It is not so difficult to “kubernetize” your application, but what’s next? There are so many subtle things to consider to make your application performant and reliable.
Unfortunately, it is easy to make it wrong: a small change in resource limits can slow your application, a wrong container liveness check will make your app crash faster under heavy load, and even following containerization best practices can make your application less performant. Let’s see why!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
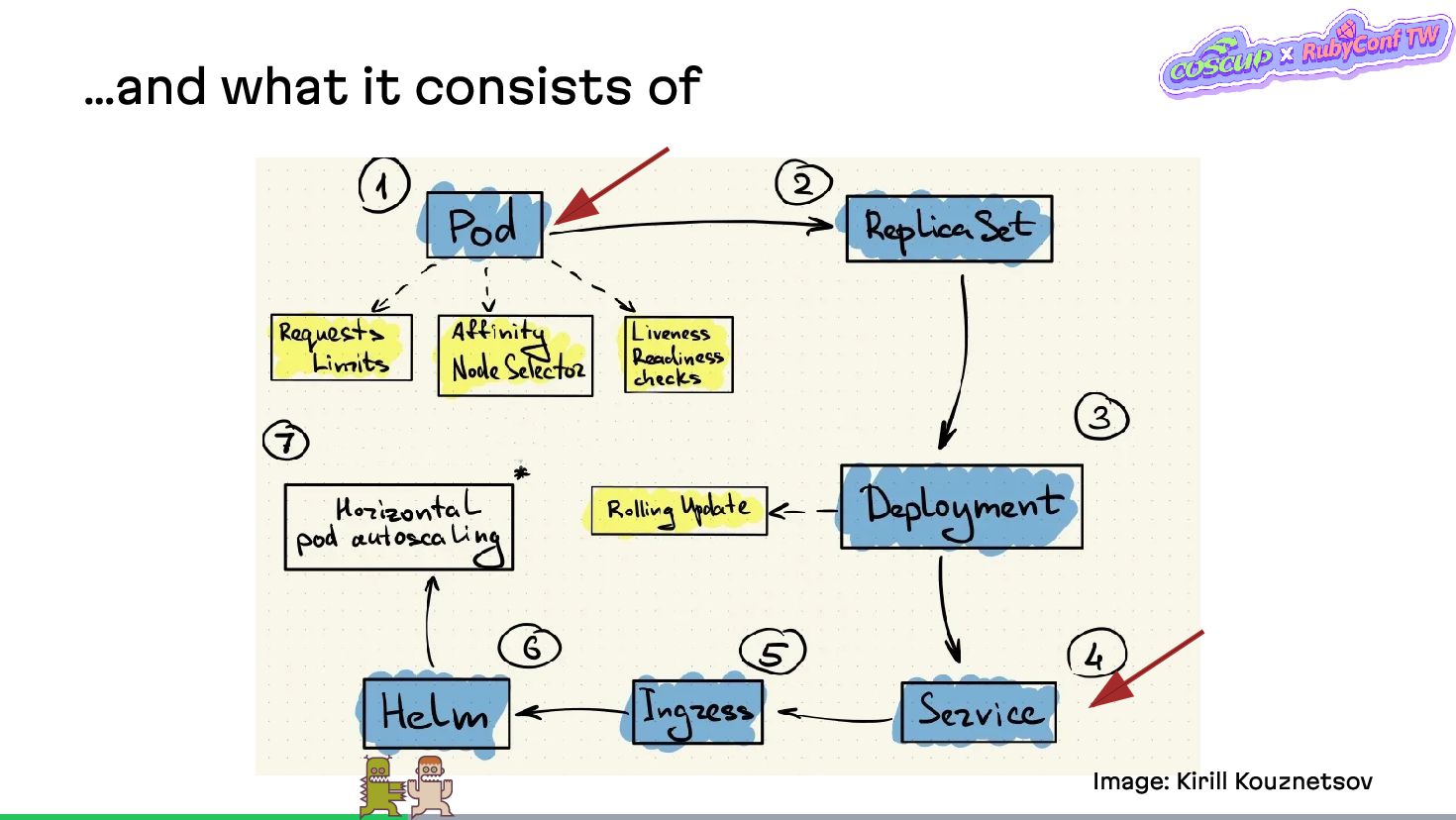{kind=link}
