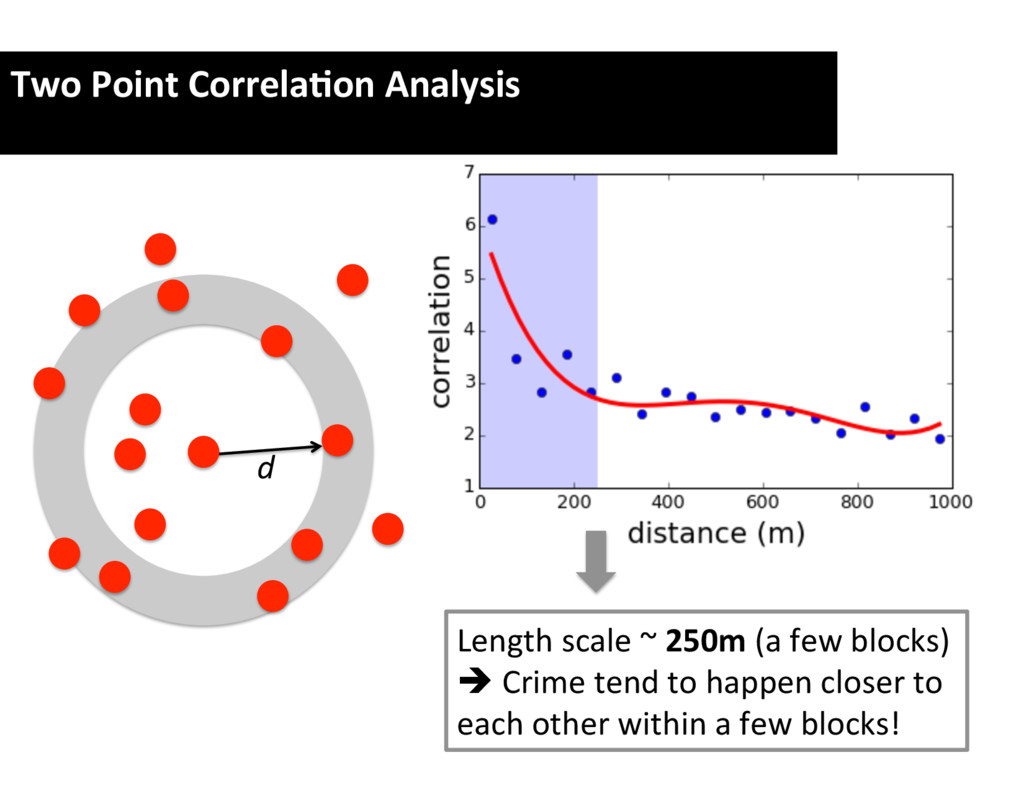
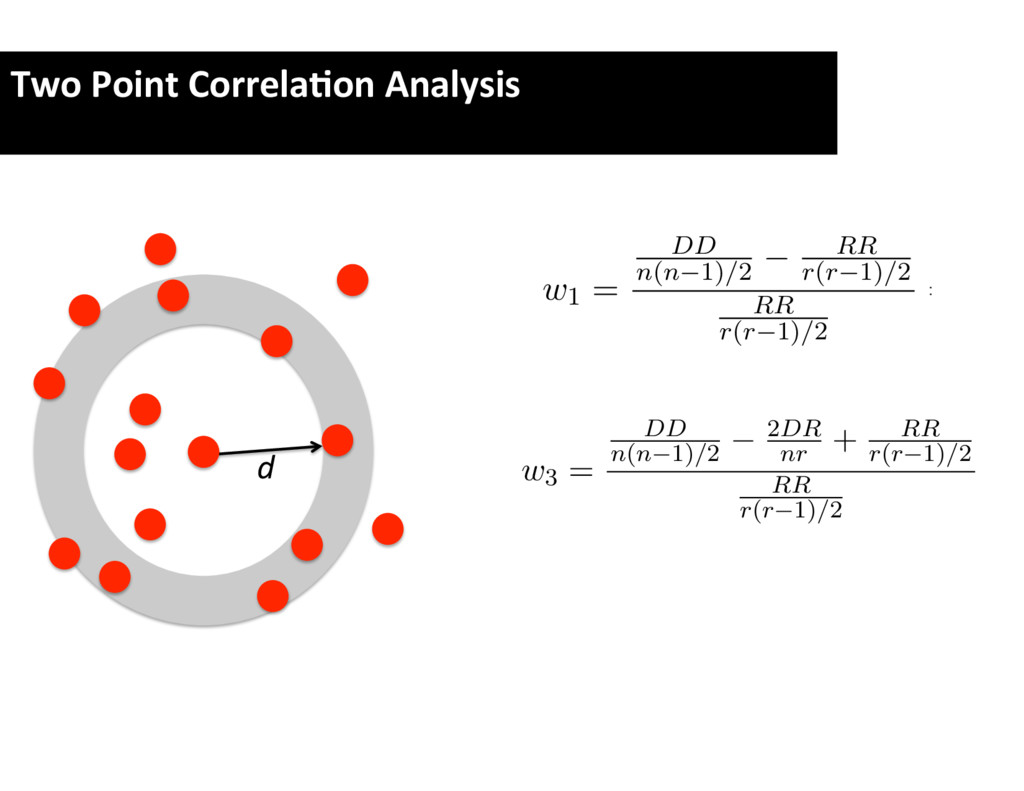
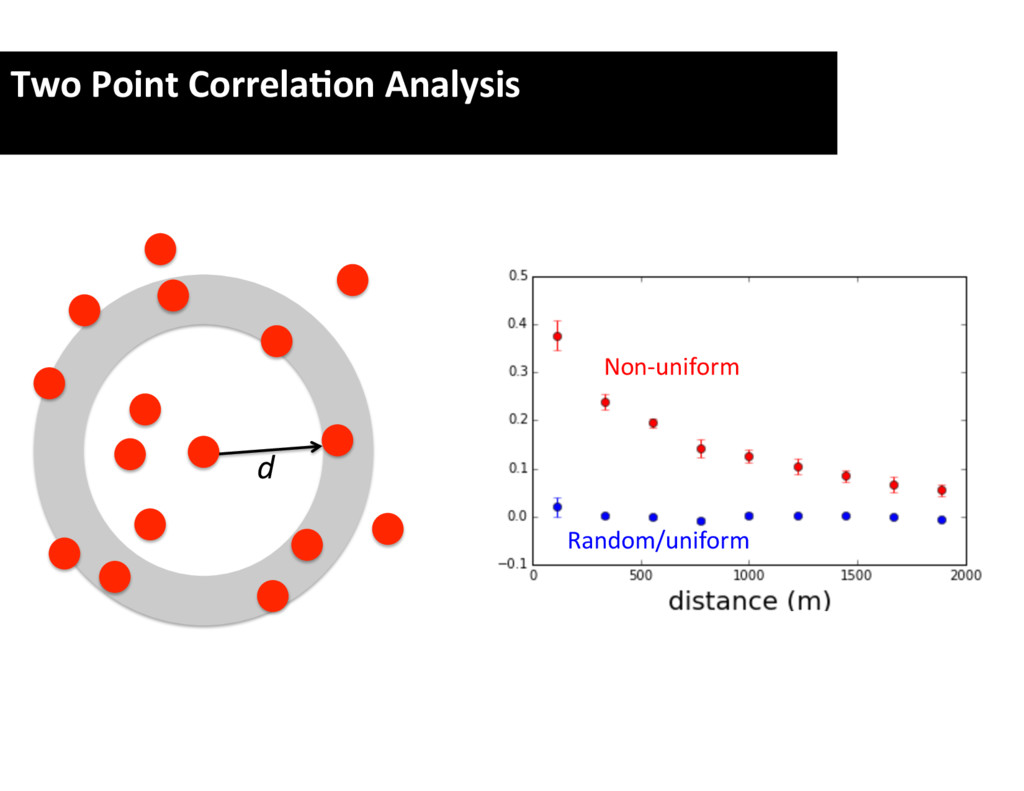
of pairs in D and R is n ( n 1) / 2 and r ( r the clustering at the angular scale ✓ , count the num separations in the interval ✓ ± ✓/ 2. Let DD and RR and R , respectively. The ‘natural’ estimator of w ( ✓ ) i w1 = DD n ( n 1) / 2 RR r ( r 1) / 2 RR r ( r 1) / 2 = r ( r n ( n To reduce the e↵ect of statistical fluctuations in RR (say, 10) random fields, and use the average number h As shown by Landy & Szalay [2], w1 is biased (i.e. even when there is no clustering). A much better the cross-correlation statistic DR , that is the numbe ✓ ± ✓/ 2, with one point taken from D and the othe The Landy–Szalay estimator is then computed as2 DD 2 DR RR r ( r 1) / 2 To reduce the e↵ect of statistical fluctuations (say, 10) random fields, and use the average nu As shown by Landy & Szalay [2], w1 is bias even when there is no clustering). A much the cross-correlation statistic DR , that is the ✓ ± ✓/ 2, with one point taken from D and t The Landy–Szalay estimator is then computed w3 = DD n ( n 1) / 2 2 DR nr + RR r ( r 1) / 2 RR r ( r 1) / 2 = It is advisable to replace RR and DR by the m In the actual calculations, DD , RR , and D counting the number of pairs in m bins of number of pairs with 0 < ✓ ✓ , DD (2) the on, up to DD ( n ), which is the number of pair
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}