At that time Oracle was still digesting the remains of Sun • Lustre lacks replication functionality • Desire not be completely dependent on iRODS • Desire to use the same skill set for storage heaps with different usage scenarios – Performance & reliability • Experience at partner institutions – SDSC & NCSA • Negative feedback on glusterfs, etc. ceph was still a year away from being production ready
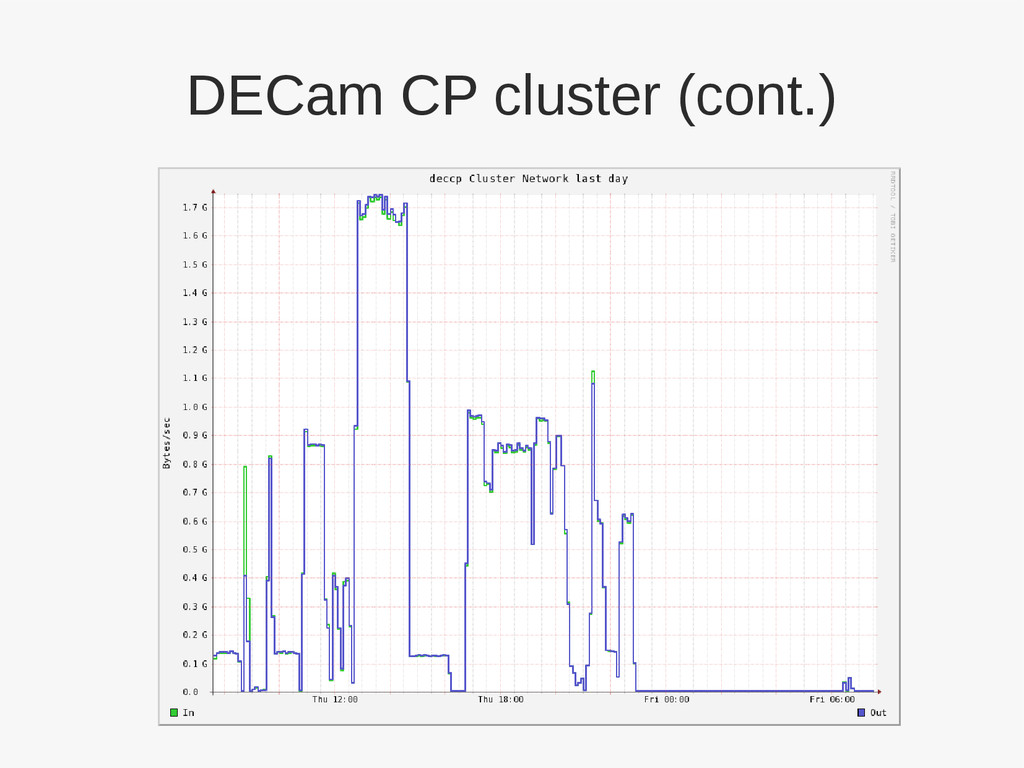
