Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CVPR2025論文紹介:「Unboxed: Geometrically and Tempor...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
村川卓也
August 09, 2025
Research
1.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CVPR2025論文紹介:「Unboxed: Geometrically and Temporally Consistent Video Outpainting」
第62回 名古屋CV・PRML勉強会
村川卓也
August 09, 2025
More Decks by 村川卓也
See All by 村川卓也
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
170
Other Decks in Research
See All in Research
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
480
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.4k
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
380
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
500
Language and AI
ayaniwa
0
180
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
130
2025年度秋葉原ウォーカブルプロジェクト調査報告 「アキバらしいウォーカブル」とは何か
izumiyama_lab
1
130
Model Discovery and Graph Simulation: A Lightweight Gateway to Chaos Engineering
anatolykr
0
240
HackSick vol.7 LT資料【LLMアーキテクチャ入門・事前学習時の躓き所解説】 スパースなAttention・状態空間モデル
rikkabotan7
0
100
全国町字単位空き家率推定データver1.0データ仕様
microbaseinc
0
160
IA for theory
gpeyre
0
300
論文紹介:HalluCitation Matters
wasyro
0
130
Featured
See All Featured
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
A Modern Web Designer's Workflow
chriscoyier
698
190k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
Building AI with AI
inesmontani
PRO
1
1.1k
Chasing Engaging Ingredients in Design
codingconduct
0
250
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
390
How GitHub (no longer) Works
holman
316
150k
Designing Experiences People Love
moore
143
24k
Music & Morning Musume
bryan
47
7.3k
Transcript
