Software Engineer at Engage (a LivePerson company) ▸ SQL Nerd ▸ Primary author of Expressions ▸ Django core developer Hi everyone. I'm Josh. I go by Jarshwah on IRC or the Mailing List and Github, so now you know who to corner later on if I haven't given your idea enough attention yet. So a little about me then. I work for a call centre company that provides hosted telephony to businesses in Australia.. which is where I'm from. A lot of that work has involved reporting which has required a fairly good understanding of SQL and some database specific tuning techniques. Nearly all of the queries and reports I've had to write have involved fairly complex SQL and lots of aggregation. Most of those queries were written by hand and were fairly static. What I really wanted to do was build a Business Intelligence application in Django that would let users compose their own reports, make calculations, add a whole lot of filters and that kind of thing. There's already lots of good products on the market if you've got $100,000 a year to spend but I was looking for something I could integrate into our existing Django project and that other people could use too. Pretty early on I found out that Django was totally incapable of aggregating across multiple fields. You can't write Sum('cost' + 'profit') or Sum('cost') + Sum('profit'). So that killed my idea of implementing a reporting app in Django right away. But it also led me to ticket #14030 which basically asked for F() expression support in aggregation, and would allow me to build my reporting app. This talk is going to be part tale about how this ticket was resolved, and part tutorial on all the new features introduced by this ticket. So I was the primary author of the 14030 patch, but there was a tonne of assistance and prior work from the community too. I picked the ticket up about 2 years ago, worked on it for a year, and it was actually committed last year at this conference by Marc. I was lucky enough to be asked to join the core team off the back of that work too, which was really my first major contribution to open source. OK so.. what are expressions then and how are they relevant to aggregating over multiple fields?
contained parcels of SQL Ok, so when we talk about expressions in programming we're referring to a computation that returns something. 1 + 1 is an expression that returns 2. print("hello world") is a statement that does not return anything. Django expressions are objects that map to SQL expressions. How many people here are familiar with F() expressions? For those not familiar, an F() expression represents a field's value within the database at runtime. And F() expressions aren't new either. They've been a part of Django since 1.1, so about 7 years now. The example here F(price) + shipping_fee creates an Expression which then returns the SQL required to perform the calculation inside the database transaction. F() expressions were really the only expressions available to the ORM until Django 1.8. Aggregates were added to Django about 10 months before F() expressions. They also produced SQL for the database to execute, but they never had the capability of adding or subtracting values or other expressions like F() expressions did. They were two entirely different concepts internally, even though the abstract idea behind both were the same. Represent a value or computation in Python, and have that representation execute within the database. All expressions within Django now derive from the underlying F() expression concept. We've created a bunch of classes that can be combined with arithmetic or passed as arguments to other expressions, including all of the aggregates. Each expression is a self contained entity that knows how to output SQL. The ORM doesn't inspect the expression and output what it thinks the SQL should be. The expressions themselves know how they should be represented. This is pretty important, but we'll come back to this a bit later.
itself has a number of concepts it needs to be familiar with right. It needs to know what kind of joins to set up, if we're performing an aggregation so it can generate the correct GROUP BY statement. What type of Field is being returned so that it can provide the right translations and conversions. It also has backend specific concepts that it needs to represent.. like MySQL's "enhancement" that allows adding or removing arbitrary columns from the GROUP BY clause. I make fun of MySQL, but I personally use Oracle at work and Django has to jump through LOTS of hoops to support it the way it does! The ORM needs all of this information to produce correct queries. Expressions provide all the context that the ORM needs to produce these queries.
multiple database backend support. This is probably my favourite feature of expressions, but it was introduced by Anssi with the custom Lookups and Transforms addition in Django 1.7. It allows expressions to define how the SQL should be rendered for each database that it supports. Traditionally all backend specific SQL was put into the backend. Any frontend objects that needed to render different SQL would have to ask the backend to do it for them. This made it incredibly difficult for users and library authors to provide backend agnostic components.
and .raw() Queryset.extra and Queryset.raw have become basically useless now. Their primary uses are allowing users to write custom SQL, which can now be done by creating your own Expressions.
in SQL ▸ .extra() for appending bits of SQL ▸ Escape hatches So .raw is for passing an entire SQL query and having that executed verbatim. The ORM essentially passes your SQL through, and makes it's best attempt to map the result back to models. If you consider the ORM as having two jobs.. the first being to generate SQL and the second being to map results back to objects. raw takes over entirely the first job, but lets the ORM do it's second job. Extra is a kind of frankenstein monster. It lets you add arbitrary sql strings to the select clause, the where clause, the from clause and the order by clause. You know how I said before that expressions provide all the context the ORM needs to produce correct results? Extra provides literally no context. It assumes you know what you're doing, that you're aware of the vast limitations, and lets you introduce SQL into places it probably shouldn't. Be wary of SQL injection. If you're ever passing data to these functions you need to ensure you're not doing your own string interpolation. Always use django's parameters APIs. Both raw and extra are escape hatches. The ORM designers intentionally designed the ORM to be user friendly. It was about getting the 80% right and easy. It was about not trying to map too closely to SQL terms, and work in a way that made sense for Python. raw and extra tried to be for the other 20% of use cases. In practise though that 20% wasn't really covered at all.
3rd party libraries and apps ▸ Unknown table aliases ▸ Broken GROUP BY So neither of these functions are portable. When you write SQL strings you're locked in to the vendors that support that exact syntax. There's a lot in common with most database vendors, but there's heaps of database specific features too. All you need to do is look at how dates are constructed in each backend to know that there's a lot of differences between backends. So if you're using extra, you better make sure you only run tests on the same backend you use in production .. which you should be doing anyway. It also means that libraries can't really ship querysets that rely on extra unless they tie it to a single backend. When writing SQL that uses fields, you have to know the table names too. These are fairly easy to figure out, but multiple joins to the same table or subqueries break the table names. So your carefully crafted SQL that has worked perfectly stops working when someone adds a new filter clause to your query. You straight up can't put aggregates into the extra clause on databases that have sane handling of GROUP BY. The ORM doesn't know you've added an aggregate, so it doesn't even produce a GROUP BY. We'll see some examples later, but I couldn't figure out a single way to get aggregates working with extra. If anyone knows a way to get aggregates working with extra then please speak to me later.
