A use-case presentation on Research Computing at International Livestock Research Institute (ILRI).
Presented at the Science Gateways & Grid Infrastructures workshop at KENET, Nairobi.
partners is aimed at producing healthier crops & livestock to alleviate poverty & hunger in the developing world through exploitation of the latest genome technologies ◦ such technologies require state-of-the-art high-performance computing infrastructure for downstream data analysis & storage • ILRI HPC serves bioinformatics, statistics & geo-spatial computational needs of ILRI & its partners • By sharing computational power of HPC, researchers have been & will be able to conduct more extensive & large-scale genomic research quickly & cost-effectively
'thin' nodes • data storage over NFS to 'master' node • compute jobs had to use MPI ◦ writing & debugging MPI code is not easy! • Ran on Rocks Cluster distro • All this was revolutionary at that time!
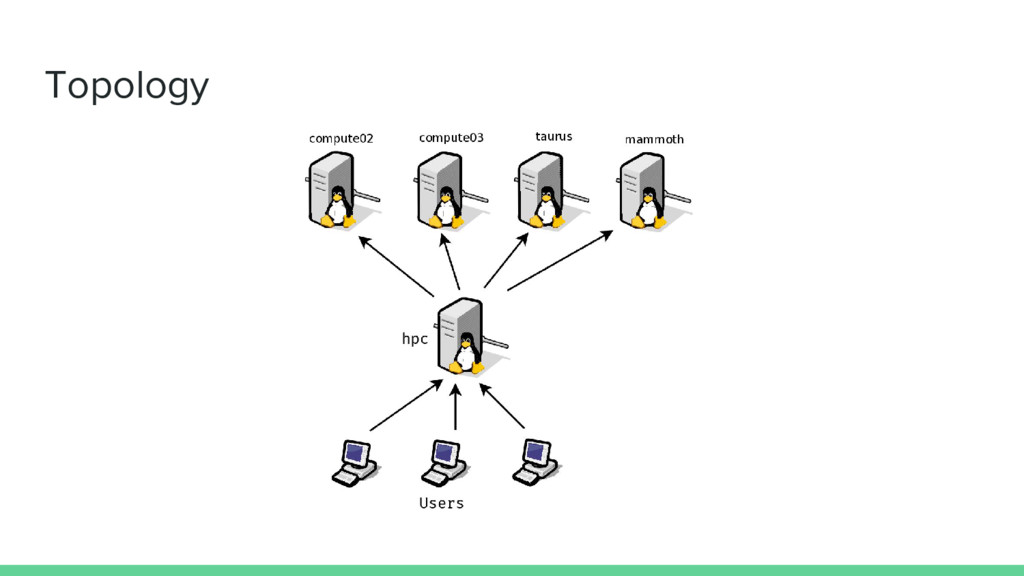
sections: ◦ Compute: ▪ Lots of CPU cores & RAM ▪ Minimal disk space ▪ Job scheduling done SLURM workload manager ◦ Storage: ▪ Lots of disk space ▪ At least 8 CPU cores ▪ Data is distributed & replicated in all storage servers ▪ GlusterFS distributed file system Users IDs, applications & data are available everywhere.
open source, highly scalable cluster management & job scheduling system for Linux clusters ◦ was conceived at Lawrence Livermore National Labs(LLNL) ◦ SLURM manages & accounts for computing resources ▪ users request CPU cores, memory & node(s) ◦ queues & prioritizes jobs, logs resource usage, e.t.c • Users can submit ‘batch’ and or ‘interactive’ jobs ◦ ‘batch’ jobs can be long-running jobs, invoke a program multiple times with different variables/options/arguments e.t.c. ◦ Running an ‘interactive’ job is as easy as typing interactive command!
distributed network file system developed by RedHat • Can do replicate, distribute, replicate+distribute, geo-replication(off site!) e.t.c. volumes • In ILRI HPC, we have 3 glusterfs replicated volumes: ◦ homes volume: contains users’ home folders, mounted in /home ◦ apps volume: contains all applications; mounted in /export/apps ◦ data volume: contains data(databases, genomes, e.t.c) shared amongst users/groups; mounted in /export/data • persistent directory paths: users can access data in GlusterFS volumes from any compute node/server within the cluster; distributed transparency
modules — http://modules.sourceforge.net • Environment modules makes it easy to support multiple application versions, libraries, dependencies, shell environment variables, e.t.c. • Install once, use everywhere… • List of applications installed on the cluster http://hpc.ilri.cgiar.org/list-of-software
& authentication done by System Security Services Daemon(SSSD) ◦ SSSD also caches logins; faster logins than using pam_ldap • Consistent UIDs/GIDs across all nodes; you only need to login once, on the head node
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![More info & contact [email protected] http://hpc.ilri.cgiar.org/](https://files.speakerdeck.com/presentations/330b8404c7bc429bb4e0abc535c51f1f/slide_12.jpg){kind=link}
{kind=link}