“Ballkind Markus” und KSC im Text • Finden “Der Karlsruher Arzt diagnostizierte...” “Autounfall in Karlsruhe...” “der in Karlsruhe gebohrene Schiri...” • “Joachim Löw” im Text
“findet” 2 Features • Wie ereignisreich war ein Spieltag? • Kein Clustering: Hohe Werte für eindeutige News Nicht wichtigste Singular Value Decomposition
(Faktor 1,2,3,3,12,10,9,8,2) 2. Vektor: Alle Wörter und Entities 3. SVD: Bildet Features Nehmen “stärkste” News für jedes Feature.. 4. Filtern doppelte News. Viele Features doppelt = Wenige Themen 5. Wenige Themen = Wenige Features. Jedes Thema ein Cluster: So finden wir k (k-means) 6. K-Means Clustering. Größe der Cluster bestimmt Ranking.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
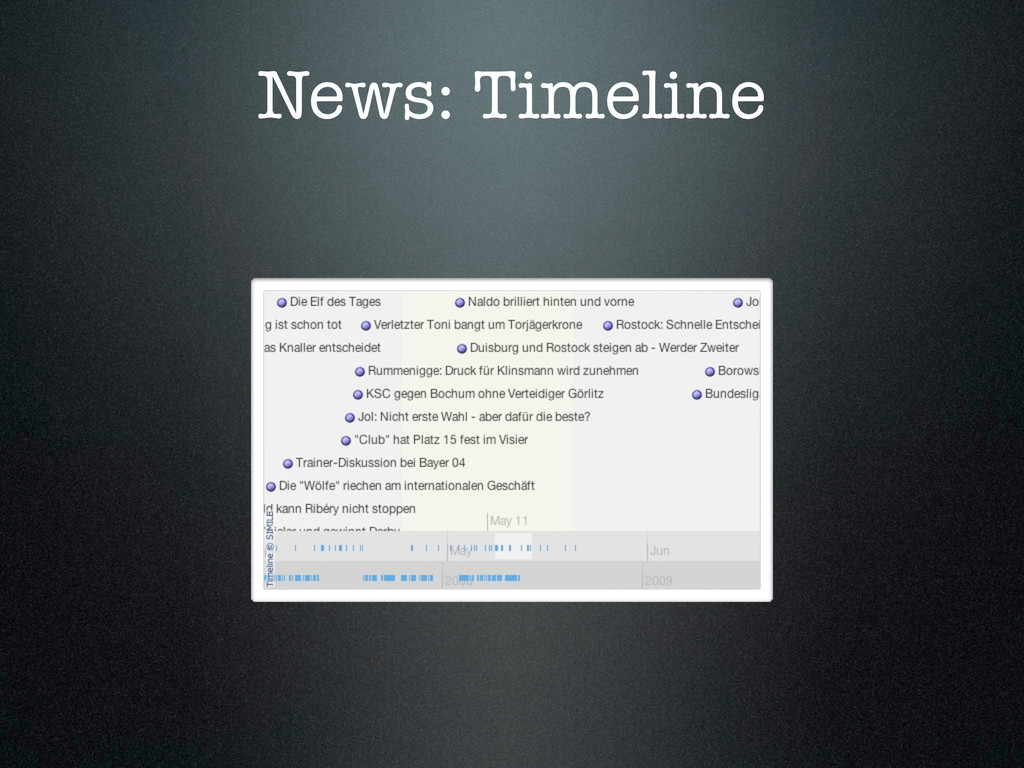{kind=link}
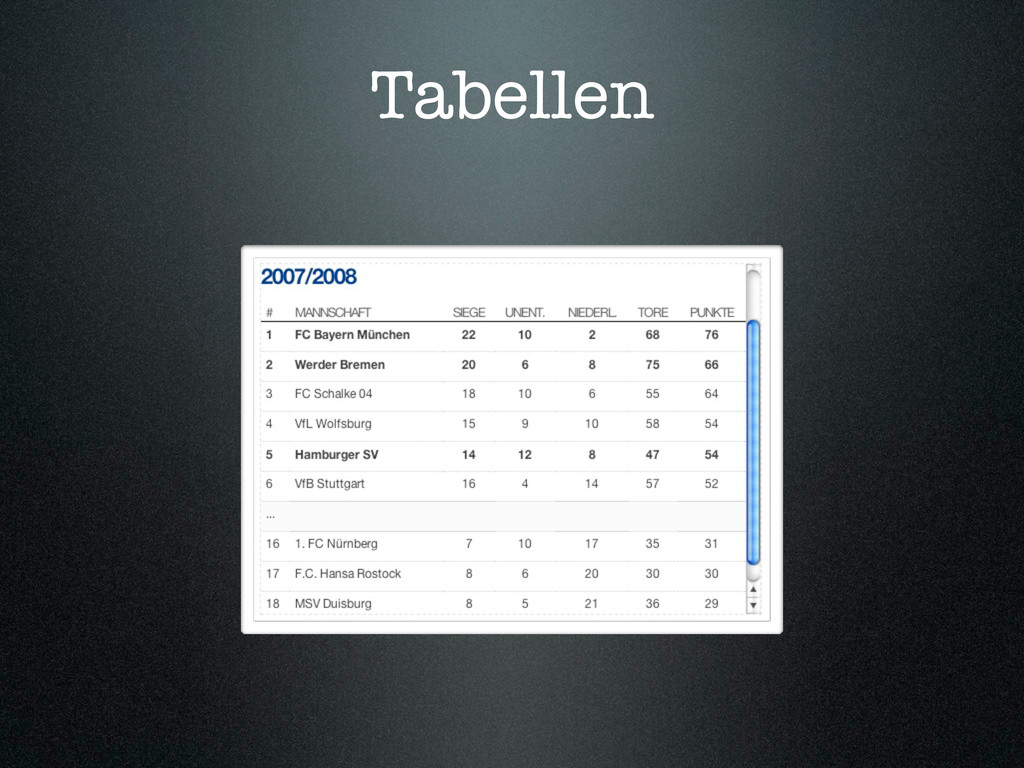{kind=link}
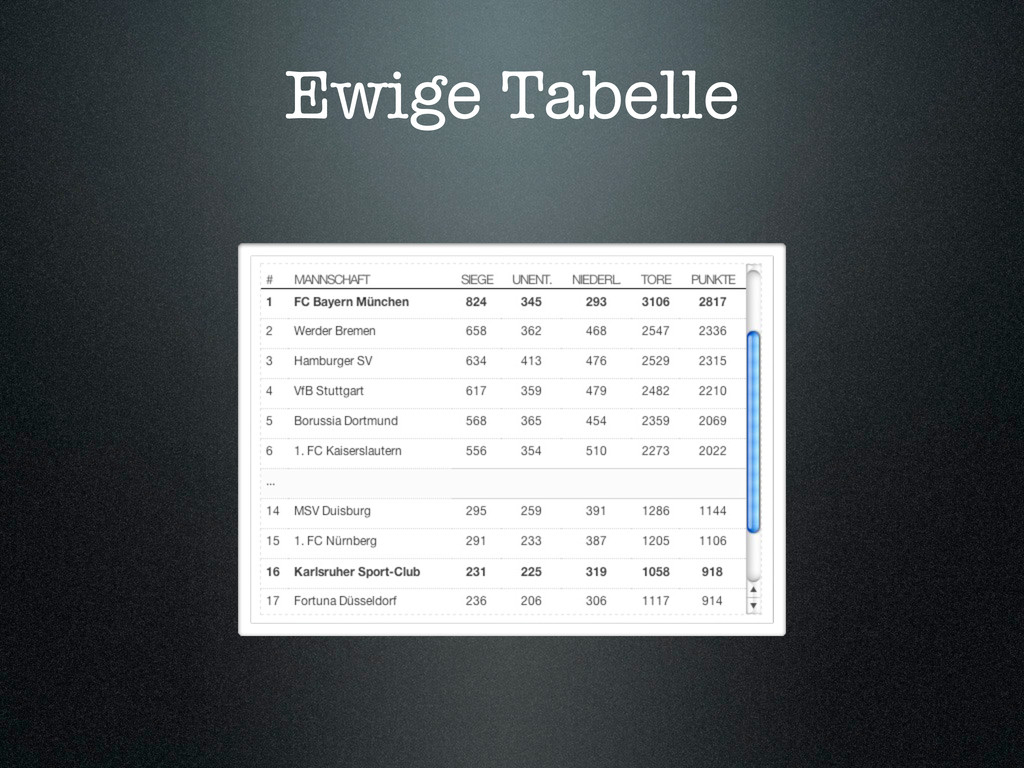{kind=link}
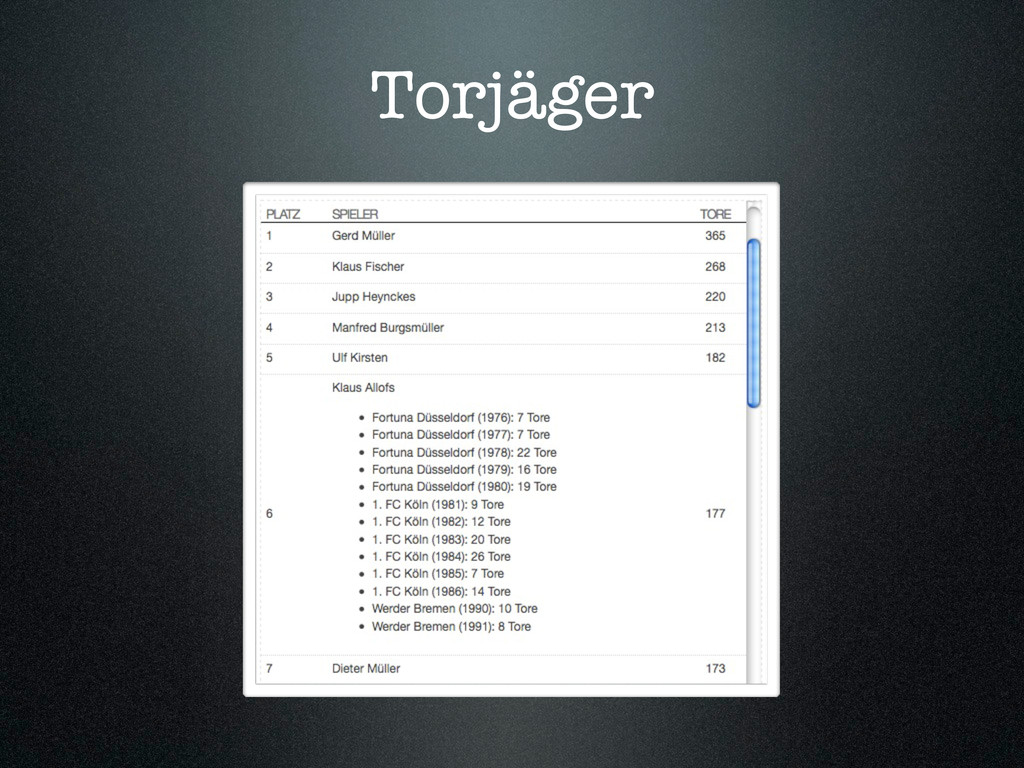{kind=link}