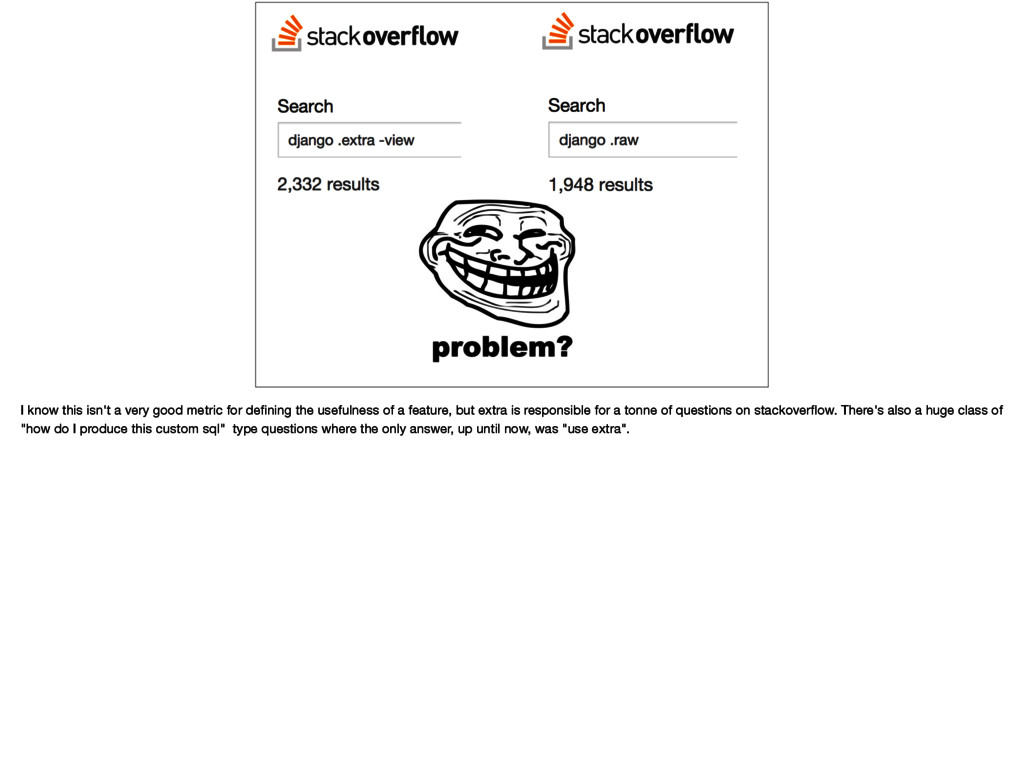
the usefulness of a feature, but extra is responsible for a tonne of questions on stackoverflow. There's also a huge class of "how do I produce this custom sql" type questions where the only answer, up until now, was "use extra".
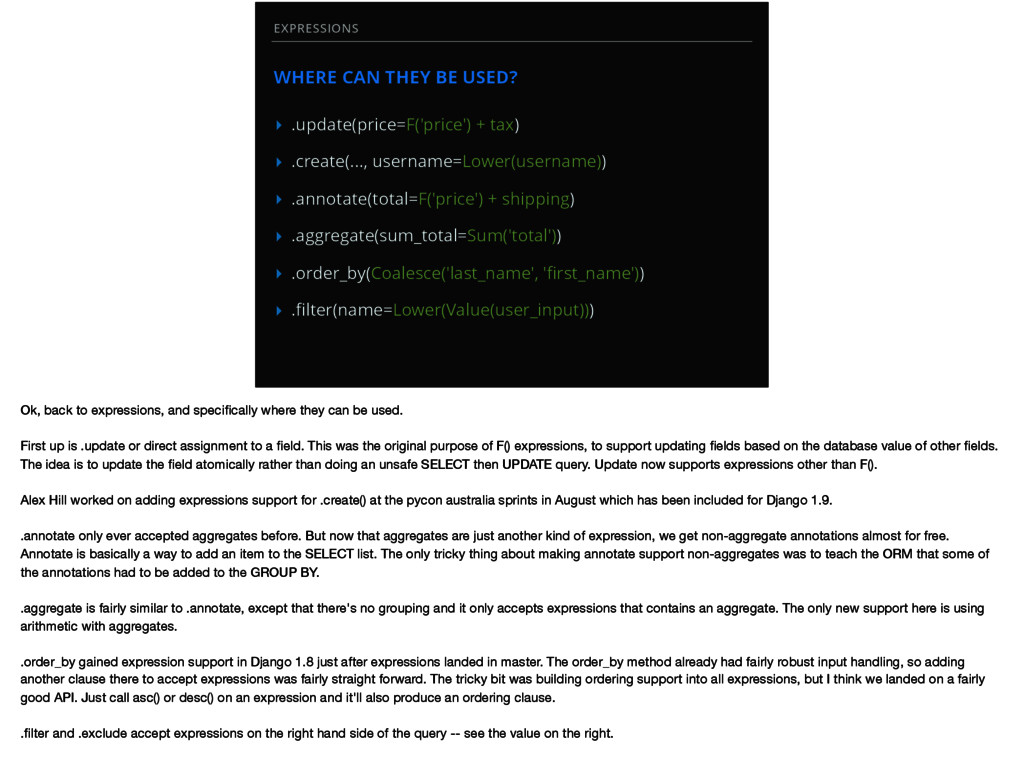
▸ .create(..., username=Lower(username)) ▸ .annotate(total=F('price') + shipping) ▸ .aggregate(sum_total=Sum('total')) ▸ .order_by(Coalesce('last_name', 'first_name')) ▸ .filter(name=Lower(Value(user_input))) Ok, back to expressions, and specifically where they can be used. First up is .update or direct assignment to a field. This was the original purpose of F() expressions, to support updating fields based on the database value of other fields. The idea is to update the field atomically rather than doing an unsafe SELECT then UPDATE query. Update now supports expressions other than F(). Alex Hill worked on adding expressions support for .create() at the pycon australia sprints in August which has been included for Django 1.9. .annotate only ever accepted aggregates before. But now that aggregates are just another kind of expression, we get non-aggregate annotations almost for free. Annotate is basically a way to add an item to the SELECT list. The only tricky thing about making annotate support non-aggregates was to teach the ORM that some of the annotations had to be added to the GROUP BY. .aggregate is fairly similar to .annotate, except that there's no grouping and it only accepts expressions that contains an aggregate. The only new support here is using arithmetic with aggregates. .order_by gained expression support in Django 1.8 just after expressions landed in master. The order_by method already had fairly robust input handling, so adding another clause there to accept expressions was fairly straight forward. The tricky bit was building ordering support into all expressions, but I think we landed on a fairly good API. Just call asc() or desc() on an expression and it'll also produce an ordering clause. .filter and .exclude accept expressions on the right hand side of the query -- see the value on the right.
