formats 4 thoughts : i. Aren't structured formats like JSON, XML, HTML well-served by existing parsers ? ii. Parsing log files & configuration files are easy with python. iii. Regular expression is good enough. 3 How to parse texts with PEGs NLTK iv. What is wrong with the classical way of writing parsers ?
suitable for modeling both natural & computer languages. 4 BNF is the defacto notation for describing syntax of CFGs. if_stmt ::= "if" expression ":" suite ( "elif" expression ":" suite )* [ "else" ":" suite ] EBNF Original BNF only supported recursion. sequence, decision(choice) repetition, recursion S S → a S → Ɛ
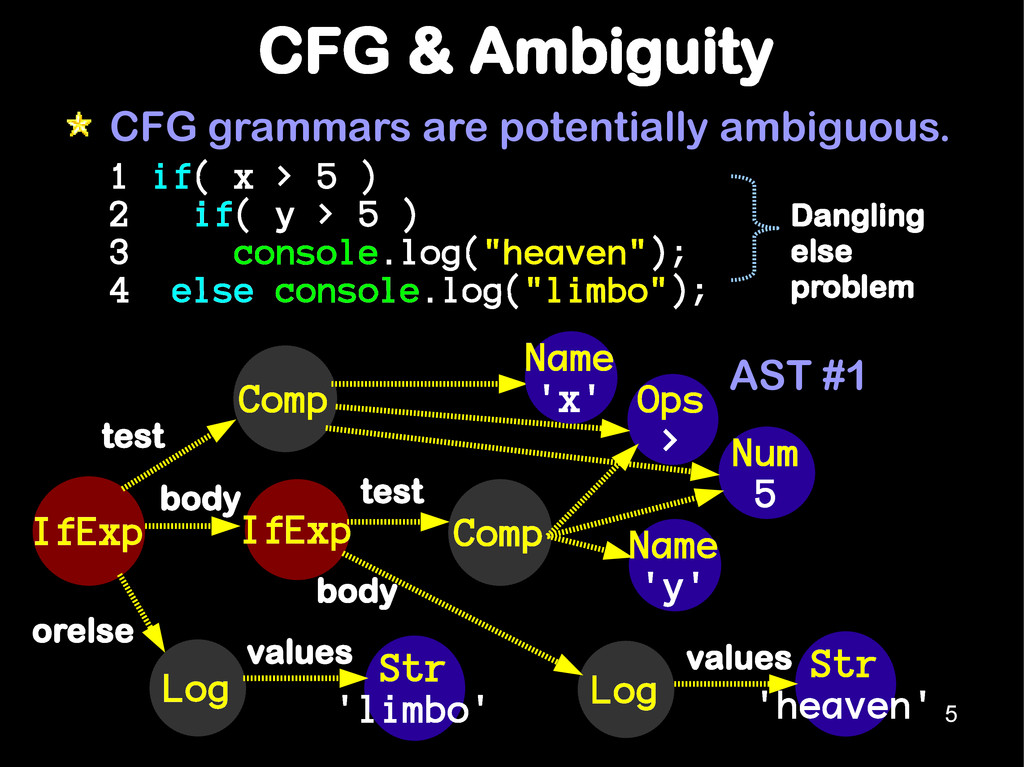
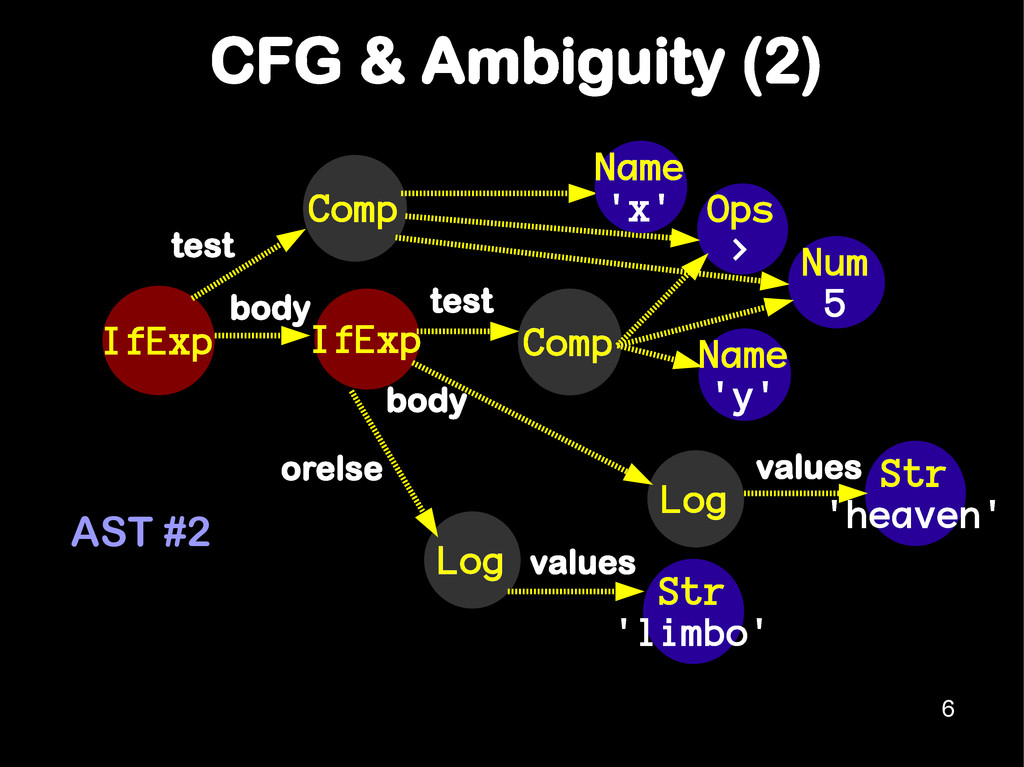
