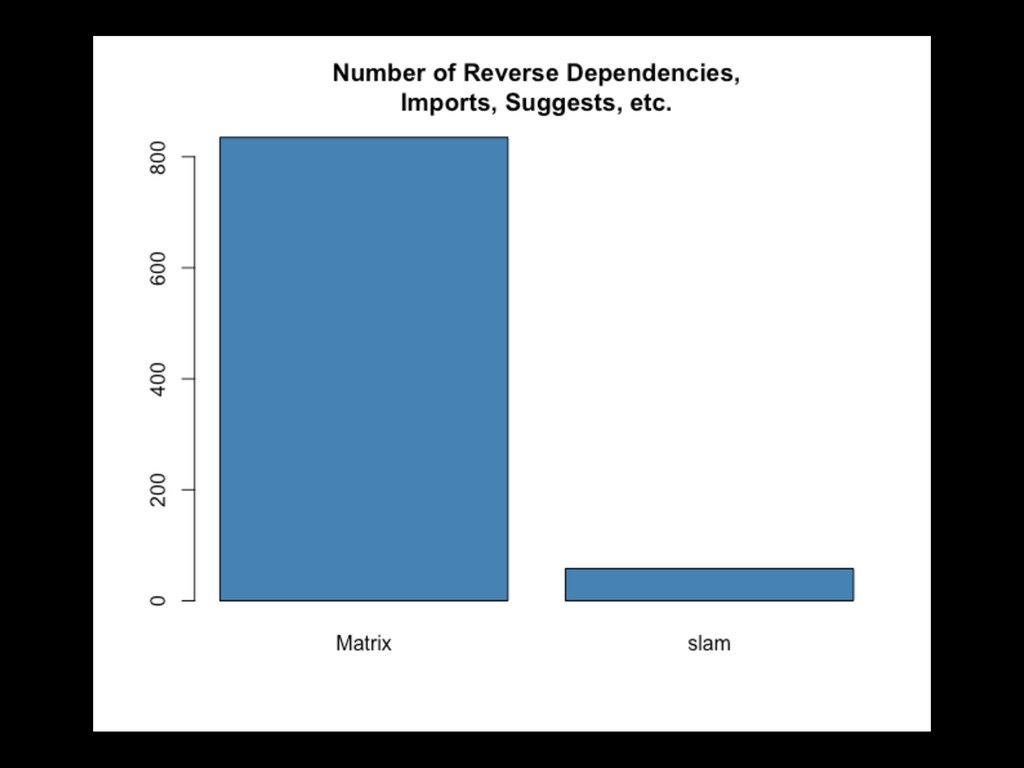
framework 1. Maximal interoperability with other R packages 2. Scaleable for object storage and computation time 3. Syntax that is idiomatic to R • A pretty darn good topic modeling work bench • Some special stuff based on my research
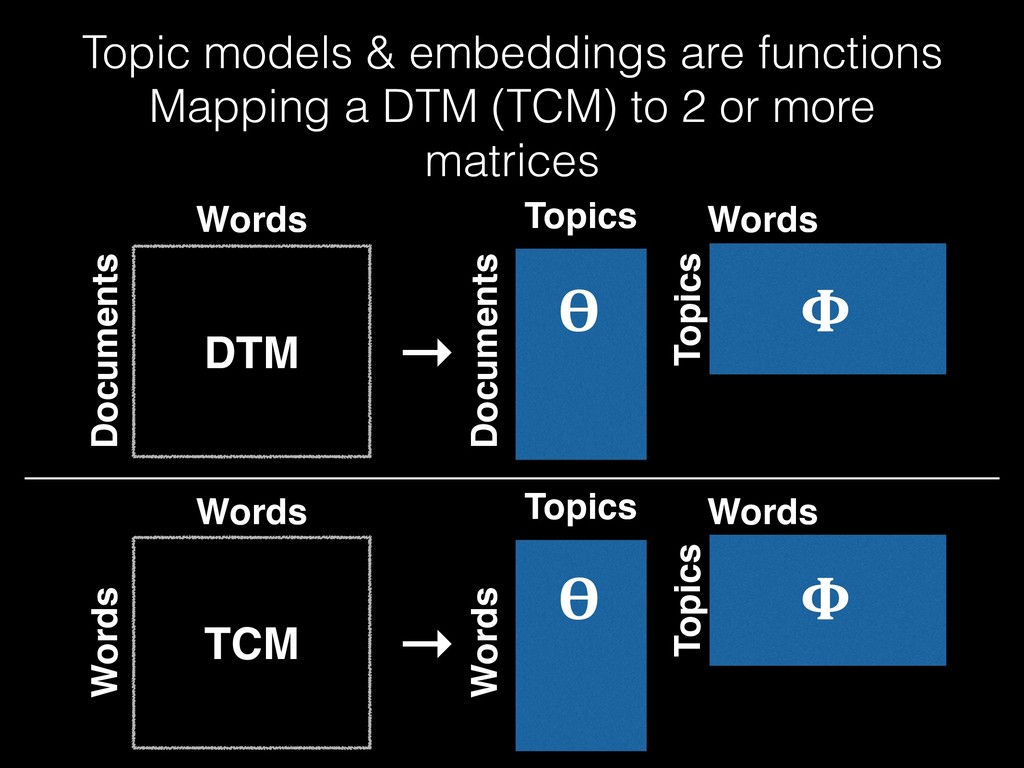
Document 4 Document 5 … reduce health policy food choice study sodium social … 1 1 1 2 1 2 1 1 3 • Rows are documents • Columns are linguistic features • Much wider than tall
sodium social … reduce health policy food choice study sodium social … 1 1 2 2 1 2 1 1 3 1 • Rows and columns are linguistic features • Square, not necessarily symmetric