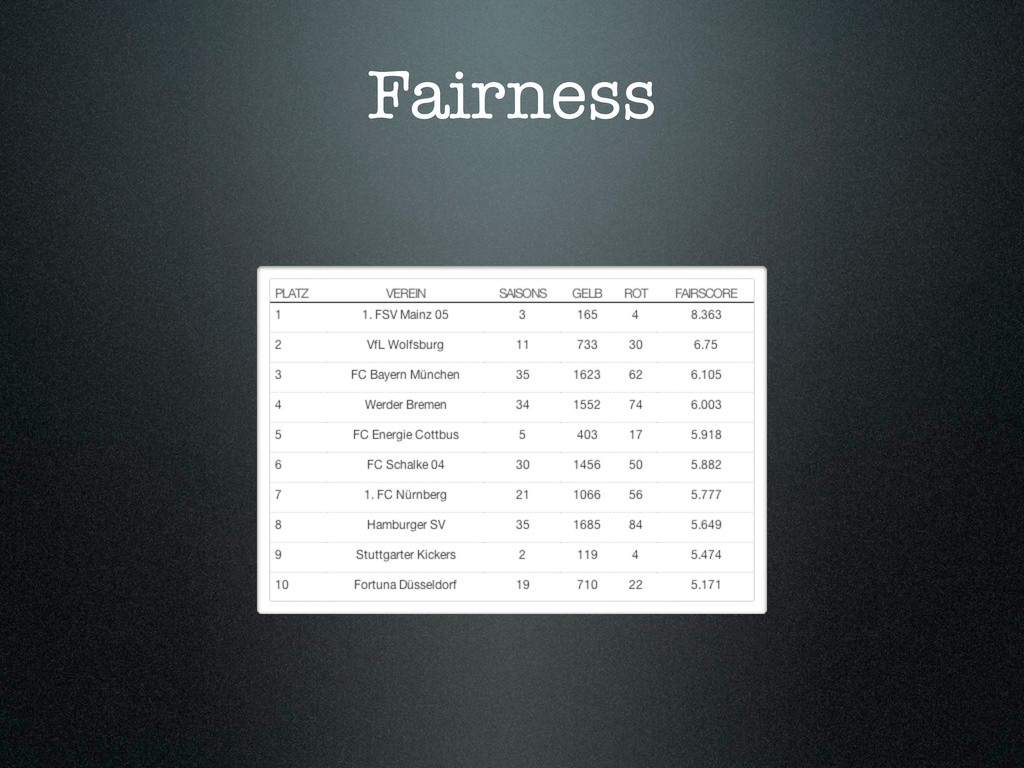{kind=link}
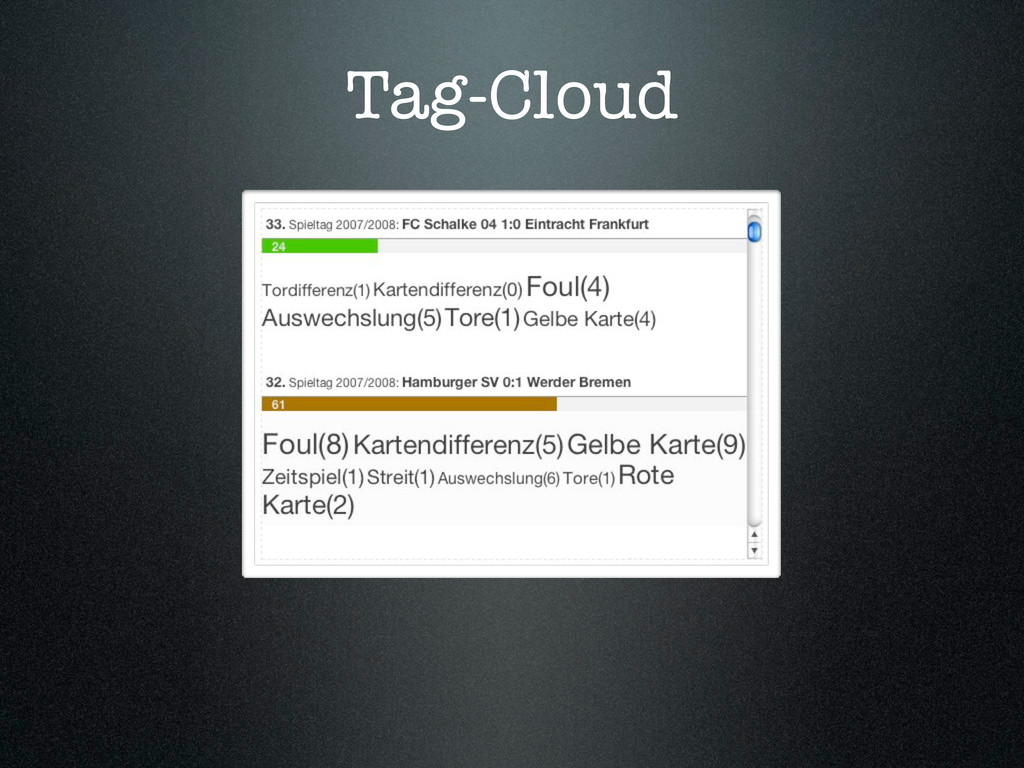{kind=link}
{kind=link}
{kind=link}
{kind=link}
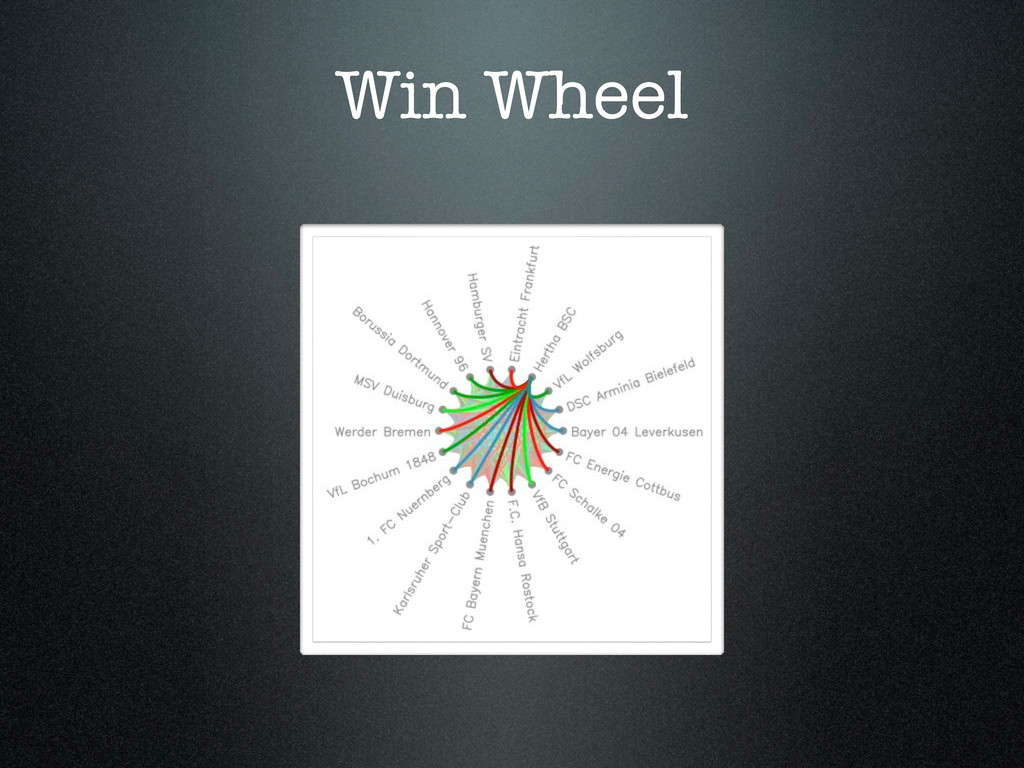{kind=link}
{kind=link}
{kind=link}
{kind=link}