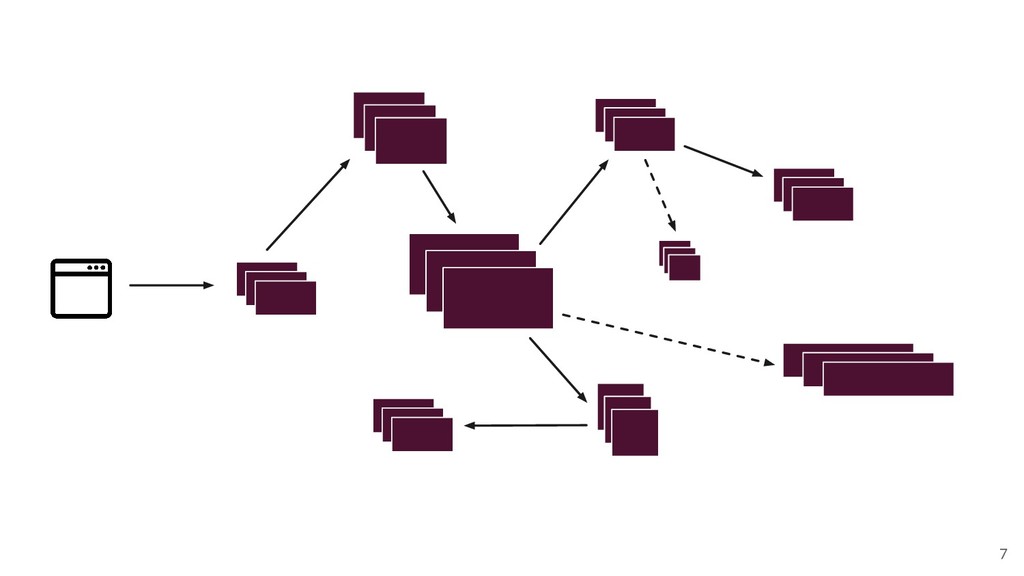
Microservices have transformed the way we think about software architecture and design. They enable developers to rapidly extend application functionality in the form of additional services, each of which can be scaled and deployed independently. Many highly successful software companies such as Netflix, Amazon, and Airbnb, have thousands of interconnected services which form the foundation of their products. These services often communicate over HTTP - passing messages between each other, synchronously and asynchronously, sometimes via message queues or brokers.