n-grams • stems, lemmas, parts of speech, named entities, etc… • What is a document? • Books, chapters, pages, paragraphs, sentences, etc… • What is the measure relating my rows to columns? • Raw counts, TF-IDF, some other index, etc… • Skip-grams, count of document co-occurence, etc…
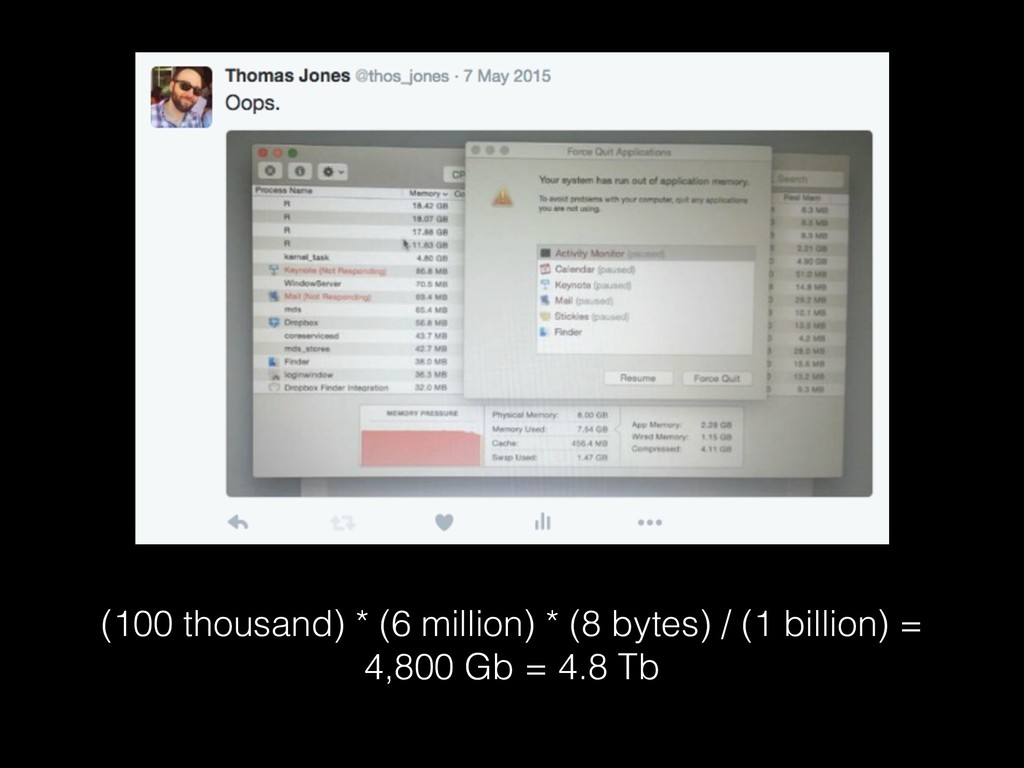
corpus with many terms removed) is 1.6 Gb • 10,000 X 60,000 matrix (the same ratio of rows to columns as on the last slide) is 4.8 Gb • 20,000 X 100,000 (a fairly standard corpus size) is 16 Gb.