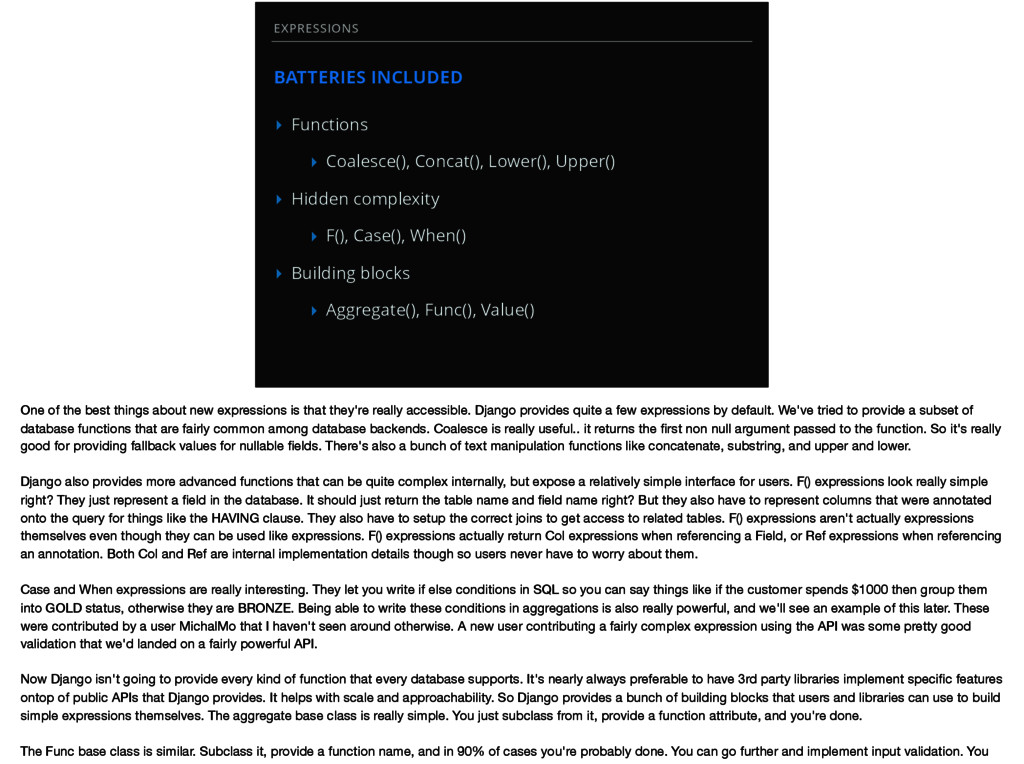
▸ Hidden complexity ▸ F(), Case(), When() ▸ Building blocks ▸ Aggregate(), Func(), Value() One of the best things about new expressions is that they're really accessible. Django provides quite a few expressions by default. We've tried to provide a subset of database functions that are fairly common among database backends. Coalesce is really useful.. it returns the first non null argument passed to the function. So it's really good for providing fallback values for nullable fields. There's also a bunch of text manipulation functions like concatenate, substring, and upper and lower. Django also provides more advanced functions that can be quite complex internally, but expose a relatively simple interface for users. F() expressions look really simple right? They just represent a field in the database. It should just return the table name and field name right? But they also have to represent columns that were annotated onto the query for things like the HAVING clause. They also have to setup the correct joins to get access to related tables. F() expressions aren't actually expressions themselves even though they can be used like expressions. F() expressions actually return Col expressions when referencing a Field, or Ref expressions when referencing an annotation. Both Col and Ref are internal implementation details though so users never have to worry about them. Case and When expressions are really interesting. They let you write if else conditions in SQL so you can say things like if the customer spends $1000 then group them into GOLD status, otherwise they are BRONZE. Being able to write these conditions in aggregations is also really powerful, and we'll see an example of this later. These were contributed by a user MichalMo that I haven't seen around otherwise. A new user contributing a fairly complex expression using the API was some pretty good validation that we'd landed on a fairly powerful API. Now Django isn't going to provide every kind of function that every database supports. It's nearly always preferable to have 3rd party libraries implement specific features ontop of public APIs that Django provides. It helps with scale and approachability. So Django provides a bunch of building blocks that users and libraries can use to build simple expressions themselves. The aggregate base class is really simple. You just subclass from it, provide a function attribute, and you're done. The Func base class is similar. Subclass it, provide a function name, and in 90% of cases you're probably done. You can go further and implement input validation. You
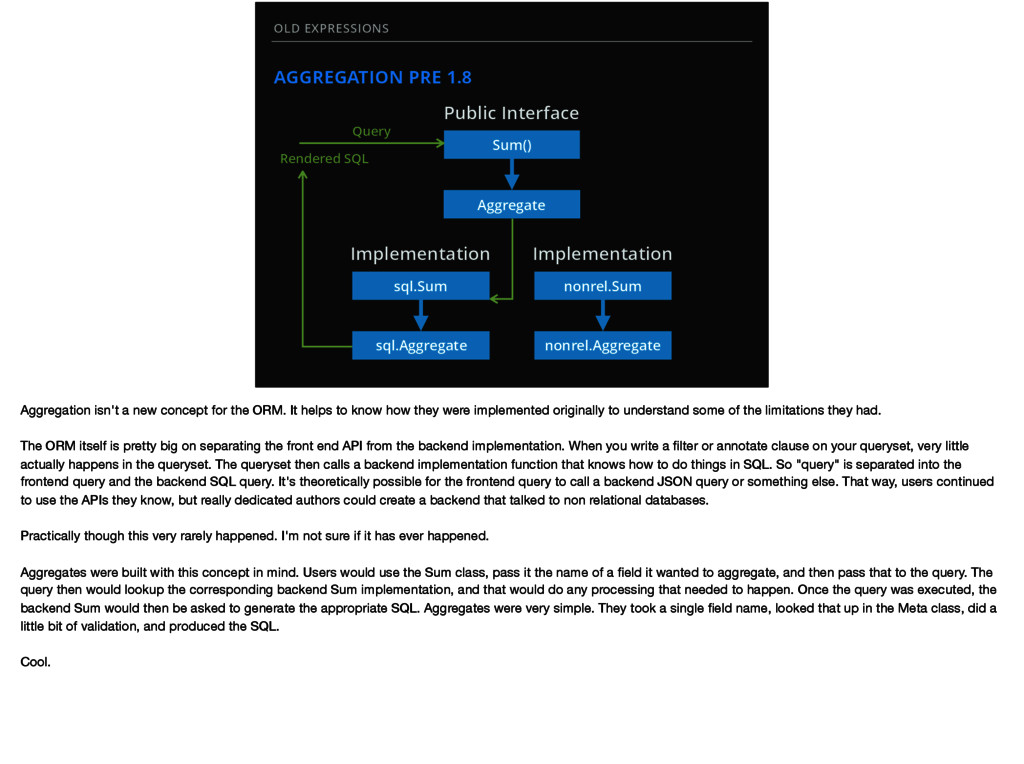
sql.Sum sql.Aggregate Implementation nonrel.Sum nonrel.Aggregate Implementation Rendered SQL Aggregation isn't a new concept for the ORM. It helps to know how they were implemented originally to understand some of the limitations they had. The ORM itself is pretty big on separating the front end API from the backend implementation. When you write a filter or annotate clause on your queryset, very little actually happens in the queryset. The queryset then calls a backend implementation function that knows how to do things in SQL. So "query" is separated into the frontend query and the backend SQL query. It's theoretically possible for the frontend query to call a backend JSON query or something else. That way, users continued to use the APIs they know, but really dedicated authors could create a backend that talked to non relational databases. Practically though this very rarely happened. I'm not sure if it has ever happened. Aggregates were built with this concept in mind. Users would use the Sum class, pass it the name of a field it wanted to aggregate, and then pass that to the query. The query then would lookup the corresponding backend Sum implementation, and that would do any processing that needed to happen. Once the query was executed, the backend Sum would then be asked to generate the appropriate SQL. Aggregates were very simple. They took a single field name, looked that up in the Meta class, did a little bit of validation, and produced the SQL. Cool.