4MB block size • 3.4 -> 3.5 • Metadata migrated to SSDs • Metadata replication decnsd1 decnsd2 disk disk disk disk dec01 dec02 ... dec15 3G SAS 10G Ethernet
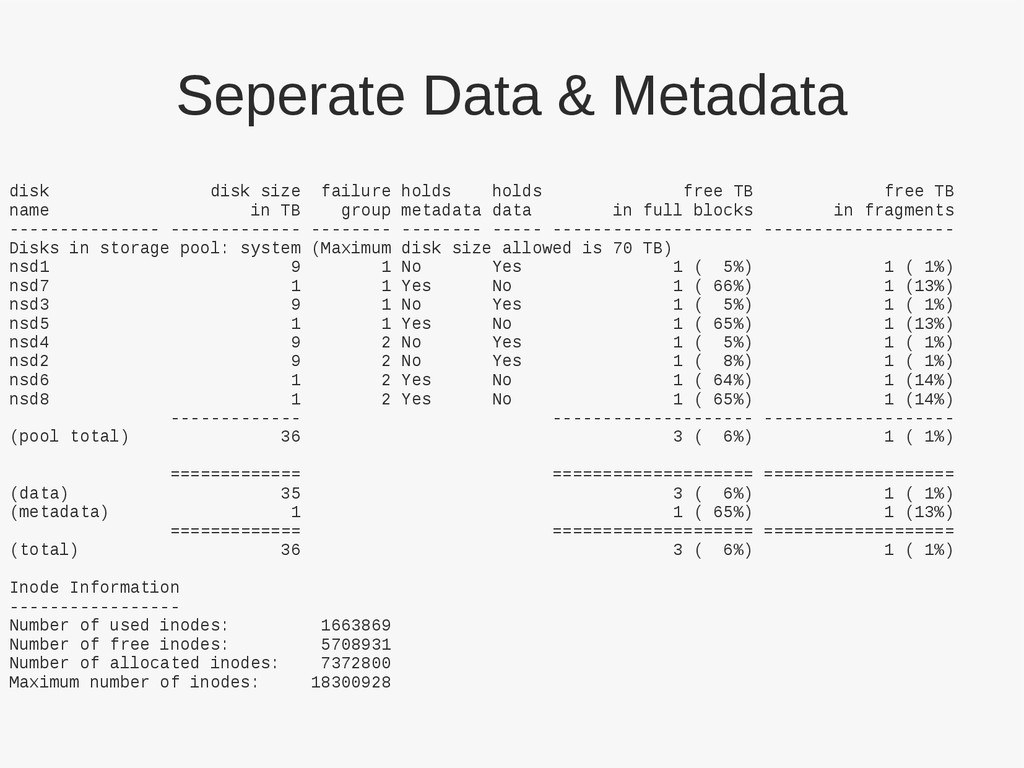