problem 1 if( x > 5 ) 2 if( y > 5 ) 3 console.log("heaven"); 4 else console.log("limbo"); IfExp IfExp Comp Name 'x' Ops > Log test Num 5 body orelse Str 'limbo' values Comp Name 'x' Name 'y' test Str 'heaven' Log values body AST #1 5
whitespace, braces, semicolons = abstract = begin with start nonterminal. = work down the parse tree. = identify terminals = infer nonterminals = climb the parse tree. = nodes are nonterminals from grammar = uses tree nodes specific to language constructs
constructed from recursive functions. * Each function represents a rule in the grammar. version ::= <digit> '.' <digit> digit ::= '0' | '1' ... | '9' def version( source, position=0 ): digit( source, position ) period( source, position + 1 ) digit( source, position + 2 ) Run (pymeta) nose --nocapture -v test_rdp_list.py
a recursive descent parser (+ backtracking). 14 A PEG grammar consists of a set of parsing expressions of the form: A e → One expression is denoted the starting expression e1 / e2 Ordered Choice e1 e2 Sequence e+ e? e* Repetition &e !e Predicates PEG != EBNF
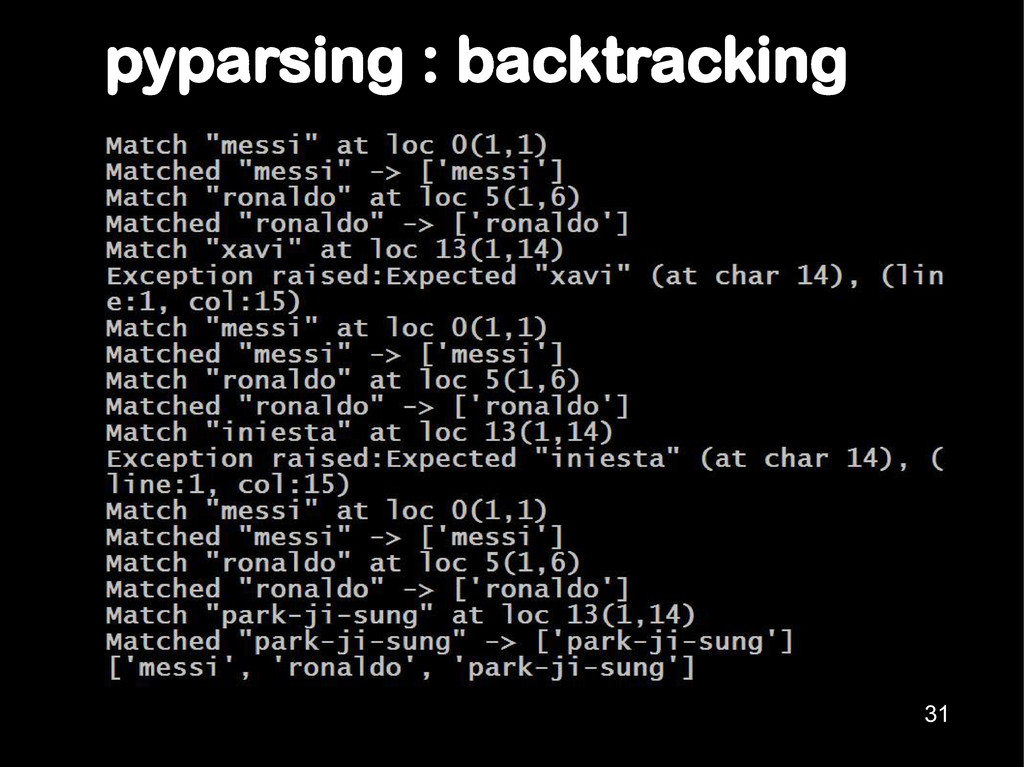
an input string of “Hitchens”, what is the result of the parse ? Law #1: Given an input of A, the parsing expression matches a prefix A' of A or fails. Law #2: A rule S -> M / N will try to parse for a M. If that fails, backtrack & look for N. Answer: Hitch 15
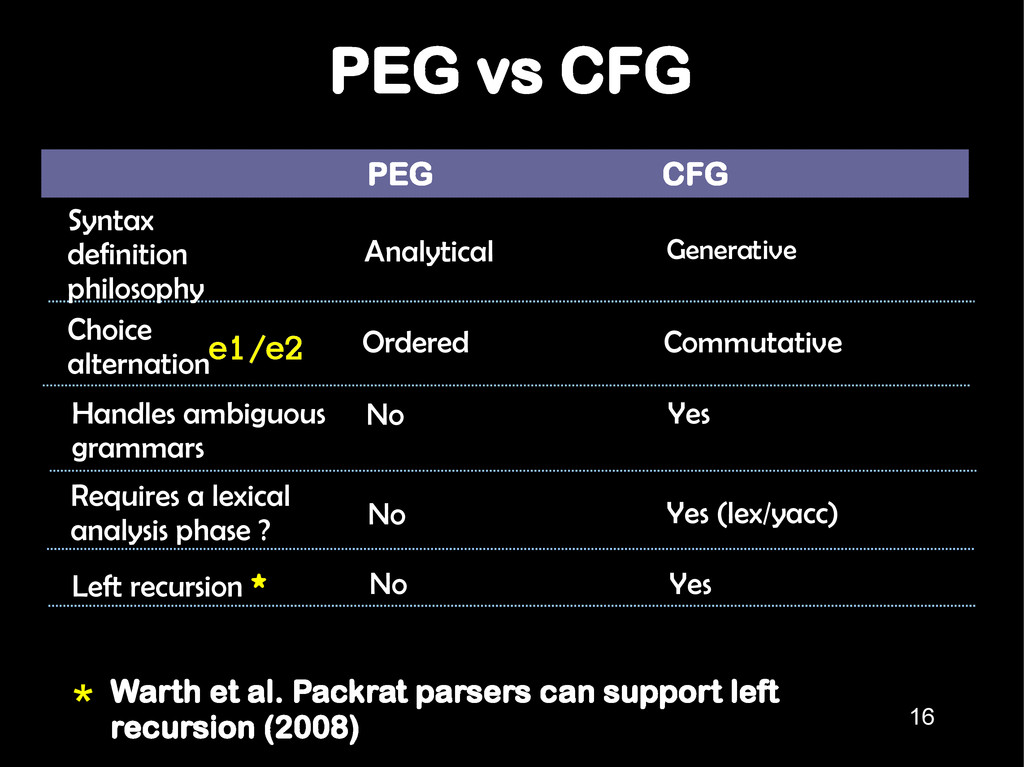
