Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AWS Data Pipelineを本番投入してみた話
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
jhashimoto
December 20, 2017
Programming
1.2k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AWS Data Pipelineを本番投入してみた話
社内勉強会で使ったスライドです。
jhashimoto
December 20, 2017
More Decks by jhashimoto
See All by jhashimoto
SteampipeとExcel Power QueryでAWS構成定義書の作成を自動化する
jhashimoto
0
220
ALBの疎通確認をWebサーバーなしでやる
jhashimoto
0
81
EdgeプロファイルでAWSアカウントを安全に使い分ける
jhashimoto
0
180
初めてのAWS / The first AWS
jhashimoto
0
320
AWS Lambdaで始めるサーバーレスアーキテクチャ
jhashimoto
0
280
Amazon S3の紹介
jhashimoto
0
310
クラウド最初の一歩
jhashimoto
0
430
Other Decks in Programming
See All in Programming
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
180
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
150
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
610
テーブルをDELETEした
yuzneri
0
110
AI時代のPHPer生存戦略 ~「言語、もうなんでもよくない?」に本気で向き合う~
vivion
0
180
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
400
自作OSでスライド発表する
uyuki234
1
3.9k
ビデオ通話が繋がる0.2秒で何が起きているのか
supurazako
2
150
今さら聞けない .NET CLI
htkym
0
140
GDG Korea Android: 2026 I/O Extended ~ What's new in Android development tools
pluu
0
180
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
16
3.6k
【やさしく解説 設計編・中級 #4】ルールの寿命と、システムの年輪
panda728
PRO
2
170
Featured
See All Featured
Six Lessons from altMBA
skipperchong
29
4.4k
The Curious Case for Waylosing
cassininazir
1
440
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
200
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
The Organizational Zoo: Understanding Human Behavior Agility Through Metaphoric Constructive Conversations (based on the works of Arthur Shelley, Ph.D)
kimpetersen
PRO
0
390
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
430
The Language of Interfaces
destraynor
162
27k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
Transcript
AWS DATA PIPELINEを本番 AWS DATA PIPELINEを本番 投⼊してみた話 投⼊してみた話 橋本 淳⼀
2017/12/20 1
アジェンダ アジェンダ AWS Data Pipelineとは︖ システム構成 AWS Data Pipelineを採⽤した理由 設計で⼯夫したところ
採⽤してよかったこと 応⽤編 Data Pipelineの注意事項 Data Pipelineではまったこと 2
AWS DATA PIPELINEとは︖ AWS DATA PIPELINEとは︖ ビッグデータを扱うシステムにおいて、ETLができるサービスで す。 3
ETLとは︖ ETLとは︖ Extract/Transform/Load(略称︓ETL)とは、デー タウェアハウスにおける以下のような⼯程を指 す。 Extract - 外部の情報源からデータを抽出 Transform -
抽出したデータをビジネスでの必要に 応じて変換・加⼯ Load - 最終的ターゲット(すな わちデータウェアハウス)に変換・加⼯済みのデ ータをロード Extract/Transform/Load - Wikipedia 4
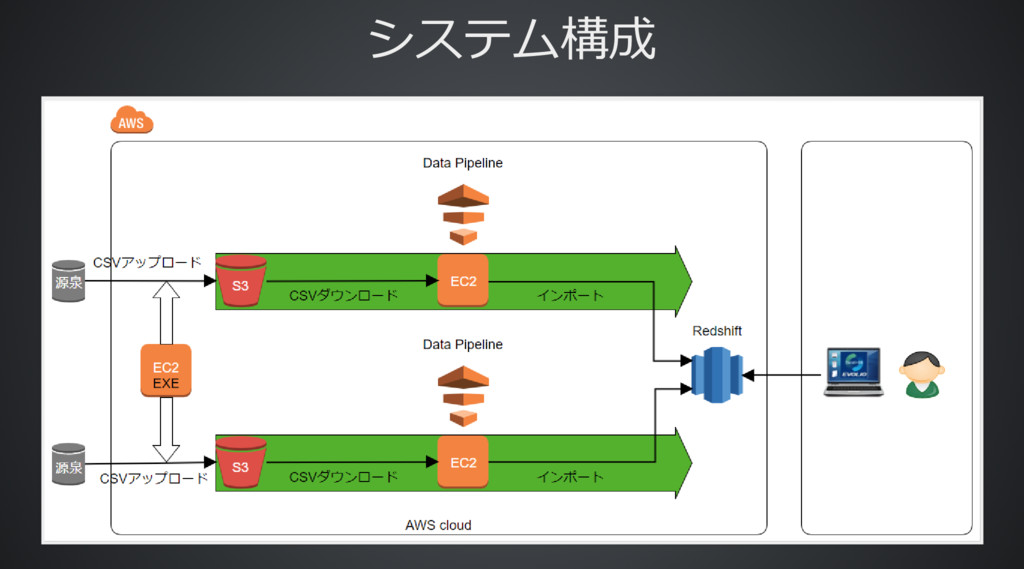
システム構成 システム構成
データ規模 データ規模 Redshiftのテーブル数 100以上 1回のデータ処理バッチで処理するレコード数 100万件 1テーブルのレコード件数 1億件 源泉の数=パイプラインの数 36
6
AWS DATA PIPELINEを採⽤した理由 AWS DATA PIPELINEを採⽤した理由 7
ビッグデータのETLに求められる要件 ビッグデータのETLに求められる要件 1. 様々なデータ源泉への対応 2. 将来データ量が増加しても対応できるアーキテクチャ 3. 複数のETL処理を並列に実⾏ 4. データ変換処理
8
ビッグデータのETLに求められる要件 ビッグデータのETLに求められる要件 5. ETLに必要なそれぞれの処理をタスクとして分解し、ジョブとして 連携 すべての処理を⼀枚岩で実装してしまうと、今どの処理を実⾏し ているのかがわからず運⽤がしにくくなります。 タスクに分解することで、タスクを組み合わせて柔軟にワークフ ローを構成することができるようになります。 6.