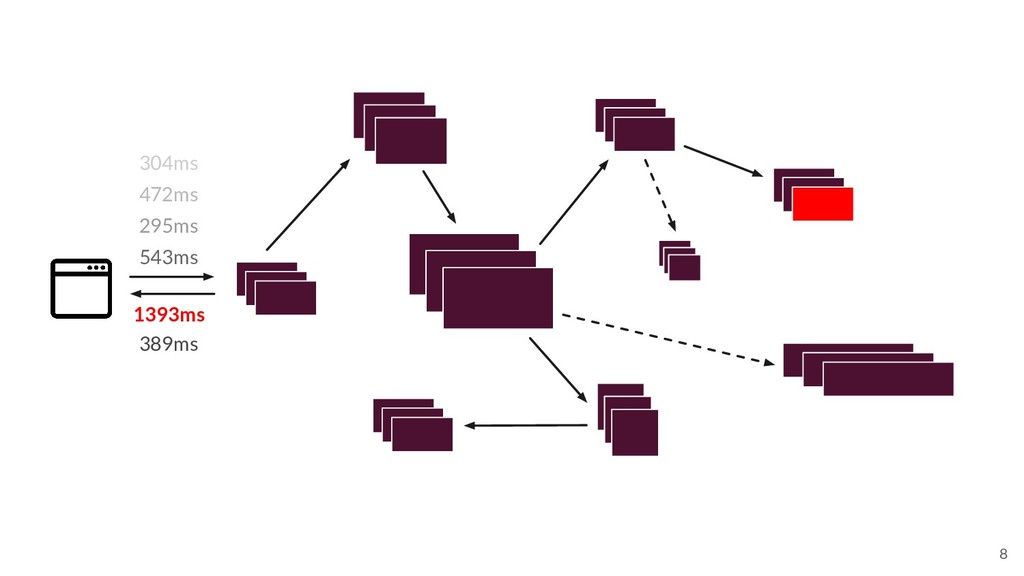
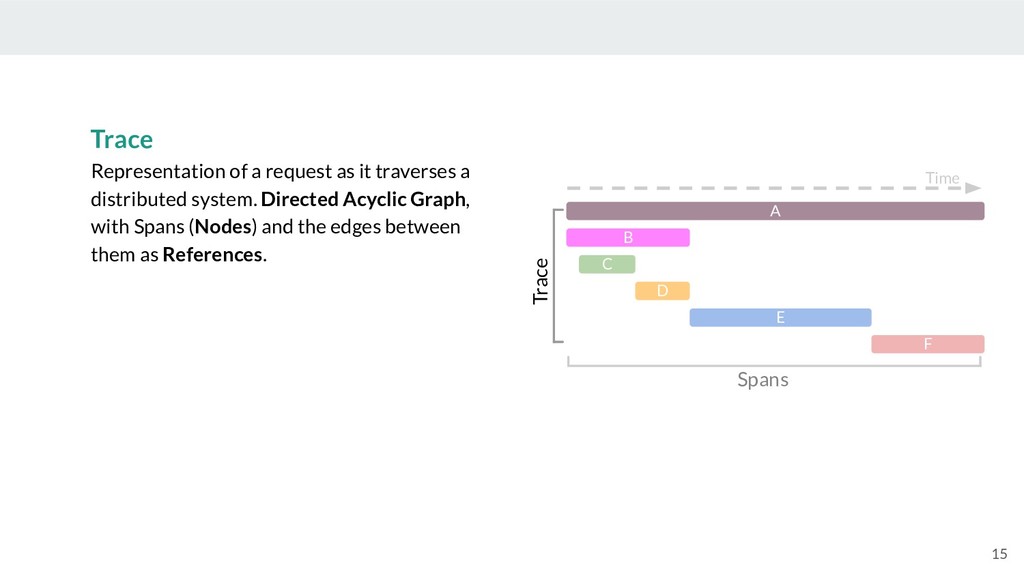
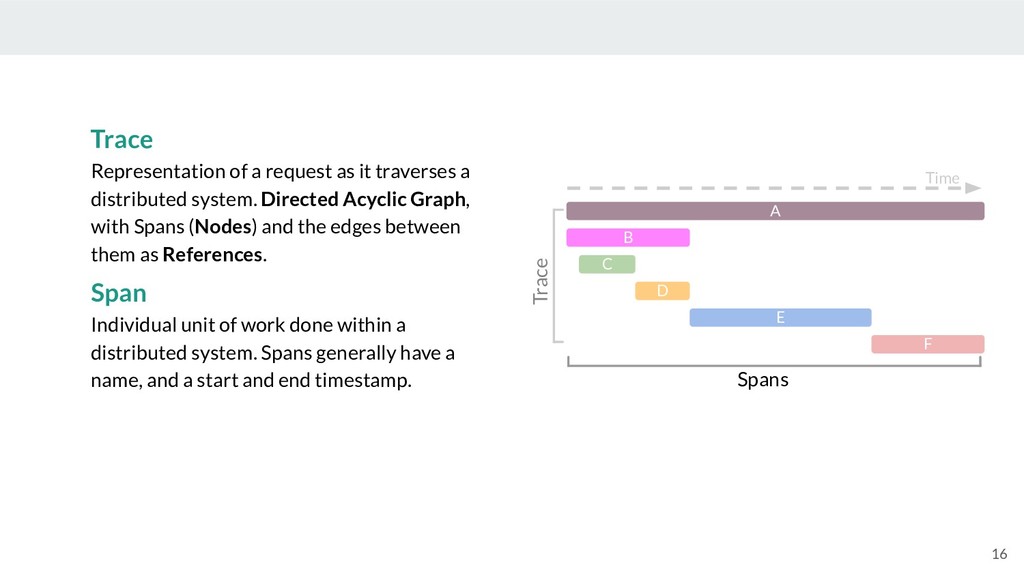
Of course, none of the benefits of microservices come without a cost. Networks are unreliable, and correlating thousands or millions of log entries between services can quickly become unmanageable. Therefore, understanding the source of an issue can be like finding a needle in a haystack. This is where distributed tracing comes in! Distributed tracing is the process of tracking requests through their lifetime within a complex distributed system, and has become a critical tool for debugging and understanding microservices.