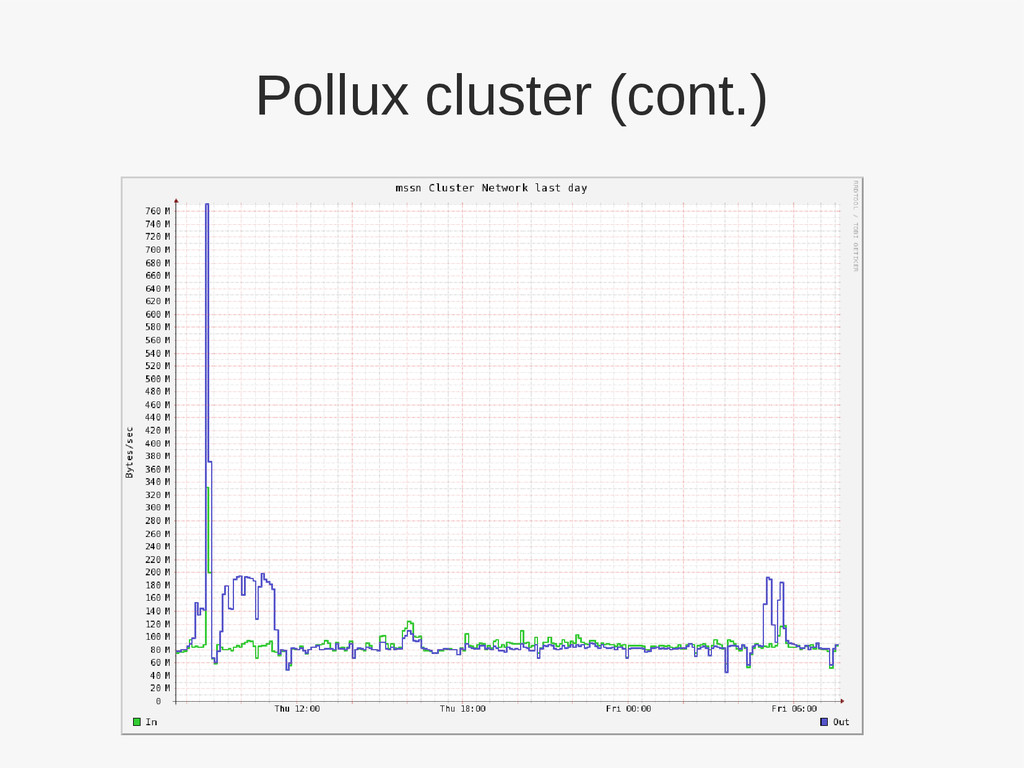
– Archive copy in La Serena – “3rd” copy on Kitt Peak • Tucson archive will have it's metadata migrated to dedicated SSDs • On going annual expansion • Aggregate capacity of 1020TiB by end of FY13