管理画⾯ 7. エラー時のリトライ 8. 成功/失敗の通知 9
AWS DATA PIPELINEでできること AWS DATA PIPELINEでできること 10
1. 様々なデータ源泉への対応 1. 様々なデータ源泉への対応 S3 DB(JDBCで接続できればOK) オンプレミスのサーバーにも対応 11
2. データ量が増加しても対応できるアーキテ 2. データ量が増加しても対応できるアーキテ クチャ クチャ パフォーマンス向上の⼿法として、⼀般的にスケールアップとスケ ールアウトの2つの⽅法があります。 スケールアップ マシンの性能を上げる⽅法です。
スケールアウト 処理を複数マシンに分散できるようにしておき、処理マシンの 台数を増やす⽅法です。 12
DATA PIPELINEでこれらを実現するには DATA PIPELINEでこれらを実現するには スケールアップ EC2のインスタンスタイプのスペックを上げる。 スケールアウト Amazon EMR(複数のEC2インスタンスをクラスタとして提供す るサービス)と連携
すると、複数のEC2インスタンスで分散処理 させることができます。 13
3. 複数のETL処理を並列に実⾏ 3. 複数のETL処理を並列に実⾏ EC2のインスタンスはパイプラインごとに⽣成されるので、実⾏環 境は独⽴しています。他のパイプラインの実⾏に影響を及ぼしませ ん。 14
4. データ変換処理 4. データ変換処理 Javaまたはシェルスクリプトでカスタムロジックを実装できます。 15
5. ETLに必要なそれぞれの処理をタスクとして 5. ETLに必要なそれぞれの処理をタスクとして 分解し、ジョブとして連携 分解し、ジョブとして連携 個々の処理をアクティビティという単位に分割できます。 アクティビティを組み合わせてワークフローを構成できます。 16
6. 管理画⾯ 6. 管理画⾯ 管理画⾯が⽤意されているので、開発者が作成する必要はありませ ん。 17
7. エラー時のリトライ 7. エラー時のリトライ アクティビティ単位のリトライ処理が⽤意されています。 18
8. 成功/失敗の通知 8. 成功/失敗の通知 Amazon SNSと連携し、メールまたはSMSで結果を通知できます。 19
設計で⼯夫したところ 設計で⼯夫したところ 20
データのインポート処理でステージングをしています。ステージン グは、Data Pipelineに限定された概念ではなく、データ処理で⼀般 的に使われる考え⽅です。 ステージングとは、直接対象にインポートするのではなく、⼀時的 に別の領域に(今回はRedshiftにステージング⽤のテーブルを⽤意 しました)データを⼊れることをいいます。 最終的なターゲットのテーブルにはステージングテーブルから INSERTすることになります。 21
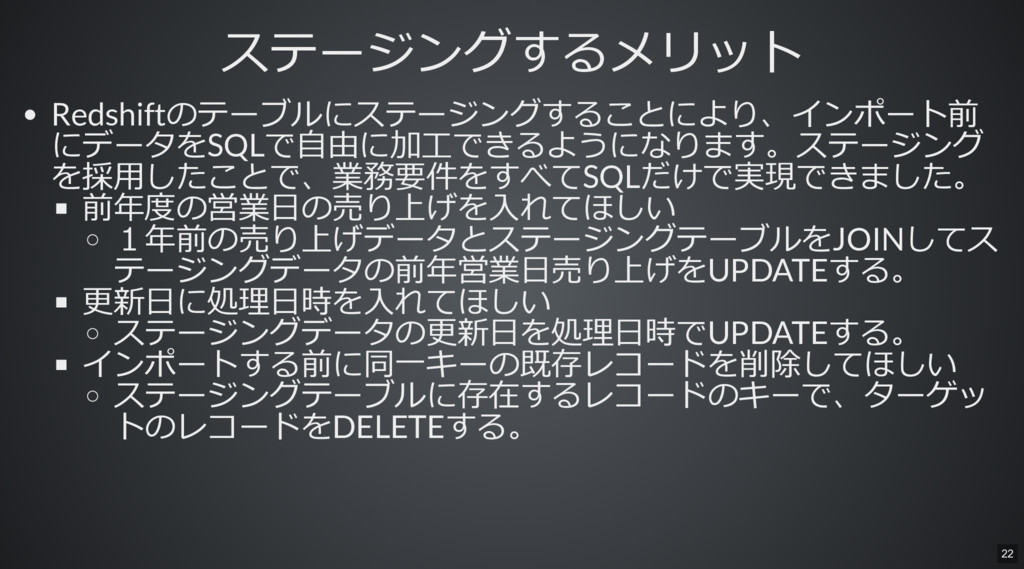
ステージングするメリット ステージングするメリット Redshiftのテーブルにステージングすることにより、インポート前 にデータをSQLで⾃由に加⼯できるようになります。ステージング を採⽤したことで、業務要件をすべてSQLだけで実現できました。 前年度の営業⽇の売り上げを⼊れてほしい 1年前の売り上げデータとステージングテーブルをJOINしてス テージングデータの前年営業⽇売り上げをUPDATEする。 更新⽇に処理⽇時を⼊れてほしい ステージングデータの更新⽇を処理⽇時でUPDATEする。
インポートする前に同⼀キーの既存レコードを削除してほしい ステージングテーブルに存在するレコードのキーで、ターゲッ トのレコードをDELETEする。 22
採⽤してよかったこと 採⽤してよかったこと 23
将来への安⼼感 将来への安⼼感 データ量が増えても… EC2インスタンスのスペックを上げて対応 源泉が増えても… EC2インスタンスはパイプラインごとに独⽴しているので、パイ プラインを増やしても既存のパイプラインの実⾏環境に影響を及 ぼさない 24
