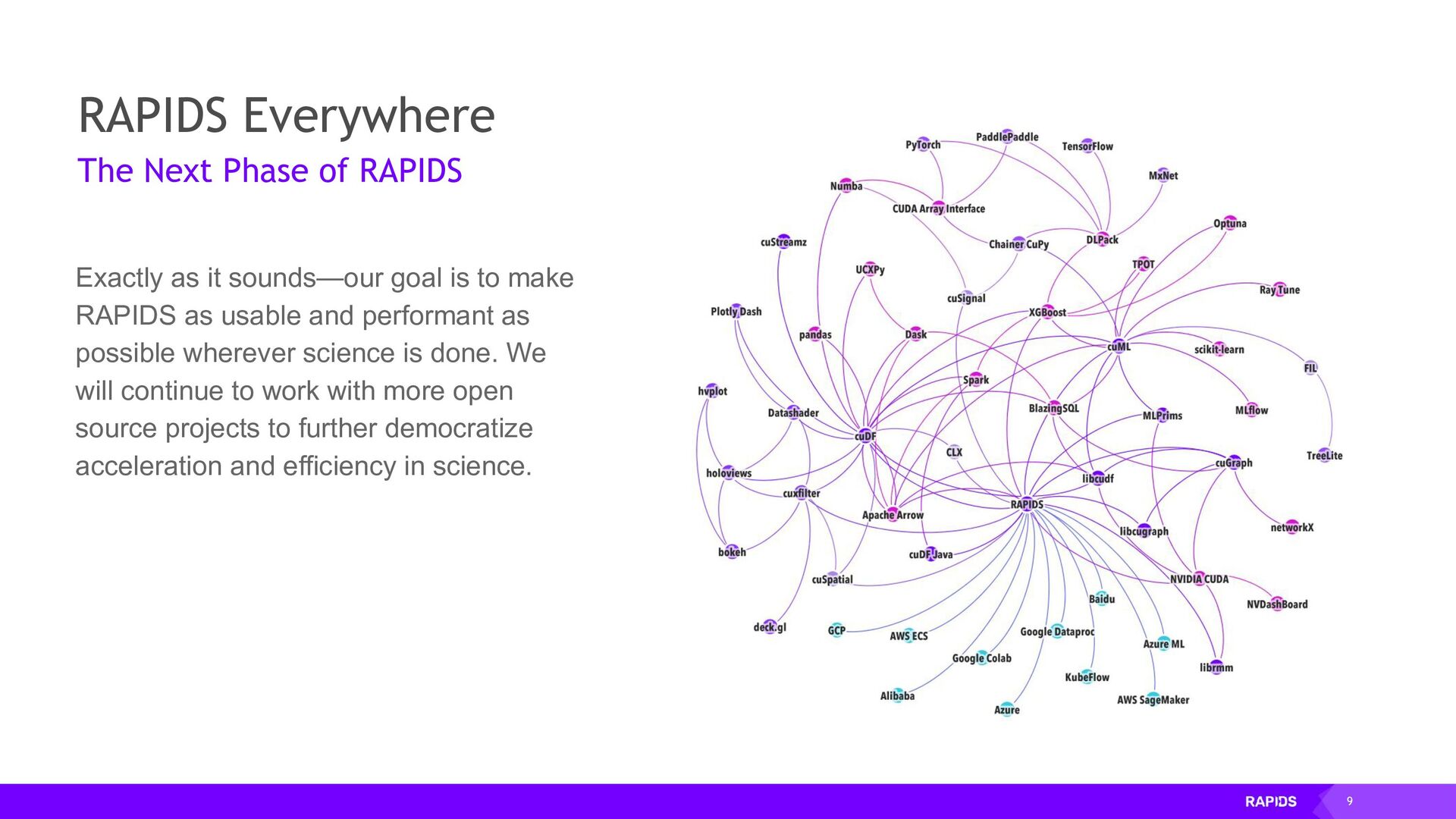
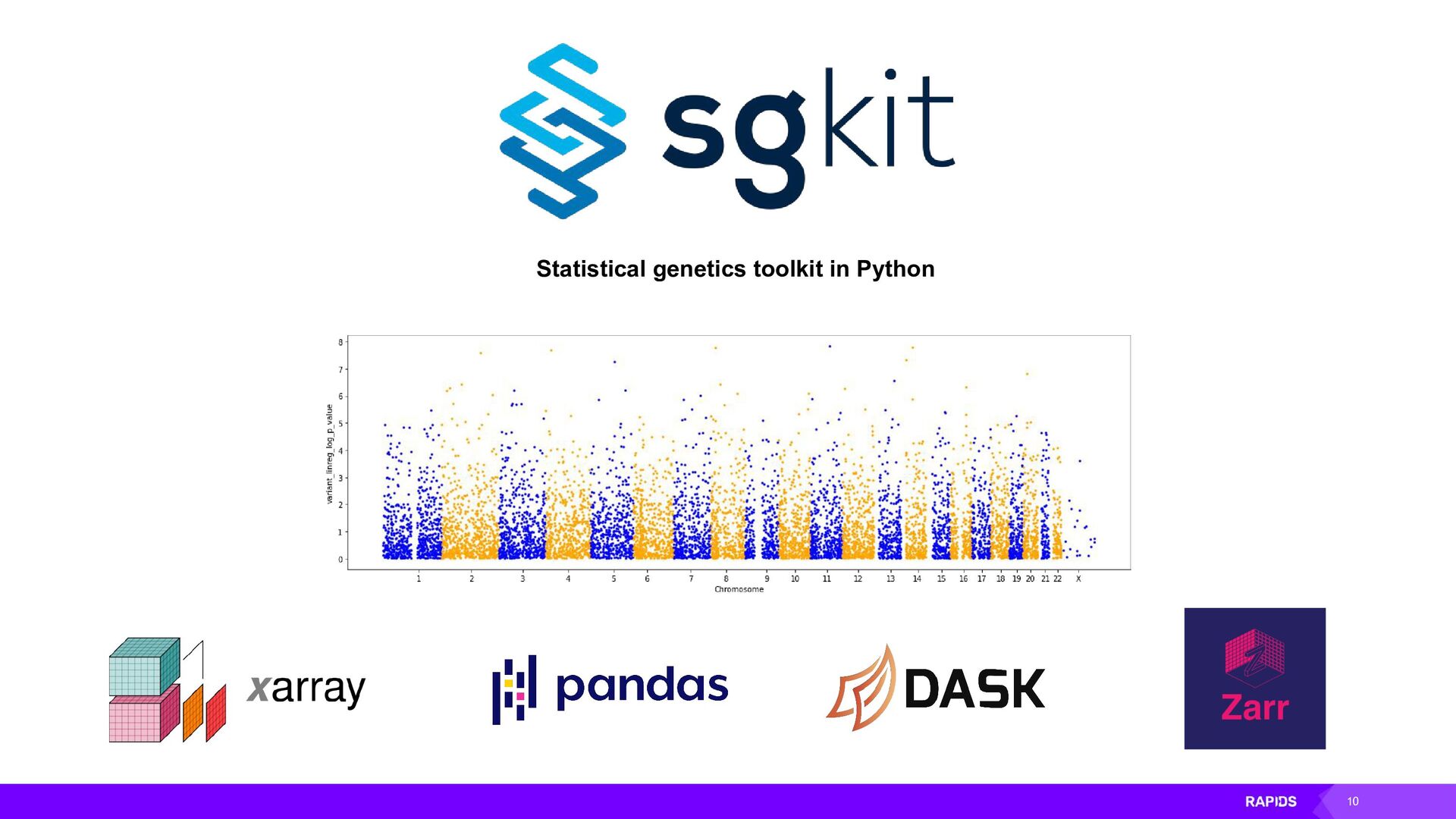
There are many powerful libraries in the Python ecosystem for accelerating the computation of large arrays with GPUs. We have CuPy for GPU array computation, Dask for distributed computation, cuML for machine learning, Pytorch for deep learning and more. We will dig into how these libraries can be used together to accelerate geoscience workflows and how we are working with projects like Xarray to integrate these libraries with domain-specific tooling. Sgkit is already providing this for the field of genetics and we are excited to be working with community groups like Pangeo to bring this kind of tooling to the geosciences.
How to cite: Tomlinson, J.: Distributing your GPU array computation in Python, EGU General Assembly 2022, Vienna, Austria, 23–27 May 2022, EGU22-7610, https://doi.org/10.5194/egusphere-egu22-7610, 2022.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU Jacob Tomlinson [email protected] @_jacobtomlinson](https://files.speakerdeck.com/presentations/a41c1140b964450c817833a03e68c5b6/slide_11.jpg){kind=link}