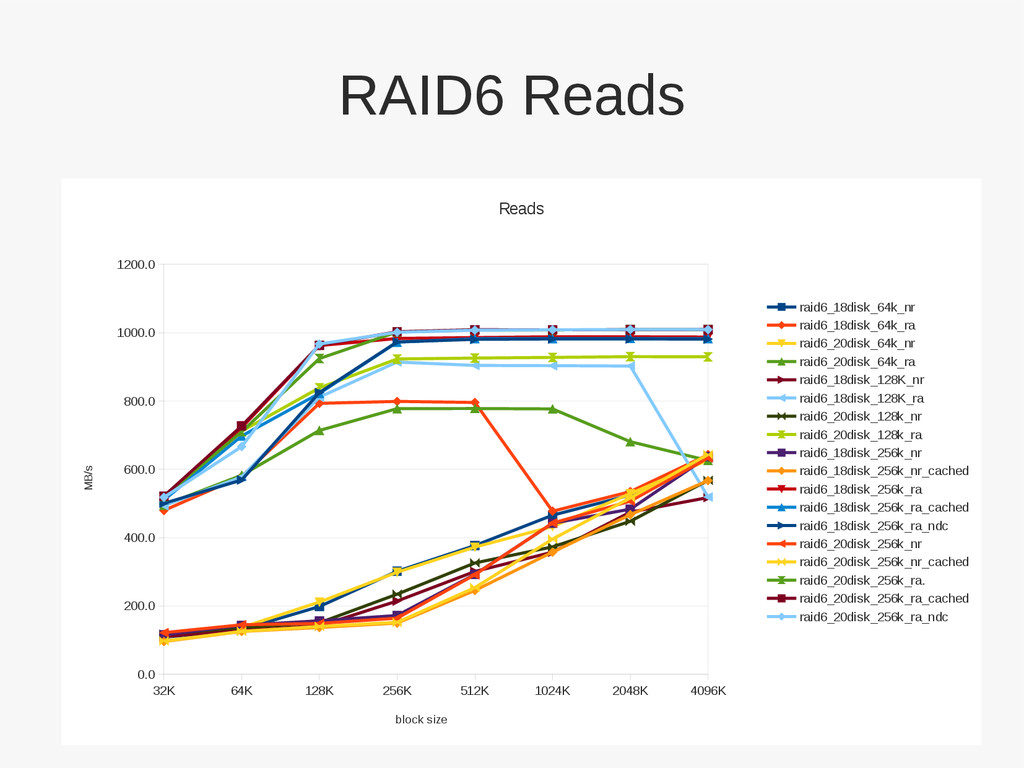
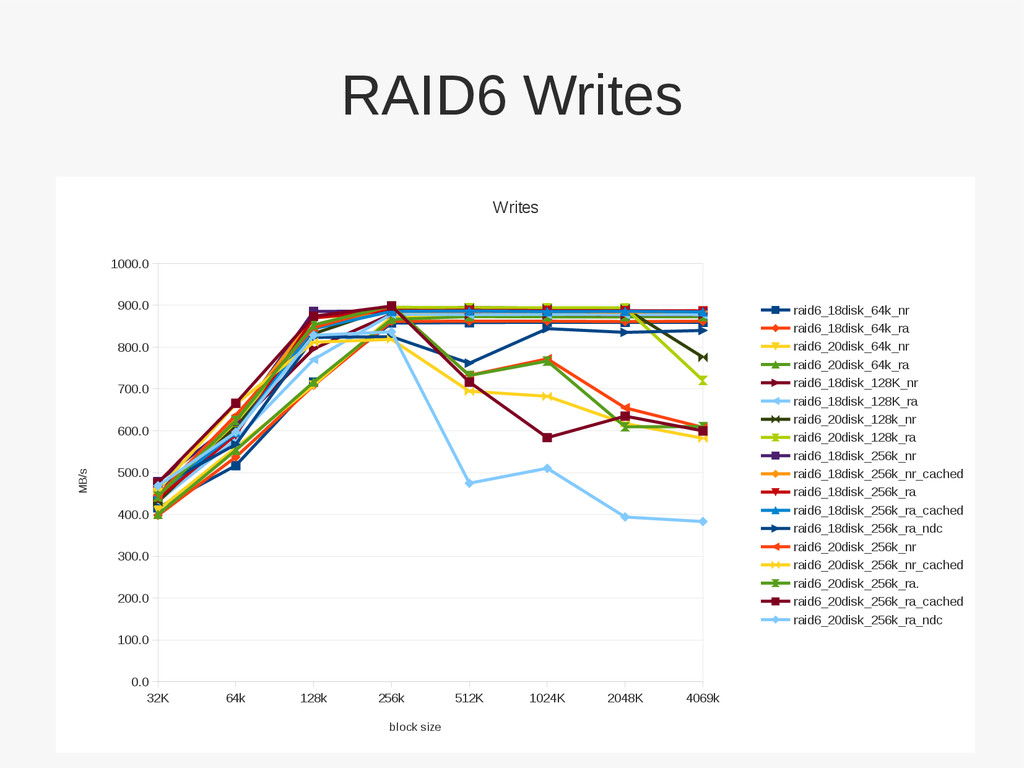
the entire • Tunneling SATA over SAS has high overhead (~30%?) • Match filesystem write width to RAID set array width • Array set