google AI Studio나 Gemini API의 무료 할당량(Unpaid quota)을 사용할 경우, Google은 제출된 콘텐츠와 생성된 응답을 사용하여 Google의 제품, 서비스 및 머신러닝 기술을 개선하고 개발합니다. • 주의사항: 품질 개선을 위해 사람(검토자)이 데이터를 읽거나 주석을 달 수 있으므로, 민감하거나 개인적인 정보를 제출하지 말 것을 권고하고 있습니다. https://ai.google.dev/gemini-api/terms#data-use-paid 8
아니요, 사용하지 않습니다. • 내용: Cloud Billing 계정을 활성화하여 유료로 서비스를 이용하는 경우, Google은 사용자의 프롬프트나 응답을 제품 개선(학습)에 사용하지 않습니다. • 예외: 유료 서비스의 데이터는 '금지된 사용 정책' 위반을 감지하거나 법적/규제적 공개 요구를 위해서만 제한된 기간 동안 일시적으로 저장 (로그)됩니다. https://ai.google.dev/gemini-api/terms#data-use-paid 9
a focus on efficiency, Gemma 3n models are available in two sizes based on effective parameters: E2B and E4B. While their raw parameter count is 5B and 8B respectively, architectural innovations allow them to run with a memory footprint comparable to traditional 2B and 4B models, operating with as little as 2GB (E2B) and 3GB (E4B) of memory. 28
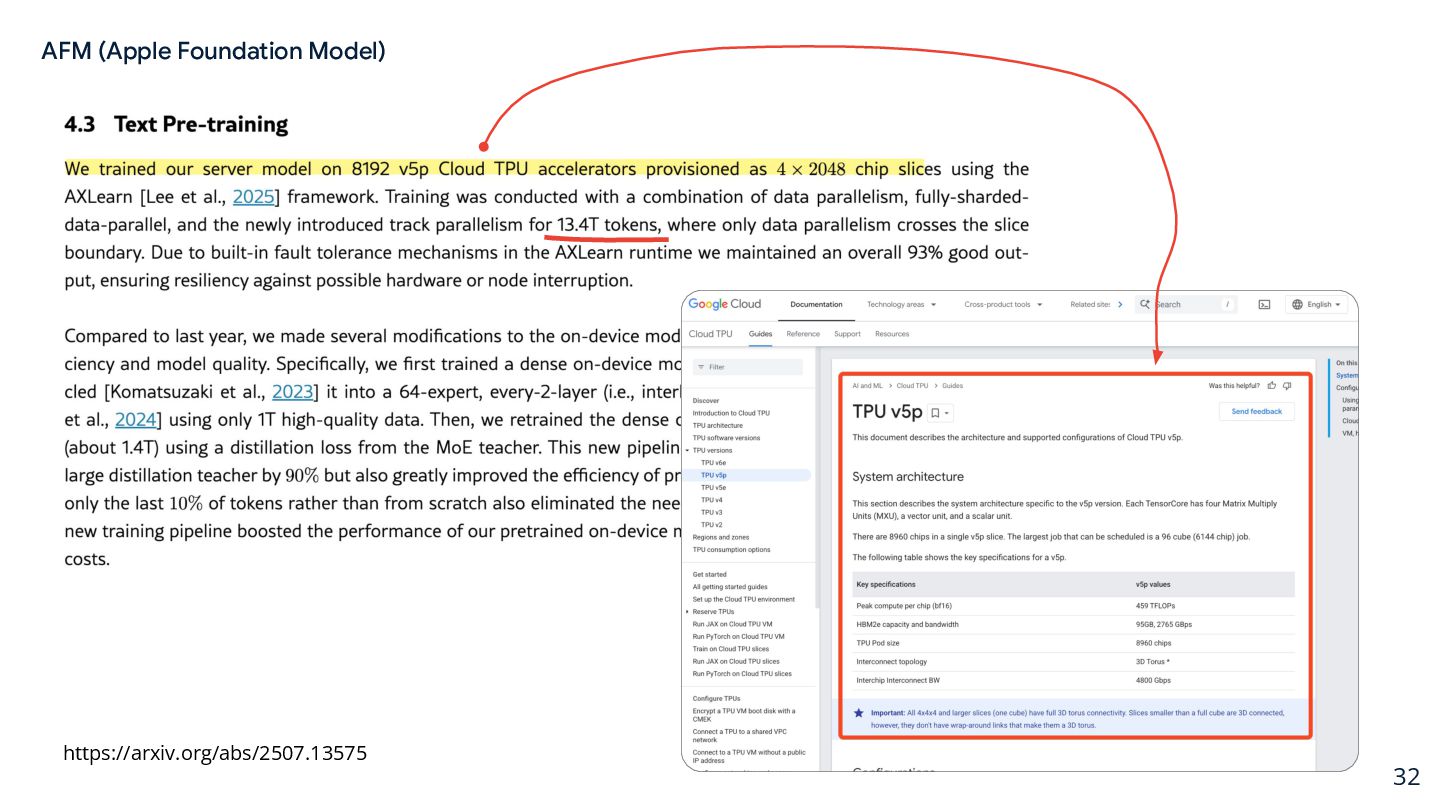
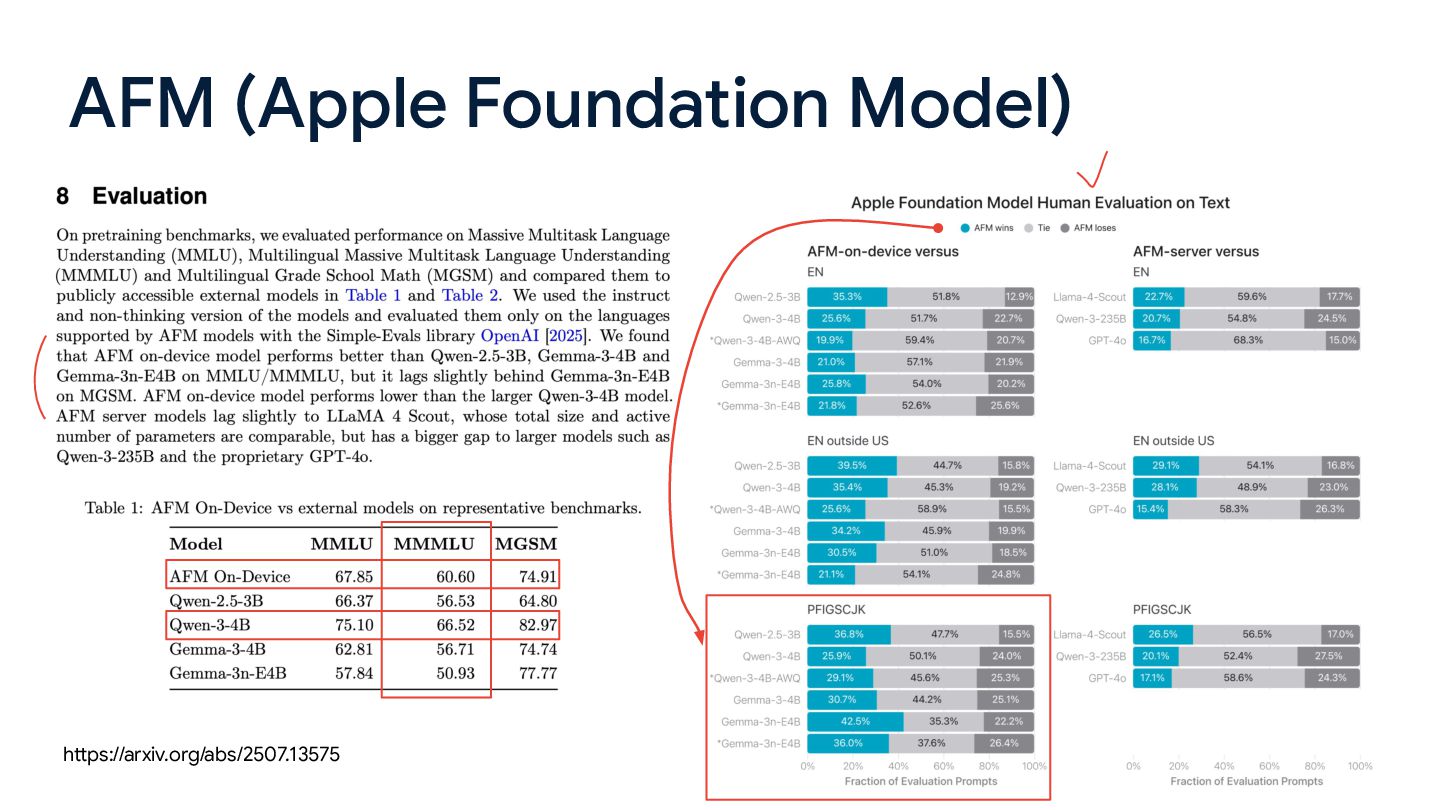
innovations such as KV-cache sharing and 2-bit quantization-aware training; The context window size: the system model supports up to 4,096 tokens https://arxiv.org/abs/2507.13575 AFM (Apple Foundation Model)
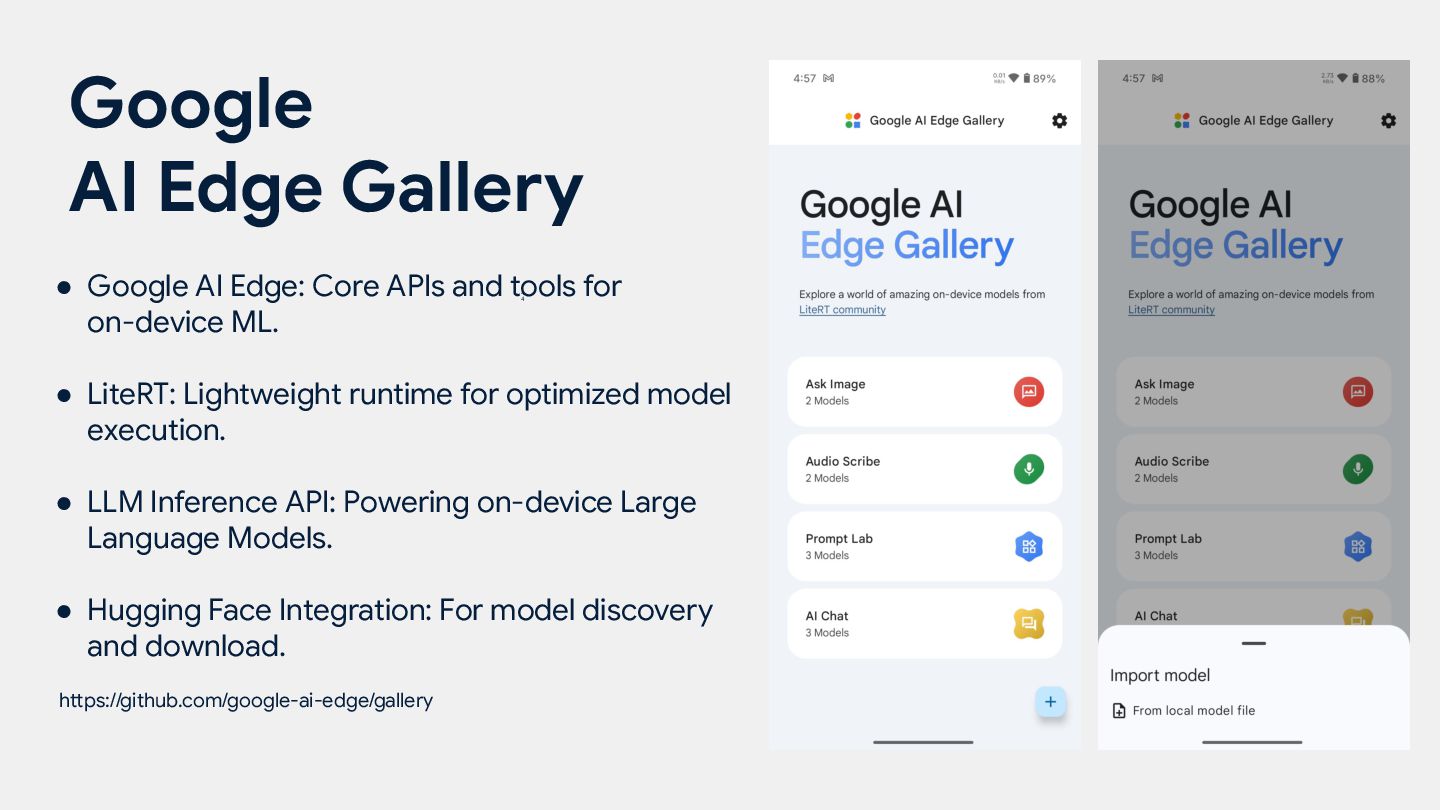