Query Rendered SQL evaluate recursively sql.Evaluator Implementation nonrel.Evaluator Implementation prepare recursively Then along came F expressions a little while later. The authors recognised the value in separating the frontend from the backend. That was the contract. It had to be possible for 3rd parties to create their own implementations. F expressions had to do a little more though. They had to represent part of a computation.. they had to support arithmetic. Users would want to add, substract, and multiply fields by other fields or by python literals. So now the backend couldn't just be a 1 to 1 mapping between F() expression frontend and backend. The backend also had to be able to evaluate entire trees. FIELD + 1 is actually represented as a tree right? At the top of the tree is the + symbol, on the left of the tree is FIELD, and on the right is the 1. So what the backend here actually did was call evaluate at the top of the tree. The tree would then pass it's children to the backend for preparation, and the backend would call evaluate on each of the children. If you're familiar with the visitor pattern, that's exactly what was implemented here. If you're not familiar with the visitor pattern Eric will explain it later! Anyway from a high level perspective, aggregates and F expressions functioned in a similar way. Users would use the high level classes, and the django backend implementations did all the heavy lifting. This presents a bit of a trade off though. The design allowed for django reimplementations to change how these components were rendered, but it flat out prevented users from adding their own expressions or aggregates without resorting to very private APIs. Adding a frontend class was simple, but it couldn't actually DO anything because there was no way to add your backend implementation. This was a problem I really wanted to solve.
Children Rendered SQL Implementation EXPRESSIONS 1.8 Alright so this is how expressions work today. Regular users don't need to change anything they were doing before. They import the appropriate class, instantiate it, and add it to the queryset. The frontend queryset then passes the expression to the backend queryset as normal. What's different though is that the expression doesn't have a backend implementation anymore. It's passed to the backend query as-is. The difference is how the expression is turned into SQL. When it's time to evaluate all of the expressions, the query calls an as_sql method on the expression. The expression will then recursively call as_sql on all of it's children, so there's none of the back and forth that happened with the F expressions on the last slide. This is what makes it possible for users to create their own expressions now.. they don't have to worry about writing a backend evaluator class. One of the benefits of the previous setup was that different database backends could provide their own implementations. If Sum was actually called Add on a particular database, then that Database could provide an Add backend to the Sum frontend. We've solved this by allowing multiple as_sql implementations directly on the frontend expression. An expression can have an as_sql default, an as_postgres, an as_mysql, or an as_mongo method that produces the correct output for that particular databases. We've pushed all of the SQL differences directly into the expression.
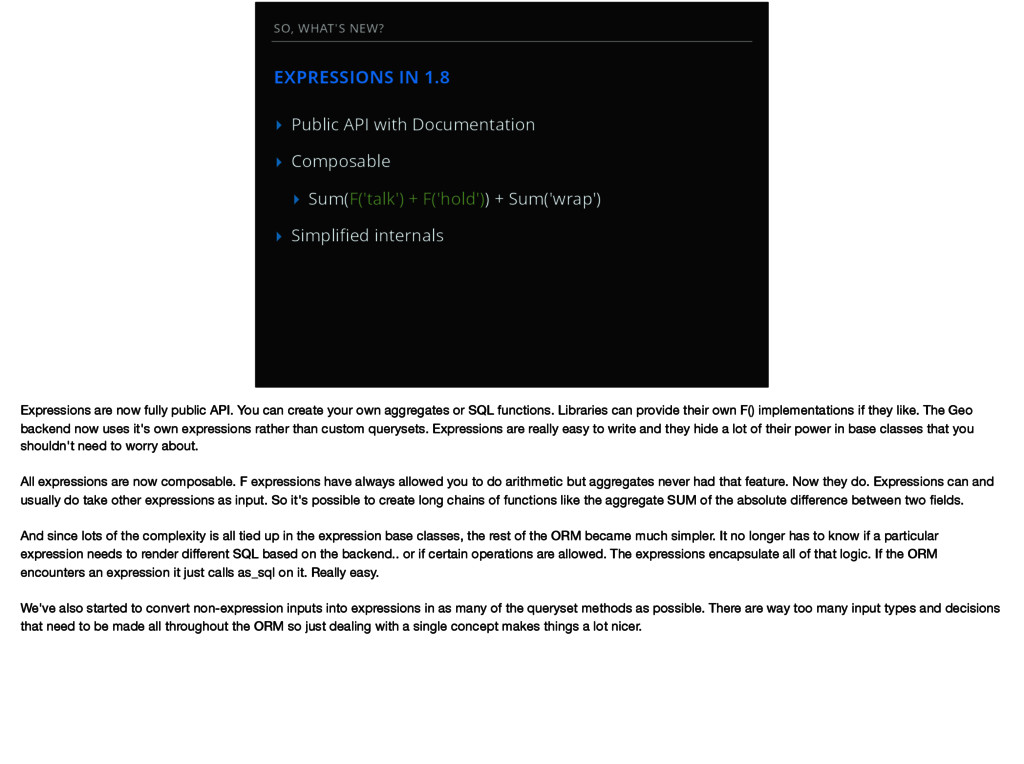
Documentation ▸ Composable ▸ Sum(F('talk') + F('hold')) + Sum('wrap') ▸ Simplified internals Expressions are now fully public API. You can create your own aggregates or SQL functions. Libraries can provide their own F() implementations if they like. The Geo backend now uses it's own expressions rather than custom querysets. Expressions are really easy to write and they hide a lot of their power in base classes that you shouldn't need to worry about. All expressions are now composable. F expressions have always allowed you to do arithmetic but aggregates never had that feature. Now they do. Expressions can and usually do take other expressions as input. So it's possible to create long chains of functions like the aggregate SUM of the absolute difference between two fields. And since lots of the complexity is all tied up in the expression base classes, the rest of the ORM became much simpler. It no longer has to know if a particular expression needs to render different SQL based on the backend.. or if certain operations are allowed. The expressions encapsulate all of that logic. If the ORM encounters an expression it just calls as_sql on it. Really easy. We've also started to convert non-expression inputs into expressions in as many of the queryset methods as possible. There are way too many input types and decisions that need to be made all throughout the ORM so just dealing with a single concept makes things a lot nicer.
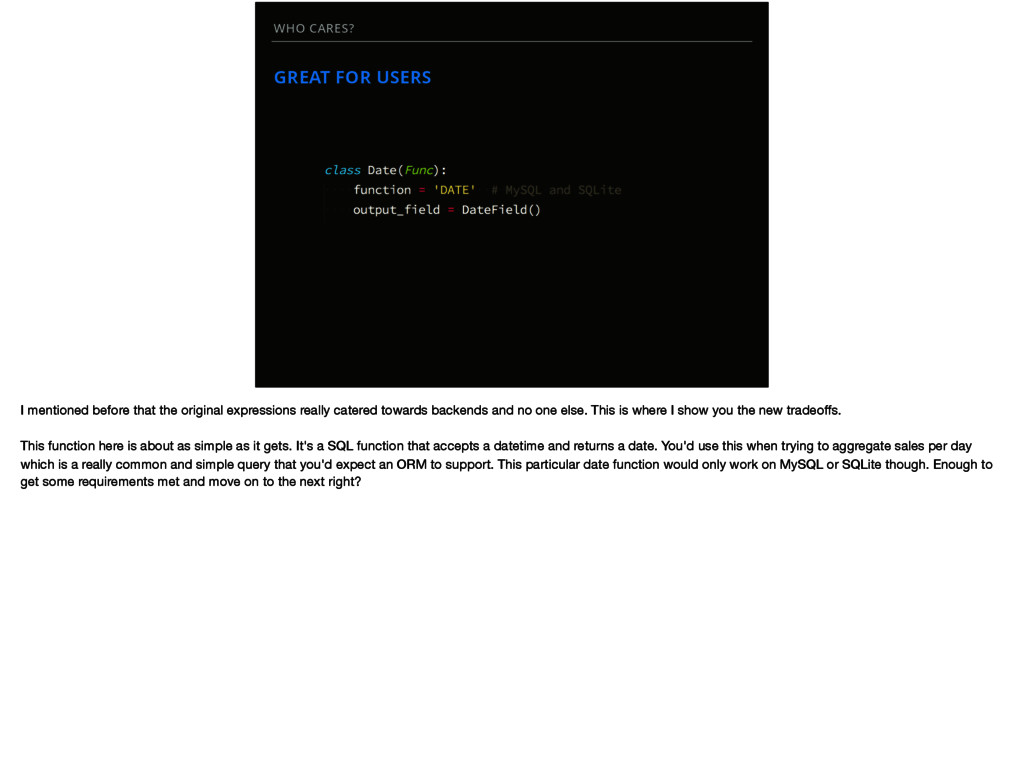
original expressions really catered towards backends and no one else. This is where I show you the new tradeoffs. This function here is about as simple as it gets. It's a SQL function that accepts a datetime and returns a date. You'd use this when trying to aggregate sales per day which is a really common and simple query that you'd expect an ORM to support. This particular date function would only work on MySQL or SQLite though. Enough to get some requirements met and move on to the next right?
