As we are witnessing our society becoming increasingly more reliant on mobile technology, so are we seeing the mobilization of money. In this new realm of commerce, online identity is becoming significantly more important.
As a payment is processed, it becomes incredibly important to not only understand who a person is, but also to understand what their broader interests and preferences are so that personalized experiences, suggesting new content and merchandise, may be delivered on an individual level.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
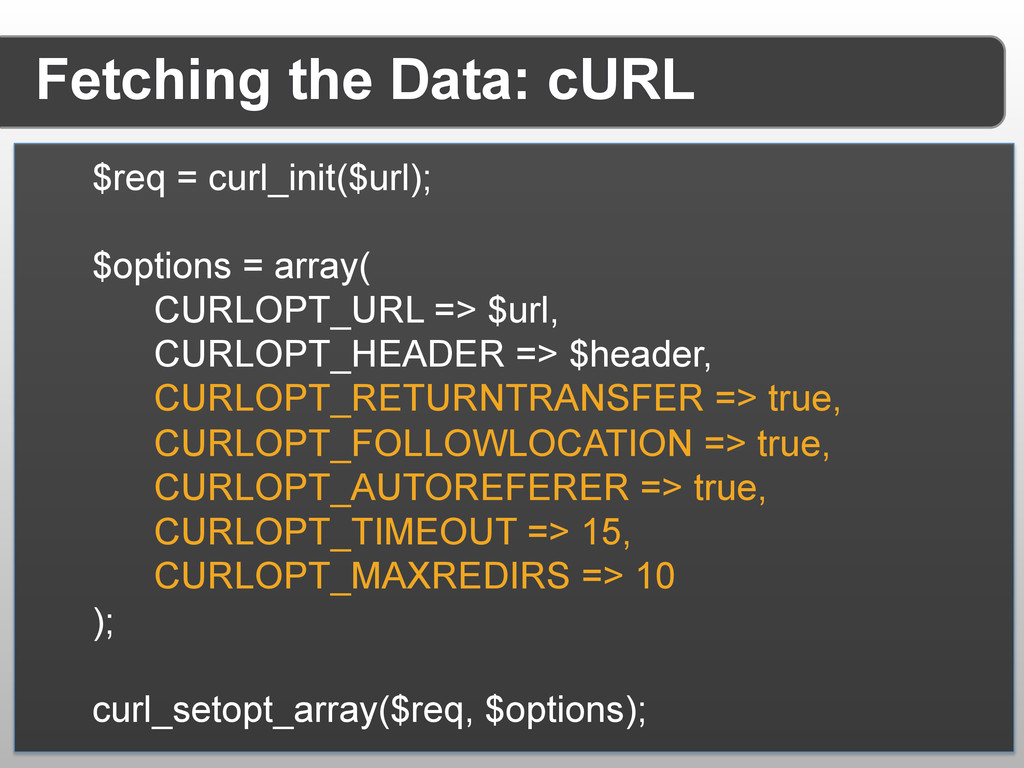{kind=link}
{kind=link}
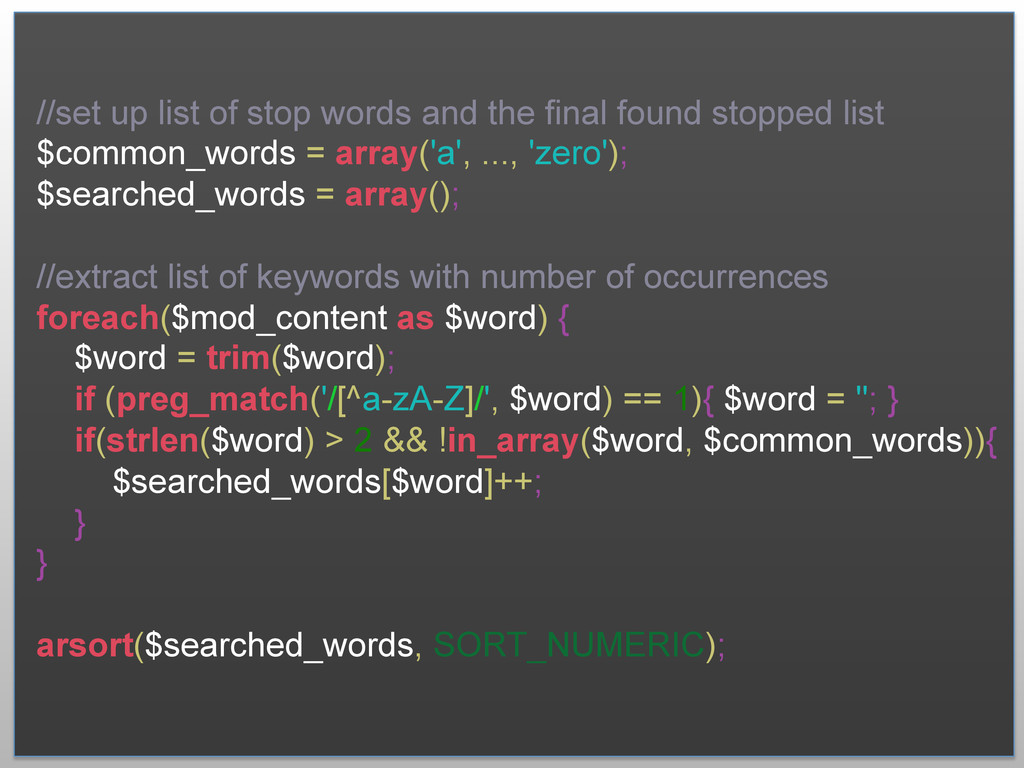{kind=link}
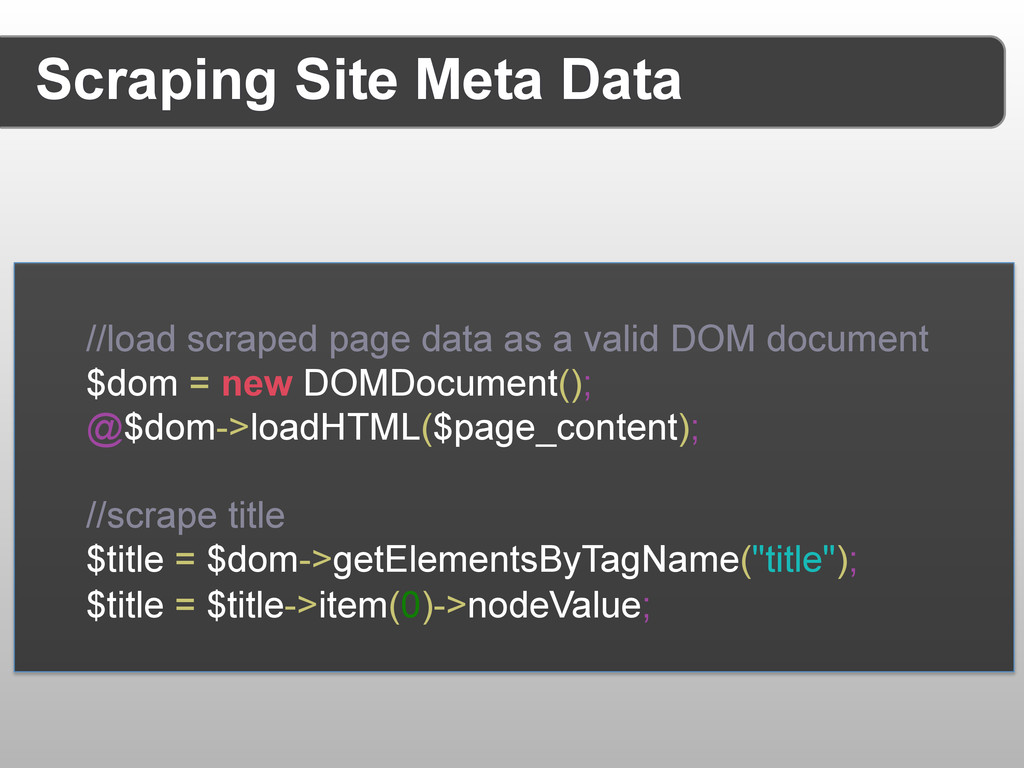{kind=link}
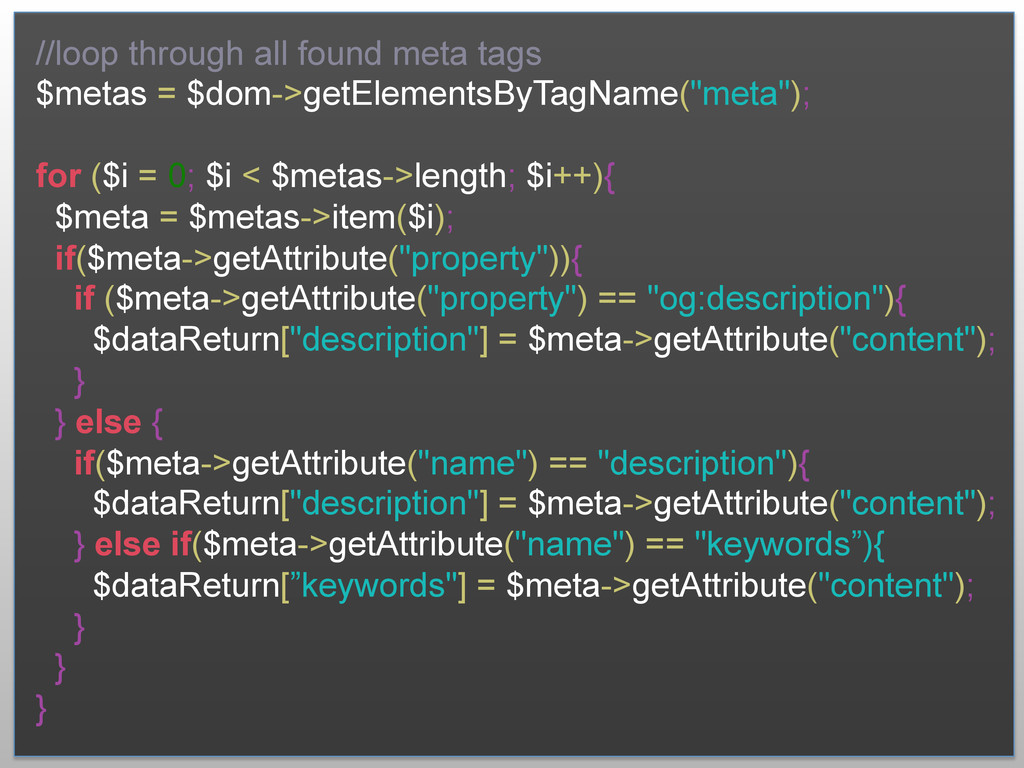{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}