Syntax definition philosophy Analytical Generative Requires a lexical analysis phase ? No Yes (lex/yacc) Choice alternation Ordered Commutative e1/e2 16 Left recursion * No Yes * Warth et al. Packrat parsers can support left recursion (2008)
linear time performance. Context: recursive descent parsing with backtracking Problem: an input substring might be re-parsed during backtracking. grammar ::= AB | AC Photo attribution: http://en.wikipedia.org/wiki/File:Neotoma_cinerea.jpg
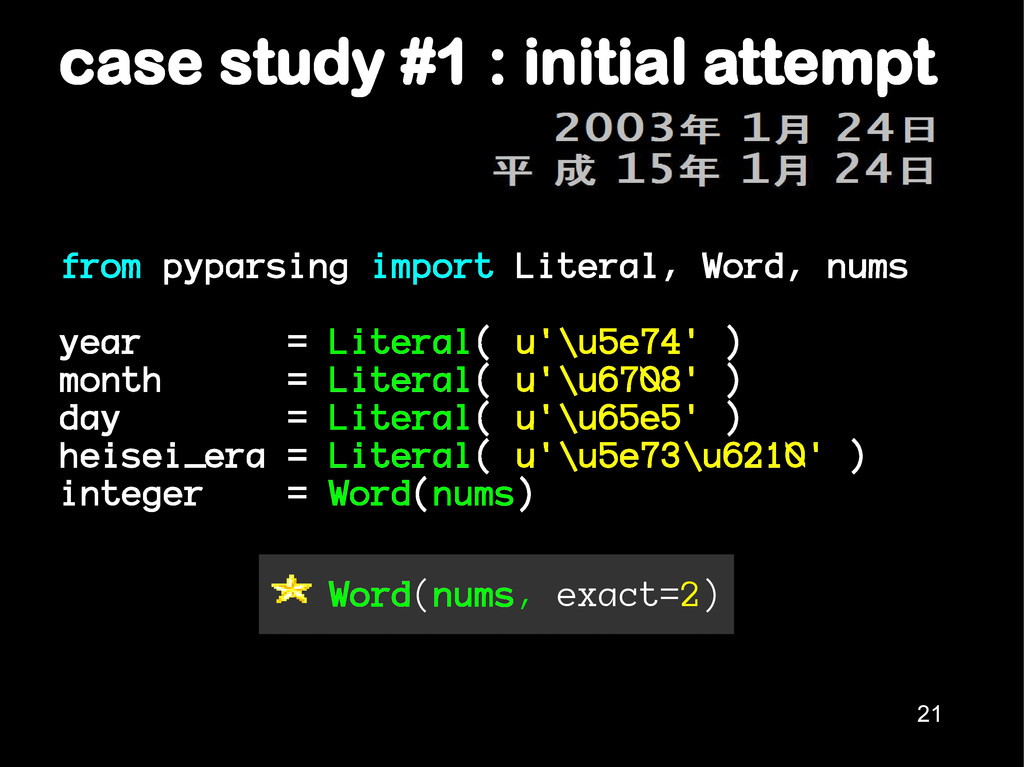
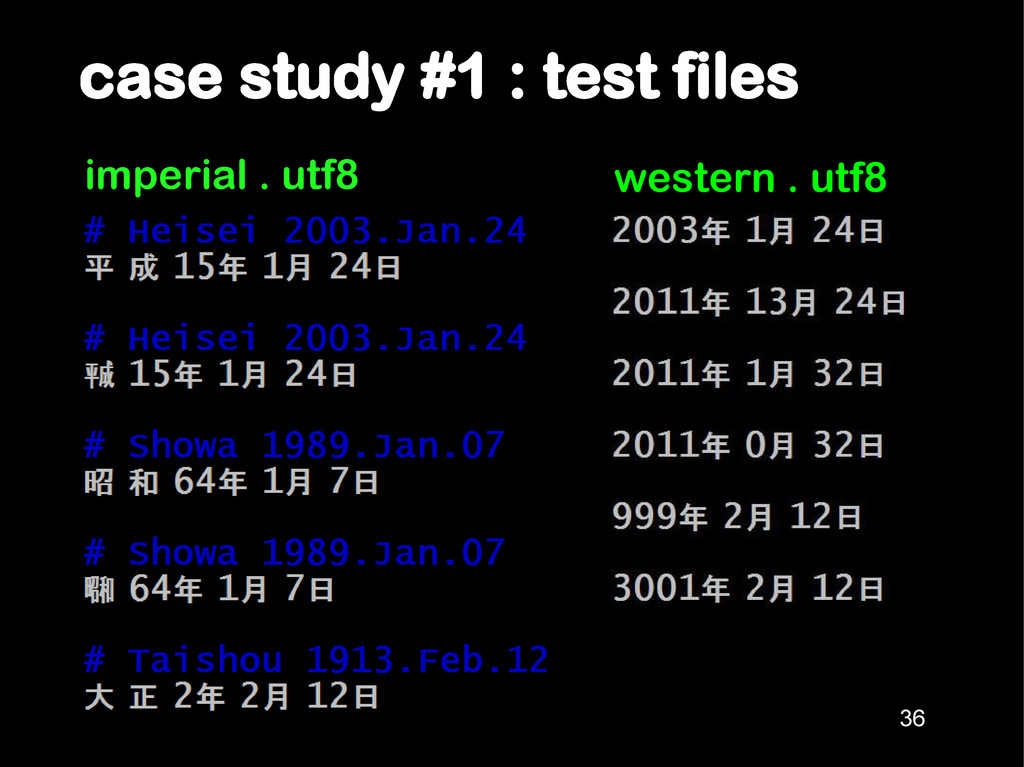
days-of-the-week tagged onto the end. 2. Numbers use western digits, not kanji. 3. Some eras have overlapping days. Ignore. 4. For 1st year of an era, no support for gannen. 20