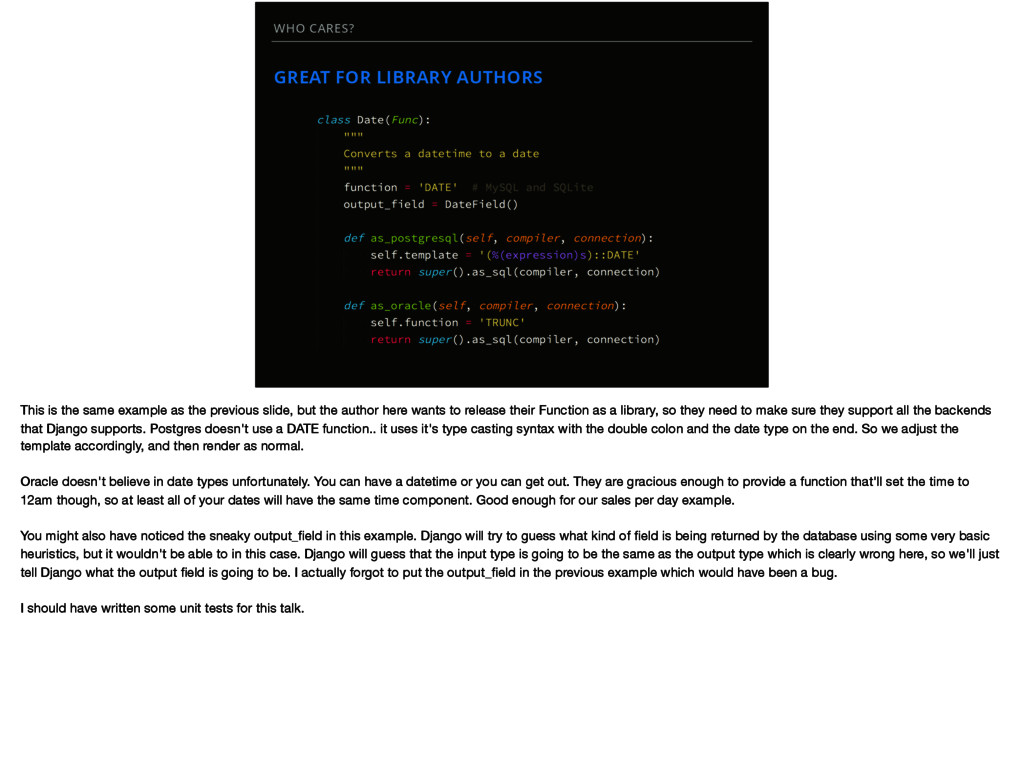
example as the previous slide, but the author here wants to release their Function as a library, so they need to make sure they support all the backends that Django supports. Postgres doesn't use a DATE function.. it uses it's type casting syntax with the double colon and the date type on the end. So we adjust the template accordingly, and then render as normal. Oracle doesn't believe in date types unfortunately. You can have a datetime or you can get out. They are gracious enough to provide a function that'll set the time to 12am though, so at least all of your dates will have the same time component. Good enough for our sales per day example. You might also have noticed the sneaky output_field in this example. Django will try to guess what kind of field is being returned by the database using some very basic heuristics, but it wouldn't be able to in this case. Django will guess that the input type is going to be the same as the output type which is clearly wrong here, so we'll just tell Django what the output field is going to be. I actually forgot to put the output_field in the previous example which would have been a bug. I should have written some unit tests for this talk.
uses Date() so would work with standard implementation. ▸ Monkey patch support for builtins. ▸ Backends can create their own types for obscure functions. See GIS backend. So expressions are great for users and library authors, but what about the 3rd party backends that might like an opportunity to join the party? So I'm of the opinion that support for them is pretty good, but not as good as users or library authors have it. I think that's a fine tradeoff to make, considering the number of projects in each of those 3 groups. If a backend has the same implementation as the default as_sql then they don't need to do anything. It just so happens that the DB2 database uses a DATE function just like mysql and sqlite. No extra work for our dear DB2 friends. Firebird is a database that has a django backend, but it uses CAST AS DATE to convert datetime to date. The only real option for adding support to this function is to monkey patch the appropriate function onto the Date expression. There was a bit of pushback on this decision, but there weren't really any better options put forward other than hiding the monkey patching behind a register function. Backends can also provide their own types. GIS provides quite a few spatial aggregates and transformation functions now, and will be able to deprecate a tonne of code that relies on private django APIs. I'm of the opinion that the 3rd party backend support for expressions should be better now than having to reimplement backend evaluators. The maintainer of the sqlserver backend, Michael, is here today though, and he might have some strong words for me later :)
add custom joins. Must resort to .extra(). ▸ Still early days and a few bugs still to fix. ▸ Documentation and examples. Too many people using ExpressionWrapper(). Expressions are brilliant and there's not a single problem or drawback. Except joins. Expressions are really good at adding columns, and doing other computations. There is zero support for joins. If you reference a field on a related table then that table will be pulled in as normal. But you don't get to ask for an INNER JOIN to some table to restrict the result set coming back. If you need to add arbitrary tables to the query, your options are still just the extra queryset function. Oh, and that won't let you do a LEFT JOIN. Some people have been looking into Model annotations. Which is annotating a model and a Q() object onto an existing query, which is supposed to setup the correct joins. I haven't seen any work on this front in awhile though. If anyone here is keen for a fairly complex hack project, this would be a really good one to look at. There's still a few bugs that are popping up around new expressions. It'd be really nice to have a few more people getting involved with expressions and fixing some of the bugs that come up. If you've ever been scared away from working on the ORM, I'd like to really encourage you to look into Expressions. All new things have bugs though.. and I'm actually pretty happy with the low number. Docs. Tests. It's really hard writing API documentation for concepts. There are lots of base classes that are available to be used, but which do we document? You also run the risk of getting too technical and too detailed and scaring people off. The docs could use a bit of love, especially from people new to the concept. These will only improve, Django has lots of great contributors that help to make the documentation better all the time.