ML. • LiteRT: Lightweight runtime for optimized model execution. • LLM Inference API: Powering on-device Large Language Models. • Hugging Face Integration: For model discovery and download. https://github.com/google-ai-edge/gallery Google AI Edge Gallery 4 4
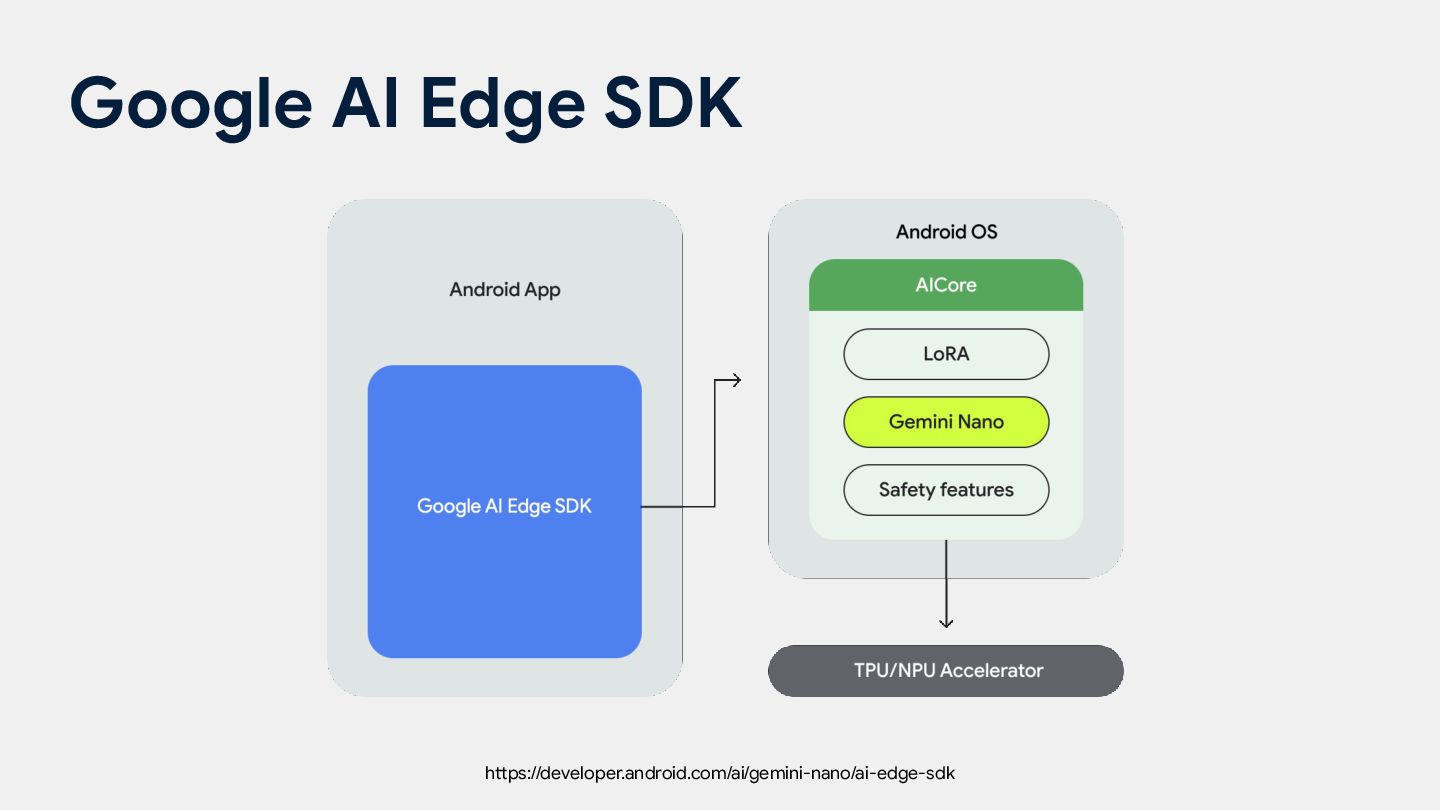
생성형 AI 경험 제공 가능 • Android의 AICore 시스템 서비스 내에서 실행 ◦ 이 서비스는 기기 하드웨어를 활용하여 추론 지연 시간(latency)을 낮추고 모델을 최신 상태로 유지 • ML Kit GenAI API ◦ 요약, 교정, 재작성, 이미지 설명 등 사용 사례별 API를 위한 상위 수준의 인터페이스를 제공하며, 유연한 활용을 위한 하위 수준의 프롬프트 API(Prompt API) 제공 https://developer.android.com/ai/gemini-nano 46
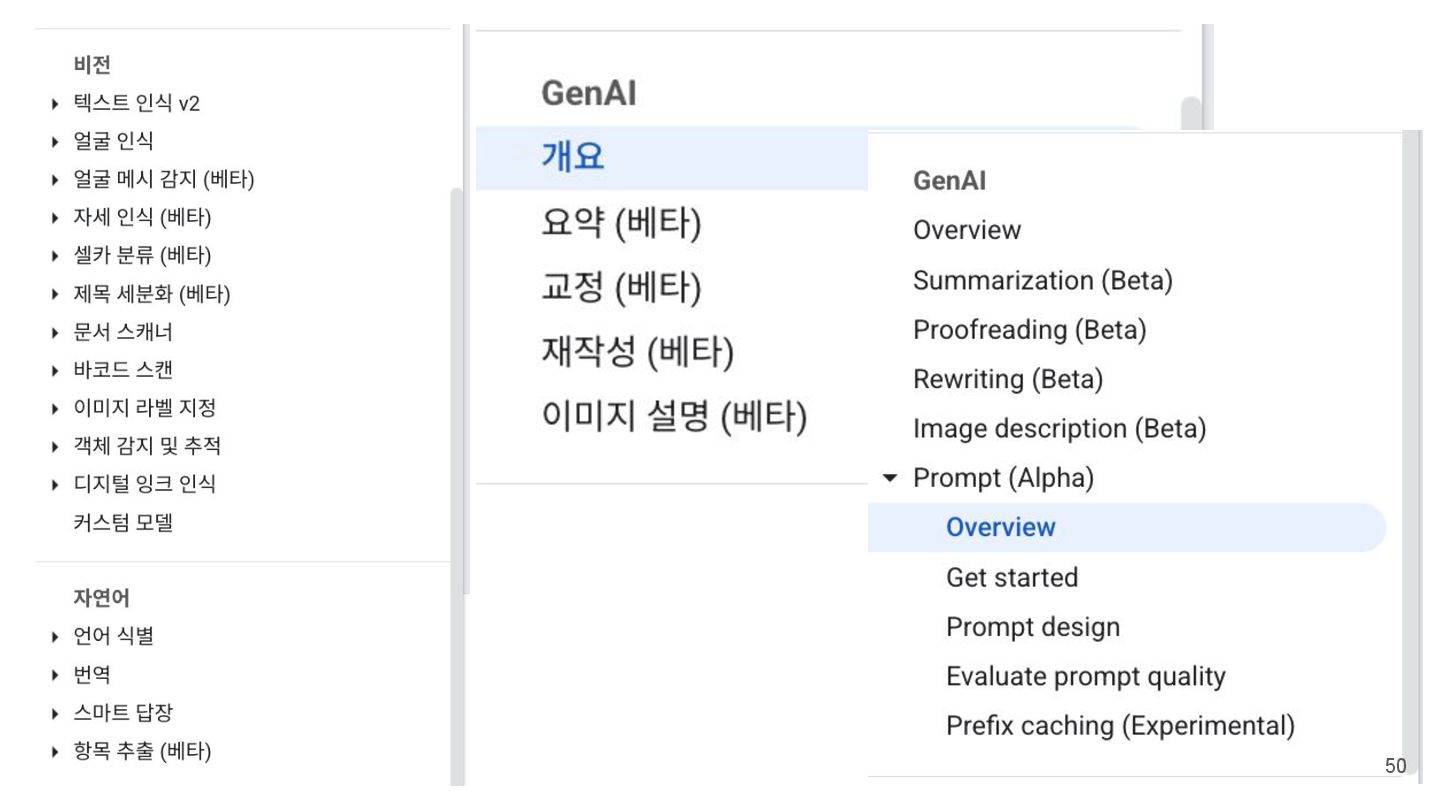