blocksize can be tricky / non-intutive – Larger blocksize tend to optimize heavily for writes over reads
{kind=link}
{kind=link}
{kind=link}
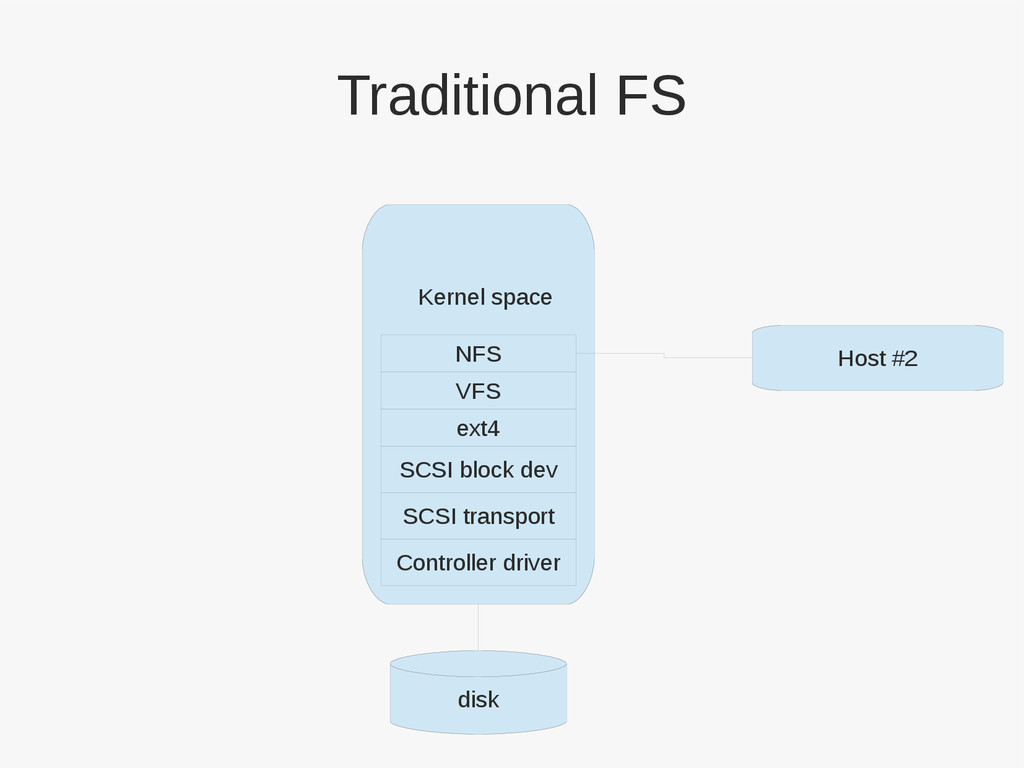{kind=link}