Unboxed: Geometrically and Temporally Consistent Video Outpainting 村川卓也(名工大玉木研B4) 2025/8/9 Zhongrui
Yu, Martina Megaro-Boldini, Robert W. Sumner, Abdelaziz Djelouah CVPR2025
Video outpainting ◼時空間的一貫性を保ちながら動画像のフレーム外を拡張する手法 ◼生成品質と計算コストはトレードオフ
概要 ◼従来手法のvideo outpainting • 生成領域の物体生成に弱い • 物体の重複,形状が不安定,消失 • 高解像度化への制約 •
生成時間とVRAM使用量の増加 ◼提案手法 • 3段階の生成 • 静的領域と動的オブジェクトで 個別に生成 入力動画 (左) , 提案手法, MOTIA [Wang+, ECCV2024]の比較
◼Dehan [Dehan+, CVPR2022] • オプティカルフローを用いた時間的一貫性の改善 • 視点の動きが激しい動画や動く物体の生成が困難 ◼M3DDM [Fan+, ACM
MM2023] • Diffusionと3D U-Netを用いたvideo outpainting • 動画全体から抽出したフレームによる時間的一貫性の 改善 • フレーム外情報が少ない動画の生成が困難 ◼MOTIA [Wang+, ECCV2024] • 生成前に入力動画でファインチューニングを行い, 学習動画と異なるドメインの動画の生成に対応 • 他手法と比較して生成時間とVRAM使用量が大幅に増加 • 動的オブジェクトが重複して出現することがある 関連研究
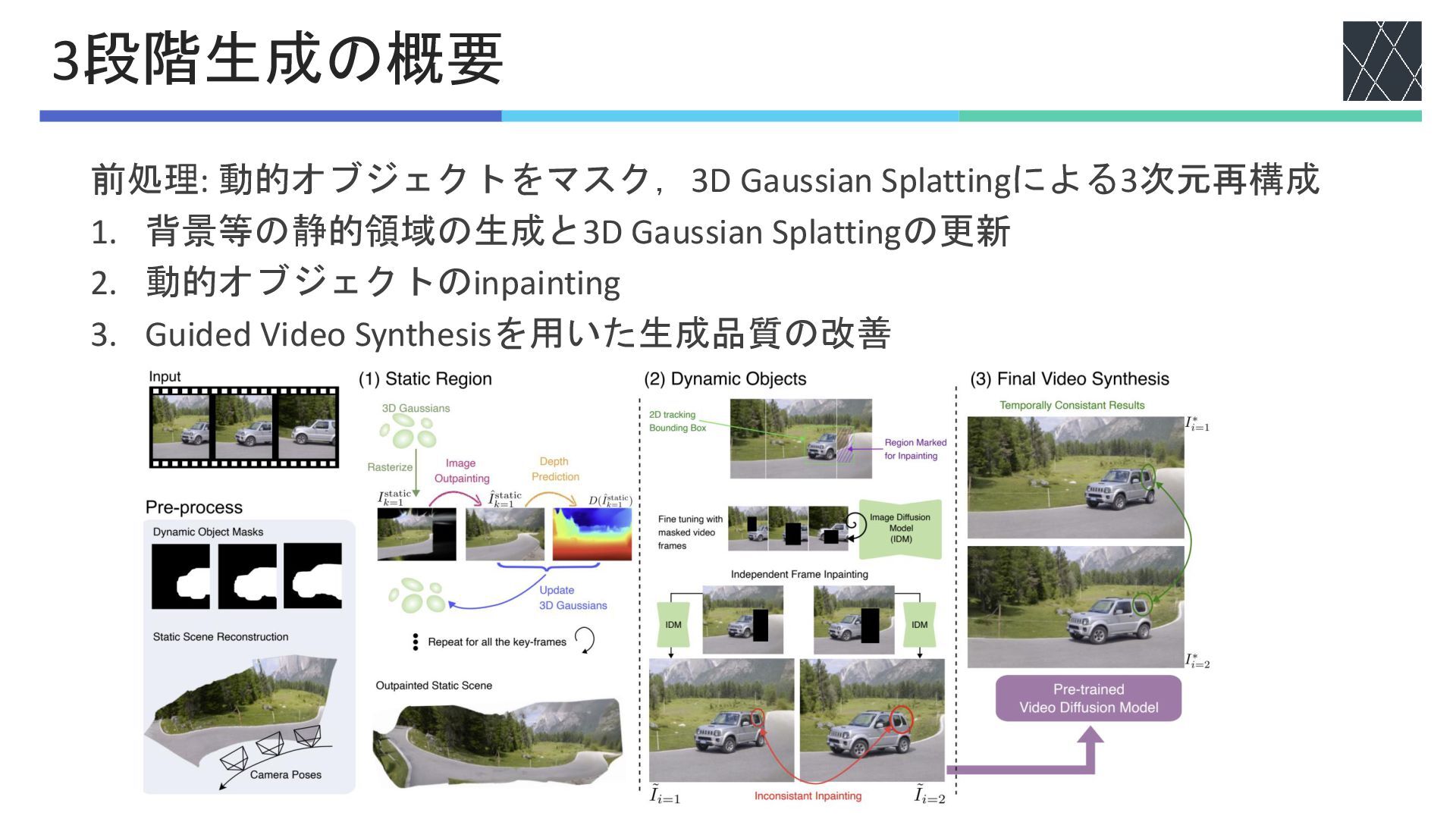
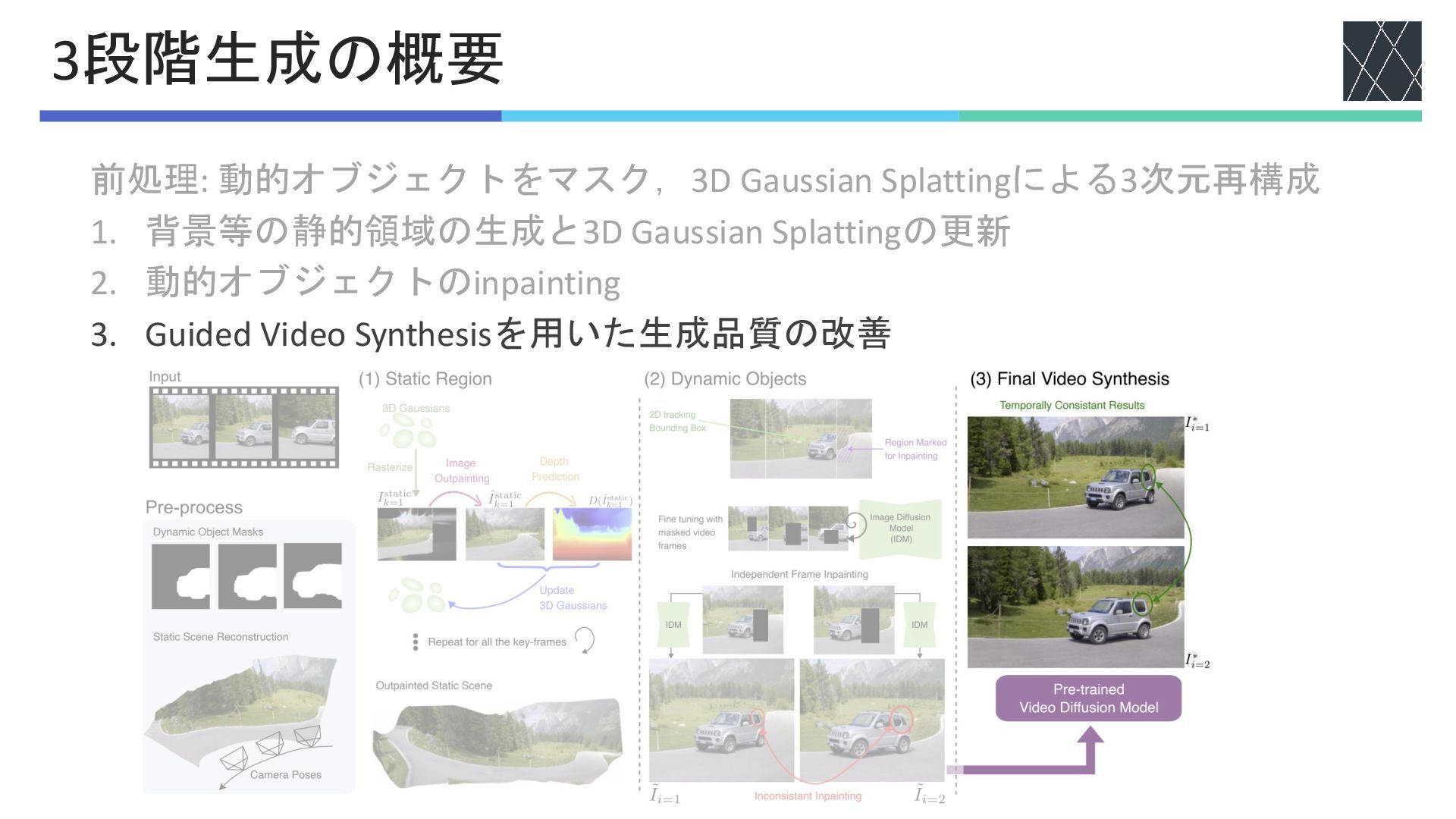