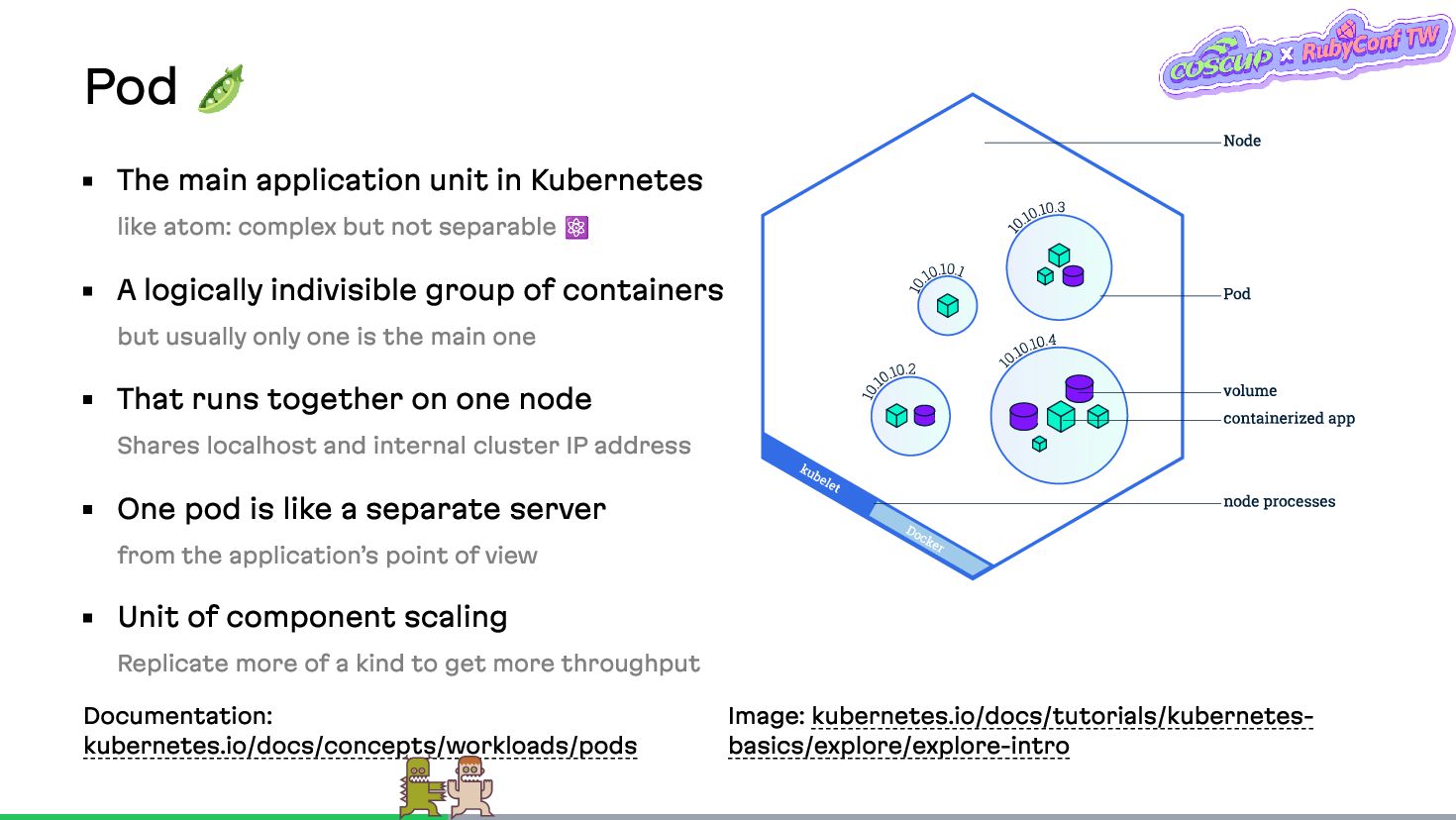{kind=link}
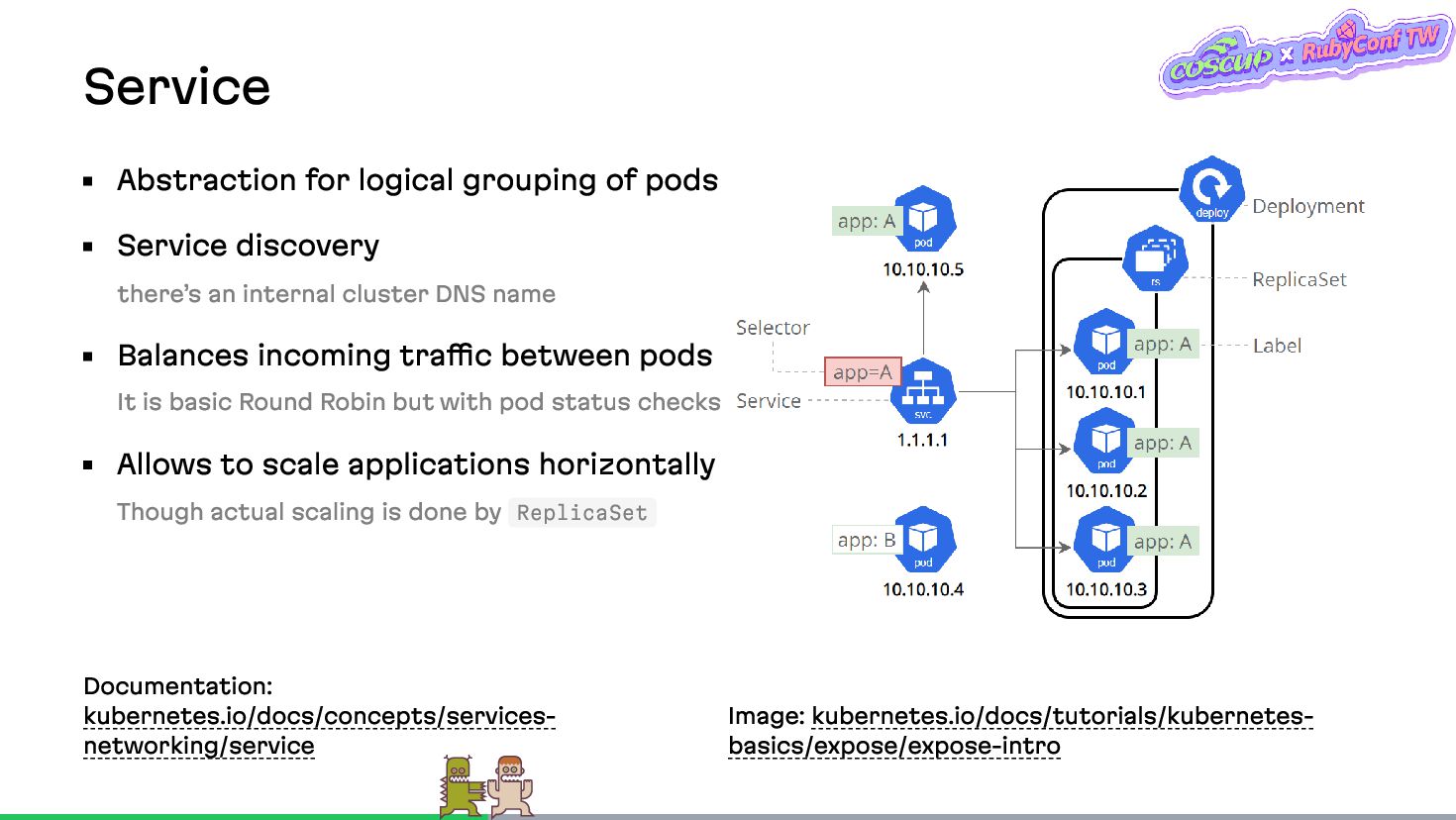{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