In this session we will explore the basics of distributed tracing. We'll then take a look at the OpenTelemetry (formally OpenTracing) standard - a vendor neutral framework for distributed tracing instrumentation. Finally, we'll take a hands-on look at distributed tracing in action using Jaeger, a popular open source distributed tracing tool which is part of the Cloud Native Computing Foundation. By the end of this session I hope you will not only have a good understanding of distributed tracing, but will be equipped with the knowledge and inspiration to introduce it within your own applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
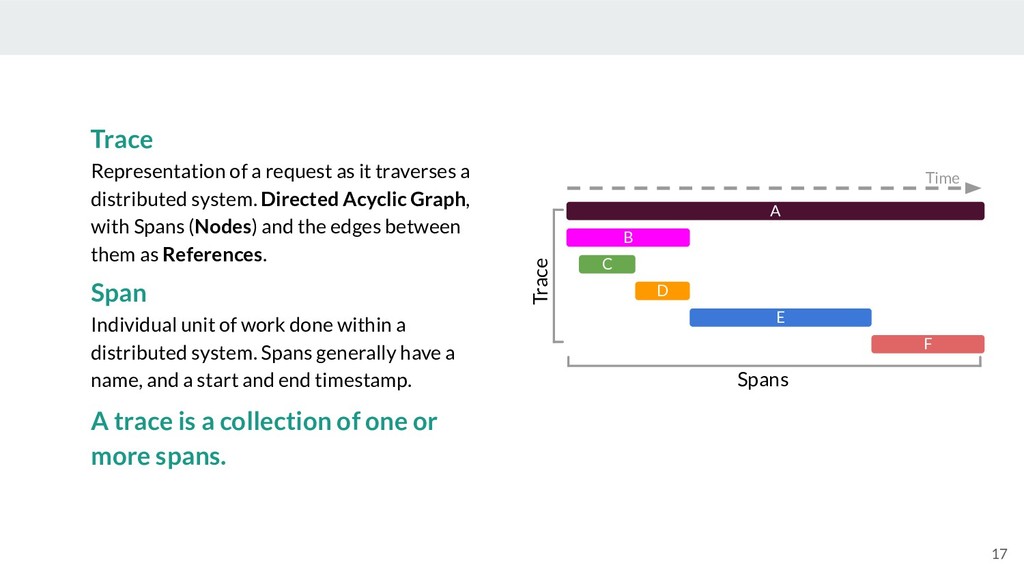{kind=link}
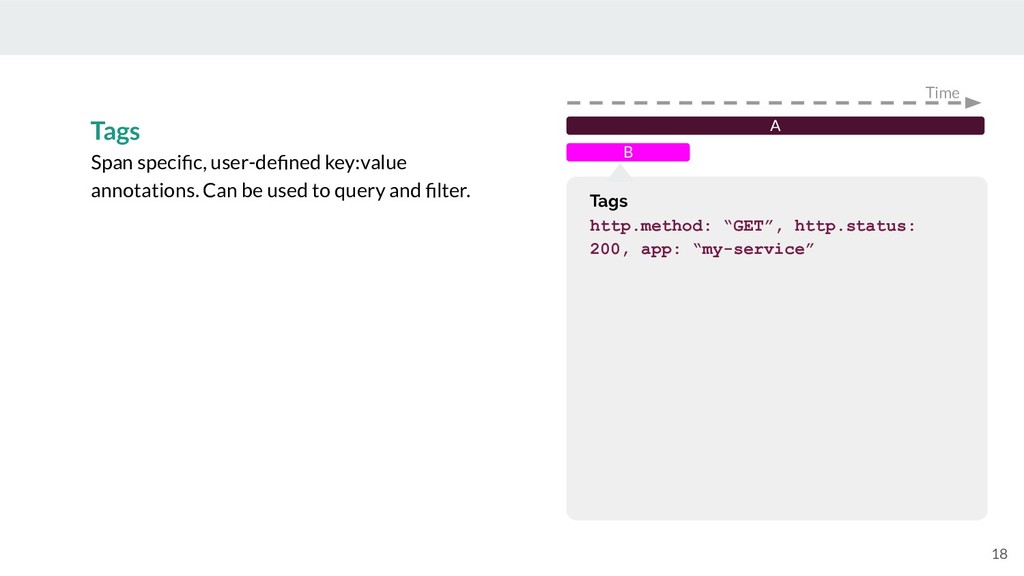{kind=link}
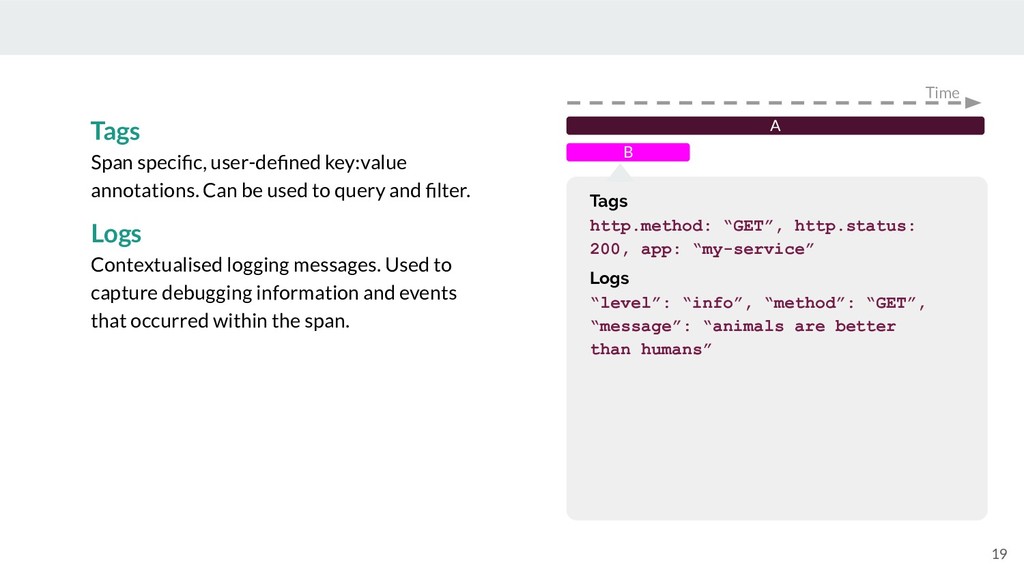{kind=link}