前処理: 動的オブジェクトをマスク,3D Gaussian Splattingによる3次元再構成 1. 背景等の静的領域の生成と3D Gaussian Splattingの更新 2. 動的オブジェクトのinpainting
3. Guided Video Synthesisを用いた生成品質の改善 3段階生成の概要
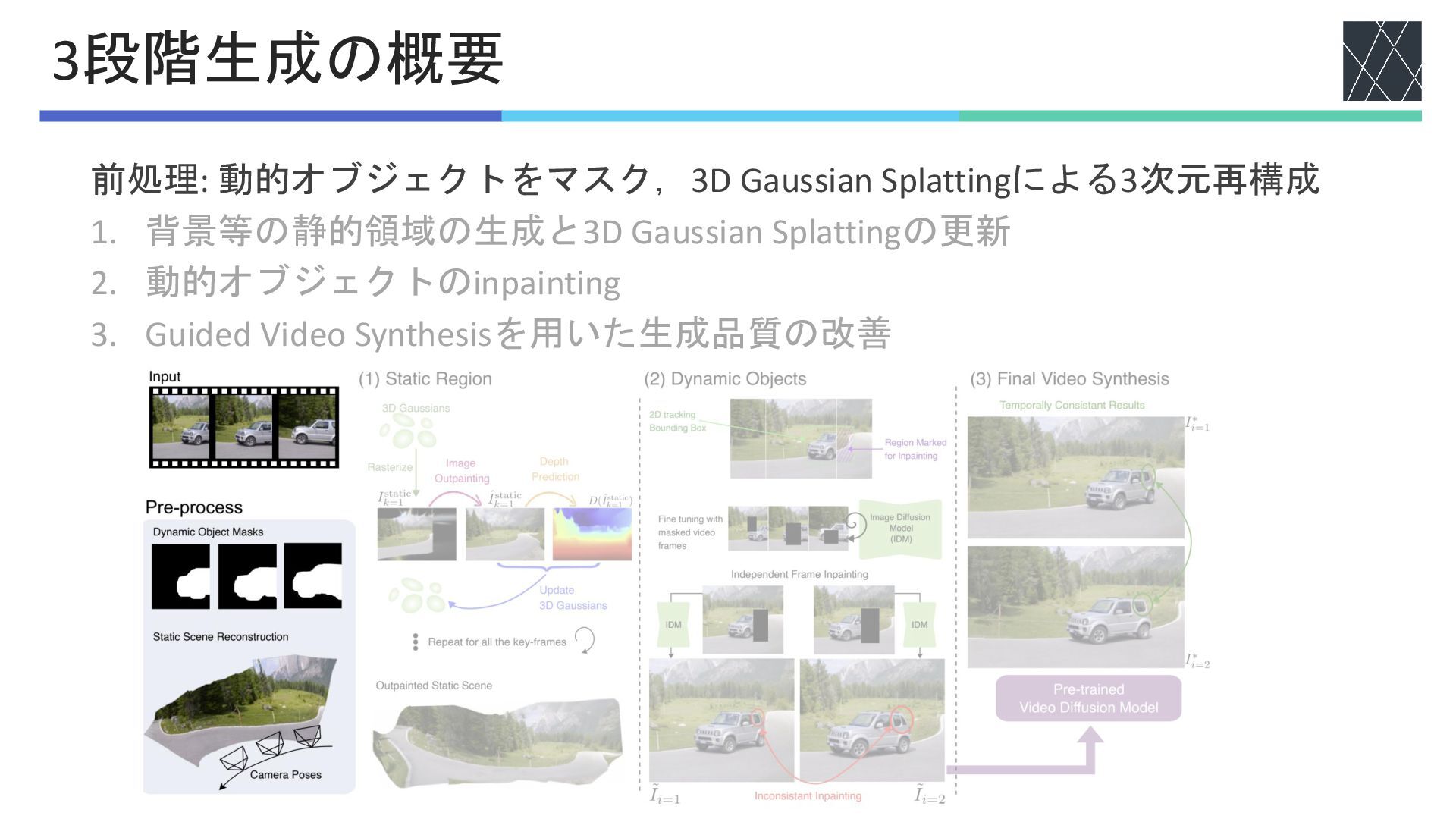
前処理: 動的オブジェクトをマスク,3D Gaussian Splattingによる3次元再構成 1. 背景等の静的領域の生成と3D Gaussian Splattingの更新 2. 動的オブジェクトのinpainting
3. Guided Video Synthesisを用いた生成品質の改善 3段階生成の概要
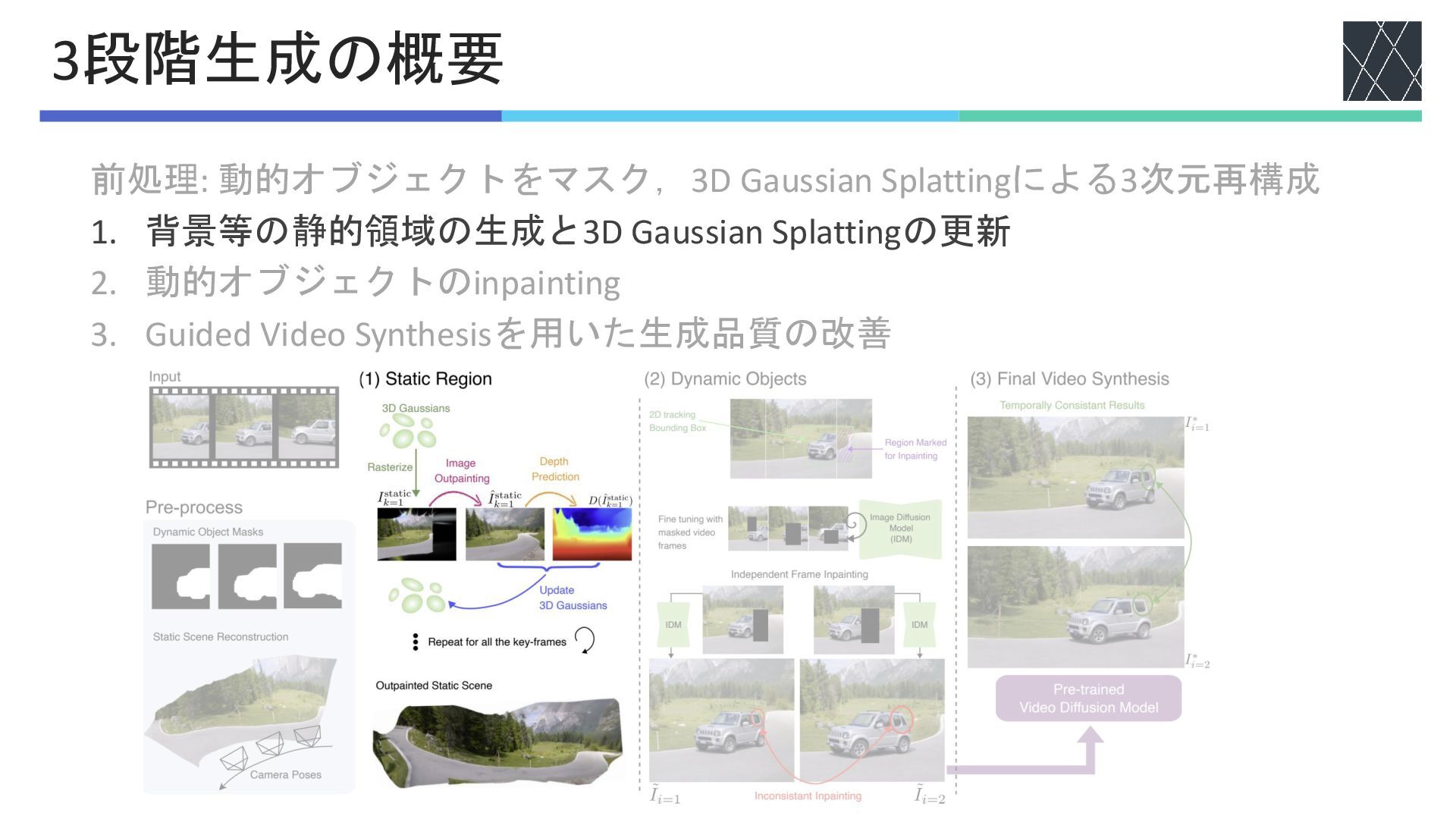
前処理: 動的オブジェクトをマスク,3D Gaussian Splattingによる3次元再構成 1. 背景等の静的領域の生成と3D Gaussian Splattingの更新 2. 動的オブジェクトのinpainting
3. Guided Video Synthesisを用いた生成品質の改善 3段階生成の概要
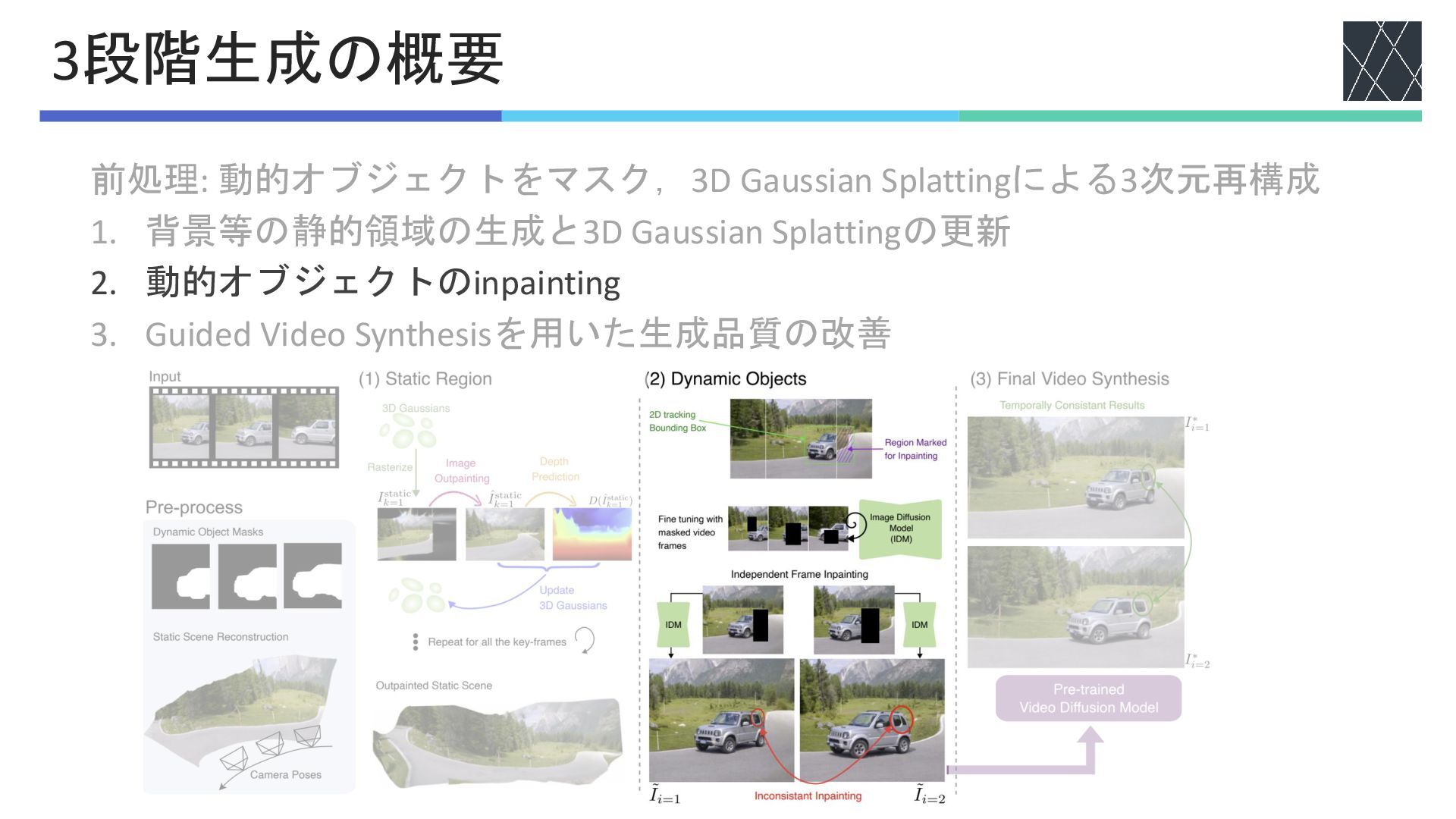
前処理: 動的オブジェクトをマスク,3D Gaussian Splattingによる3次元再構成 1. 背景等の静的領域の生成と3D Gaussian Splattingの更新 2. 動的オブジェクトのinpainting
3. Guided Video Synthesisを用いた生成品質の改善 3段階生成の概要
前処理: 動的オブジェクトをマスク,3D Gaussian Splattingによる3次元再構成 1. 背景等の静的領域の生成と3D Gaussian Splattingの更新 2. 動的オブジェクトのinpainting