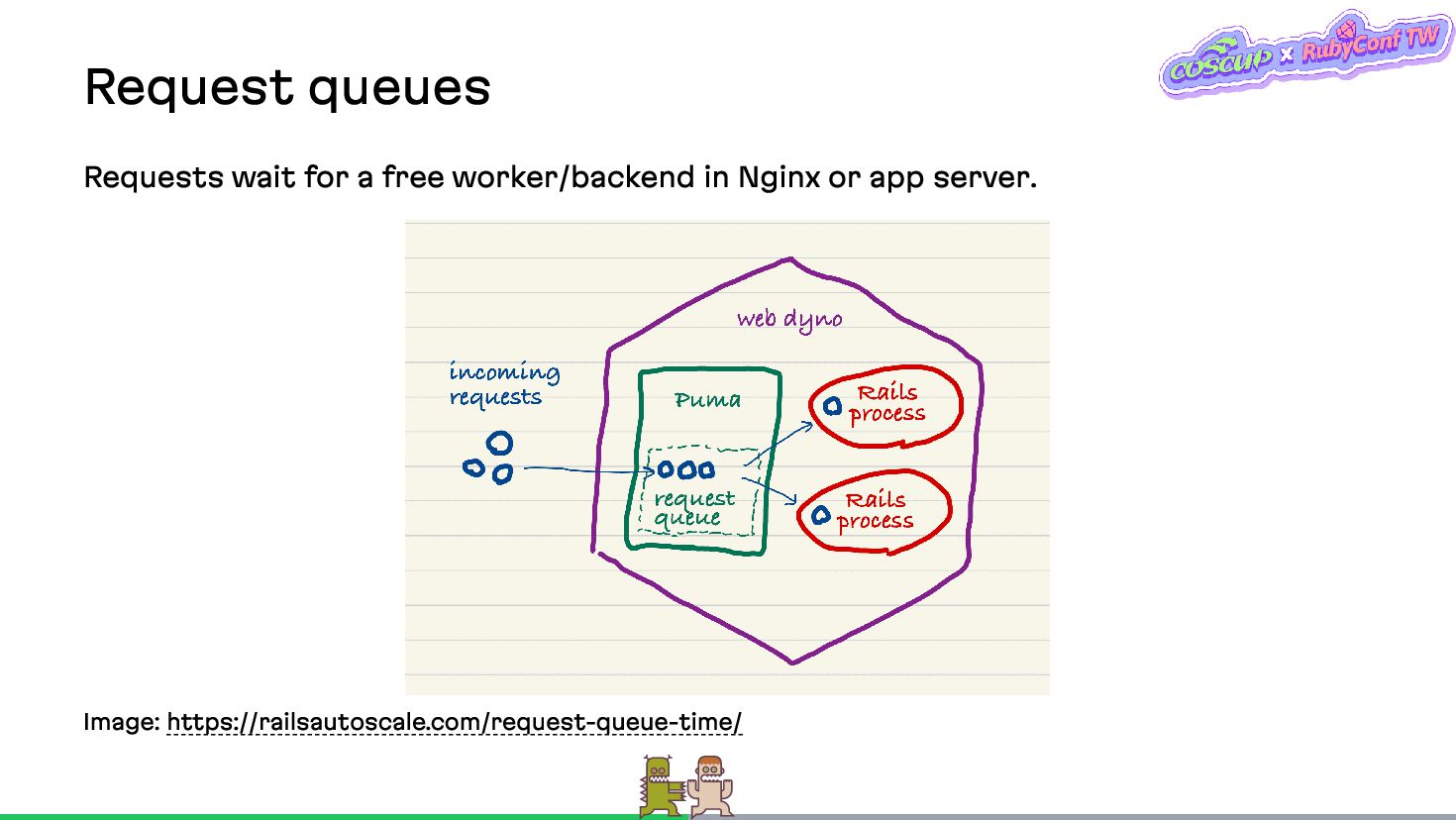{kind=link}
{kind=link}
{kind=link}
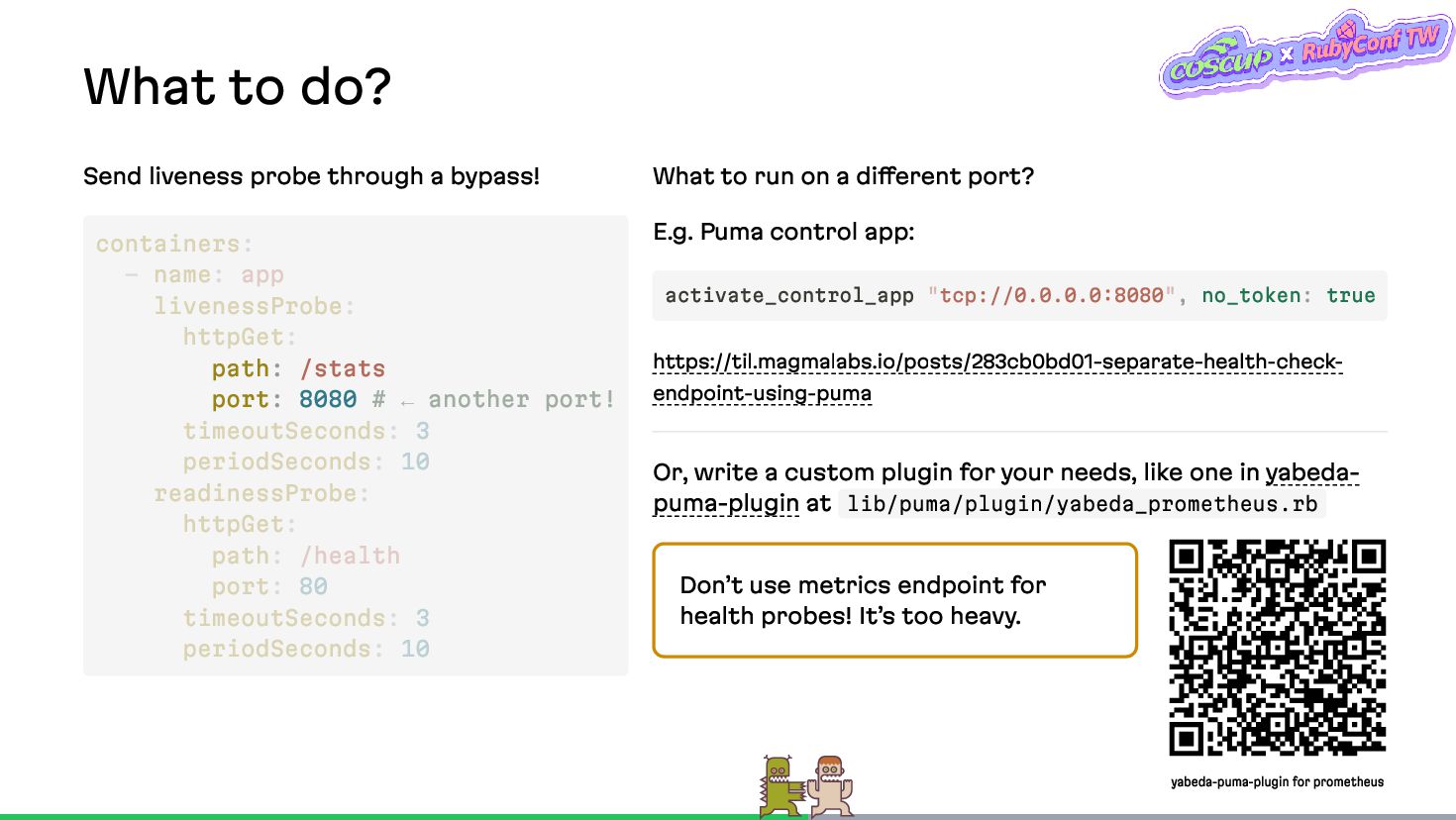{kind=link}
