Case study of collecting Pakistan census data for robust distribution and better availability. This deck discusses the problems faced while accessing public data in general, using this particular case.
but not available in reusable and widely accessible formats. In fact, the website itself is not available most of the time. • World Bank (data.worldbank.org) • ReliefWeb (reliefweb.int) • USAID (usaid.gov) Data available in different accessible formats but data is brief, limited and directed.
available for each district. • Each district data accessible2 as HTML page. • Patience! 1. Who am I kidding?! That is the only census data available. 2. Only when website is available & accessible
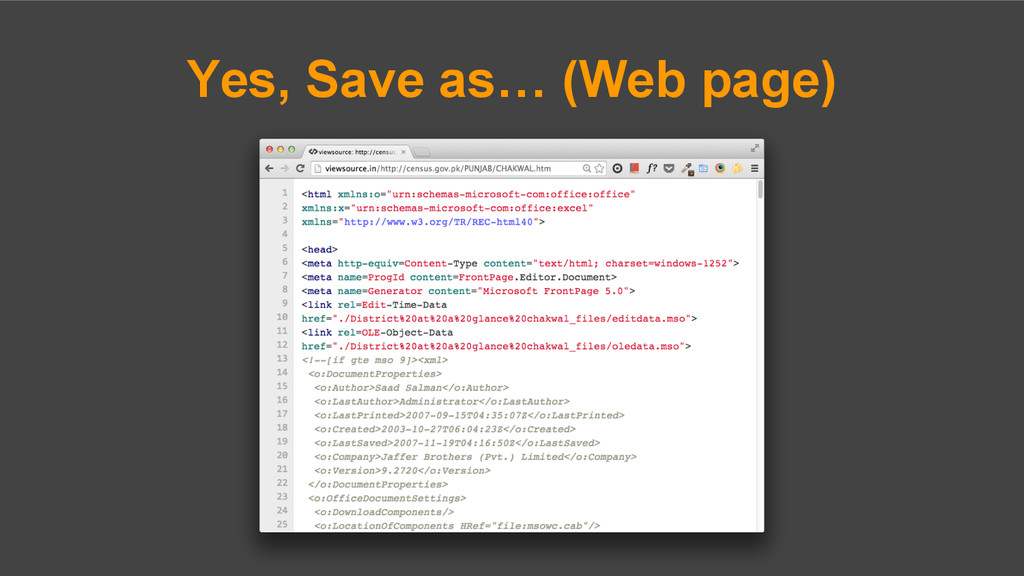
2. Server unavailable after script comes across an error. 3. Ridiculous latency. (Patience methodology applies here.) 4. Non-semantic data e.g. some districts have extra information columns; in result, returning error and going back to #2. 