또는 채팅 대화를 글머리기호 목록으로 요약합니다. ◦ 교정: 문법을 다듬고 맞춤법 오류를 수정하여 짧은 콘텐츠를 다듬습니다. ◦ 재작성: 짧은 메시지를 다양한 어조나 스타일로 다시 작성합니다. ◦ 이미지 설명: 주어진 이미지에 대한 간단한 설명을 생성합니다. ◦ 프롬프트 : 맞춤 텍스트 전용 또는 멀티모달 프롬프트를 기반으로 텍스트 콘텐츠를 생성합니다. https://developer.android.com/ai/gemini-nano/ml-kit-genai https://developers.google.com/ml-kit/genai?hl=ko 47
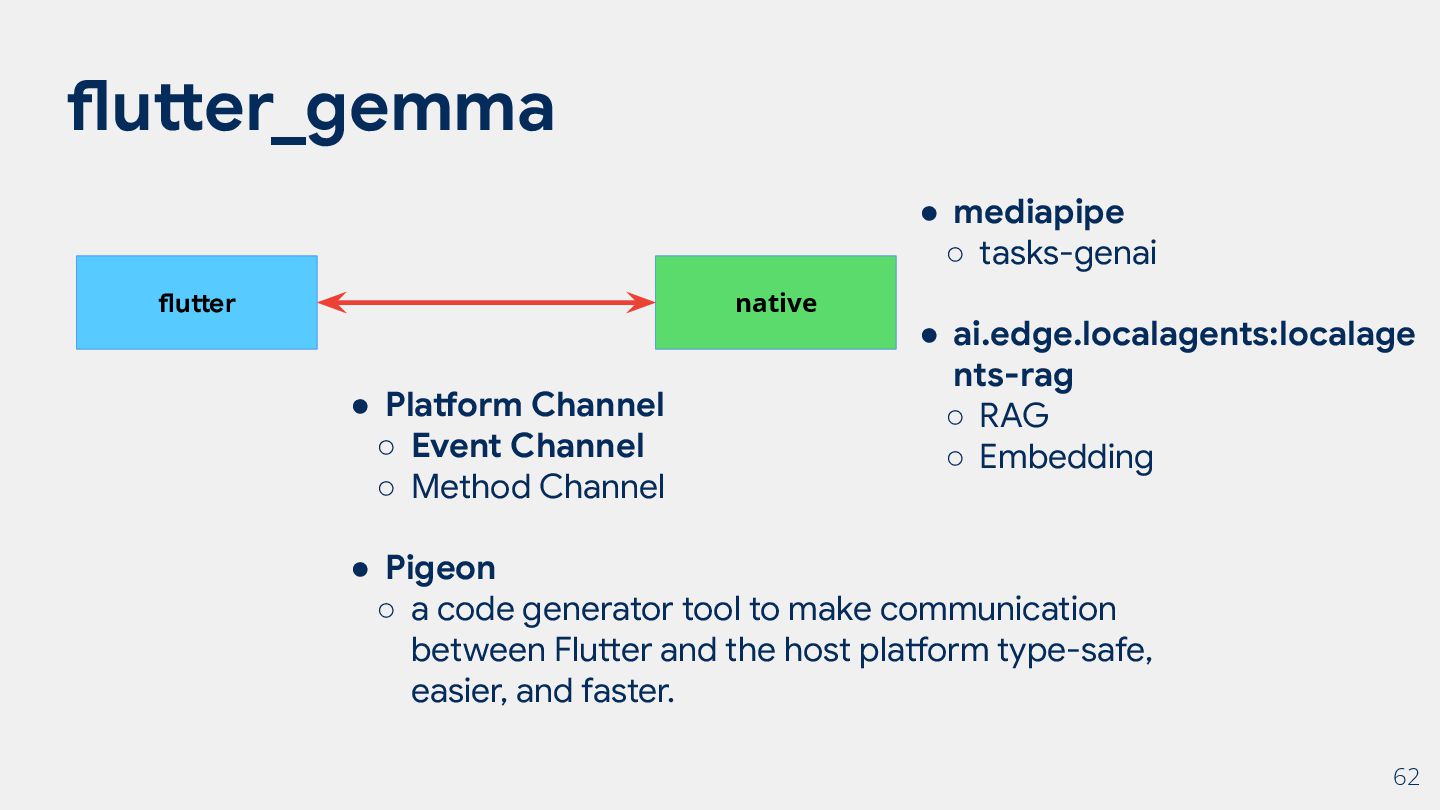
◦ Method Channel • Pigeon ◦ a code generator tool to make communication between Flutter and the host platform type-safe, easier, and faster. • mediapipe ◦ tasks-genai • ai.edge.localagents:localage nts-rag ◦ RAG ◦ Embedding
