Soirée exceptionnelle mélangeant les 3 communautés Cloud nantaises : Google Cloud avec le GDG Cloud Nantes, AWS avec AWS Nantes et Microsoft Azure avec le MTG Nantes.
https://www.linkedin.com/posts/aws-user-group-nantes_50-personnes-r%C3%A9unies-mission-r%C3%A9ussie-activity-7374009051375882241-DXsr/
https://www.linkedin.com/posts/jlandure_tr%C3%A8s-fier-dorganiser-ce-soir-the-clouds-activity-7373613608989106177-Xnaq/
Talk "Serverless GPU ou comment déployer facilement son LLM" par Julien Landuré
Description:
Les solutions d'IA fleurissent : de bonnes pratiques se mettent en place, des frameworks deviennent populaires, le changement de LLM est moins contraignant...
Par contre, quand il faut aller en production afin de pouvoir héberger son propre LLM pour assurer la sécurité, il n'y a moins de monde.
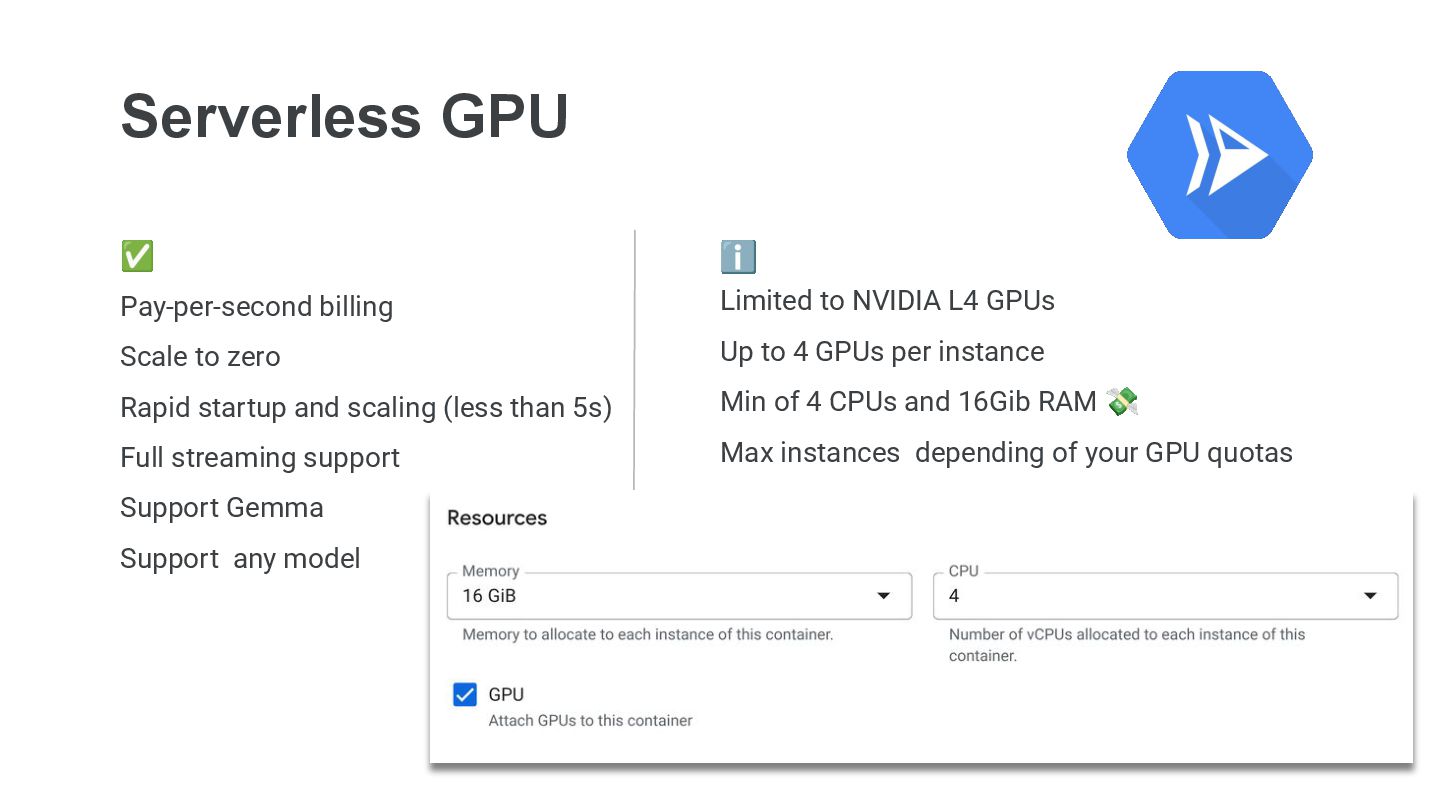
Une solution intéressante est de s'appuyer sur les solutions Serverless avec du GPU pour passer moins de temps sur l'infrastructure et plus de temps ailleurs !