on call center reporting. Well here are some basic models that represent some calls coming in. We're capturing the agent or person that the customer spoke to, how long they spoke, how long the customer was put on hold, and how much time the agent spent on paperwork at the end of the call. We also capture the start time of the call obviously. Agents can belong to teams, but that's not a requirement. See that handle time calculation? That's a standard metric used to measure performance. It measures the total time an agent required to fully handle a phone call. What managers are usually interested in though is the average handle time across a number of calls so they can see trends and whatnot. OK so let's do some live coding.
way too many typos and embarrass myself more than I'm willing to. Ok, so here all we want to do is annotate the name of the team onto the call record. Since teams are optional, we want a default value if the team is null. This is exactly the kind of thing that Coalesce is used to do. On the left here we've solved the problem using expressions. We simply annotate the query with a new column called team, and set it to the name of the team of the agent that made the call. If the agent doesn't have a team, then "No Team" is used. We use Value() here to wrap "No Team" because Coalesce assumes that any strings coming in are field references. The SQL underneath is exactly what you'd expect it to be. It's got all the model columns plus our additional team column. All the joins have been created to pull out the team name, with a LEFT JOIN used for the nullable team relation. Pretty simple so far? On the right is how we'd write the same query with extra. Right away we can see that we've called select_related to ensure that the team table is available to the query. Extra lets you add old style joins, but it doesn't support old style LEFT joins which is what we need here. So I've cheated a little by using this select related. The meat of the query is the extra clause though. We setup the column name team, and then output the exact SQL needed to produce that column. The major difference is that we need to know what the name of the table and column are going to be in SQL. These aren't necessarily going to be the same as our field names, but the conventions are pretty intuitive. If you squint a little, both of these querysets look similar. Looking at the SQL output though reveals a few more differences. The right side includes all of the columns from Agent and from Team. That's a side effect of using
with the previous example but add some aggregation as well. And since we can now, we're going to aggregate over a calculated field. Remember we spoke about measuring average handle time? That's what we're calculating now, but we're calculating it for the entire team. Sally wants to show Bob how much better her sales team is compared to his customer service team. The queryset already has the team added from before. We select the team in the values method to group by it. The annotation is the interesting bit though. If we look at it inside out, we sum the 3 fields together to reach the handle time. It's the same calculation we saw on the model before. But now, we wrap that calculation in an aggregate. It's really intuitive, because it's just how you'd do it in SQL or python. We've assigned the aggregate to the field "aht" above. But naming the aggregation result is optional right? Does anyone know what the generated name would be for that result? ... You can't generate a name from that result. I don't like automatically generated aliases. I never remember if it's supposed to be sum__talk_time or talk_time__sum. And I think the name's look ugly. Old style aggregates that take a single field as input still support automatic names. Every other expression requires them when used as an annotation. Again, the SQL is exactly how I expect it to look. It's also smart enough to replicate the COALESCE in the GROUP BY clause rather than trying to reference it by the name "team". .. That's nice.. Thanks Django :) What I really wanted to do next was write the same query using extra or raw. I tried. Stackoverflow told me I wasn't allowed but I didn't believe it. I tried anyway. Whenever the ORM doesn't work properly people say "USE EXTRA! it sucks but it works". It doesn't work. Not for aggregation. We could use extra to add the Average calculation, and it might even end up correct. But Django doesn't know that you're hand writing an aggregate, so it's not going to
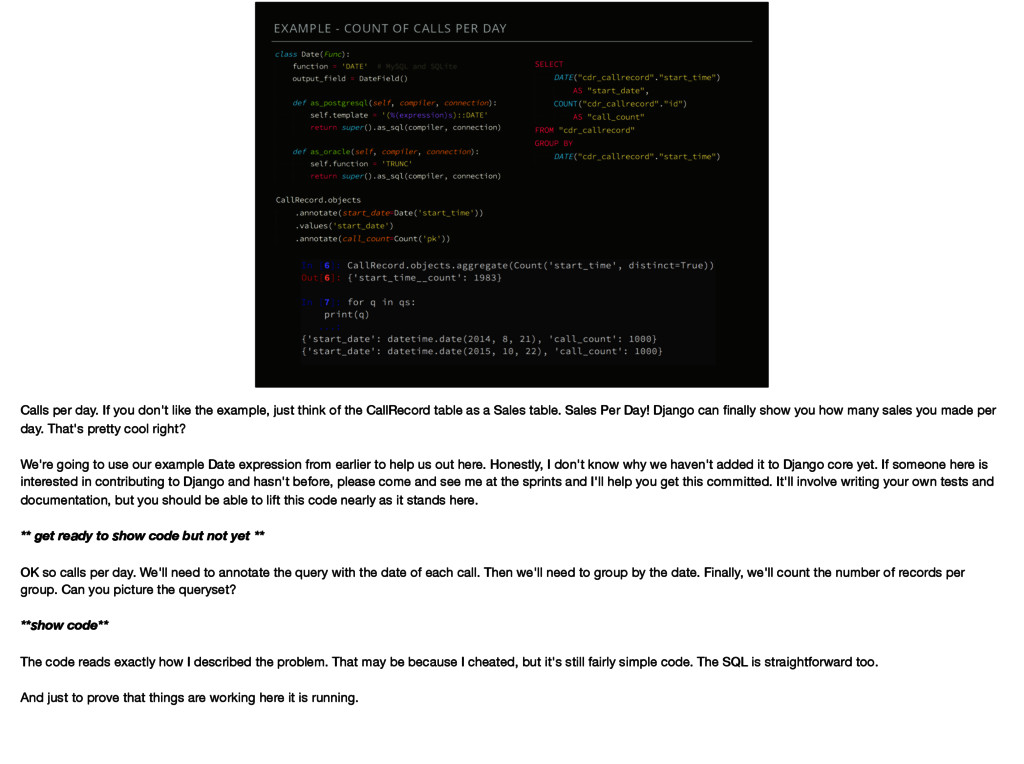
If you don't like the example, just think of the CallRecord table as a Sales table. Sales Per Day! Django can finally show you how many sales you made per day. That's pretty cool right? We're going to use our example Date expression from earlier to help us out here. Honestly, I don't know why we haven't added it to Django core yet. If someone here is interested in contributing to Django and hasn't before, please come and see me at the sprints and I'll help you get this committed. It'll involve writing your own tests and documentation, but you should be able to lift this code nearly as it stands here. ** get ready to show code but not yet ** OK so calls per day. We'll need to annotate the query with the date of each call. Then we'll need to group by the date. Finally, we'll count the number of records per group. Can you picture the queryset? **show code** The code reads exactly how I described the problem. That may be because I cheated, but it's still fairly simple code. The SQL is straightforward too. And just to prove that things are working here it is running.