3. Guided Video Synthesisを用いた生成品質の改善 3段階生成の概要
◼3D Gaussian Splatting • 3Dガウス分布を使用して2次元の 入力動画の3次元復元を行う 3D Gaussian SplattingとInpainting ◼Inpainting
• フレーム内のマスク部分や欠損部分 を生成 [Suvorov+, arXiv2021] [Kerbl+, arXiv2023] 入力画像 生成画像
◼動的オブジェクトをマスク 1. SAM2 [Ravi+, arXiv2024]でセグメンテーション 2. エピポーラ誤差で動的オブジェクトのセグメント を判別してマスク ◼3D Gaussian
Splatting (GS) [Kerbl+, SIGGRAPH2024]で3次元再構成 前処理
◼静的領域の生成と3D GSの更新 1. Stable Diffusion XL [Podell+, arXiv2023] (SDXL)でフ レーム外をimage
outpainting 2. 画像再構成損失(L1, SSIM)と深度損失 [Piccinelli+, CVPR2024]を最適化 3. 生成領域を3D GSモデルに反映 生成1:静的領域の生成
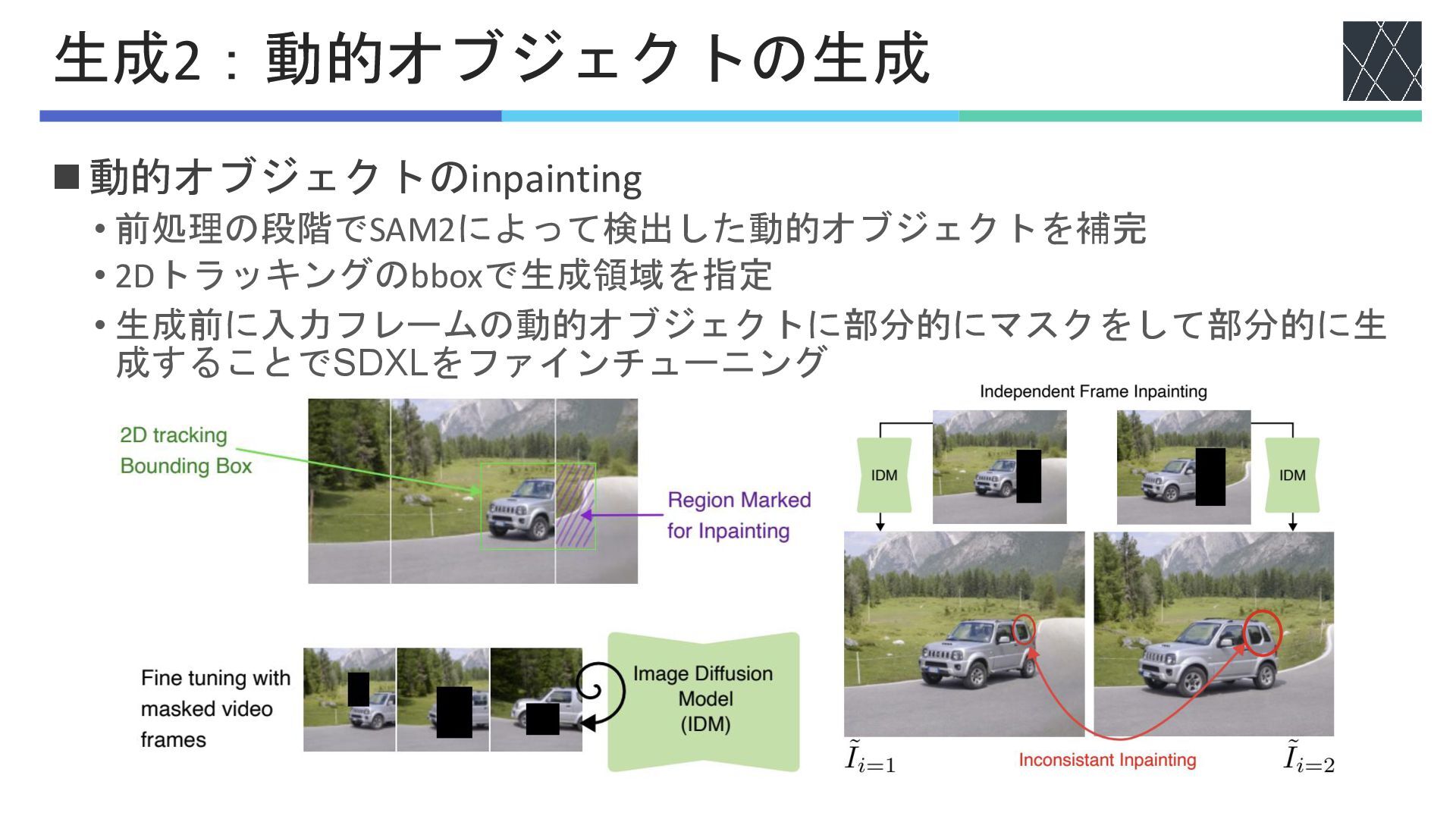
◼動的オブジェクトのinpainting • 前処理の段階でSAM2によって検出した動的オブジェクトを補完 • 2Dトラッキングのbboxで生成領域を指定 • 生成前に入力フレームの動的オブジェクトに部分的にマスクをして部分的に生 成することでSDXLをファインチューニング 生成2:動的オブジェクトの生成
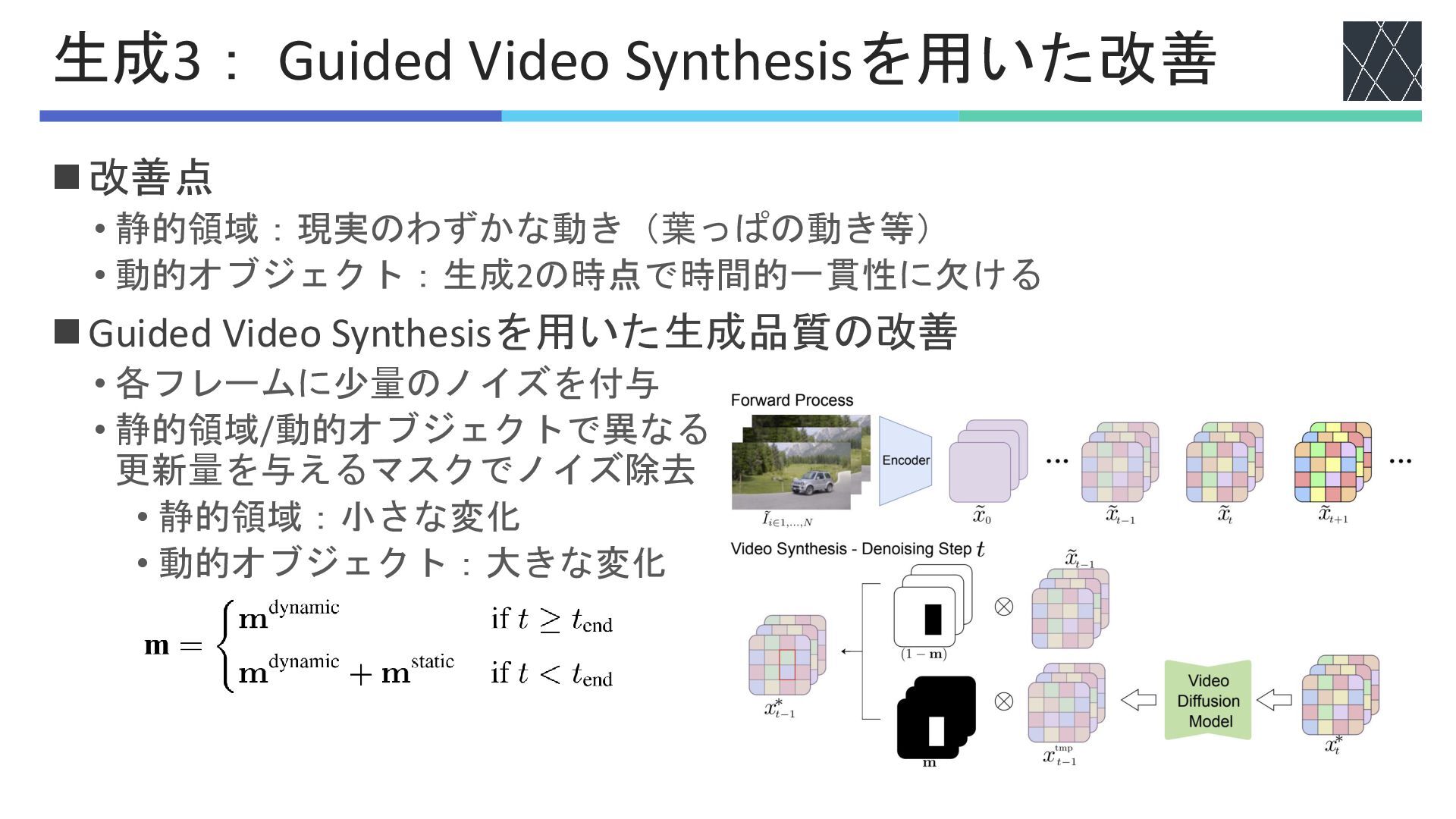