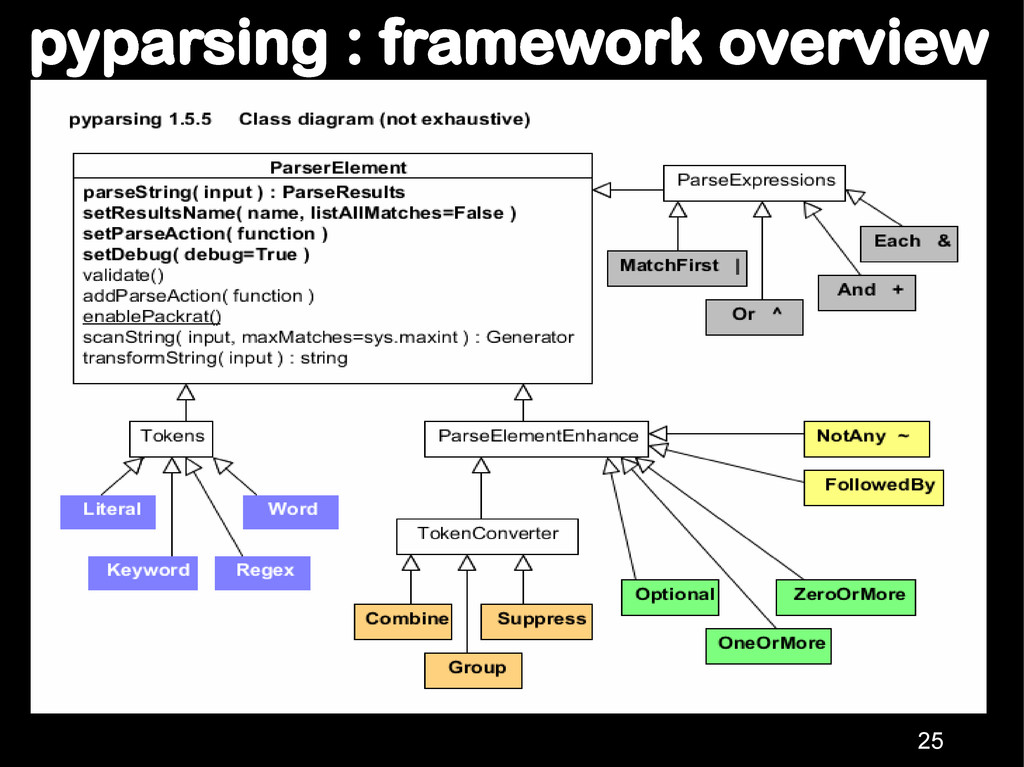
definitions in python Framework distributed as one file pyparsing.py Runs on both python 2.x & 3.x . Future releases after 1.5.x will be focused on python 3.x only 24 Not classified as recursive descent !
exhaustive search of the alternatives. (match longest) Or might introduce ambiguities. No better than non-PEG parsers. Tweak the order of alternatives & put most probable (e.g. frequency of occurrence) first. Avoids wasteful backtracking. 29
Caches: a. ParseResults b. Exceptions thrown run python select_parser.py 33 Caveat emptor: A grammar with parse actions that has side effects do not always play well with memoization turned on.
