more) node cluster — For local development you adapt to only expect one node — Or just run 3 independent instances of elasticsearch Note, that for development on a local machine, with small indices, it usually makes sense to "disable"
multicast and elect one master node — If the master nodes became unavailable the remaining nodes elect a new master node — If the old master comes back online again, it will not promoted to master again it remains a regular node in the cluster
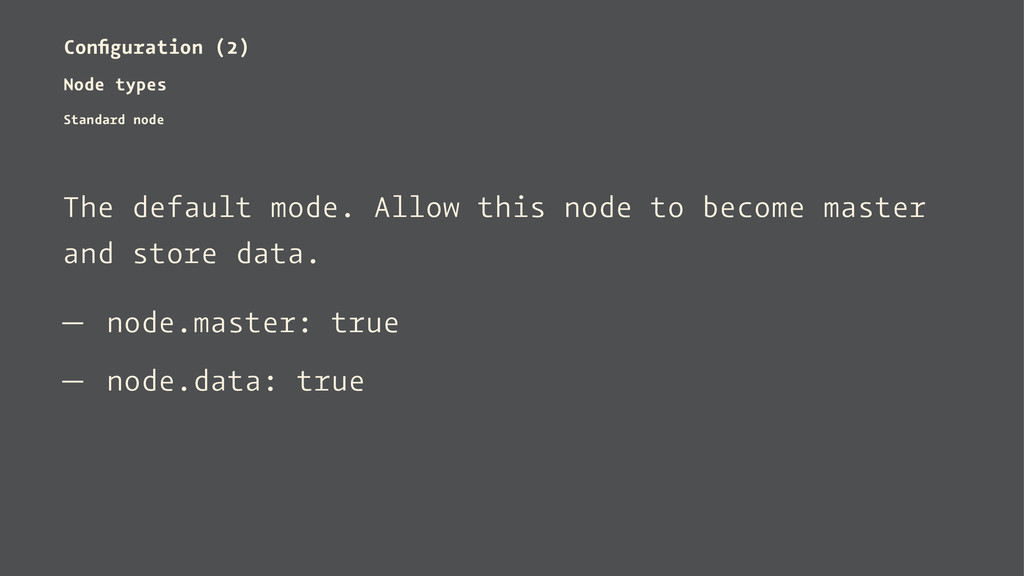
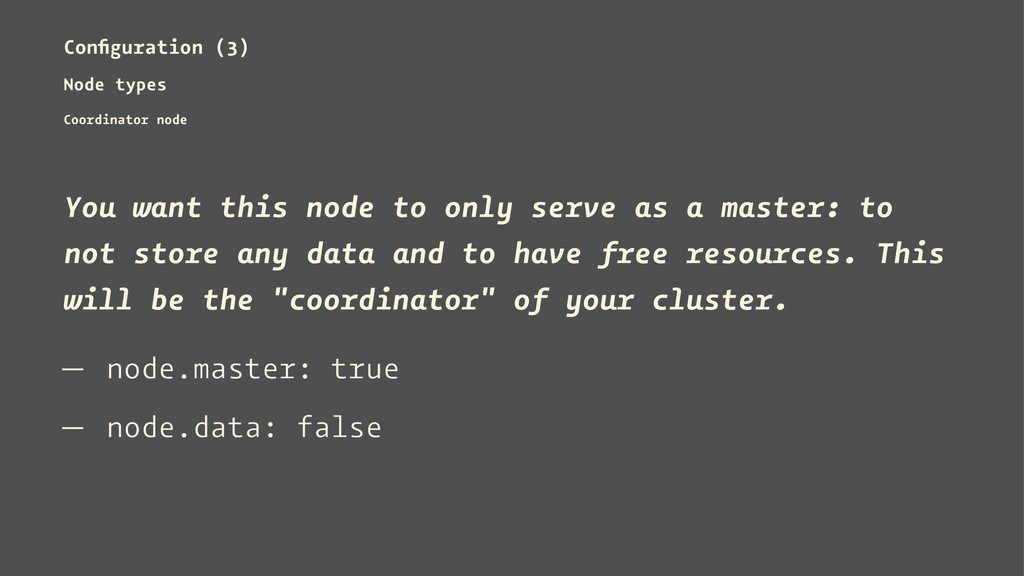
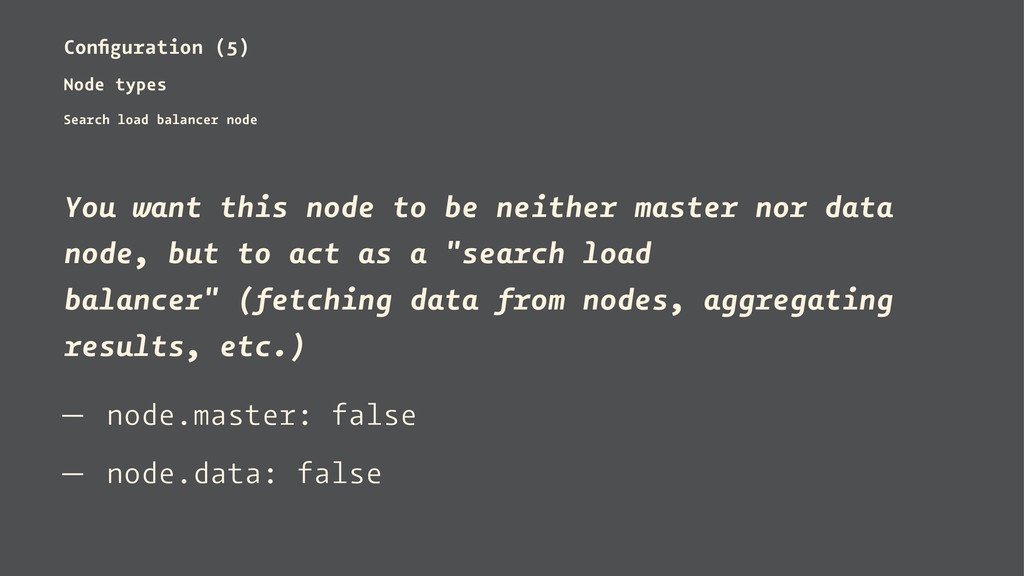