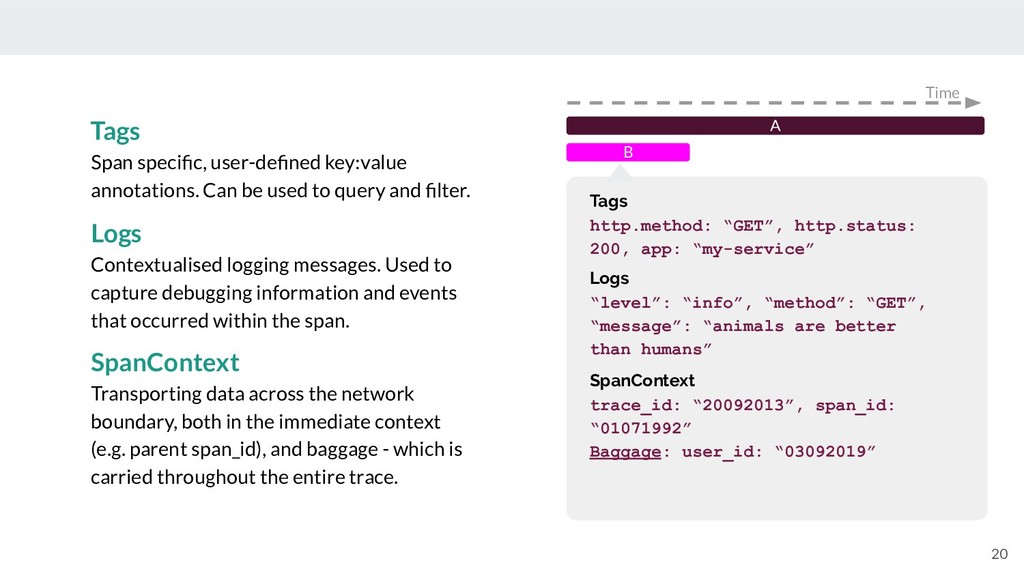{kind=link}
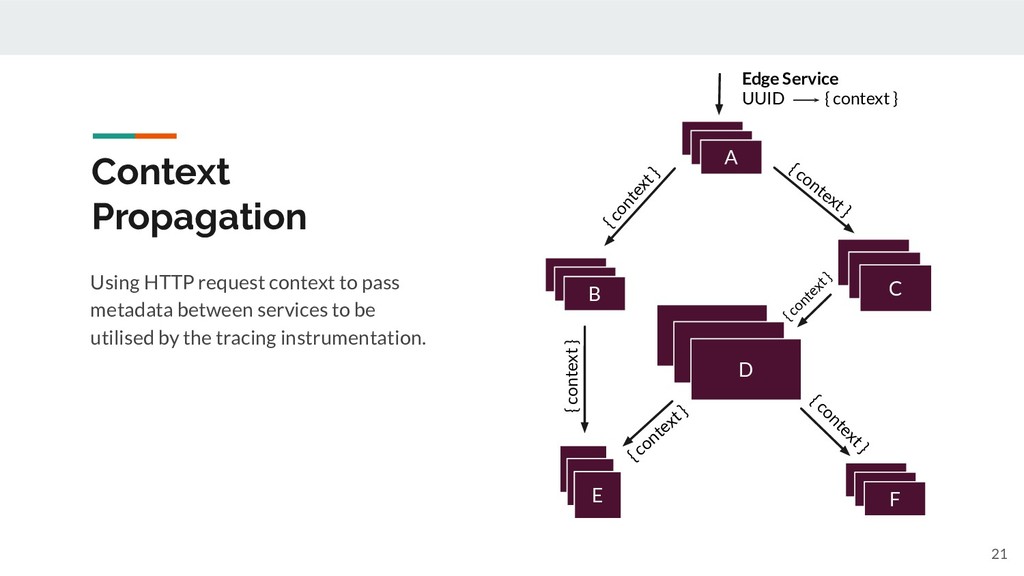{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
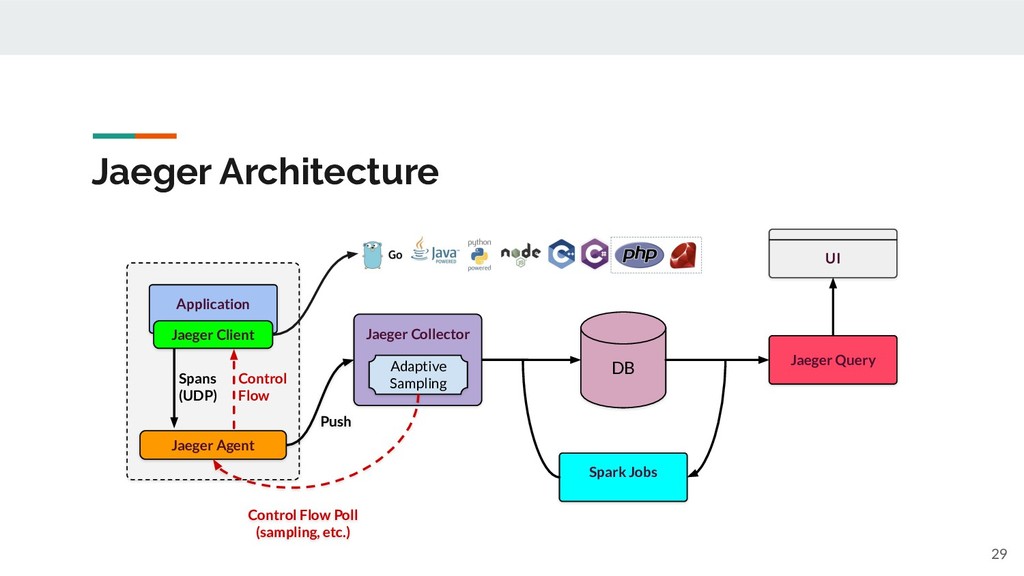{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![35 @jmickey_ jmichielsen jmickey mickey.dev [email protected] Thanks for Listening!](https://files.speakerdeck.com/presentations/37a5bcd15d12463da367ef2ee6ad2f96/slide_34.jpg){kind=link}