have zero or more parsing actions. 34 4 forms of parse actions: fn(s,loc,toks) fn(loc,toks) fn(toks) fn() Usage: ParserElement.setParseAction( *fn ) ParserElement.addParseAction( *fn ) Uses: 1. Perform validation (see ParseException ) 2. Process the matched token(s) & modify it Returning a value overwrites the matched token(s). 3. Annotate with custom types (collary of #2)
t: int(t[0])) All users of the integer expression will inherit the parse action. def range_check(toks): month = int(toks[0]) if month <=0 or month >= 13: raise ParseException('month must be in range 1..12') month_spec = integer('m').addParseAction(range_check) + month Selective assignments of parse action to copies. Show: japan_simple.py 35 integer.copy().addParseAction( .. ) integer( 'result_name' ).addParseAction( .. ) !
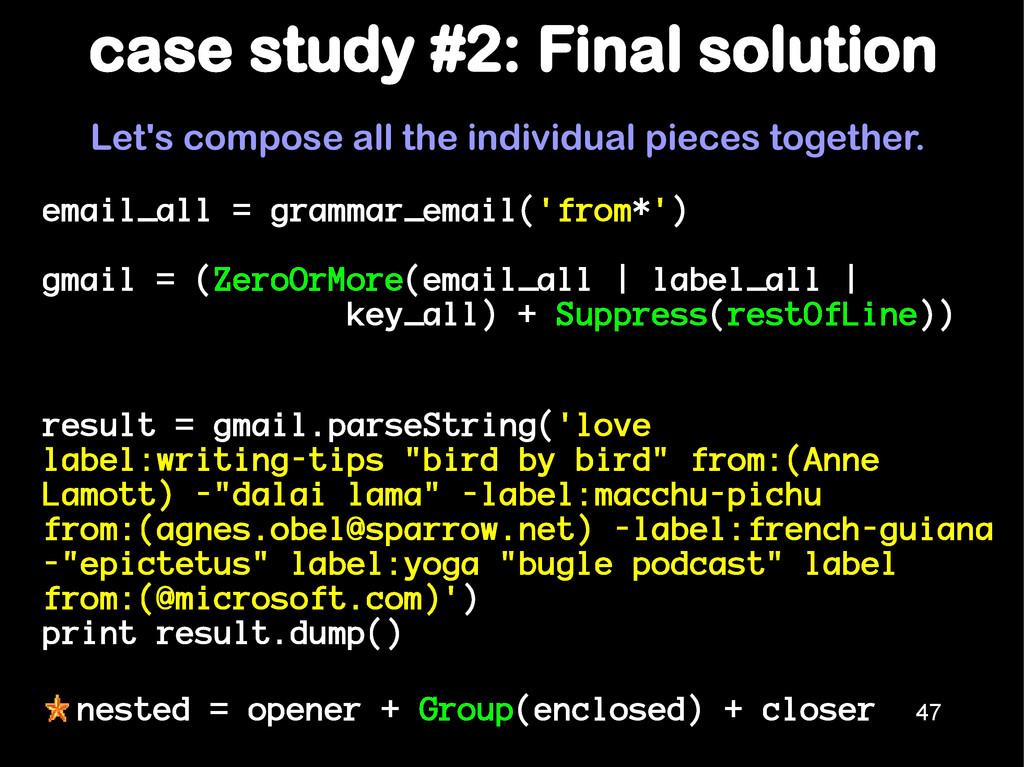
obama -"bin laden" "white house" ' ) print result.dump() Question. If the user entered single instead of double quotes, will it conform to the grammar ? 46 Answer. Yes
a nonterminal which has itself in the right-hand-side of the production rule. number ::= digit rest rest ::= digit rest | empty digit = Word(nums,exact=1).setName('1-digit') rest = Forward() rest << Optional(digit + rest) number = Combine(digit + rest, adjacent=False) ('digit-list') grammar = number.setParseAction(lambda t:int(t[0])) + Suppress(restOfLine) Run
Input : Output : How to fix it : Group(tree) Re-implement Group in class TreeGroup(TokenConverter): def postParse(self, instring, loc, tokenlist): if len(tokenlist) == 1 and tokenlist[0] is None: return tokenlist else: return [tokenlist] 52
