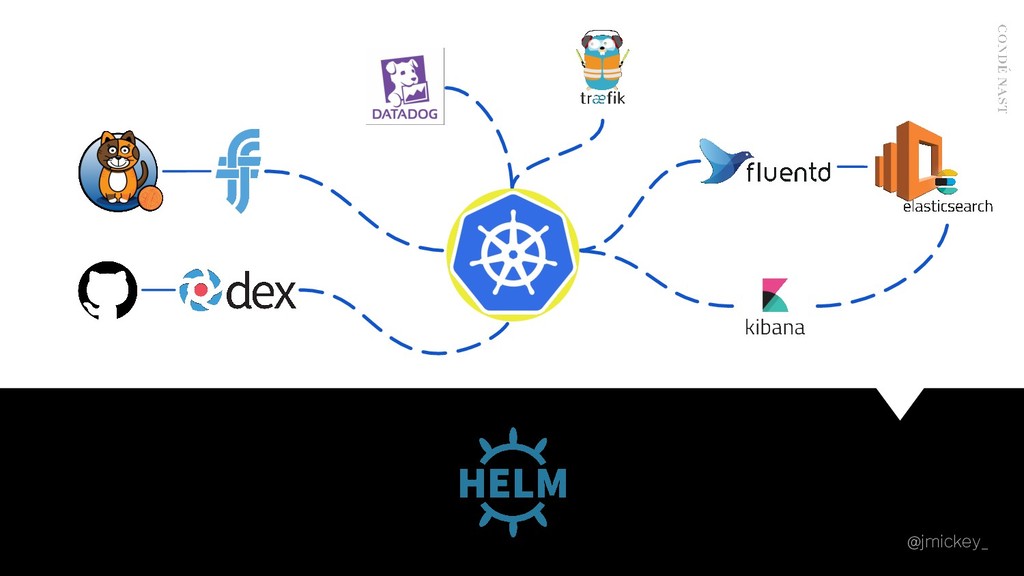
Condé Nast International is home to some of the largest online publications in the world - including Vogue, GQ, Wired, and Vanity Fair. In an effort to provide a cohesive vision for these brands across more than 30 markets, a global, centralised platform was required. Utilising AWS and Kubernetes at its core, the platform officially launched in September 2018 and serves over 80 million unique monthly users.
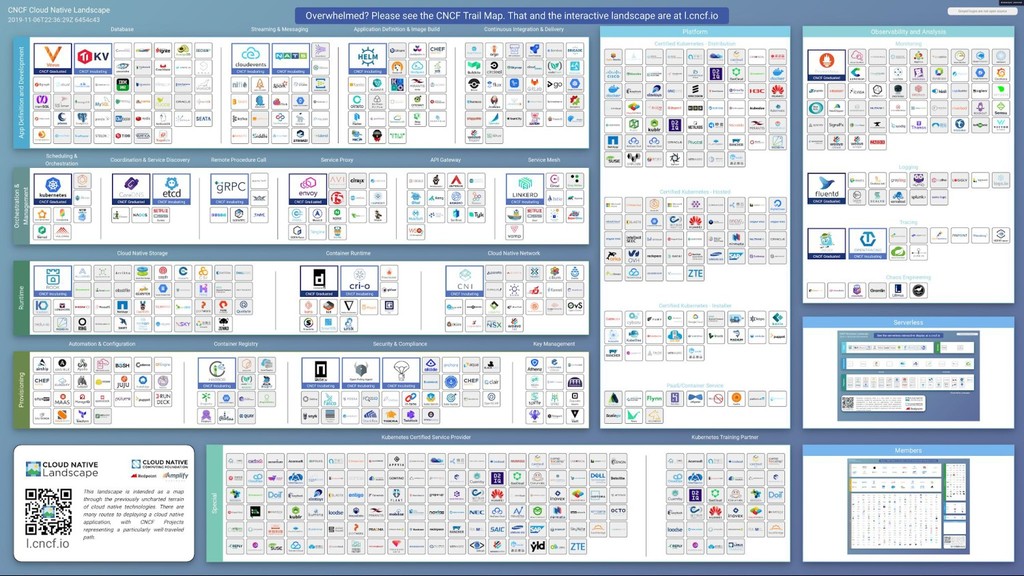
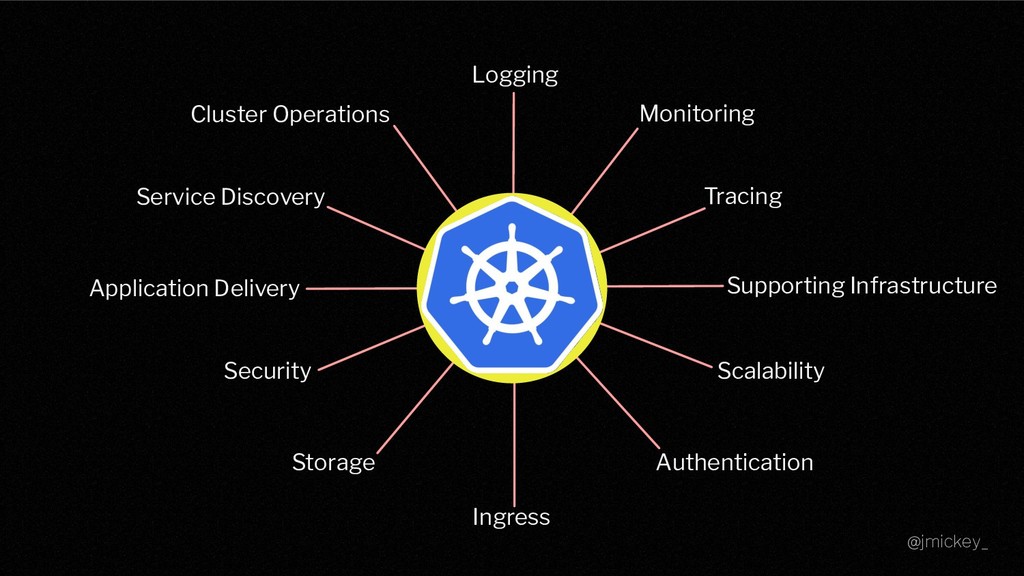
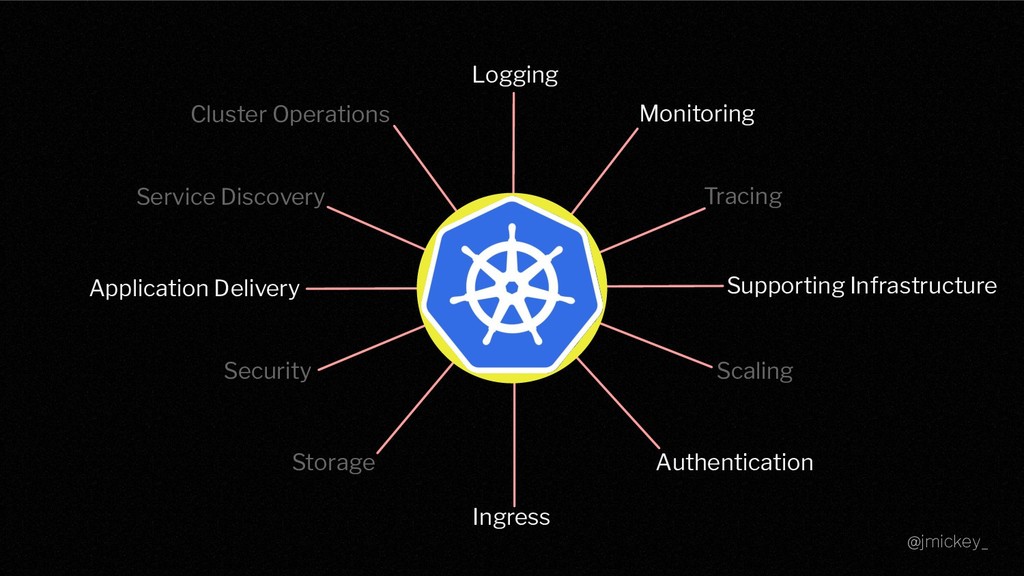
Of course, operating Cloud Native Infrastructure is more than just spinning up a container orchestrator! Auxiliary services are required in order to operate it effectively and provide developers with a true platform experience. The aim of this talk is to "go beyond the cluster", focusing on the problems that need to be solved before your platform can be truly considered "production ready". I will be discussing how Condé Nast International effectively operates multiple Kubernetes clusters across the world, paying special attention to observability, testing, application delivery, and developer experience. I will also explore the mistakes made along the way, and how we learned from those mistakes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}