Github source code: https://github.com/jlandure/simple-gemma3-ollama-langchainjs-app
Linkedin: https://www.linkedin.com/posts/jlandure_wwc25-gemma-googlecloud-activity-7348236927227097088-bZU3
Linkedin: https://www.linkedin.com/posts/jlandure_wad2025-serverlessgpu-wwc25-activity-7349324082124922882-Cj_R
AI solutions are booming, with best practices emerging, frameworks gaining popularity, and LLM switching becoming less cumbersome.
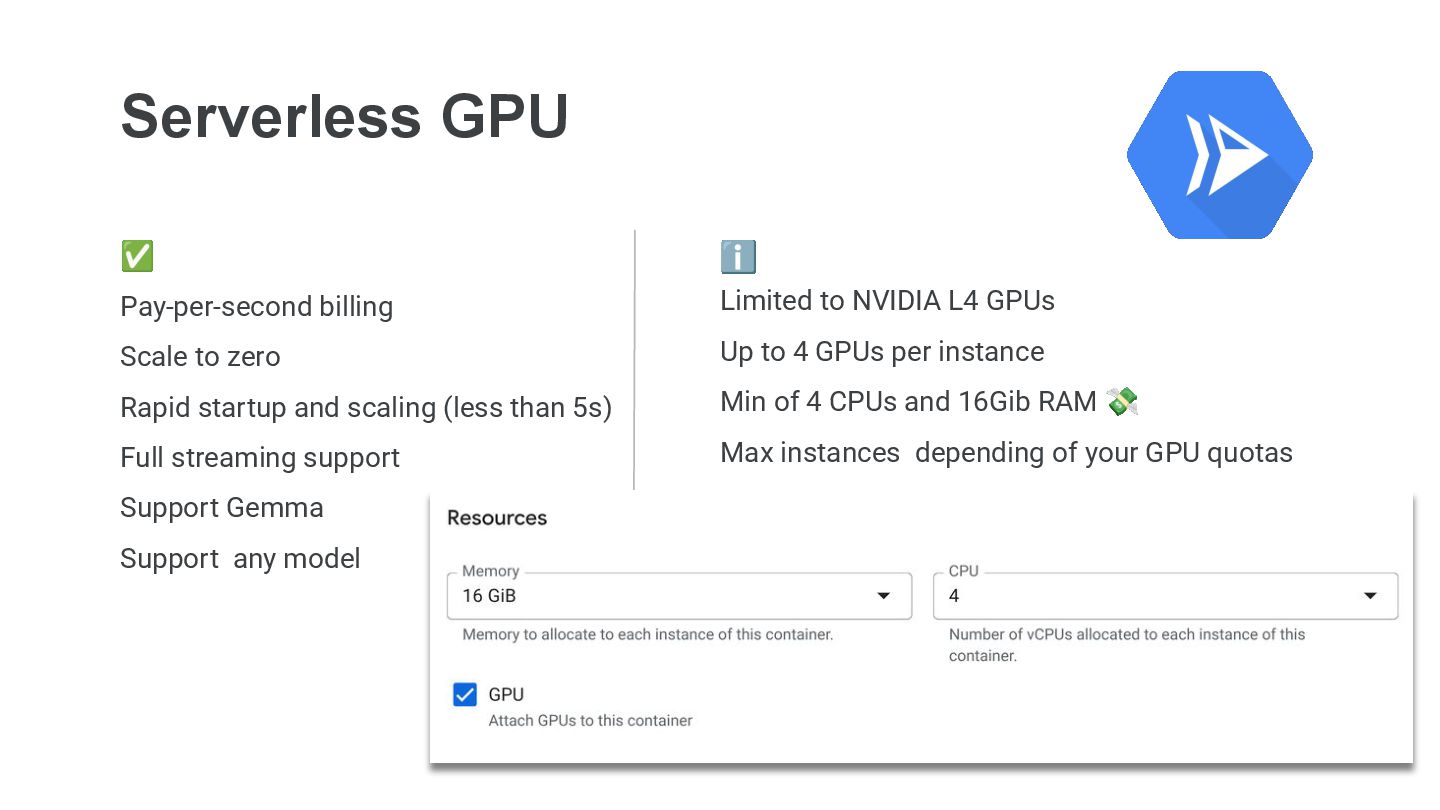
However, the path to production—especially when it comes to securely hosting your own LLM—often presents significant hurdles. This talk introduces an exciting solution: leveraging Serverless GPU options to minimize infrastructure overhead and maximize your focus on innovation.
