storage nodes • 10 x compute + 4U DAS nodes • 66? x 1U compute nodes • 4 x DB nodes • 4 x 8U/74 disk systems (off site) • total raw storage = 3.6PB • 147 nodes / 1492 cores Stats as of 2012-11-30 courtesy of Eugene Magnier
including 333,095 science exposures – 709,171 processed exposures (we have processed all science exposures 1x, plus nearly completed a full re-processing, plus additional re-processings) • DVO 3pi survey DB – 27 billion measurements of 1.5 billion astronomical objects – ~10TB • Storage – Nebulous is tracking 1,357,067,950 “instances” – Nebulous DB > 1.35TB – current usage = 3.2PB (raw + results + short-term outputs) Stats as of 2012-11-30 courtesy of Eugene Magnier
– Files must be accessible as a local path (cfitsio does not work with FDs) – Support seeking on remote files without copying the complete file locally – Data replication – Scales [more or less] linearly with cluster size – Synchronous state between all clients – C / Perl clients • Paper evaluated dozens of systems – Predates iRODS
operations • All storage nodes + server need to have a consistent view of target storage volumes (NFS cross mounts w/ automounter) • Performance trumps safety – No mandatory locking / no permissions – Clients are trusted implicitly – Volume rebalancing / etc. Is a batch operation • As POSIX like as is possible, eg. xattrs
file creation) • Implemented as Perl modules • Separate daemon process monitors storage volume usage / status • MySQL/innodb backend • Production system runs under Apache/mod_perl w/ SOAP RPC adaption layer • Support for memcache / sharding implemented but not in use
• POSIXish API • Responsible for handling storage object instance replication management – File modifications are tricky • POSIXish CLI utils: neb-ls, neb-df, neb-rm, etc. • IPP packages configurable for either local files or Nebulous
DSL derived from CFHT Ohana suite – Tasks poll on time intervals for pending work – Does not directly maintain state – No end-to-end concept of a processing run – Does not maintain state itself – Runs as a regular users – Runs jobs via persistent ssh connections to configured nodes – There was significant design time concern about deadlocked processing