◼改善点 • 静的領域:現実のわずかな動き(葉っぱの動き等) • 動的オブジェクト:生成2の時点で時間的一貫性に欠ける ◼Guided Video Synthesisを用いた生成品質の改善 • 各フレームに少量のノイズを付与
• 静的領域/動的オブジェクトで異なる 更新量を与えるマスクでノイズ除去 • 静的領域:小さな変化 • 動的オブジェクト:大きな変化 生成3: Guided Video Synthesisを用いた改善
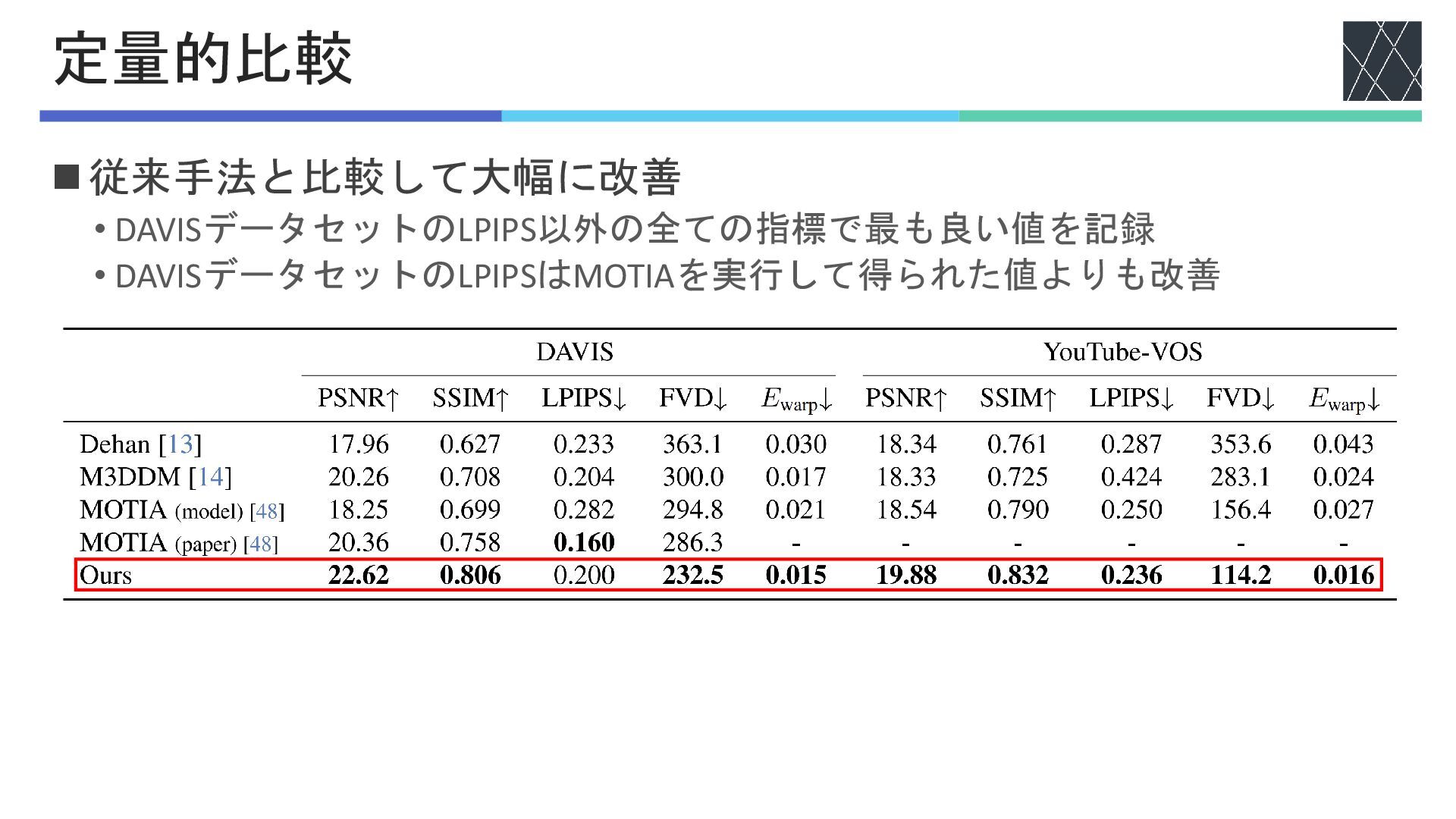
◼評価データセット • DAVIS [Perazzi+, CVPR2016] • YouTube-VOS [Xu+, arXiv2018] ◼実験方法
• 各動画の左右25%, 66%をマスク • 25%, 66%で得られた値を平均 実験設定 ◼評価指標 • PSNR↑ • 生成後の画像の類似度 • SSIM↑ • 生成後の構造的な見た目の類似度 • LPIPS↓ [Zhang+, CVPR2018] • 視覚的類似度 • FVD↓ [Unterthiner+, arXiv2018] • 生成動画と入力動画の特徴分布の距離 • Ewarp ↓ [Lai+, ECCV2018] • ワープ誤差による時間的一貫性の定量 化
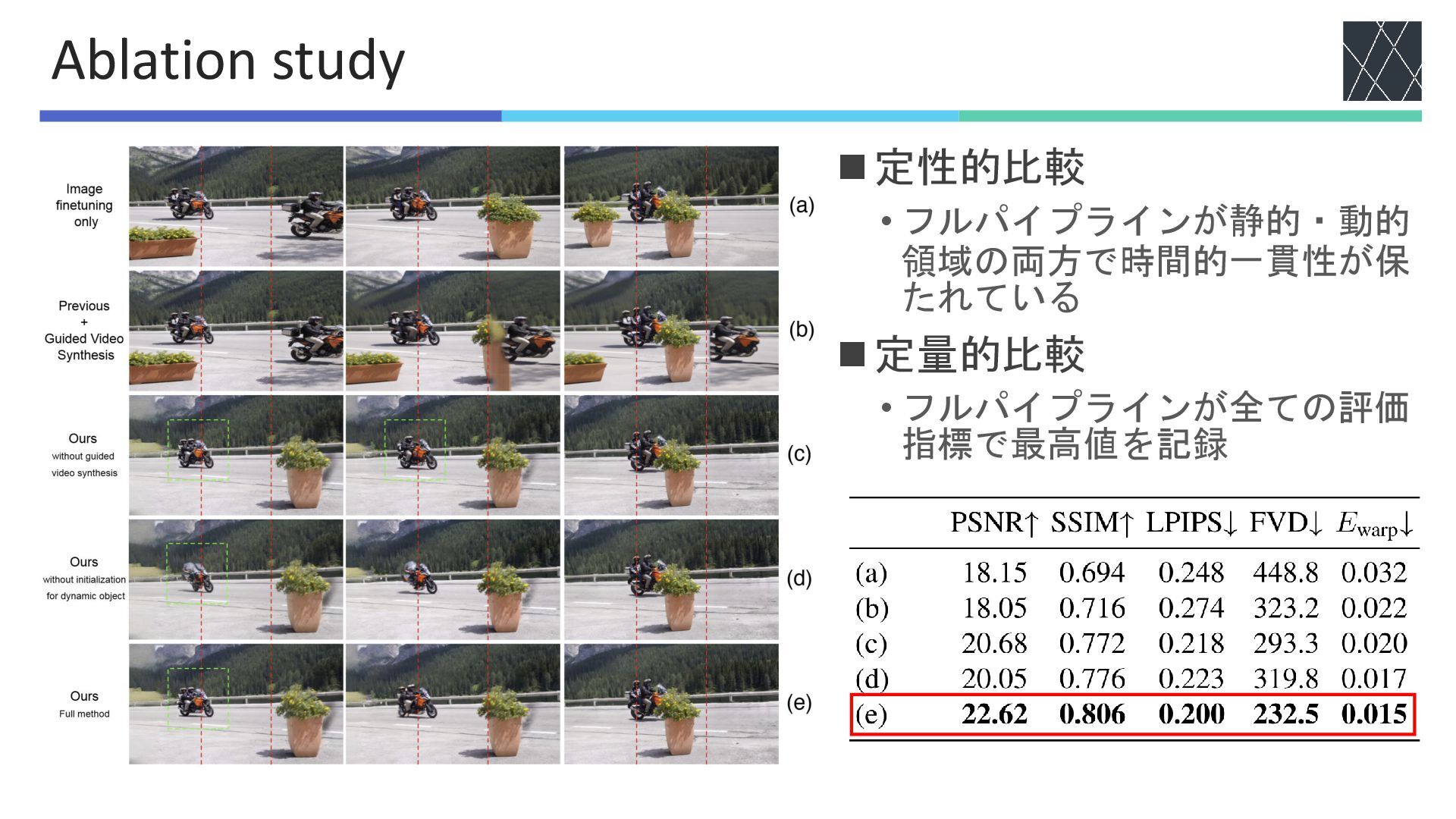
◼従来手法 • 生成失敗,ぼやけた生成 • 元フレームと生成領域の境界が 不自然 • 生成領域の物体の形状が不安定 ◼提案手法 •
元フレームと生成領域の一貫性 の向上 • 物体の自然な生成 定性的比較1
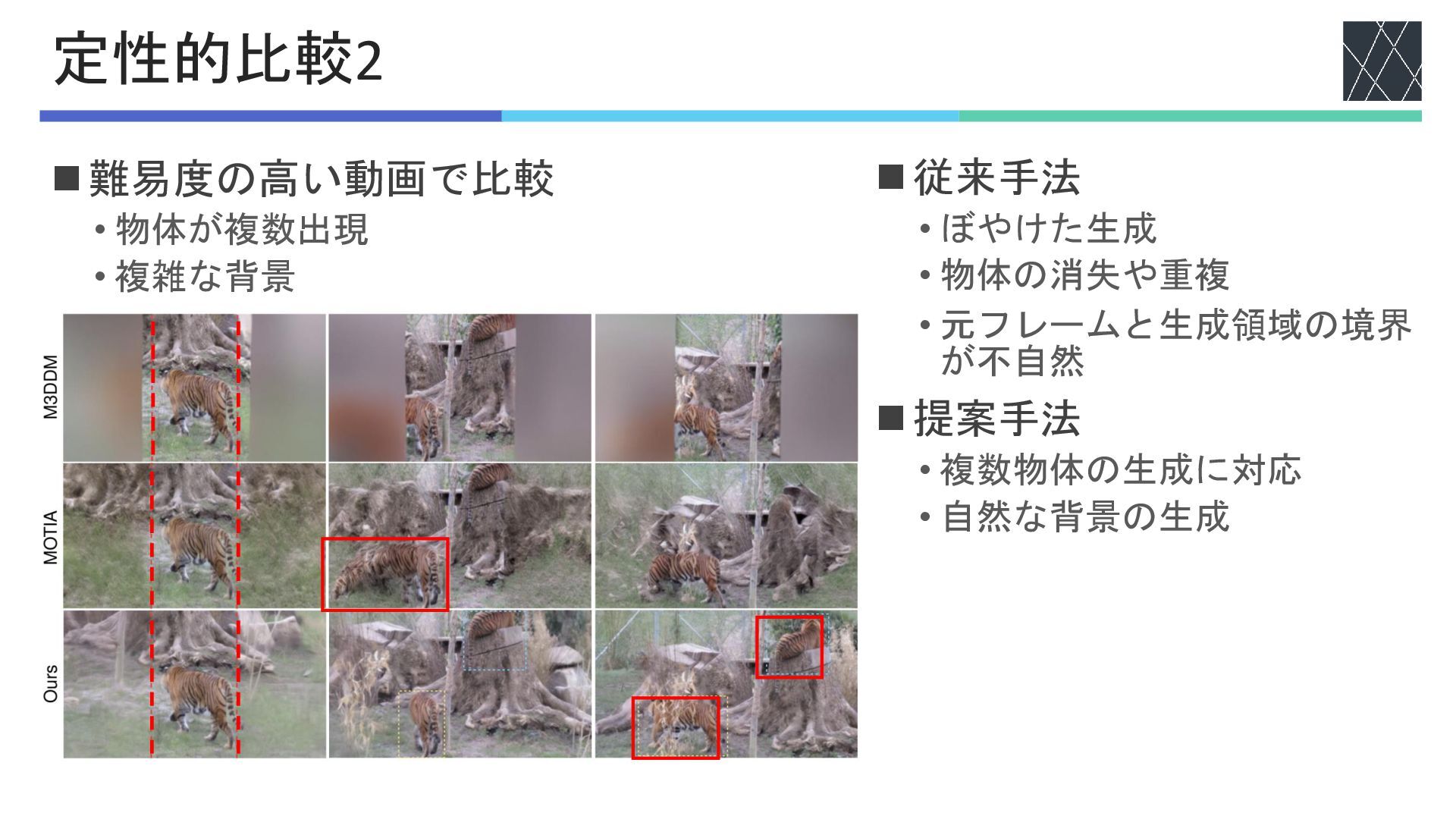
◼難易度の高い動画で比較 • 物体が複数出現 • 複雑な背景 定性的比較2 ◼従来手法 • ぼやけた生成 •
物体の消失や重複 • 元フレームと生成領域の境界 が不自然 ◼提案手法 • 複数物体の生成に対応 • 自然な背景の生成