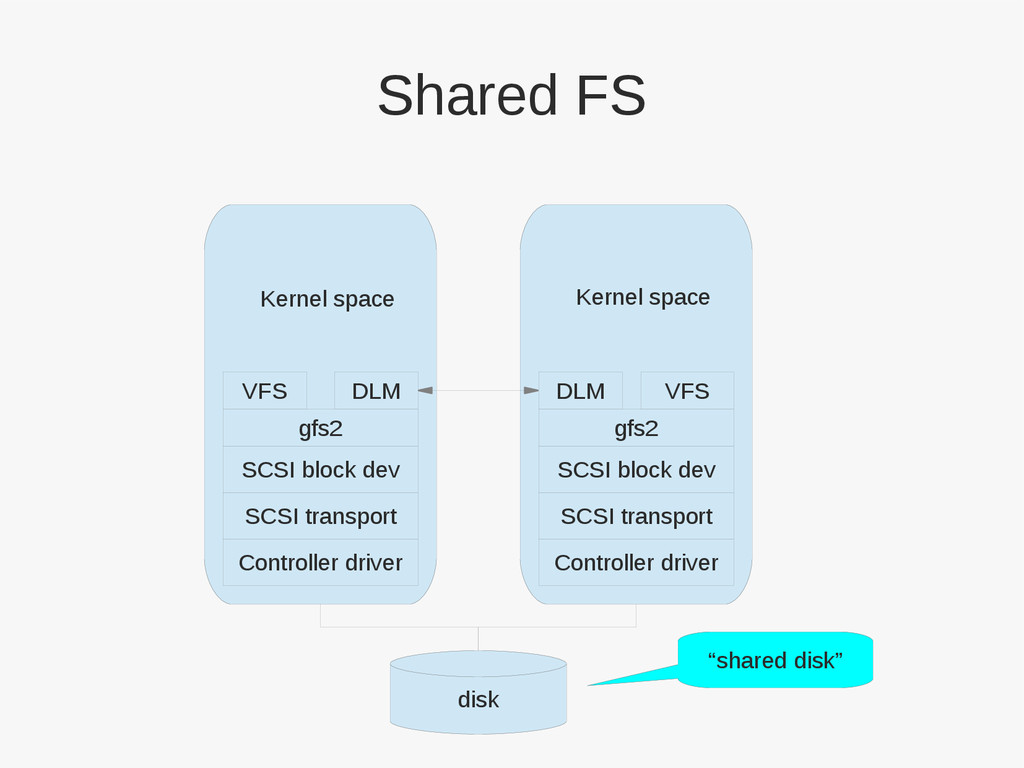{kind=link}
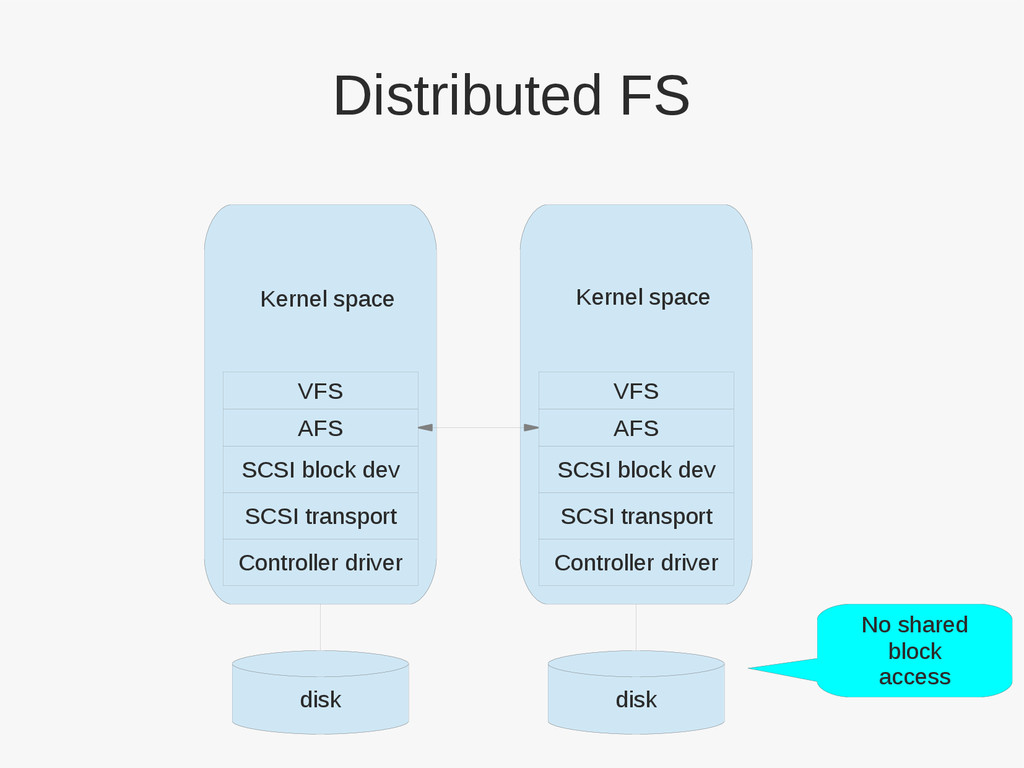{kind=link}
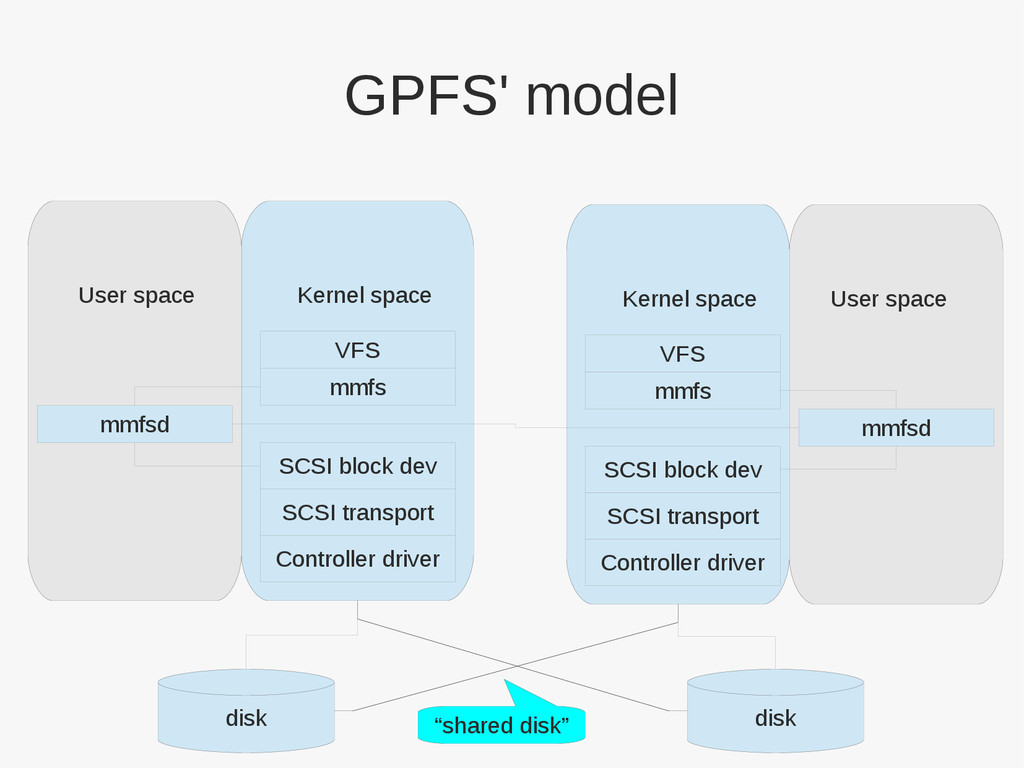{kind=link}
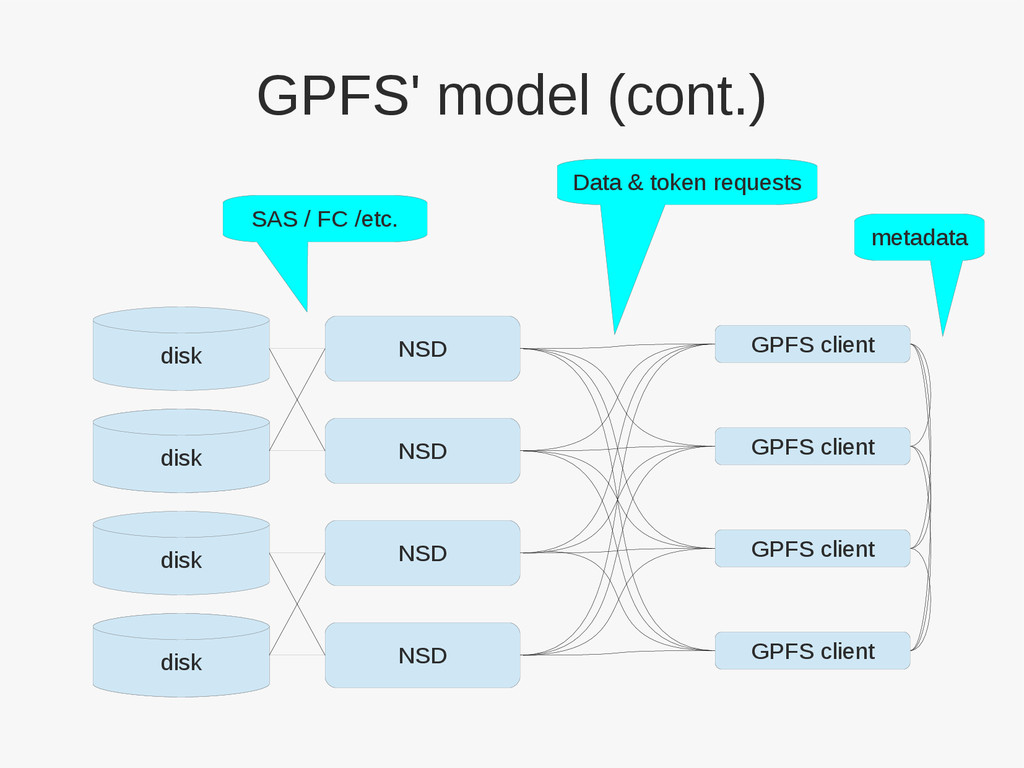{kind=link}
{kind=link}