description: 'Changes the title of the app in the AppBar. Provide a new title text.', parameters: { 'type': 'object', 'properties': { 'title': { 'type': 'string', 'description': 'The new title text to display in the AppBar', }, }, 'required': ['title'], }, ), ];
), messages: [ ChatMessage(content: 'You are a helpful assistant.', role: "system"), ChatMessage(content: 'Hi, how are you?', role: "user") ], ); await for (final chunk in streamedResult.stream) { debugPrint("chunk: $chunk") }
@escaping FlutterResult) { // 문서에 따른 가용성 확인 let model = SystemLanguageModel.default if case .available = model.availability { result(true) } else { result(false) } }
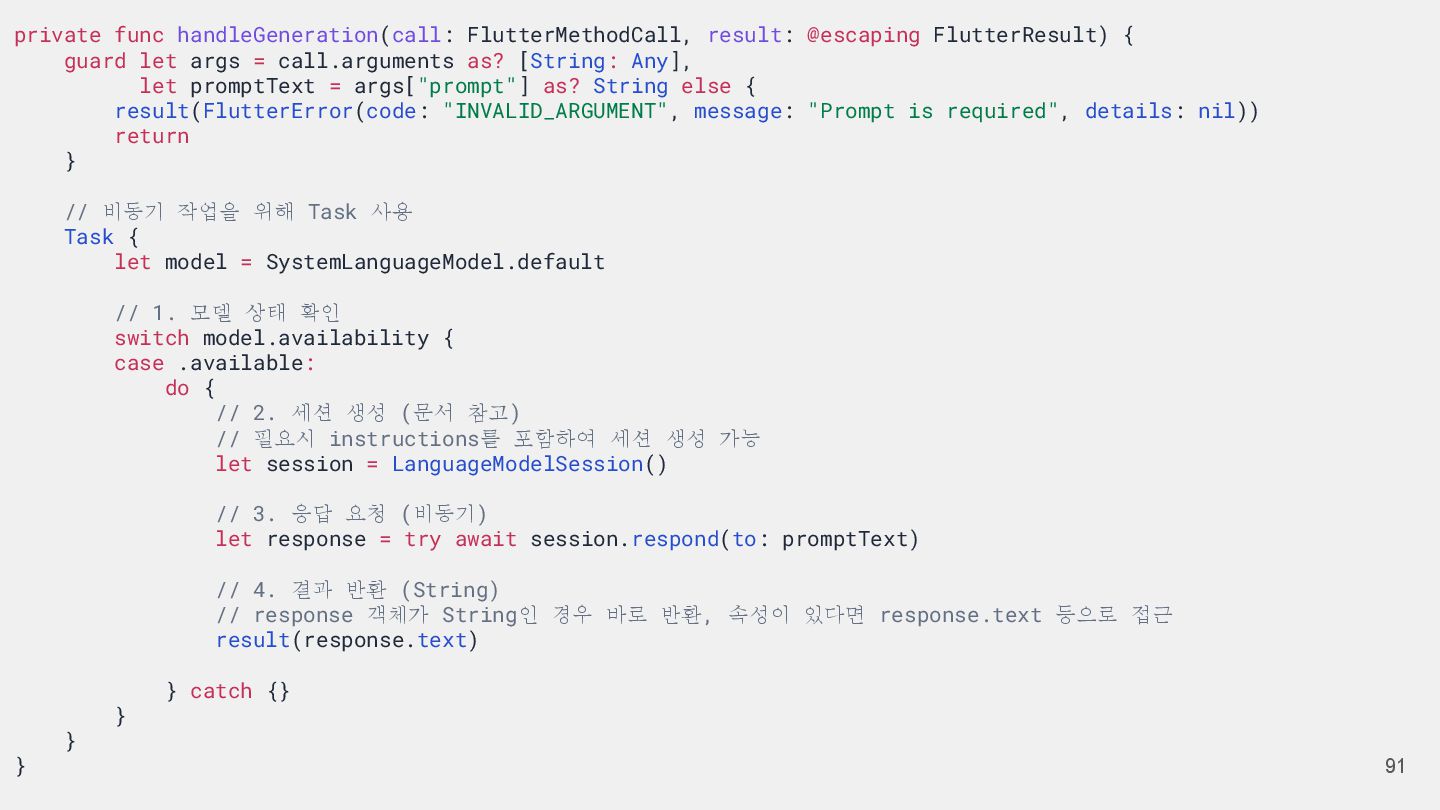
let args = call.arguments as? [String: Any], let promptText = args["prompt"] as? String else { result(FlutterError(code: "INVALID_ARGUMENT", message: "Prompt is required", details: nil)) return } // 비동기 작업을 위해 Task 사용 Task { let model = SystemLanguageModel.default // 1. 모델 상태 확인 switch model.availability { case .available: do { // 2. 세션 생성 (문서 참고) // 필요시 instructions를 포함하여 세션 생성 가능 let session = LanguageModelSession() // 3. 응답 요청 (비동기) let response = try await session.respond(to: promptText) // 4. 