We'll dive into how to use Google Cloud's Cloud Run with GPU to seamlessly deploy an open-source LLM, ensuring security and scalability without the usual headaches.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
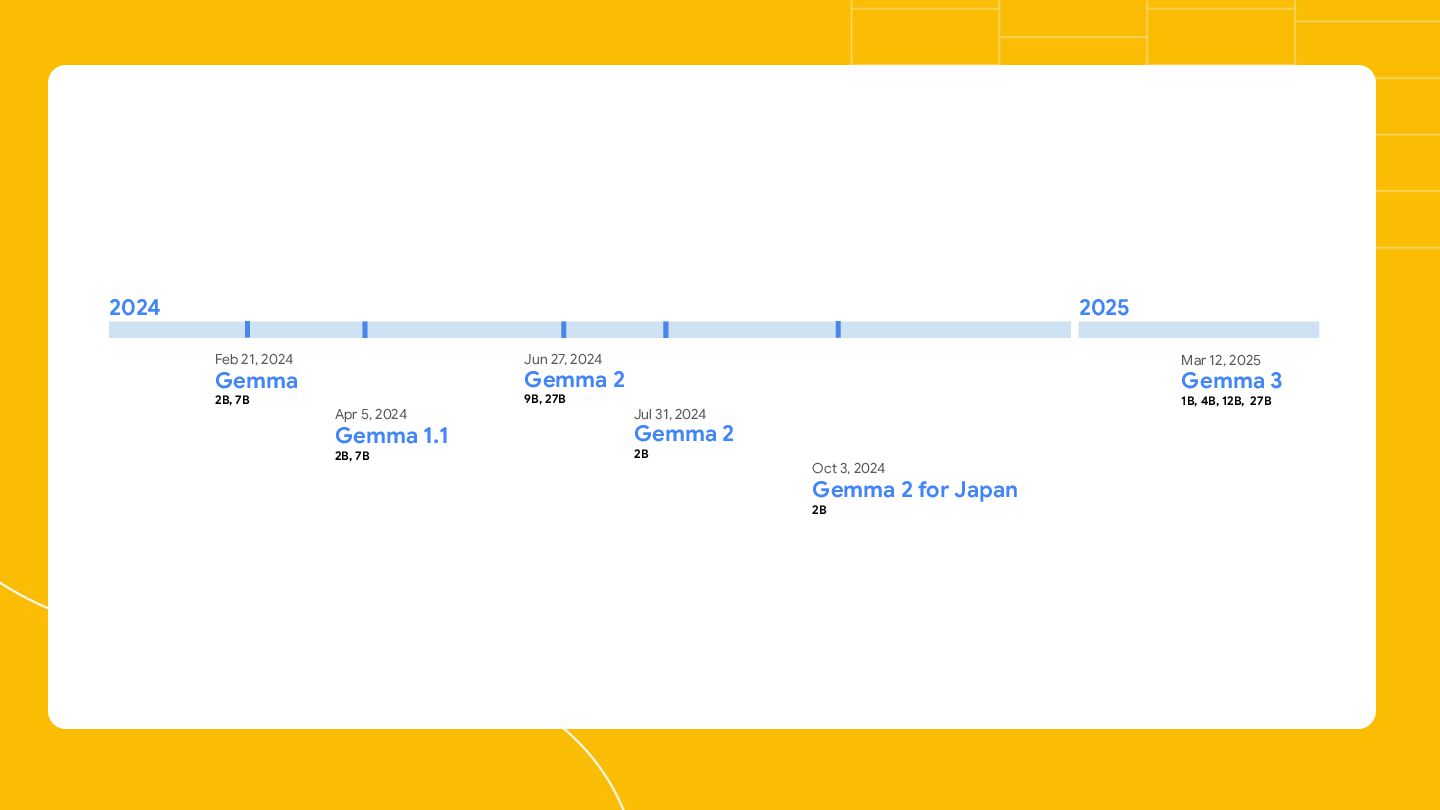{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
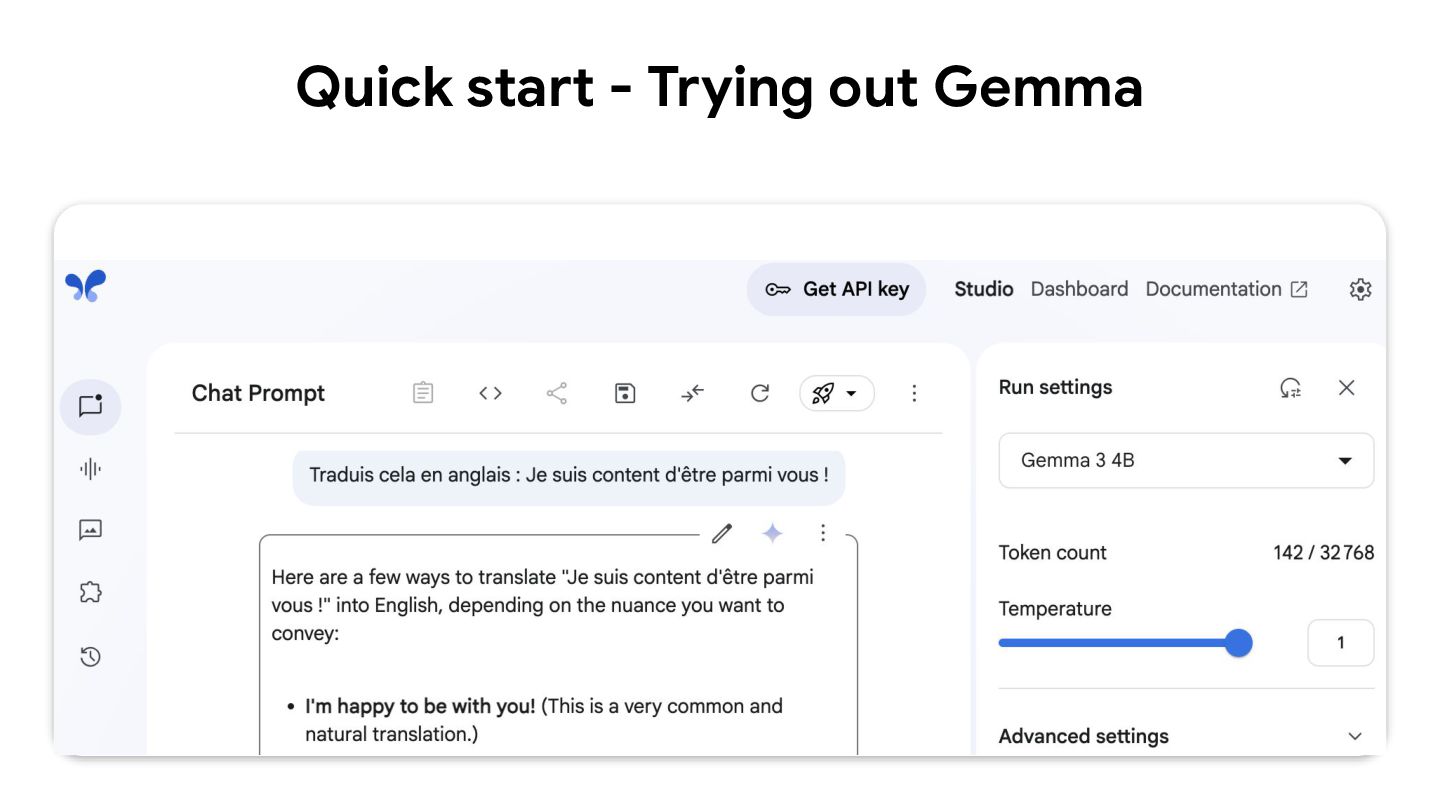{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}