◼従来手法と比較して大幅に改善 • DAVISデータセットのLPIPS以外の全ての指標で最も良い値を記録 • DAVISデータセットのLPIPSはMOTIAを実行して得られた値よりも改善 定量的比較
◼定性的比較 • フルパイプラインが静的・動的 領域の両方で時間的一貫性が保 たれている ◼定量的比較 • フルパイプラインが全ての評価 指標で最高値を記録 Ablation
study
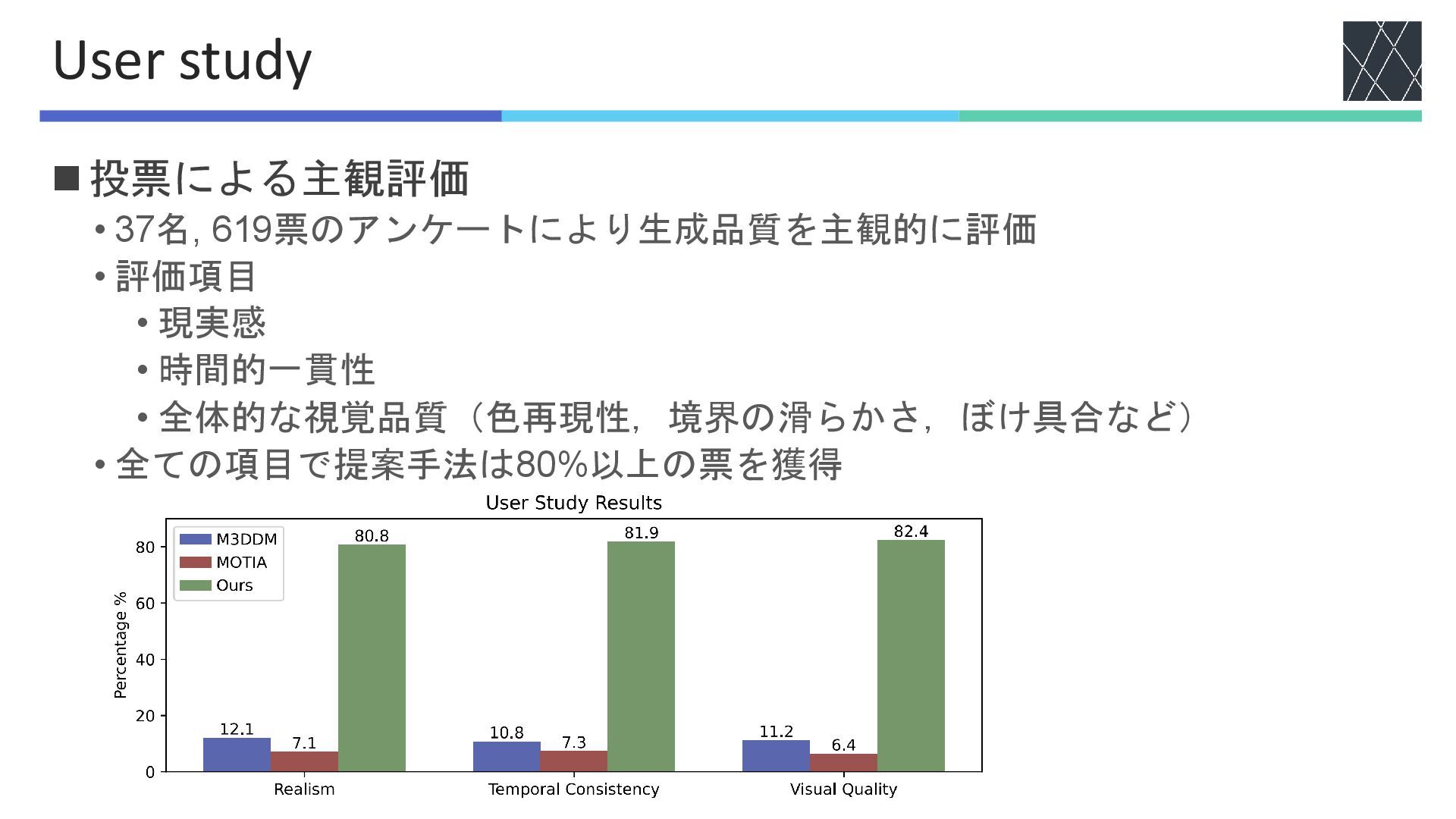
◼投票による主観評価 • 37名, 619票のアンケートにより生成品質を主観的に評価 • 評価項目 • 現実感 • 時間的一貫性
• 全体的な視覚品質(色再現性,境界の滑らかさ,ぼけ具合など) • 全ての項目で提案手法は80%以上の票を獲得 User study
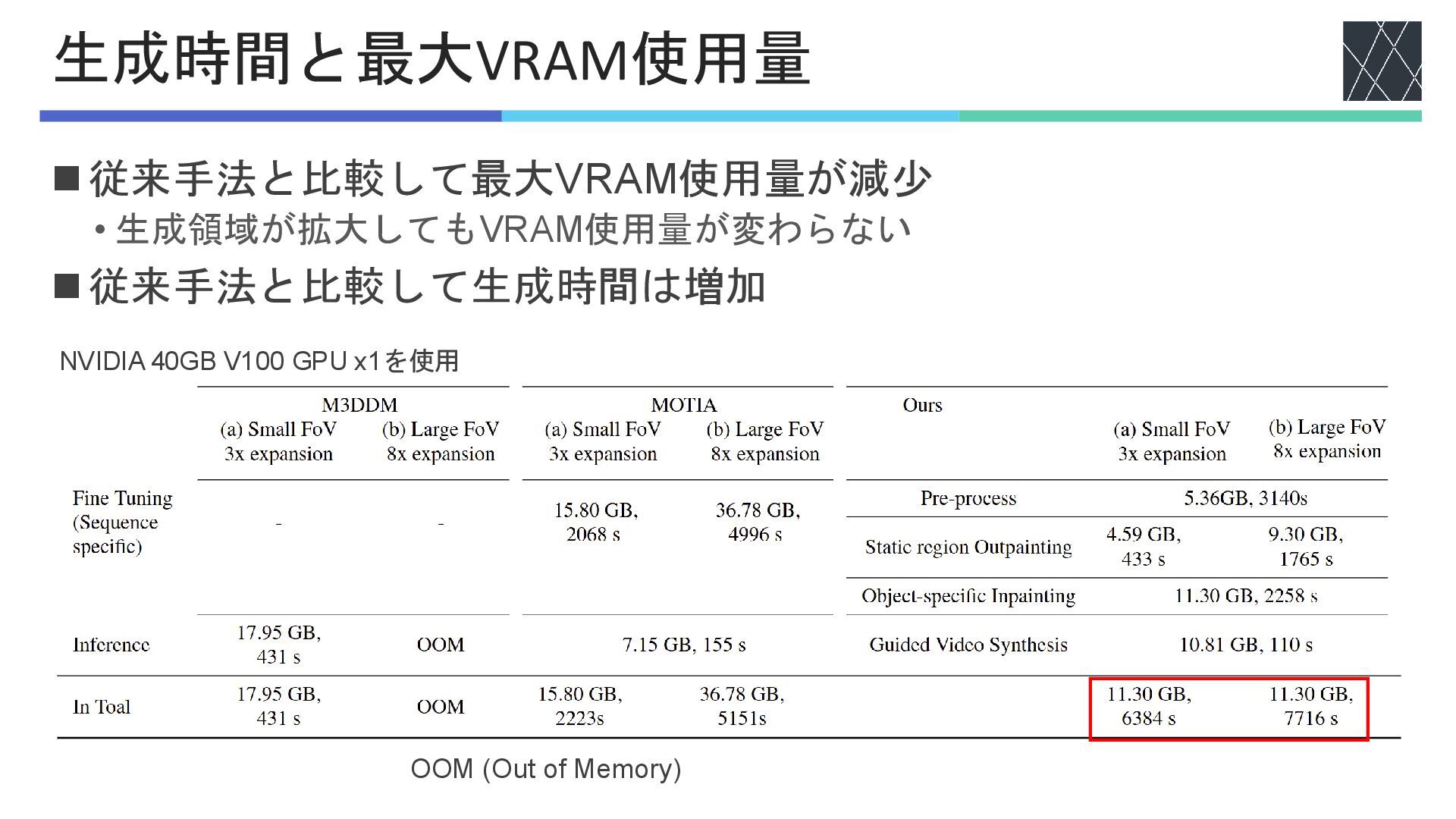
◼従来手法と比較して最大VRAM使用量が減少 • 生成領域が拡大してもVRAM使用量が変わらない ◼従来手法と比較して生成時間は増加 生成時間と最大VRAM使用量 OOM (Out of Memory) NVIDIA
40GB V100 GPU x1を使用
◼3段階の生成 1. 背景等の静的領域の生成と3D Gaussian Splattingの更新 2. 動的オブジェクトのinpainting 3. Guided Video
Synthesisを用いた生成品質の改善 ◼従来手法との比較 • 動的オブジェクトの時間的一貫性を改善 • 全ての評価指標で高い値 • 投票の主観的評価で80%以上の票を獲得 • 最大VRAM使用量が最も少ない • 高解像度の生成でも使用量が不変 • 生成時間は増加 まとめ
{kind=link}
{kind=link}
{kind=link}
![◼Dehan [Dehan+, CVPR2022] • オプティカルフローを用いた時間的一貫性の改善 • 視点の動きが激しい動画や動く物体の生成が困難 ◼M3DDM [Fan+, ACM](https://files.speakerdeck.com/presentations/6282c026799e4c8bafe8ada4c28baba9/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![◼動的オブジェクトをマスク 1. SAM2 [Ravi+, arXiv2024]でセグメンテーション 2. エピポーラ誤差で動的オブジェクトのセグメント を判別してマスク ◼3D Gaussian](https://files.speakerdeck.com/presentations/6282c026799e4c8bafe8ada4c28baba9/slide_10.jpg){kind=link}
![◼静的領域の生成と3D GSの更新 1. Stable Diffusion XL [Podell+, arXiv2023] (SDXL)でフ レーム外をimage](https://files.speakerdeck.com/presentations/6282c026799e4c8bafe8ada4c28baba9/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
![◼評価データセット • DAVIS [Perazzi+, CVPR2016] • YouTube-VOS [Xu+, arXiv2018] ◼実験方法](https://files.speakerdeck.com/presentations/6282c026799e4c8bafe8ada4c28baba9/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}