::= expr + term | term @raises(RecursiveGrammarException) def test_left_recursion(self): expr.validate() Run 53 pyparsing : left recursion pyparsing will raise a RuntimeError with message 'maximum recursion depth exceeded' ' Eliminate left recursion if you want it to work in pyparsing
is a language prototyping system (PEG). Implemented in several programming languages. * Packrat memoization * Grammar: BNF dialect (with host language snippets) * Object-Oriented: inheritance, overriding rules def rule_lowercase(): // ..body.. * <anything> consumes one object from the input stream. (c.f. regex) * Built-in rules <letter> <digit> <letterOrDigit> <token '?'>
western and Heisei imperial dates b) read & parse both imperial.utf8 & western.utf8 common.py : Common rules & utilities western_dates.py : Grammar to recognize western dates era_heisei.py : Grammar to recognize heisei dates japan_date_parser.py : Final grammar Separate files: 57
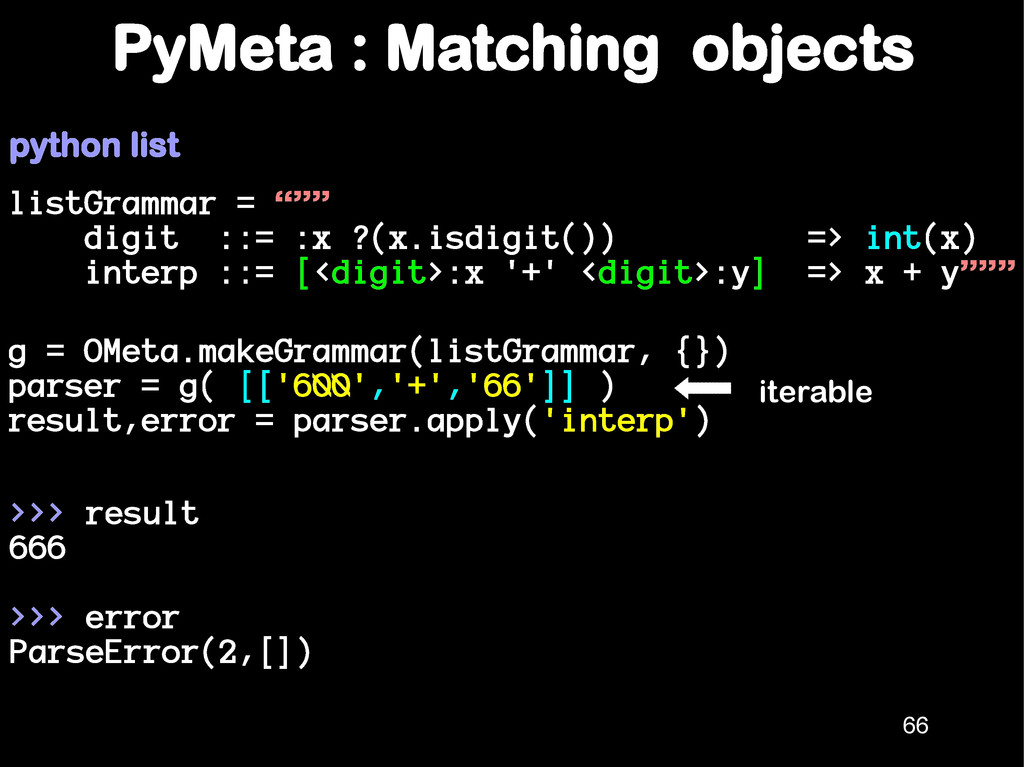
<digit>:d => n * 10 + d | <digit> digit ::= :d ?((d>='0') & (d<='9')) => int(d)""" PyMeta can handle left recursion. Run 65 Quiz. Is the following grammar equivalent ? num ::= <digit> | <num>:n <digit>:d => n * 10 + d
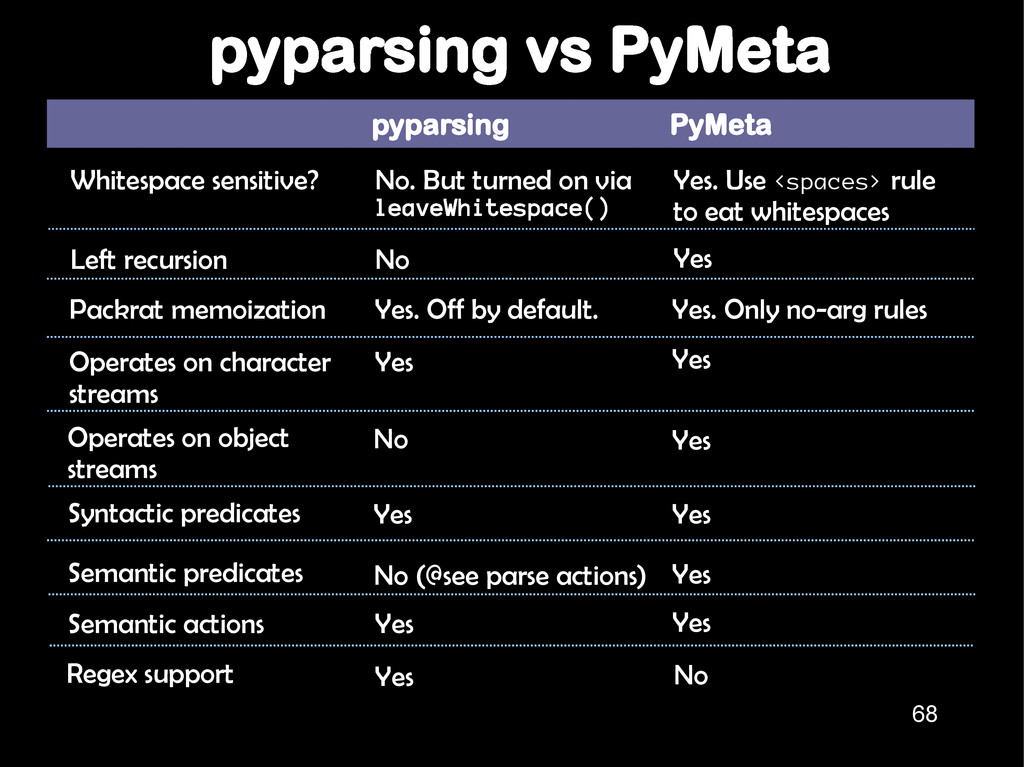
on via leaveWhitespace() Yes. Use <spaces> rule to eat whitespaces Left recursion No Yes Packrat memoization Yes. Off by default. Yes. Only no-arg rules Operates on character streams Yes Yes Operates on object streams No Yes Syntactic predicates Yes Yes Semantic predicates No (@see parse actions) Yes Semantic actions Yes Yes Regex support No Yes 68