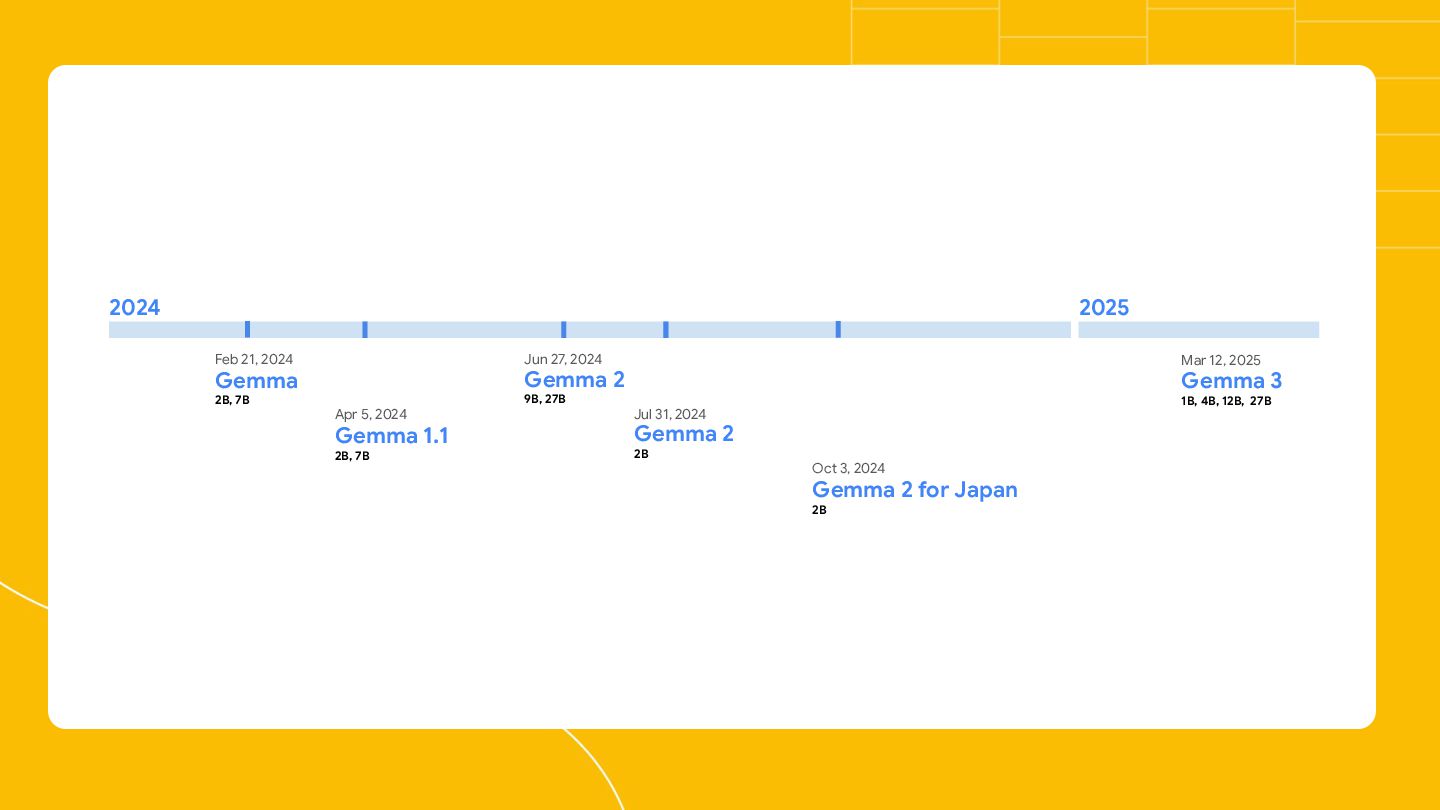
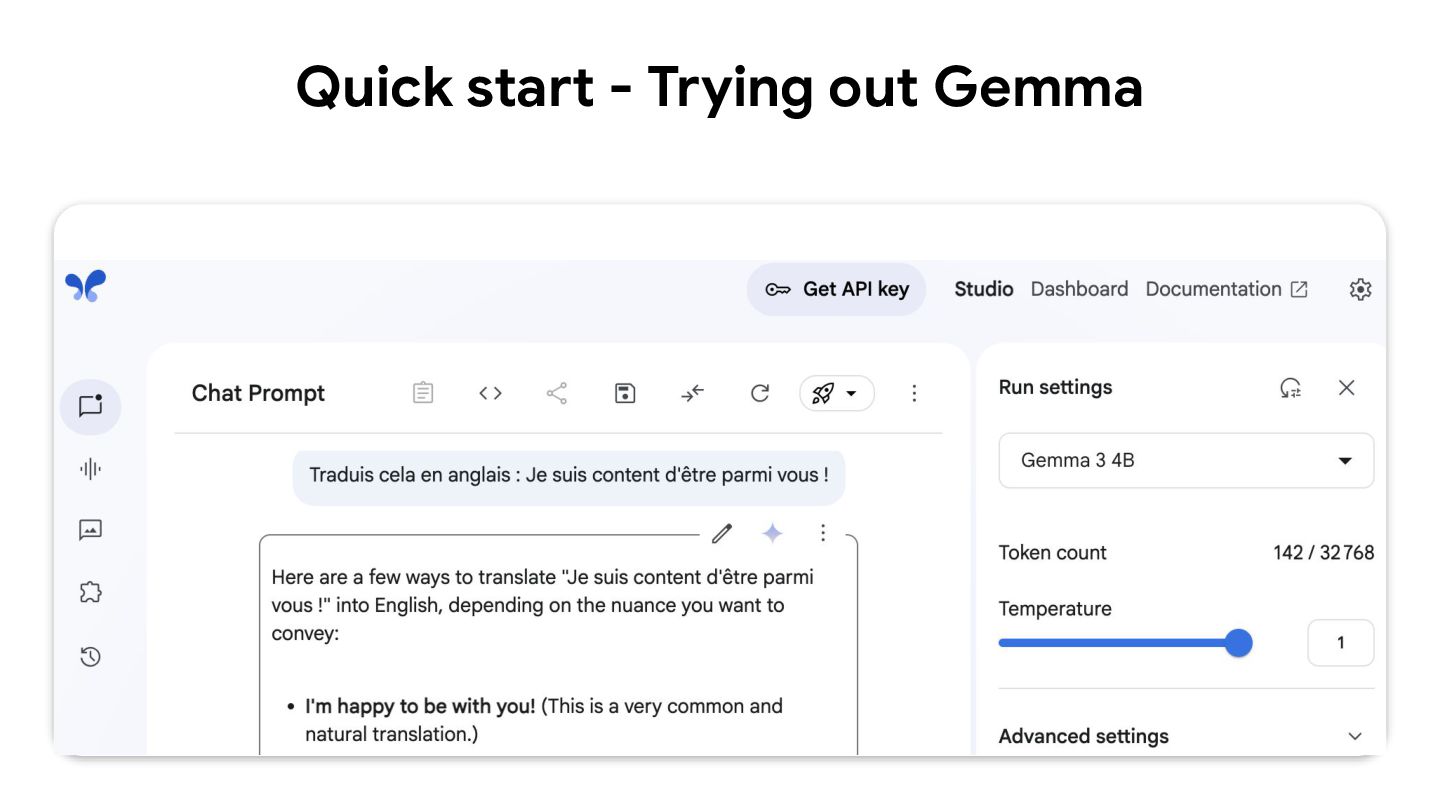
Durant ce talk, nous regarderons comment utiliser Cloud Run GPU de la plateforme Google Cloud pour déployer un LLM open (Gemma3).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}