결과 반환 (String) // response 객체가 String인 경우 바로 반환, 속성이 있다면 response.text 등으로 접근 result(response.text) } catch {} } } }
{kind=link}
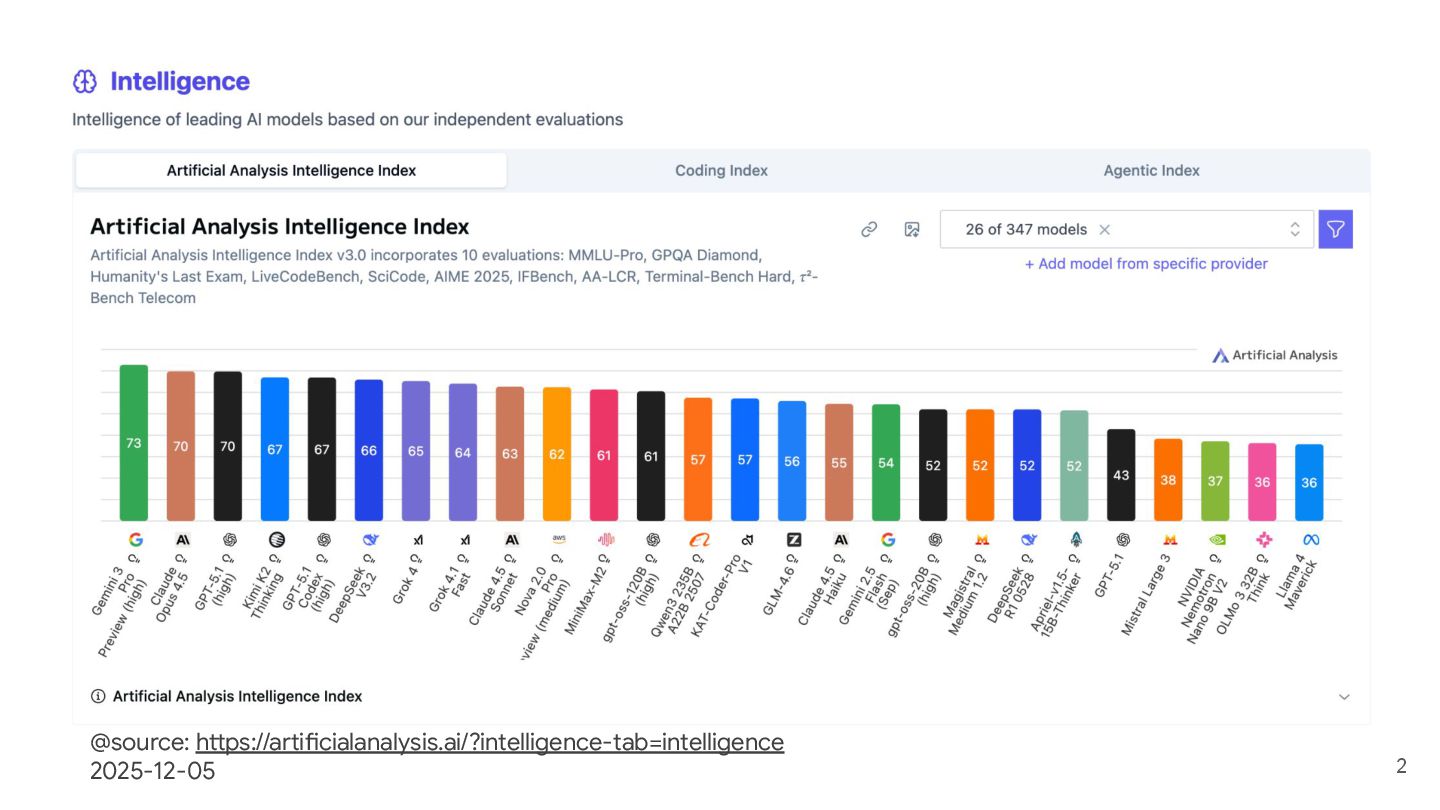{kind=link}
{kind=link}
{kind=link}
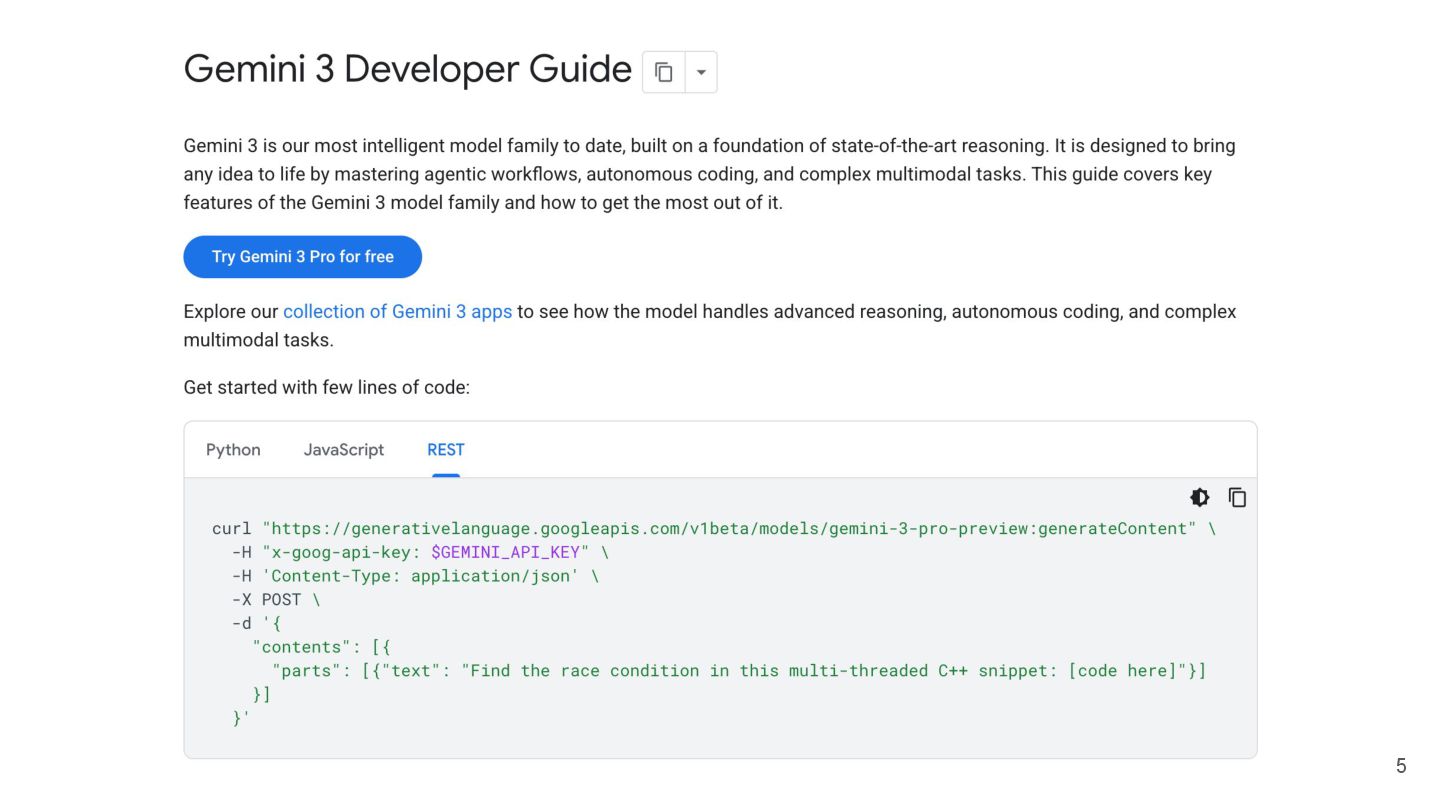{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
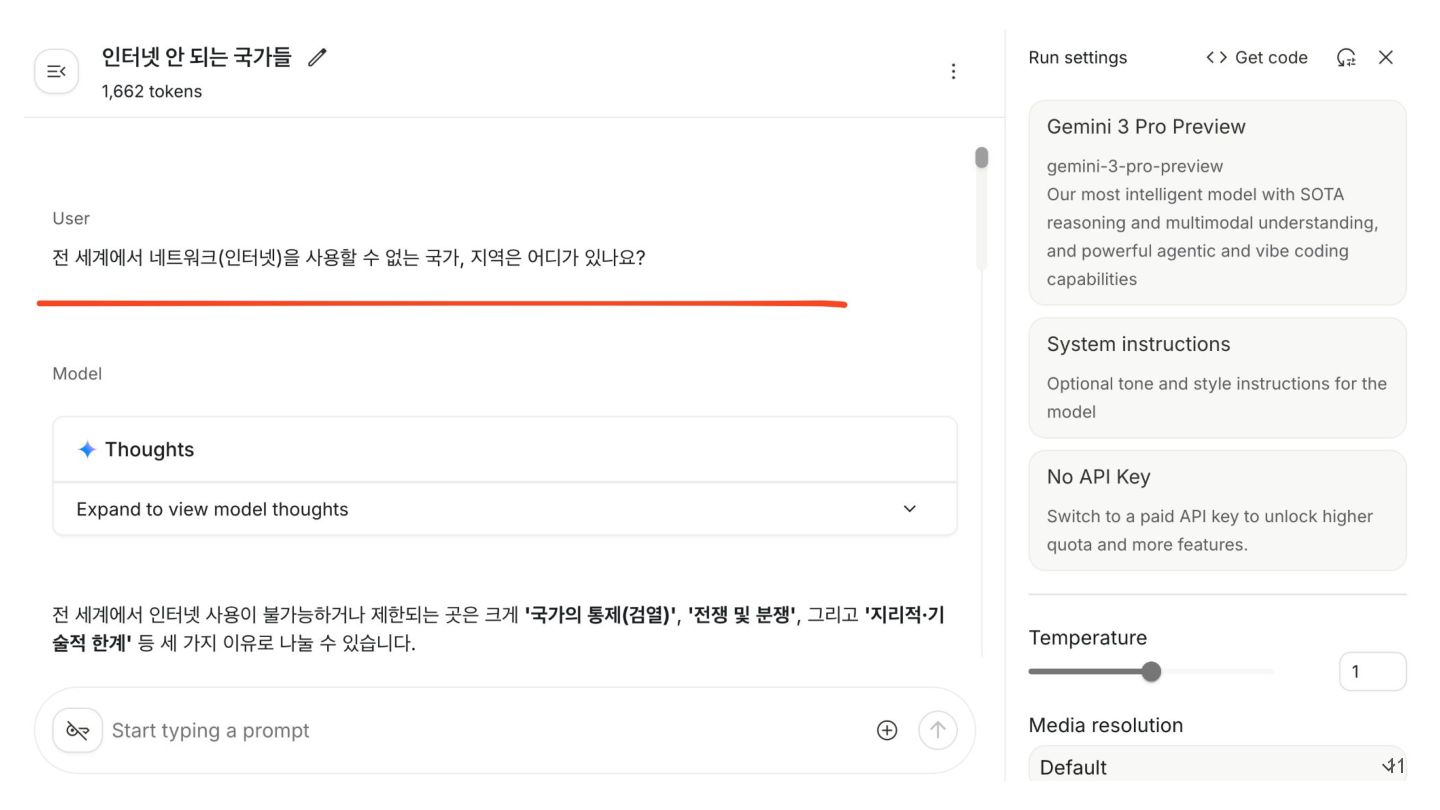{kind=link}
{kind=link}
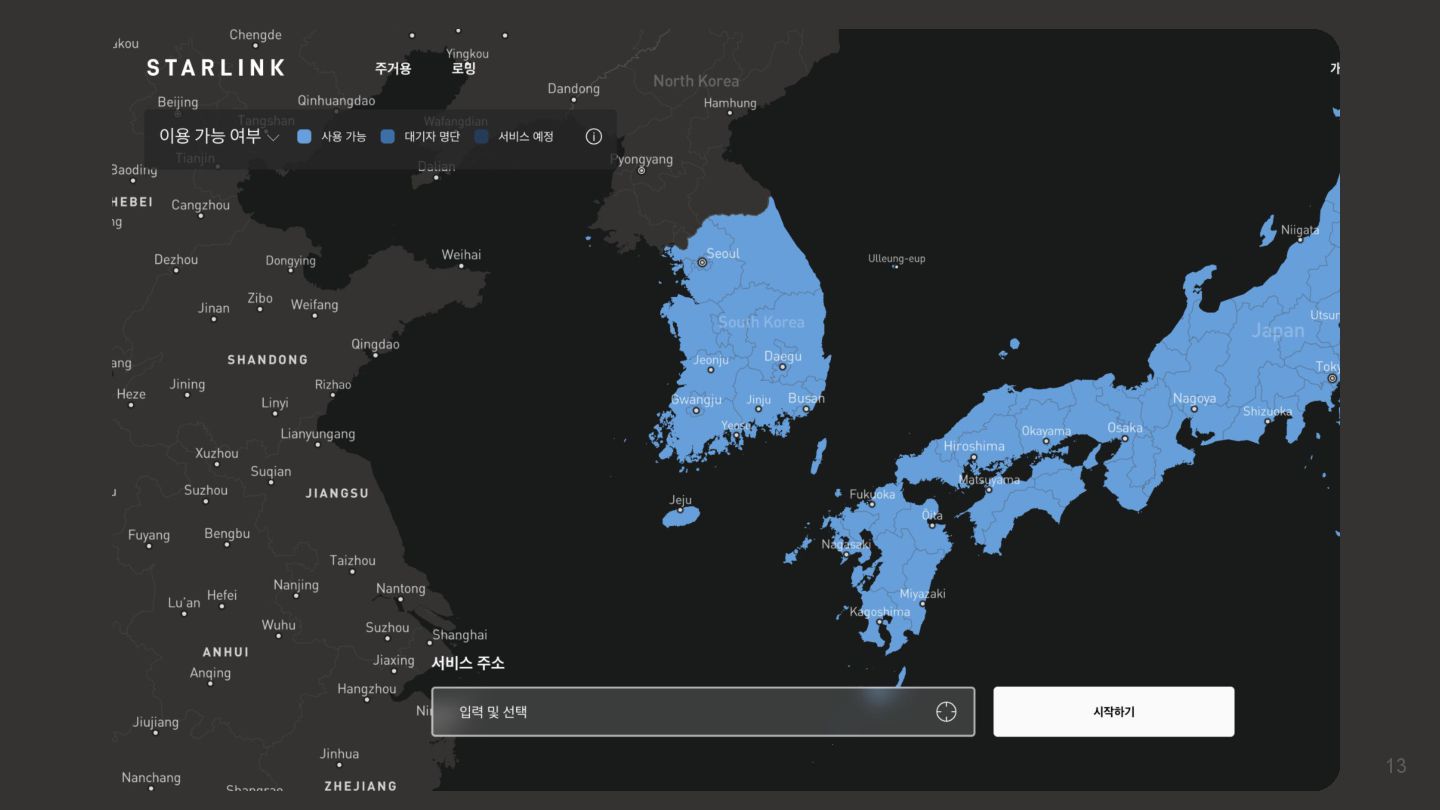{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
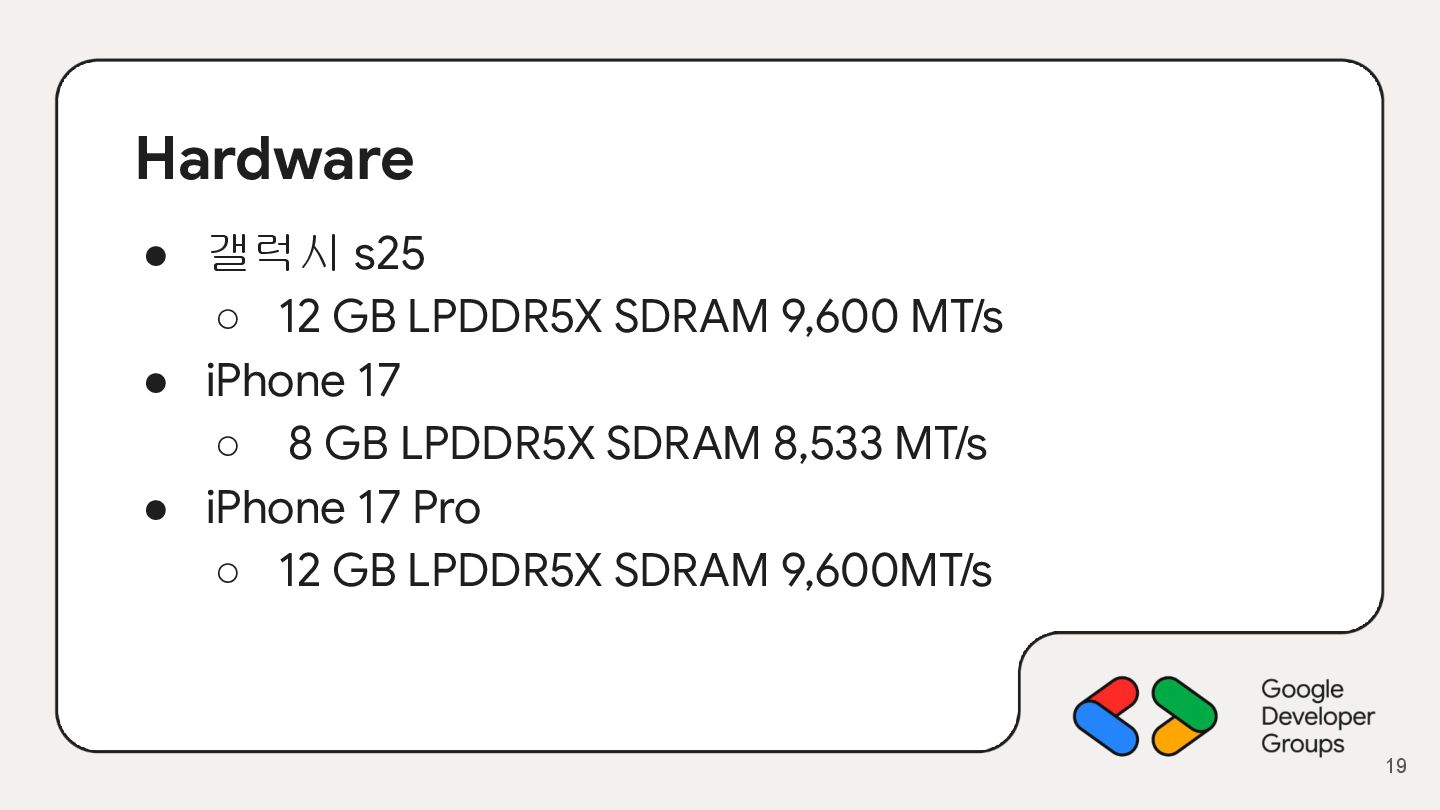{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
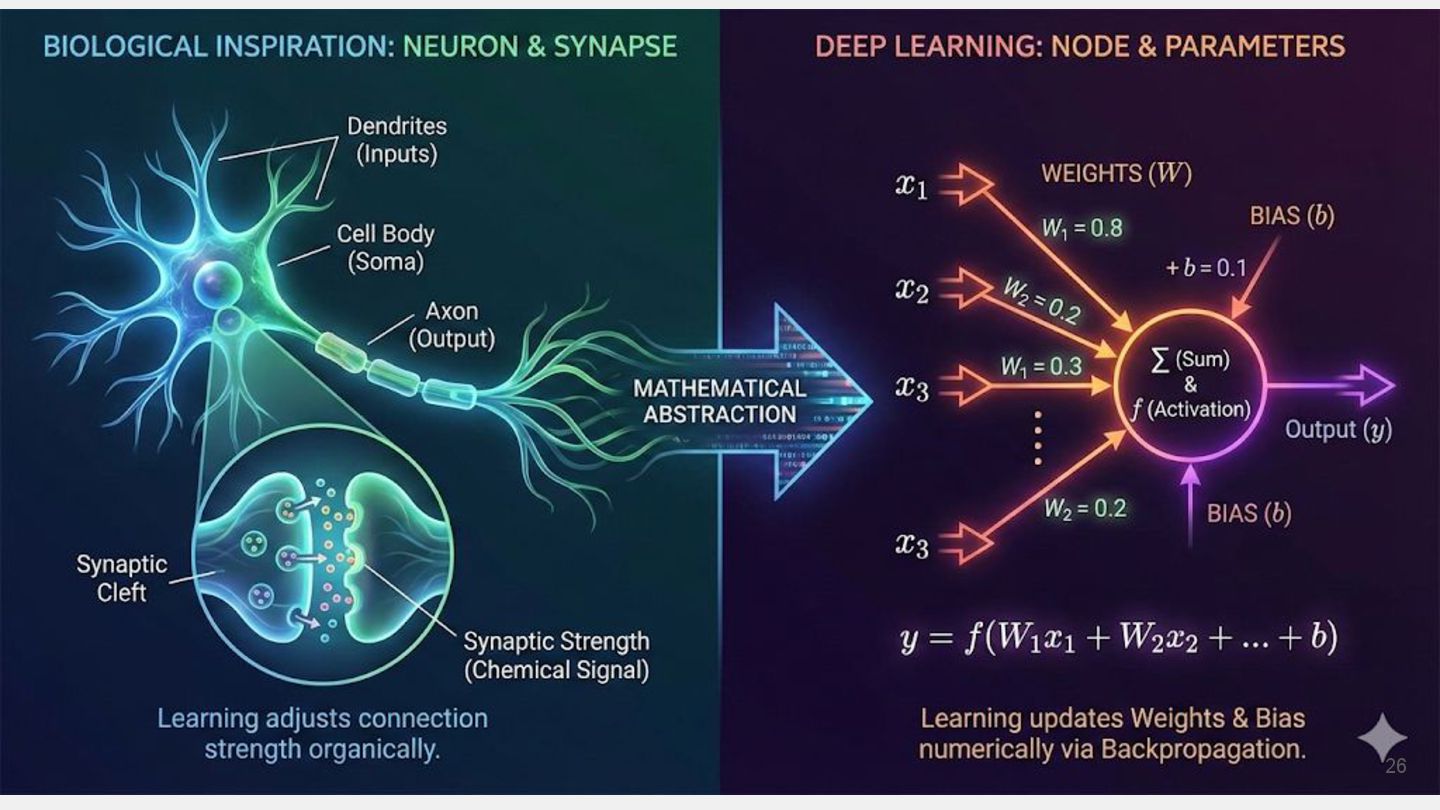{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