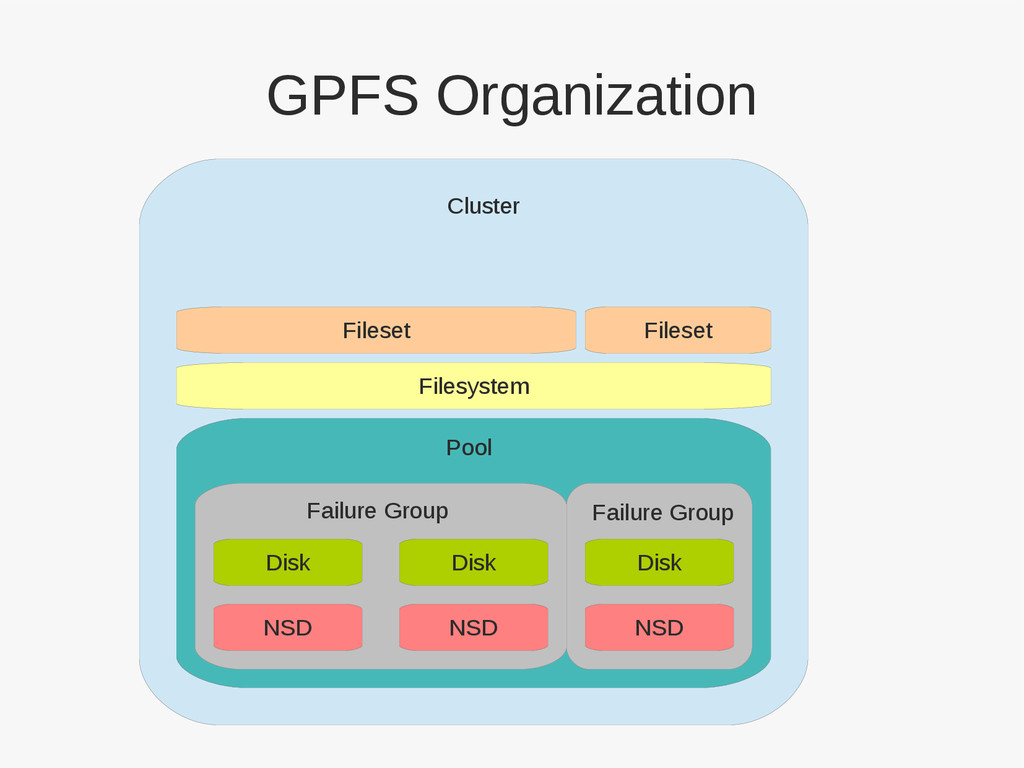{kind=link}
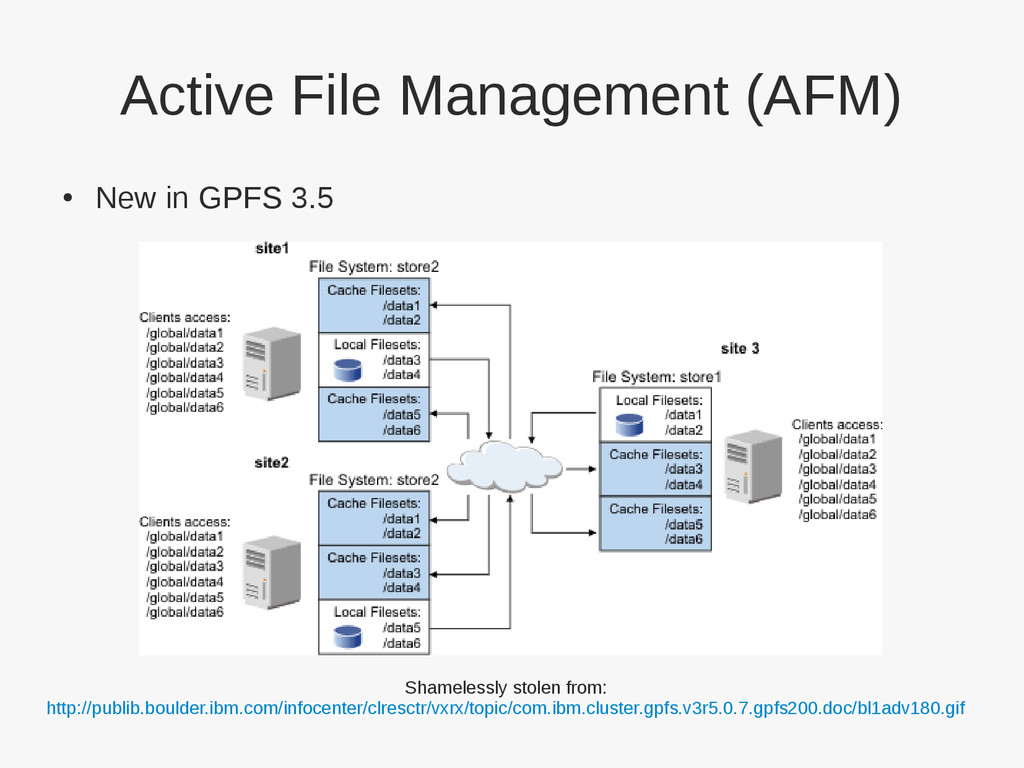{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
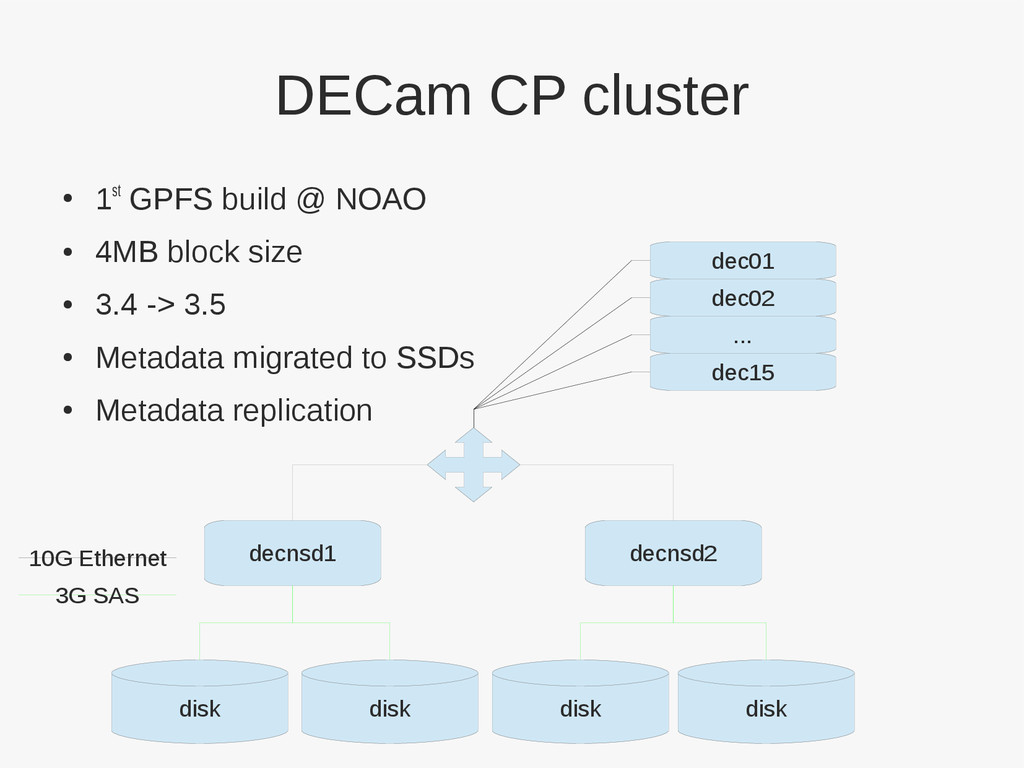{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}