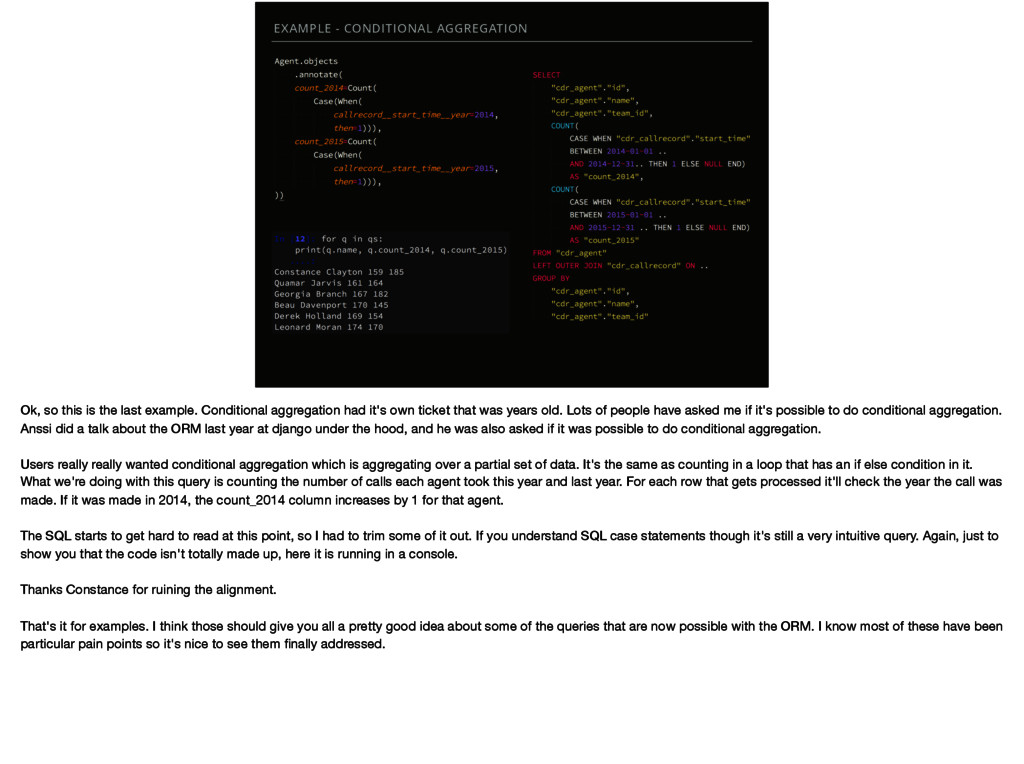
example. Conditional aggregation had it's own ticket that was years old. Lots of people have asked me if it's possible to do conditional aggregation. Anssi did a talk about the ORM last year at django under the hood, and he was also asked if it was possible to do conditional aggregation. Users really really wanted conditional aggregation which is aggregating over a partial set of data. It's the same as counting in a loop that has an if else condition in it. What we're doing with this query is counting the number of calls each agent took this year and last year. For each row that gets processed it'll check the year the call was made. If it was made in 2014, the count_2014 column increases by 1 for that agent. The SQL starts to get hard to read at this point, so I had to trim some of it out. If you understand SQL case statements though it's still a very intuitive query. Again, just to show you that the code isn't totally made up, here it is running in a console. Thanks Constance for ruining the alignment. That's it for examples. I think those should give you all a pretty good idea about some of the queries that are now possible with the ORM. I know most of these have been particular pain points so it's nice to see them finally addressed.
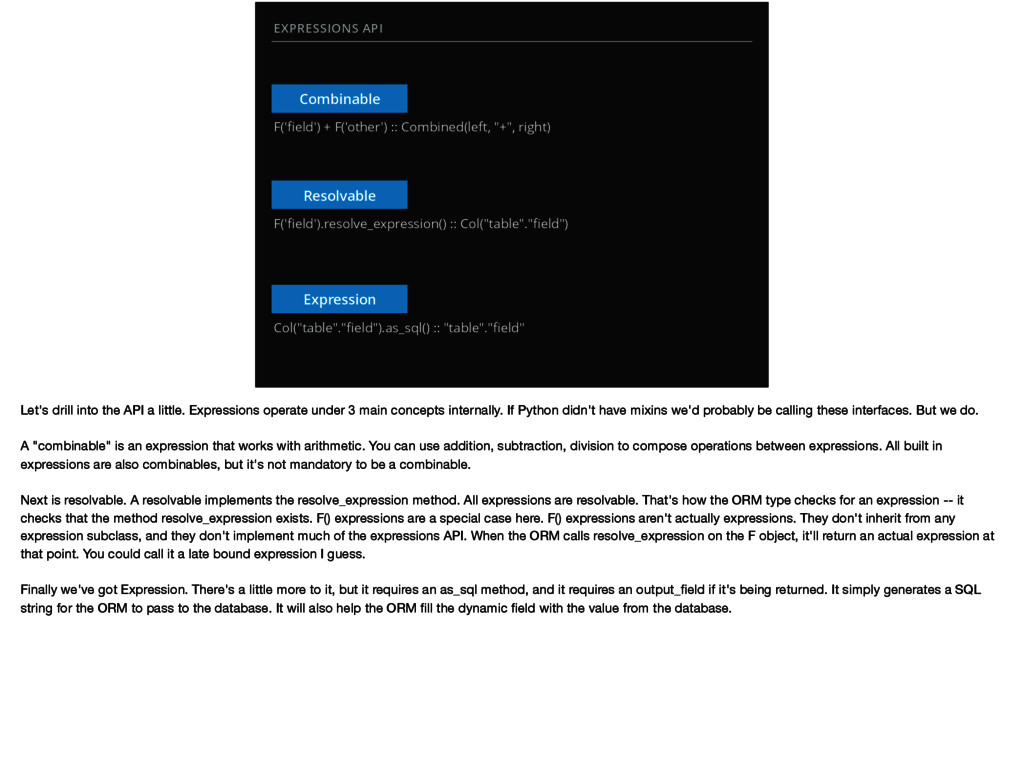
"+", right) F('field').resolve_expression() :: Col("table"."field") Col("table"."field").as_sql() :: "table"."field" Let's drill into the API a little. Expressions operate under 3 main concepts internally. If Python didn't have mixins we'd probably be calling these interfaces. But we do. A "combinable" is an expression that works with arithmetic. You can use addition, subtraction, division to compose operations between expressions. All built in expressions are also combinables, but it's not mandatory to be a combinable. Next is resolvable. A resolvable implements the resolve_expression method. All expressions are resolvable. That's how the ORM type checks for an expression -- it checks that the method resolve_expression exists. F() expressions are a special case here. F() expressions aren't actually expressions. They don't inherit from any expression subclass, and they don't implement much of the expressions API. When the ORM calls resolve_expression on the F object, it'll return an actual expression at that point. You could call it a late bound expression I guess. Finally we've got Expression. There's a little more to it, but it requires an as_sql method, and it requires an output_field if it's being returned. It simply generates a SQL string for the ORM to pass to the database. It will also help the ORM fill the dynamic field with the value from the database.
Returns a new expression or a copy ▸ Sets the new query state Resolve Expression is called on each expression at the time it is added to the query. It has to be called immediately so that the ORM knows what the state of the query was when it was added. It might need to figure out whether to add a field to the GROUP BY based on whether an aggregate has already been added to the query or not. The query calling resolve expression will pass itself into the method. The expression can use the query to inspect the current state and do whatever validation it needs to do. In the case of F() objects, it'll also setup the necessary joins required to link the column reference. It's really important that resolve_expression returns a copy. Expressions can be created in one place and then added to two separate queries. Django can't allow one query to interfere with another. I'll show a better example of this soon.
outputs vendor specific SQL ▸ Compile protocol. compiler.compile() This is where the magic happens. The as_sql method takes all of the inputs and children, and returns the corresponding SQL string to be included in the query. The ORM determines which clause the string is added to. The expression doesn't care. We can see here that it returns the SQL string, and a list of parameters that need to be escaped. The params are passed directly to the database library. If you've got data coming from users and into an expression, then ensure you're using params.
outputs vendor specific SQL ▸ Compile protocol. compiler.compile() The compile protocol is something I made up for this talk. It comes from Anssi and his work with custom lookups and transforms. I was working on expressions at around the same time he was working on lookups, and once I seen this pattern I was extremely happy. This is the magic that lets you write your as_postgresql method and the as_mysql method without having to bother messing around in the backend driver code. compiler.compile() should just about be the only thing that calls as_sql directly. If you need to generate the SQL of sub expressions inside your own expression, then use the compile parameter, and compile the sub expression. It'll take care of vendor specific implementations for you.