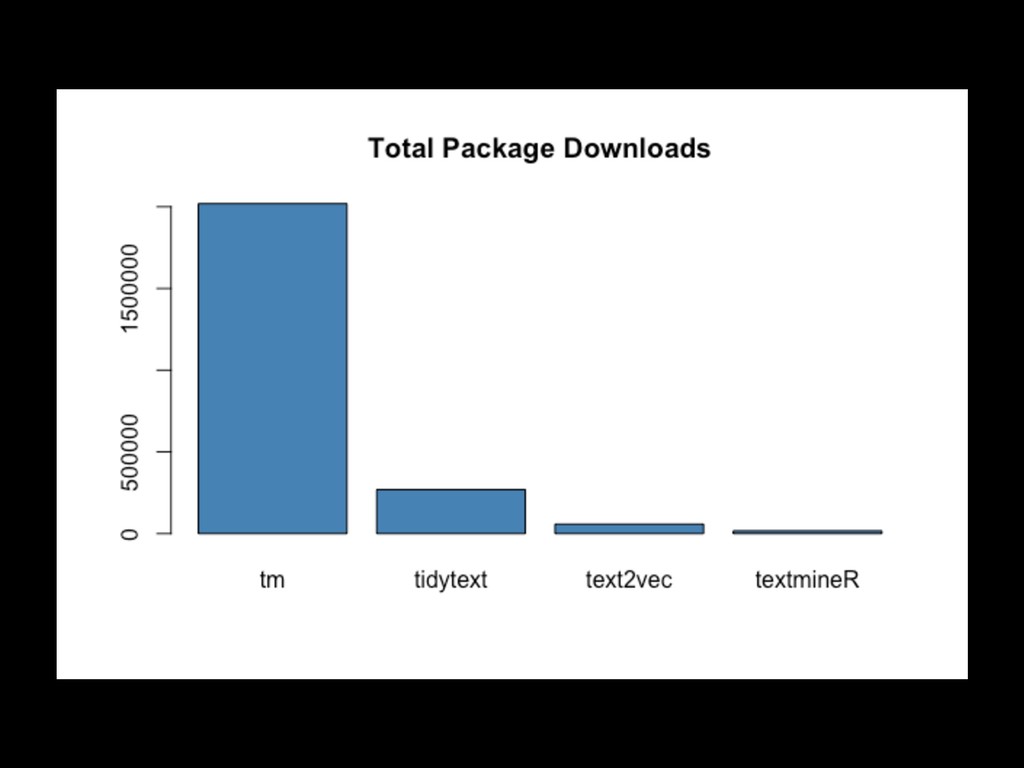
Latent Semantic Analysis (LSA/LSI) - Native with help from RSpectra • Correlated Topic Models (CTM) - from the topicmodels package • Help wanted for more!
neighboring words in each topic • Ranges between 1 and -1 • Values close to 0 indicate statistical independence (not a great topic) • Negative values indicate negative correlation (likely a terrible topic)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You • [email protected] • twitter: @thos_jones • http://www.biasedestimates.com •](https://files.speakerdeck.com/presentations/091f9ef6ae96460290500a552bdd1321/slide_35.jpg){kind=link}