EC2のインスタンスを使い捨てにできる EC2のインスタンスを使い捨てにできる パイプラインが開始されるときに、AMI(Amazon Machine Image) からインスタンスを⽣成し、パイプラインの処理が終わったらイン スタンスが破棄される。 EC2は起動時間による従量課⾦(秒単位)なので、コスト⾯のメリ ットが⼤きい 同じAMIから毎回インスタンスを⽣成し直すので、実⾏環境が常に
⼀定 知らない間にOSにパッチが適⽤されていて、バッチが動かなくな ったということがない。 25
応⽤編 応⽤編 Data PipelineはETL以外にも使えます。 カスタムロジックをシェルスクリプトで書けるので、AWS CLIを 使ってAWSのリソースを操作できます。 EC2、Redshiftを使わないときは落としておくとコストが下がりま す。 夜間の停⽌・翌朝の起動をData
Pipelineで⾃動化しています。 Amazon EC2 インスタンスの停⽌と開始 26
DATA PIPELINEの注意事項 DATA PIPELINEの注意事項 27
管理画⾯は⽇本語対応されていない。 典型的な処理なら⽤意されているアクティビティを使⽤してノンコ ーディングで実装できるが、それで実現できない場合はカスタムの ロジックをシェルスクリプトで書かなければいけない。C#の快適な 開発と⽐べると… ⽇本語の含まれるJSONを管理コンソールからインポートすると⽂ 字化けする。 AWS CLI(コマンドラインインターフェース)でインポートすれ ばOK。
28
ワークフローはGUIのエディタで定義できるがすべての機能が対応 されているわけではない。⼀部の機能はJSONを⼿で修正する必要 がある。 時刻はUTCなので、⽇本時間より9時間遅い。 ワークフロー内で条件分岐させることはできない。 データパイプラインで使⽤するEC2のインスタンスはLinuxである必 要があります。現状Windowsインスタンスは使えません。 TaskRunnerというエージェントプロセスをインストールする必要 があるが、Windowsはサポートしていないため。 Task
Runner を使⽤した既存のリソースでの作業の実⾏ - AWS Data Pipeline 29
DATA PIPELINEではまったこと DATA PIPELINEではまったこと 30
スケジュールの開始時刻どおりに実⾏されな スケジュールの開始時刻どおりに実⾏されな い い 指定した開始時刻よりもパイプラインの開始が早まったり、遅くな ったりする(⾃分が確認した範囲では数分程度) 31
AWSサポートに問い合わせました AWSサポートに問い合わせました A. これはData Pipelineの意図された動作です。負荷の集中がサービ スの安定稼働に影響を与えることを避けるため、サービス側で開始 時刻の調整をします。最⼤でどのくらい開始時刻が前後するかは回 答できません。 32
対応 対応 Data Pipelineのスケジュール機能を使うのをやめて、タスクスケジ ューラでパイプラインを定期実⾏するようにした(AWSにはAWS CLIと呼ばれるコマンドラインインターフェースがあります) 33
データパイプラインの参考資料 データパイプラインの参考資料 AWSの公開している資料 AWSの公開している資料 その他 その他 AWS Data Pipeline とは
- AWS Data Pipeline AWS Black Belt Tech シリーズ 2015 - AWS Data Pipeline Data Warehousing on AWS Data Pipeline | 特集カテゴリー | Developers.IO AWS Data Pipeline の 稀によくあるQ&A | ALBERT Of cial Blog 34
END END 35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}