grammars of mathematical expression in order to preserve operator precedence • Handling indents/dedents in order to parse indentation-sensitive languages – e.g. coffeescript, python, haskell
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![pyparsing : backtracking p1,p2,p3,p4,p5 = map(Literal,['ronaldo','messi', 'park-ji-sung', 'xavi','iniesta']) first =](https://files.speakerdeck.com/presentations/b62859402d7b0130814722000a9d03e5/slide_29.jpg){kind=link}
{kind=link}
![pyparsing : left factored p1,p2,p3,p4,p5 = map(Literal,['ronaldo','messi', 'park-ji-sung', 'xavi','iniesta']) absolute_certainty](https://files.speakerdeck.com/presentations/b62859402d7b0130814722000a9d03e5/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![case study #2: email addresses emailfull = Regex(r"(?P<user>[A-Za-z0-9._%+-]+)@ (?P<hostname>[A-Za-z0-9.-]+)\.(?P<tld>[A-Za-z]{2,4})") emailpartial](https://files.speakerdeck.com/presentations/b62859402d7b0130814722000a9d03e5/slide_39.jpg){kind=link}
{kind=link}
![case study #2: email addresses result = grammar_email.parseString( 'from:([email protected])' )](https://files.speakerdeck.com/presentations/b62859402d7b0130814722000a9d03e5/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“ ((nil,2,(nil,3,nil)),4,((nil,5,(nil,6,nil)),7,nil)) ” [[[None],2,[[None],3,[None]]],4,[[[None],5, [[None],6,[None]]],7,[None]]] case study #3: recursive solution](https://files.speakerdeck.com/presentations/b62859402d7b0130814722000a9d03e5/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}