▸ convert_value() and db_converters() like to_python() ▸ lookups and transforms So it turns out that generating correct SQL is only half the battle. You then need to get the value the database gives you out, into a consistent python format, and hand it back to the user. And as it so happens, model fields already do this. Backends have appropriate field converters to normalise whatever the database hands back so it made sense to leverage all that power. We need this, so that Django doesn't blow up when SQLite hands you back a string that looks a lot like a date. Model fields also let you use lookups and transforms on expressions which turns out to be really useful. It'll let you filter by month on an expression that returns a date for example.
Aggregates are sort of weird in SQL. If an expression contains an aggregate then all of the select columns need to be added to the group by clause. If there's an aggregate in the query, then the ORM needs to know what expressions need to be added to the group by clause. If a filter references an aggregate, then the filter needs to be added to the HAVING clause rather than the WHERE clause. These 3 methods provide enough information to the ORM so that it can generate a correct aggregate query. Most of the base classes you'll use to build your own expressions have already implemented these methods, so you don't need to worry about them.
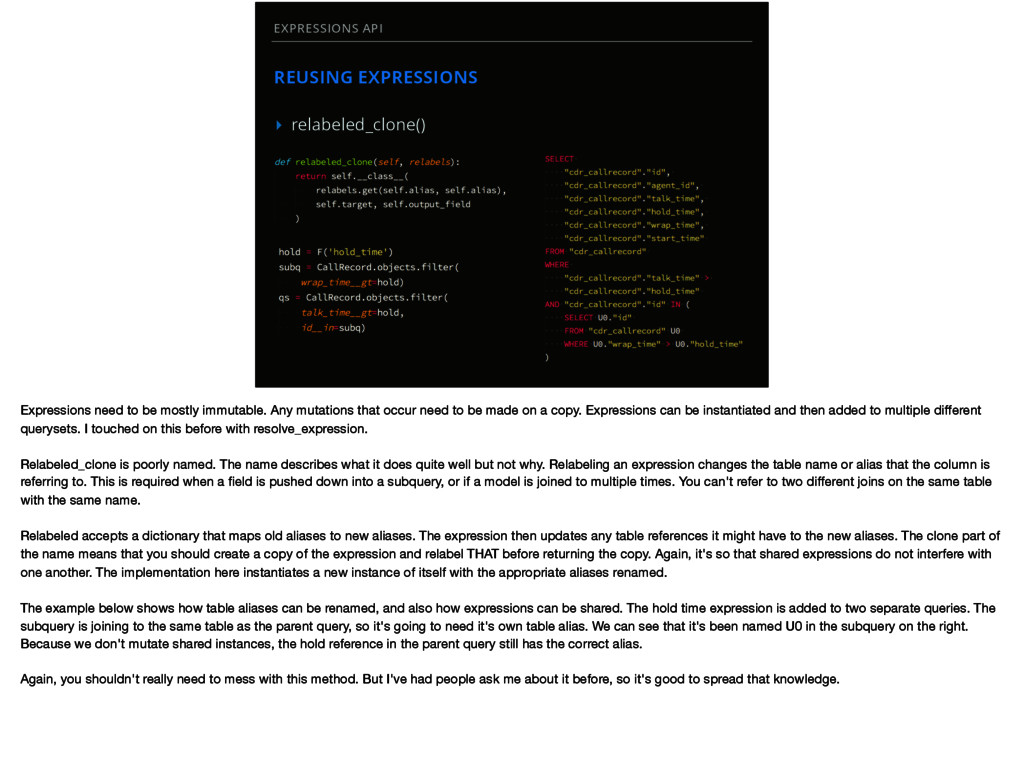
mostly immutable. Any mutations that occur need to be made on a copy. Expressions can be instantiated and then added to multiple different querysets. I touched on this before with resolve_expression. Relabeled_clone is poorly named. The name describes what it does quite well but not why. Relabeling an expression changes the table name or alias that the column is referring to. This is required when a field is pushed down into a subquery, or if a model is joined to multiple times. You can't refer to two different joins on the same table with the same name. Relabeled accepts a dictionary that maps old aliases to new aliases. The expression then updates any table references it might have to the new aliases. The clone part of the name means that you should create a copy of the expression and relabel THAT before returning the copy. Again, it's so that shared expressions do not interfere with one another. The implementation here instantiates a new instance of itself with the appropriate aliases renamed. The example below shows how table aliases can be renamed, and also how expressions can be shared. The hold time expression is added to two separate queries. The subquery is joining to the same table as the parent query, so it's going to need it's own table alias. We can see that it's been named U0 in the subquery on the right. Because we don't mutate shared instances, the hold reference in the parent query still has the correct alias. Again, you shouldn't really need to mess with this method. But I've had people ask me about it before, so it's good to spread that knowledge.
filter() ▸ values() Expressions are really good at representing fragments of SQL. Expect to see them supported in more and more queryset methods as we move forward. We've already got support for order by and filter. I'd really like to see support in the values() method next. At the moment you have to annotate a column and then select the name of the annotation in the values clause. It's usable, but not ideal.
begun proposing new syntaxes for building expressions. The first uses getattribute magic to lookup function names and return the equivalent expression. I really like the look of the lower cased functions compared to instantiating expression functions from the inside out. The second syntax is a nicer way of constructing F objects. String based field names are prone to error so the idea is that building field expressions this way will be easier to reason about. We're not looking to merge either of these into Django right now. They're both still a work in progress, but the suggestion was made that they should be released as libraries first. If one gains enough traction then we'd consider adding it to core.
Analytical/Window functions? ▸ GROUP BY CUBE/ROLLUP ▸ Aggregate FILTER WITH ▸ CTE (Common Table Expressions) I'd really like to see some analytical or window functions being implemented. I don't know if they'd be possible to do with expressions in their current form, but it'd definitely be worth looking into. Window functions typically have extra syntax like OVER clauses and ORDER BY clauses directly within the function, which might make implementing these more difficult. Cube and Rollup are GROUP BY functions that let you summarise data by unique sets, which is useful for providing row totals and column totals. But.. they go directly into the GROUP BY clause, so injecting your own SQL just for the group by may not be possible. Postgres has it's own concept of conditional aggregates which you invoke by adding a FILTER WITH clause within the aggregate definition. For those that know Funkybob on IRC, he was using FILTER WITH in some raw SQL, but hadn't translated it to Django yet. In about 20 minutes he had a working prototype with some help from me. SQL is really really capable, and chances are if you need to harness that power then expressions will be the way to do it. And if you can't do something in Django that you can do in SQL, then please, open a ticket so that we can track the feature. Django has always tried to abstract away the database, which is a fine goal to have. But now we're opening it up for those of you who need more.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}