-exec $LOADEXEC periods -timeout 30 npending 1 stdout NULL stderr $LOGDIR/receive.fileset.log task.exec $run = receivetool -pendingfileset if ($DB:n == 0) option DEFAULT else # save the DB name for the exit tasks option $DB:$receive_DB $run = $run -dbname $DB:$receive_DB $receive_DB ++ if ($receive_DB >= $DB:n) set receive_DB = 0 end add_poll_args run command $run End ...
CLI utilities called ippTools. – All state is managed in a SQL DB via wrapper APIs which is queried / updated via CLI utilities • Providence / versioning of every step is persevered • Workflow is static, ie, specific to IPP processing steps – Some steps are optional, others are not triggered by panTasks • Build on top of IPP db management utilities – C does not have a good perl DBI analog – psDB* – glueforge / ippDB
node that holds the data locally when possible • Chips in the focal plane have when possible affinity to a specific storage node • Data is transferred from summit directly to the target storage node; required as part of the transfer parallelization scheme
– Threading is a solution to latency issues – OpenMP in gcc 4.3+, Intel TBB, etc. • You will save all the bits • Simulated data != real data • “Data Challenges” are important • Estimating CPU is difficult • Hardware is cheaper than debugging memory errors • Post-commissioning support requires more software FTEs than development • DSL use needs to be carefully considered • Tightly coupling workflow, storage, cluster design limits reuse but reduces software effort • Beware of over specification
![Overview of [some of] the PS1 Image Processing Pipeline Infrastructure](https://files.speakerdeck.com/presentations/0e144fa0b221013190c862aacf32eac0/slide_0.jpg){kind=link}
{kind=link}
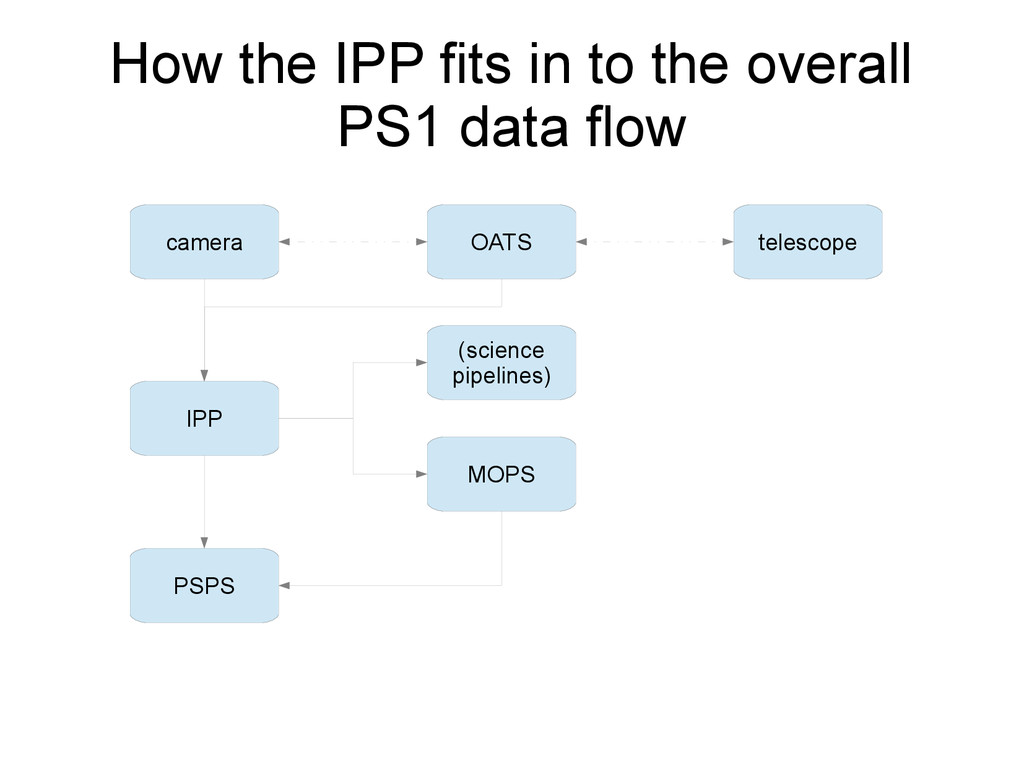{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
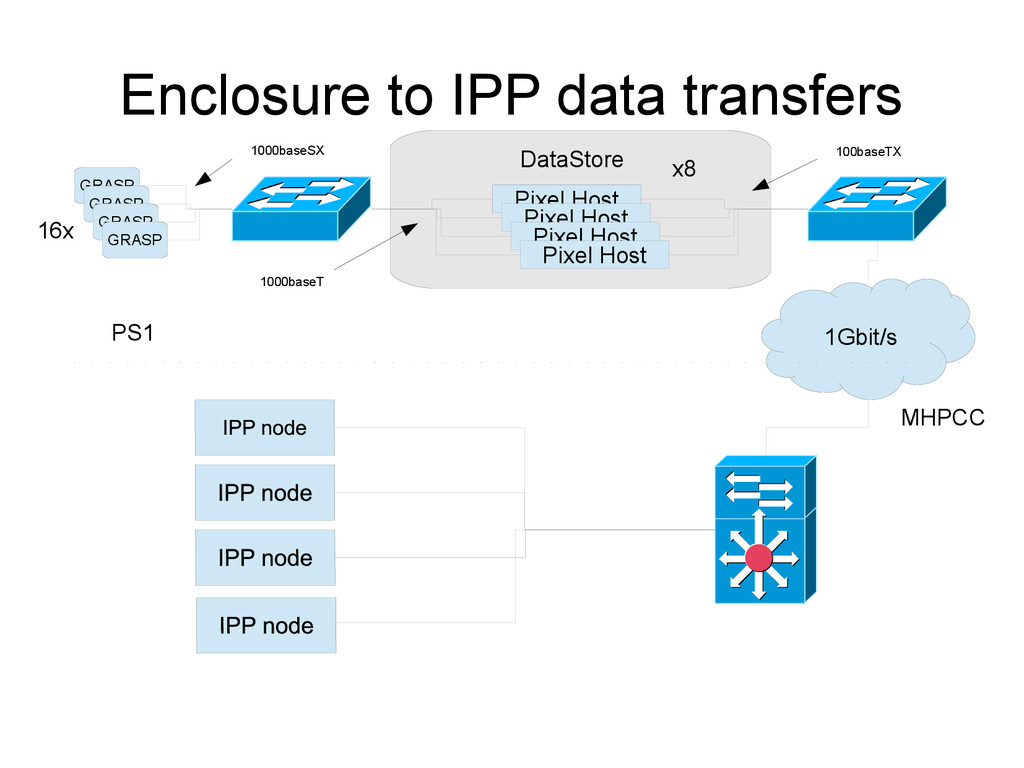{kind=link}
{kind=link}