or deny being eligible as the master, and to allow or deny to store the data. — Standard node — Coordinator node — Workhorse node — Search load balancer node
to only serve as a master: to not store any data and to have free resources. This will be the "coordinator" of your cluster. — node.master: true — node.data: false
this node to be neither master nor data node, but to act as a "search load balancer" (fetching data from nodes, aggregating results, etc.) — node.master: false — node.data: false
allows to explicitly control which nodes will be used to discover the cluster. It can be used when multicast is not present, or to restrict the cluster communication-wise. discovery.zen.ping.multicast.enabled: false discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9301", "127.0.0.1:9302", "127.0.0.1:9304"]
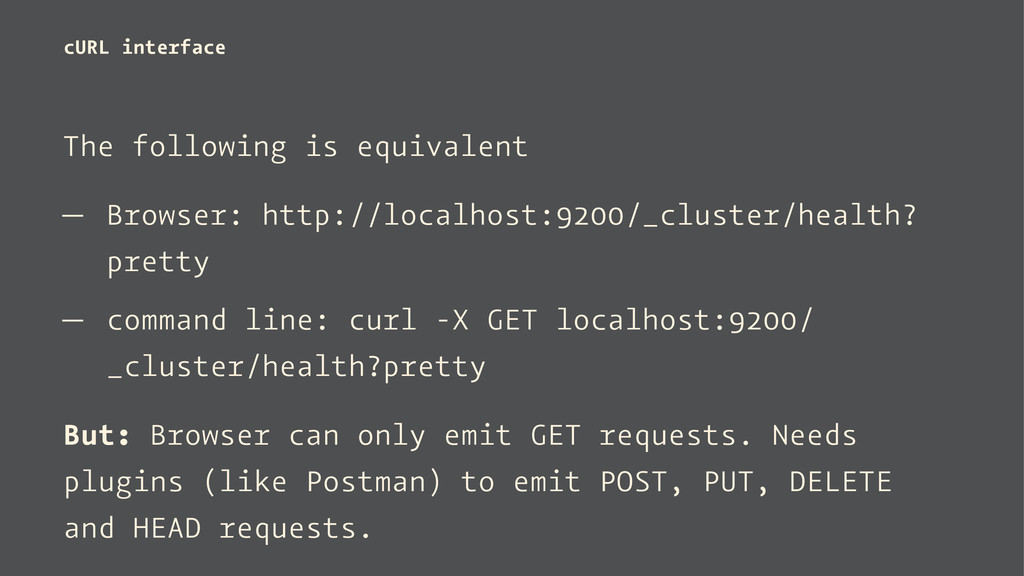
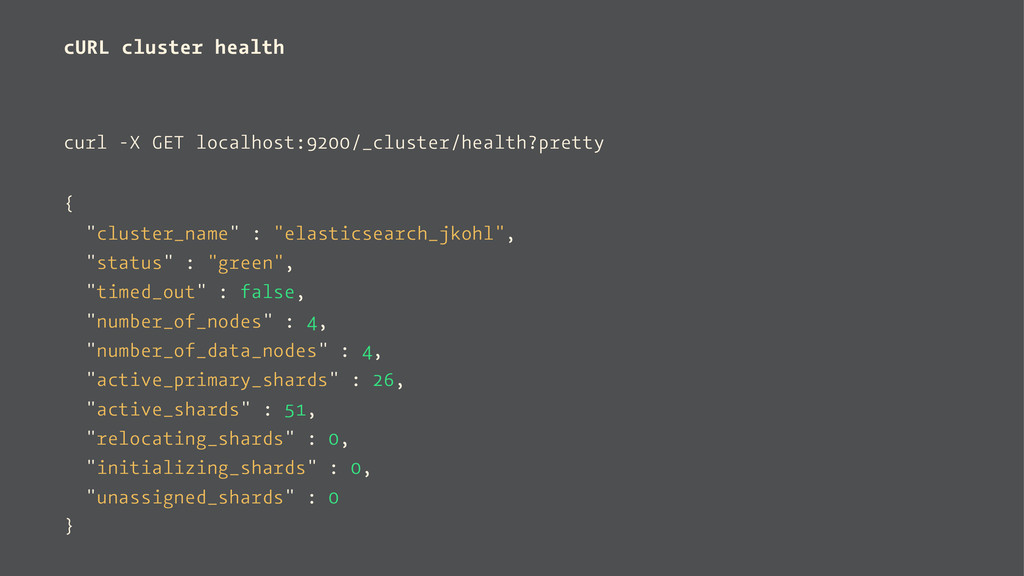
— command line: curl -X GET localhost:9200/ _cluster/health?pretty But: Browser can only emit GET requests. Needs plugins (like Postman) to emit POST, PUT, DELETE and HEAD requests.
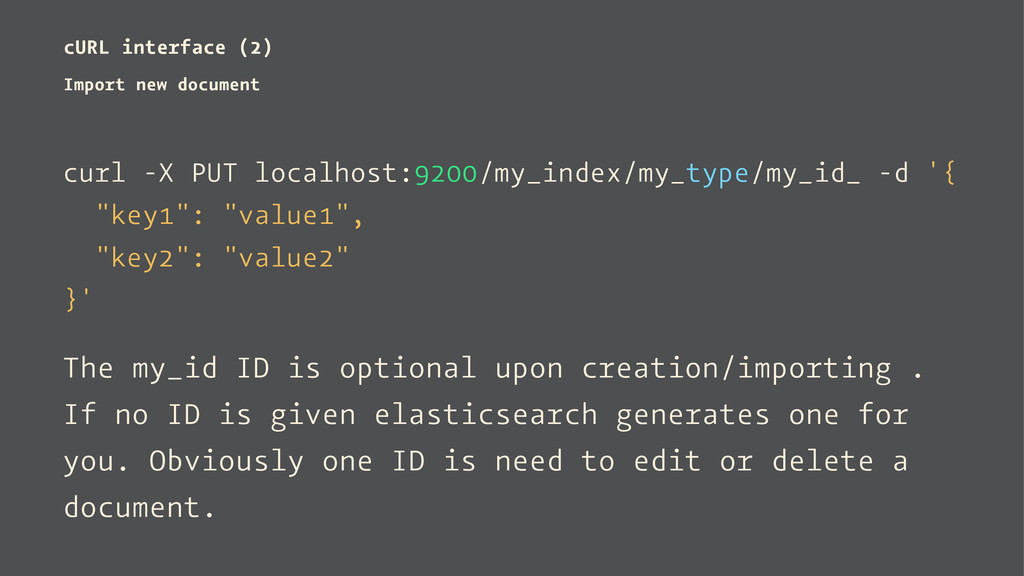
-d '{ "key1": "value1", "key2": "value2" }' The my_id ID is optional upon creation/importing . If no ID is given elasticsearch generates one for you. Obviously one ID is need to edit or delete a document.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}