5. HTML files were literally saved from Microsoft Office!!
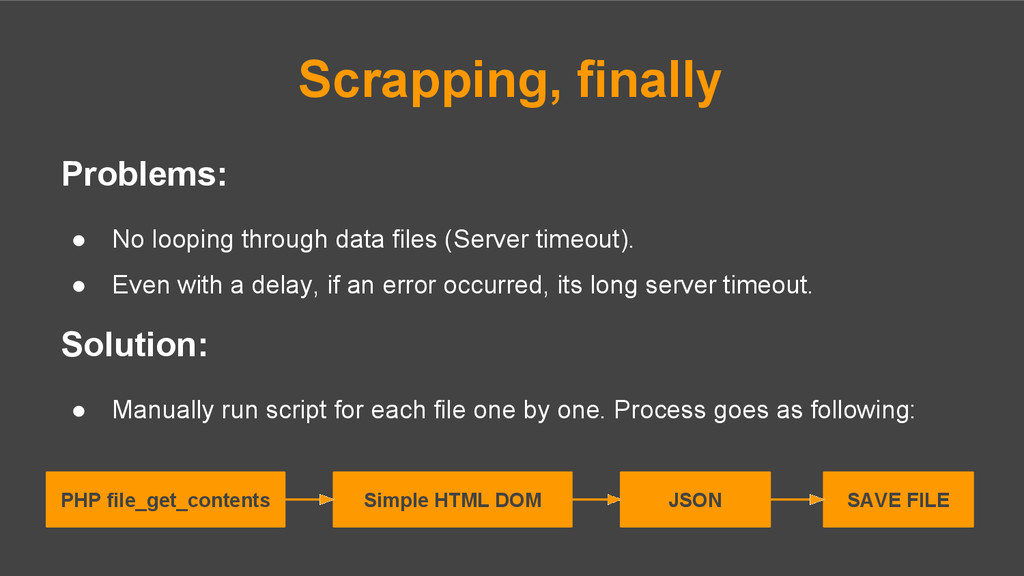
Even with a delay, if an error occurred, its long server timeout. Solution: • Manually run script for each file one by one. Process goes as following: Scrapping, finally PHP file_get_contents Simple HTML DOM JSON SAVE FILE
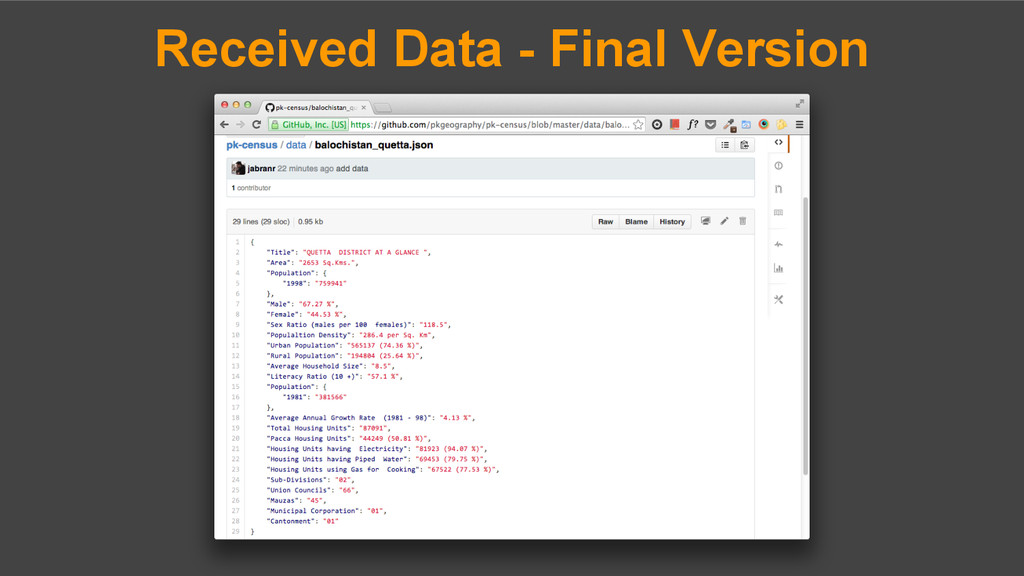
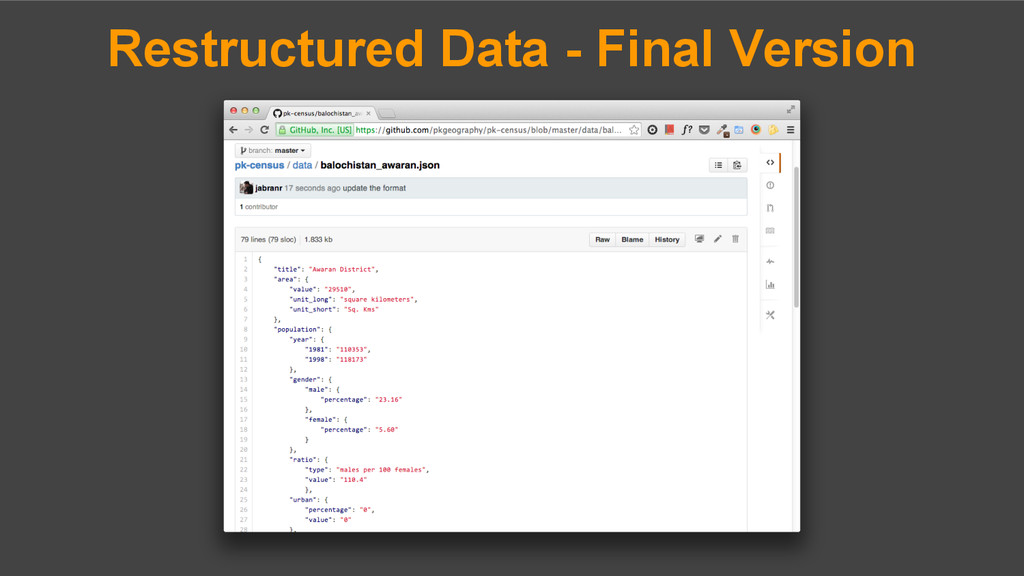
of this whole process. 2. Restructure all data into a standard format. 3. Acquire missing data. 4. Make it all available for public use. Get it, share it or contribute to it at git.io/pk-census
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! @jabranr | [email protected] http://git.io/pk-census](https://files.speakerdeck.com/presentations/d4c5b230fe1801317f47363b7b8f1b16/slide_15.jpg){kind=link}