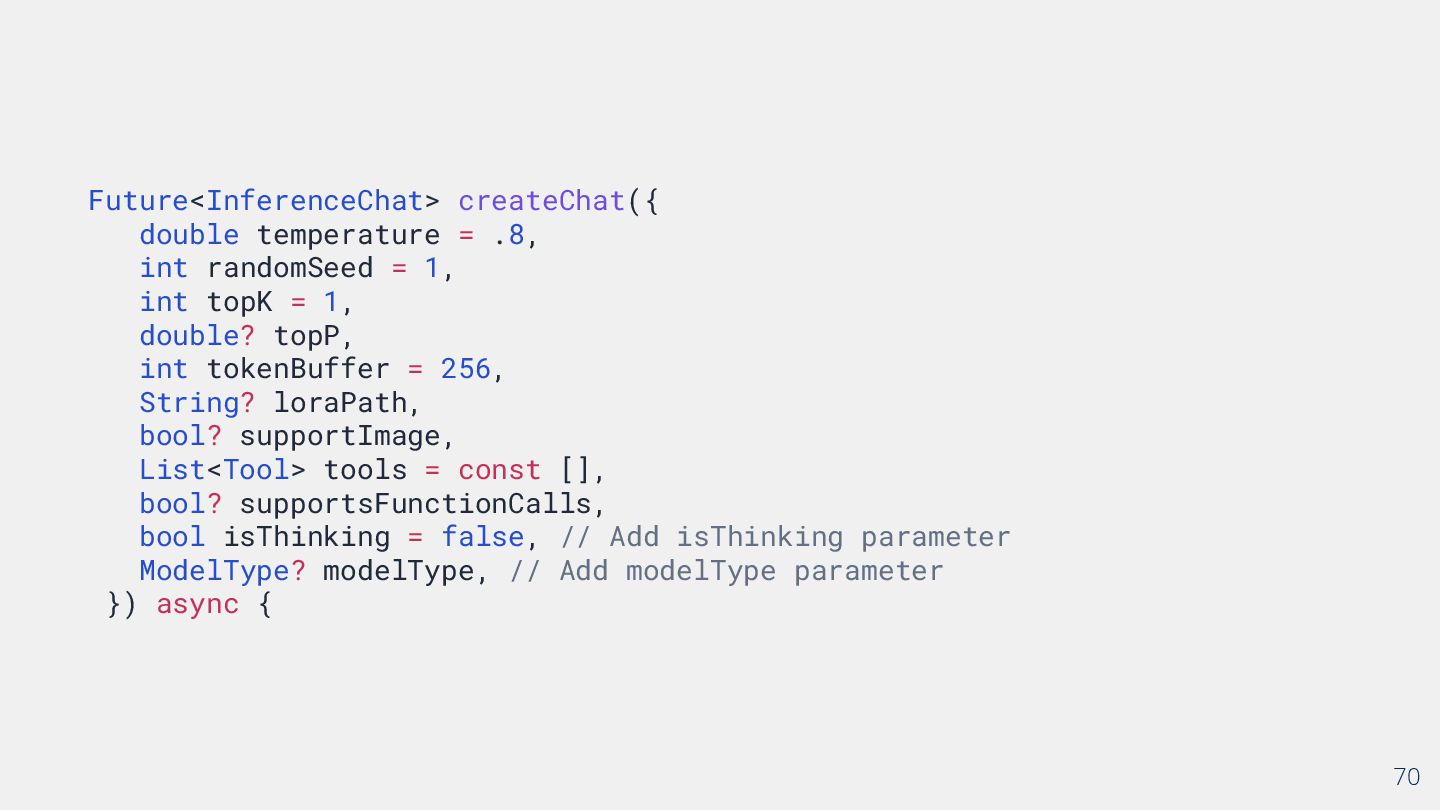{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
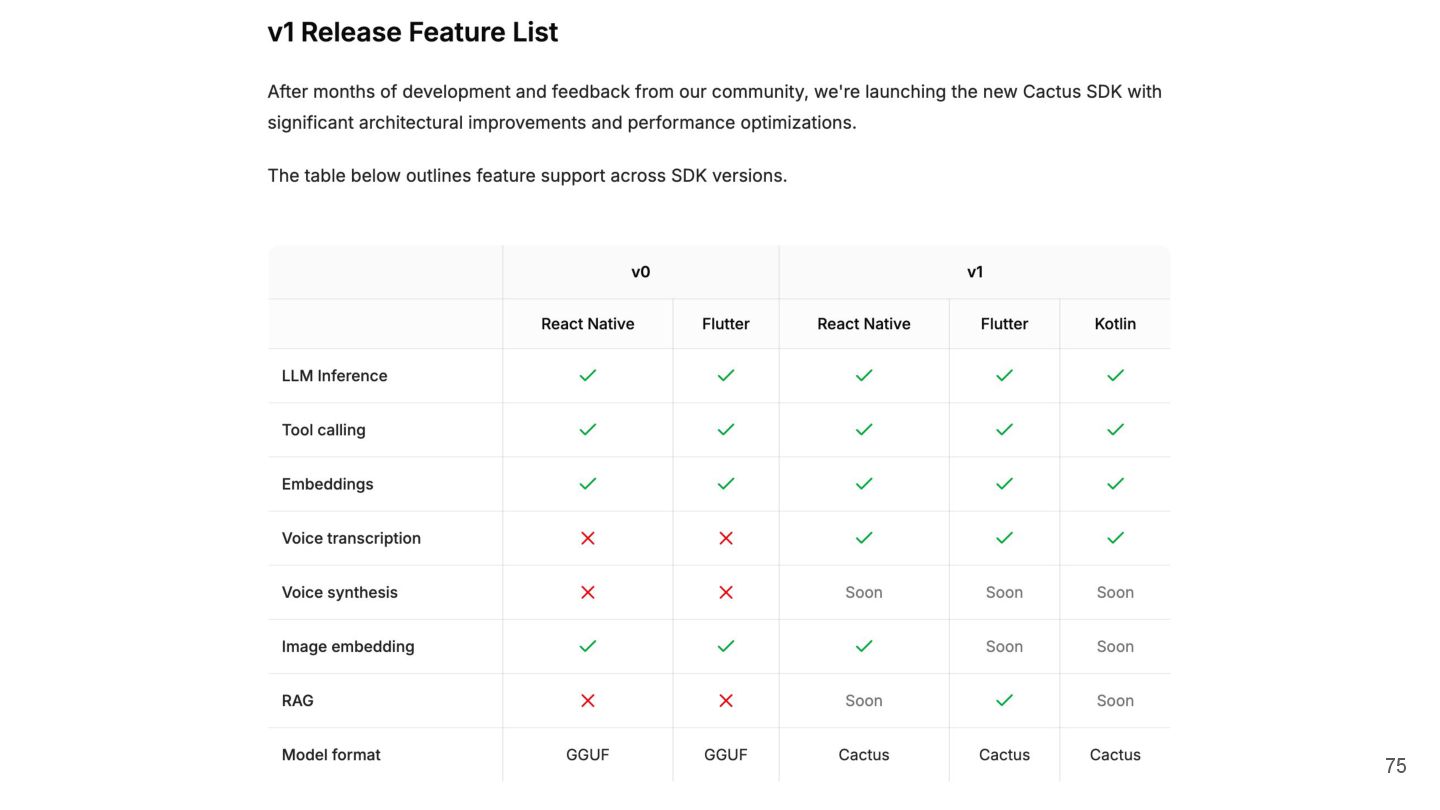{kind=link}
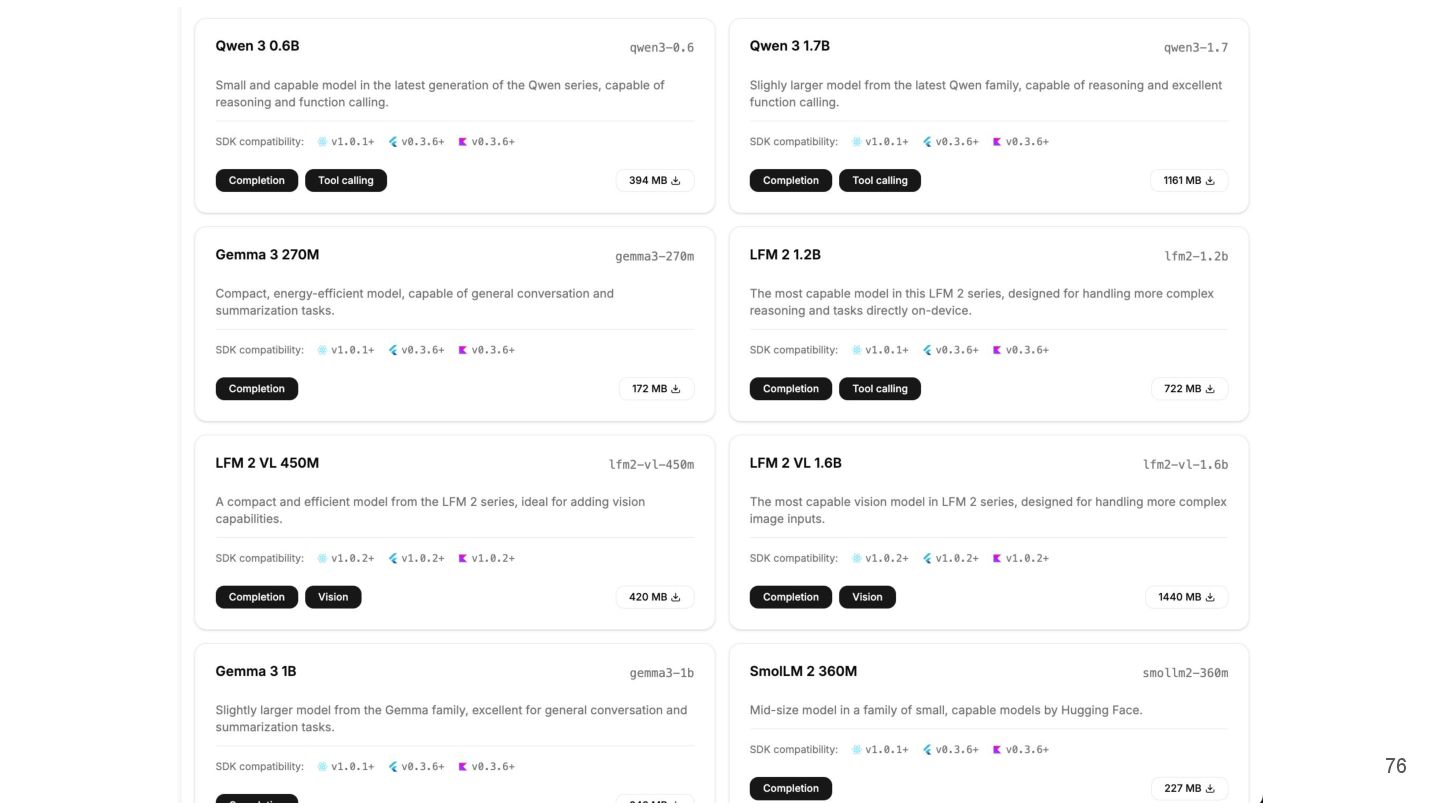{kind=link}
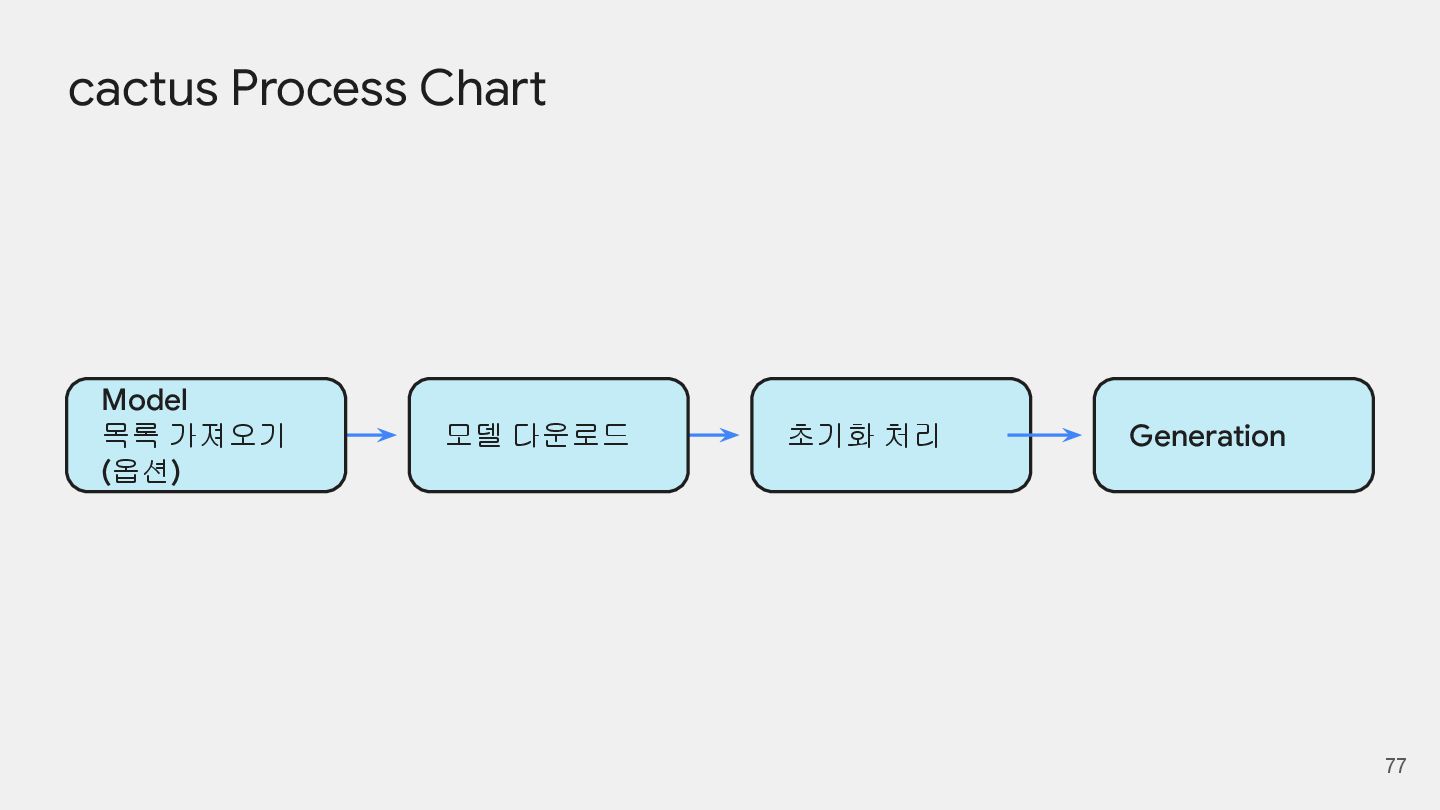{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
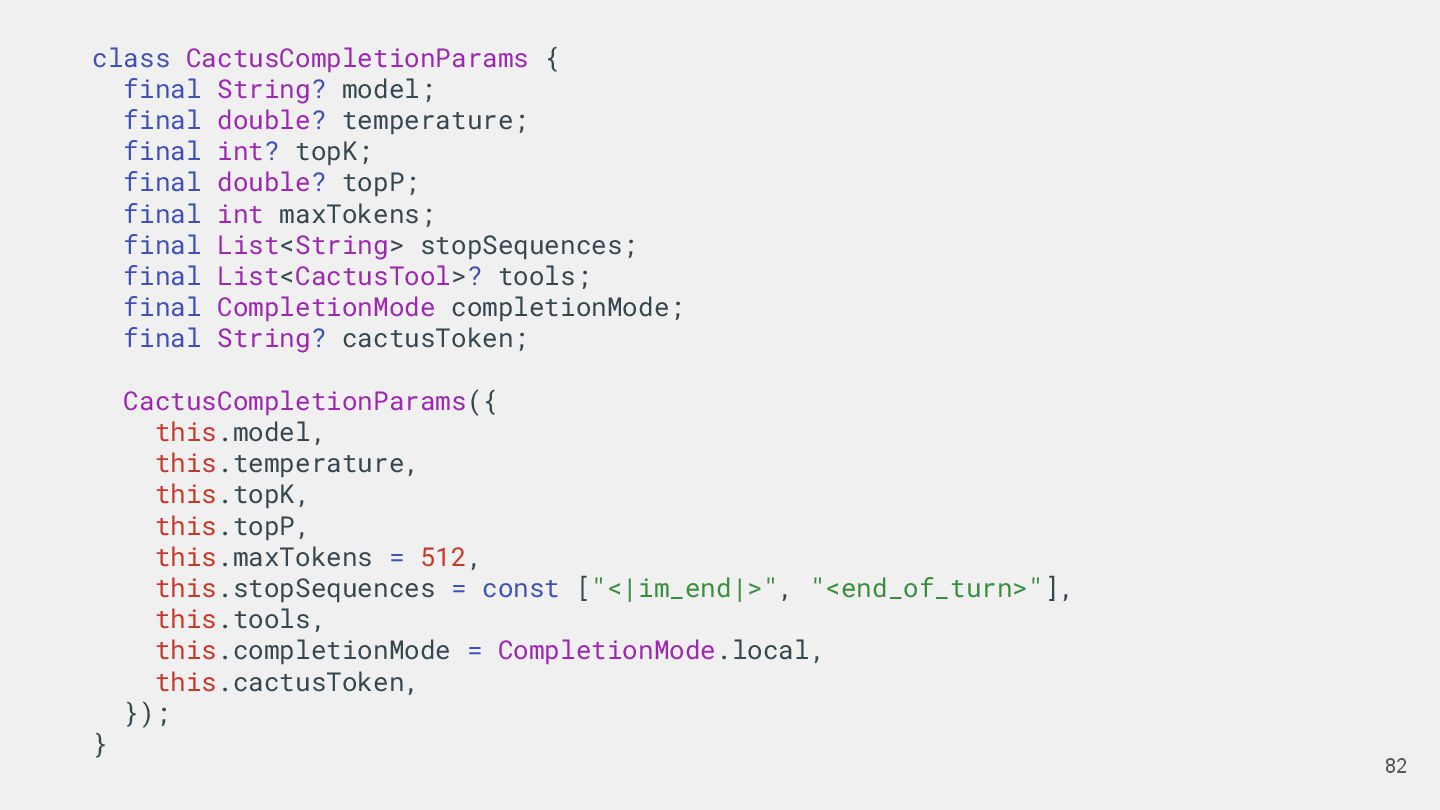{kind=link}
{kind=link}
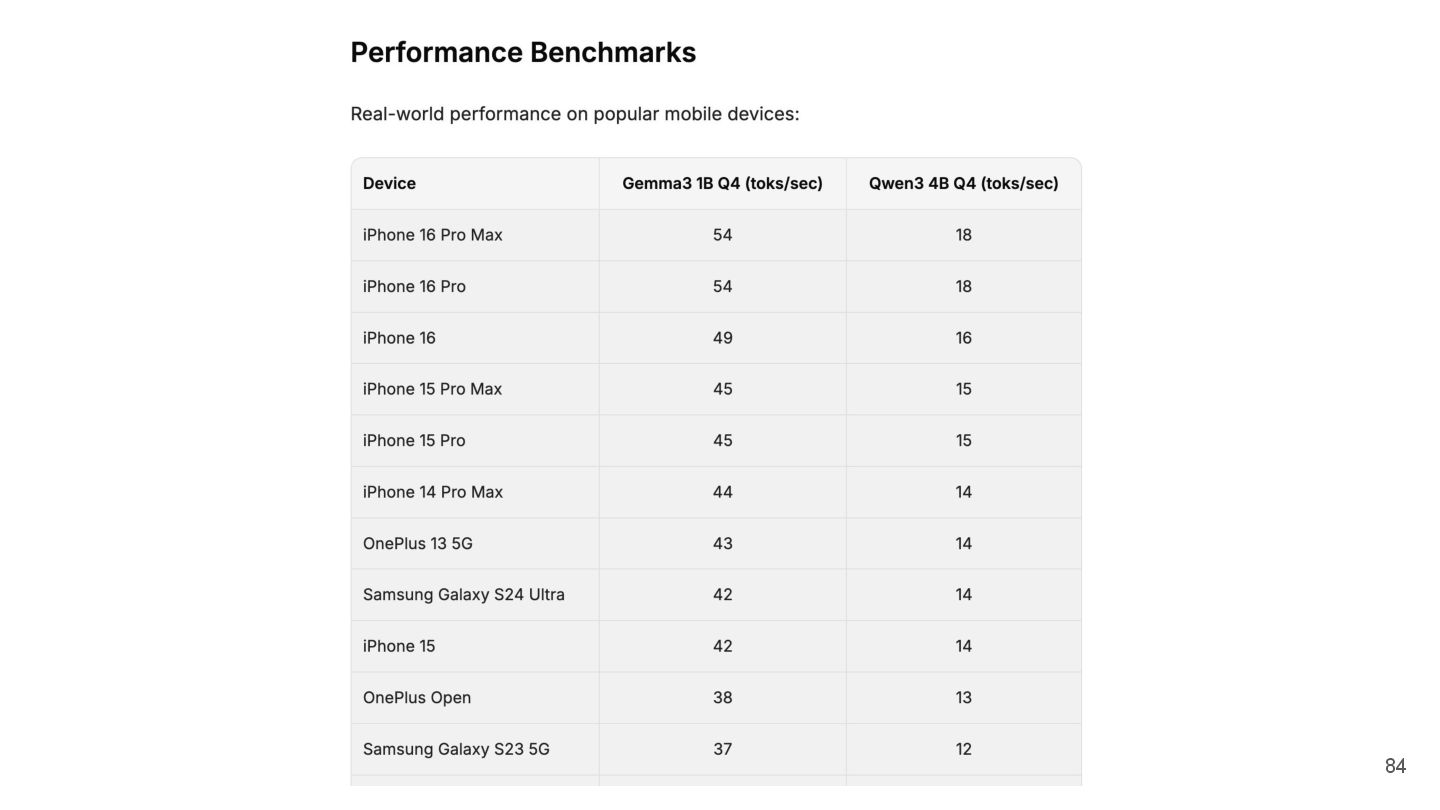{kind=link}
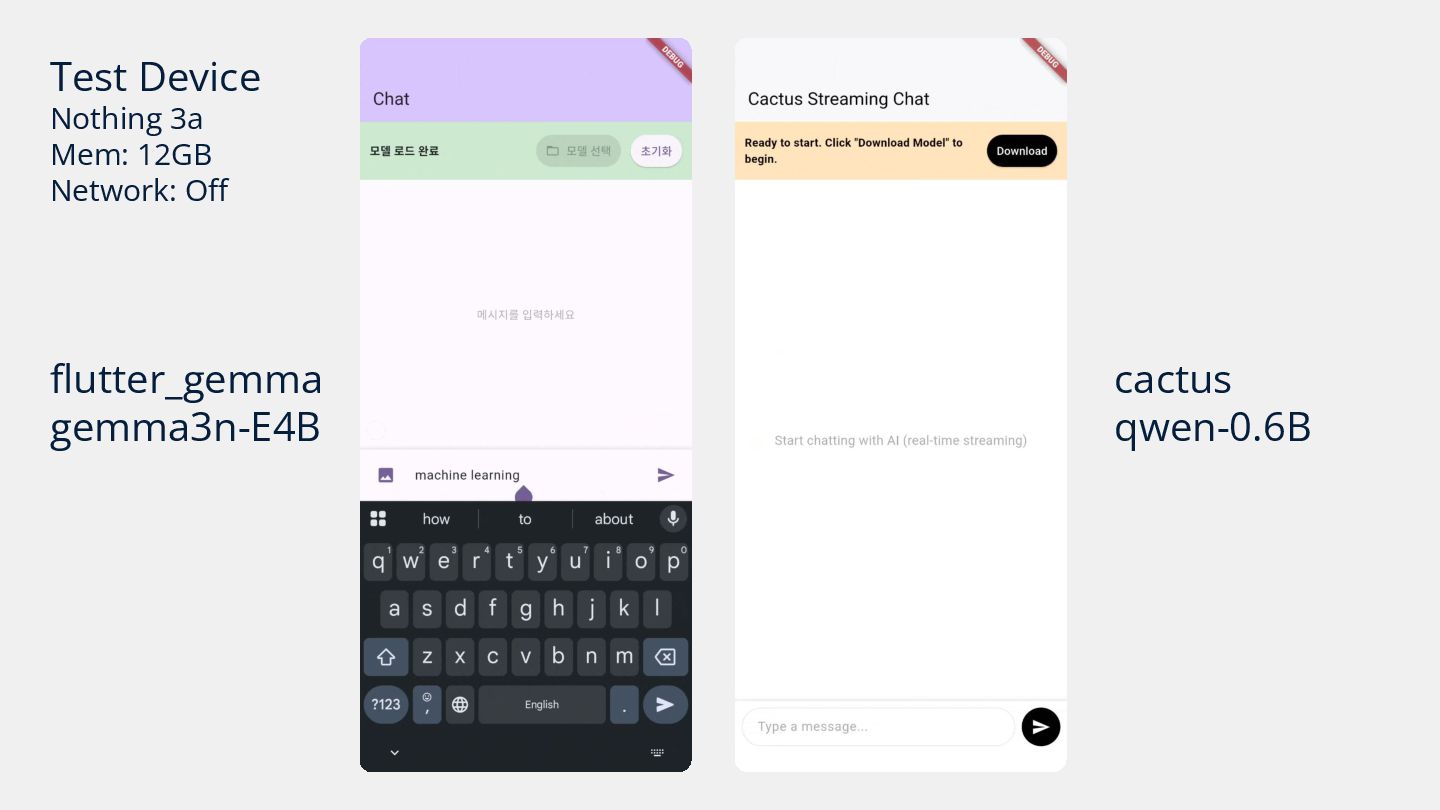{kind=link}
{kind=link}
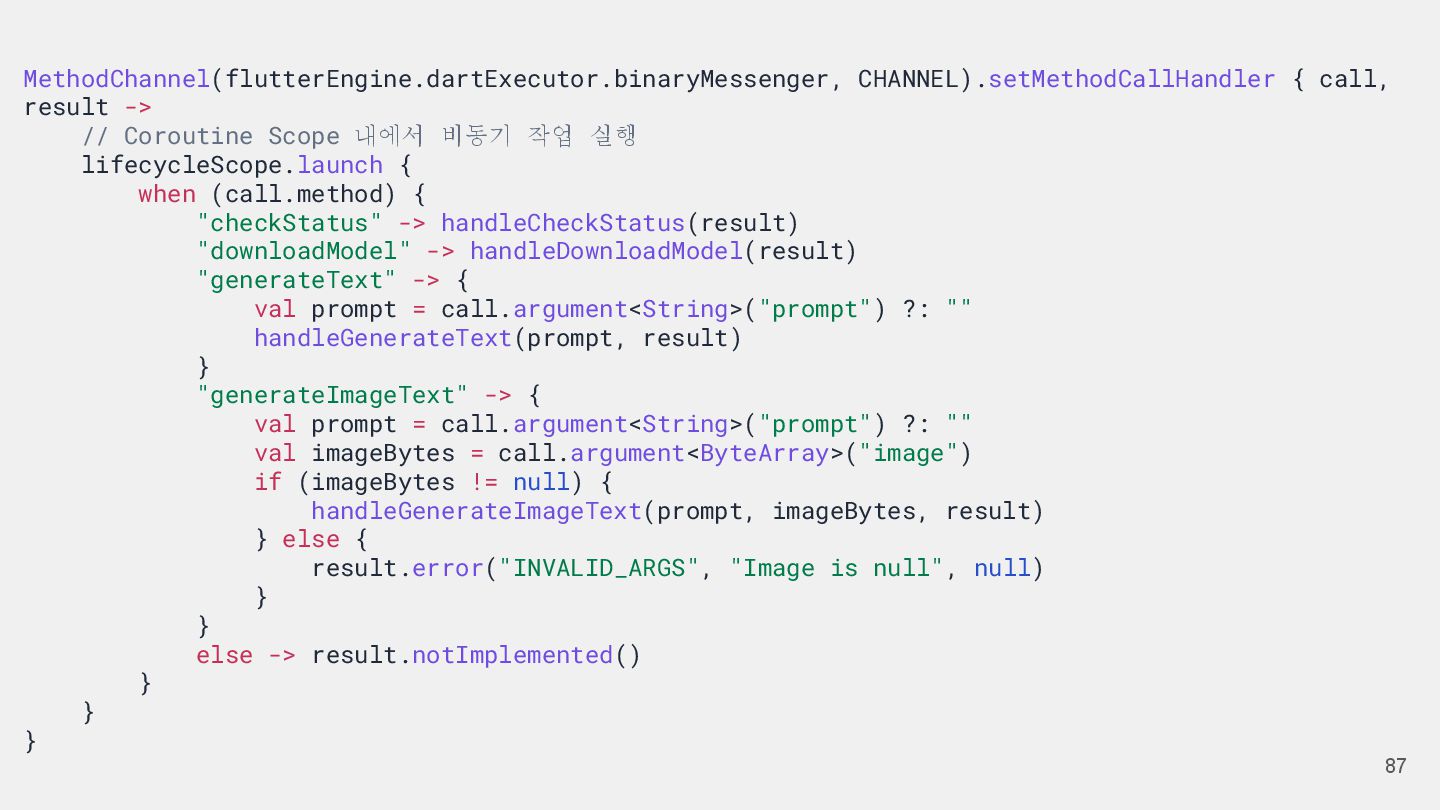{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}