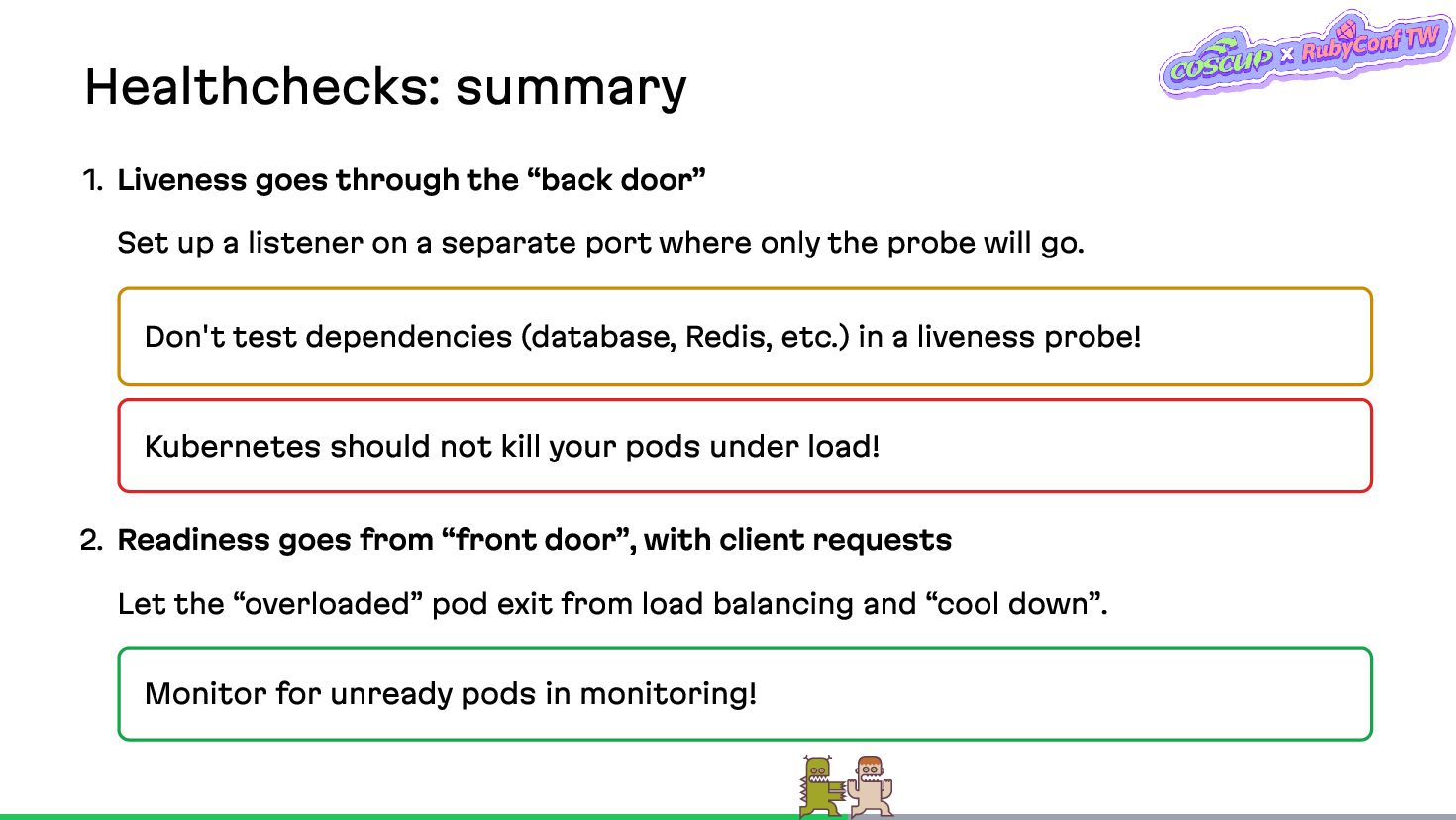{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
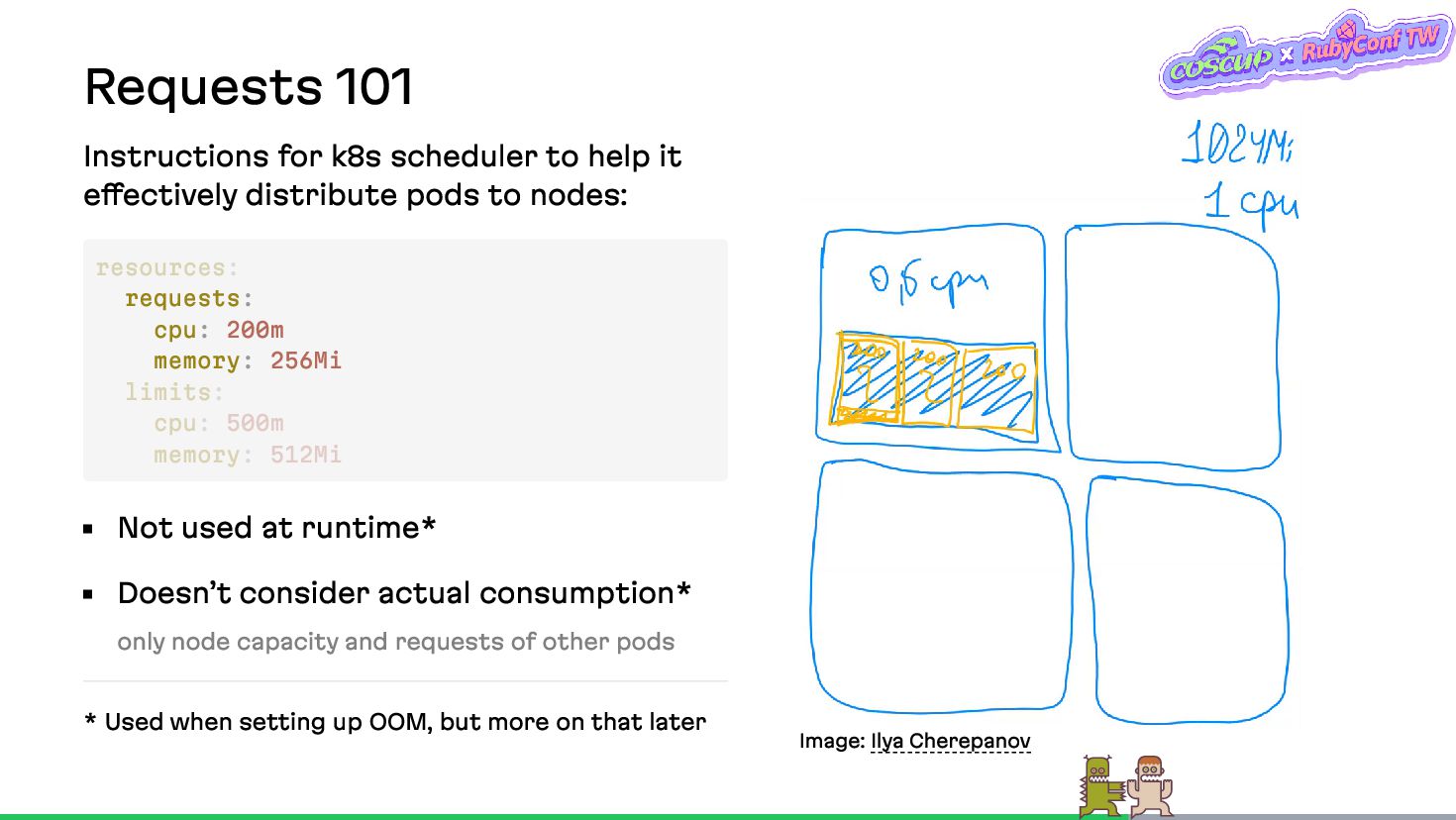{kind=link}
{kind=link}
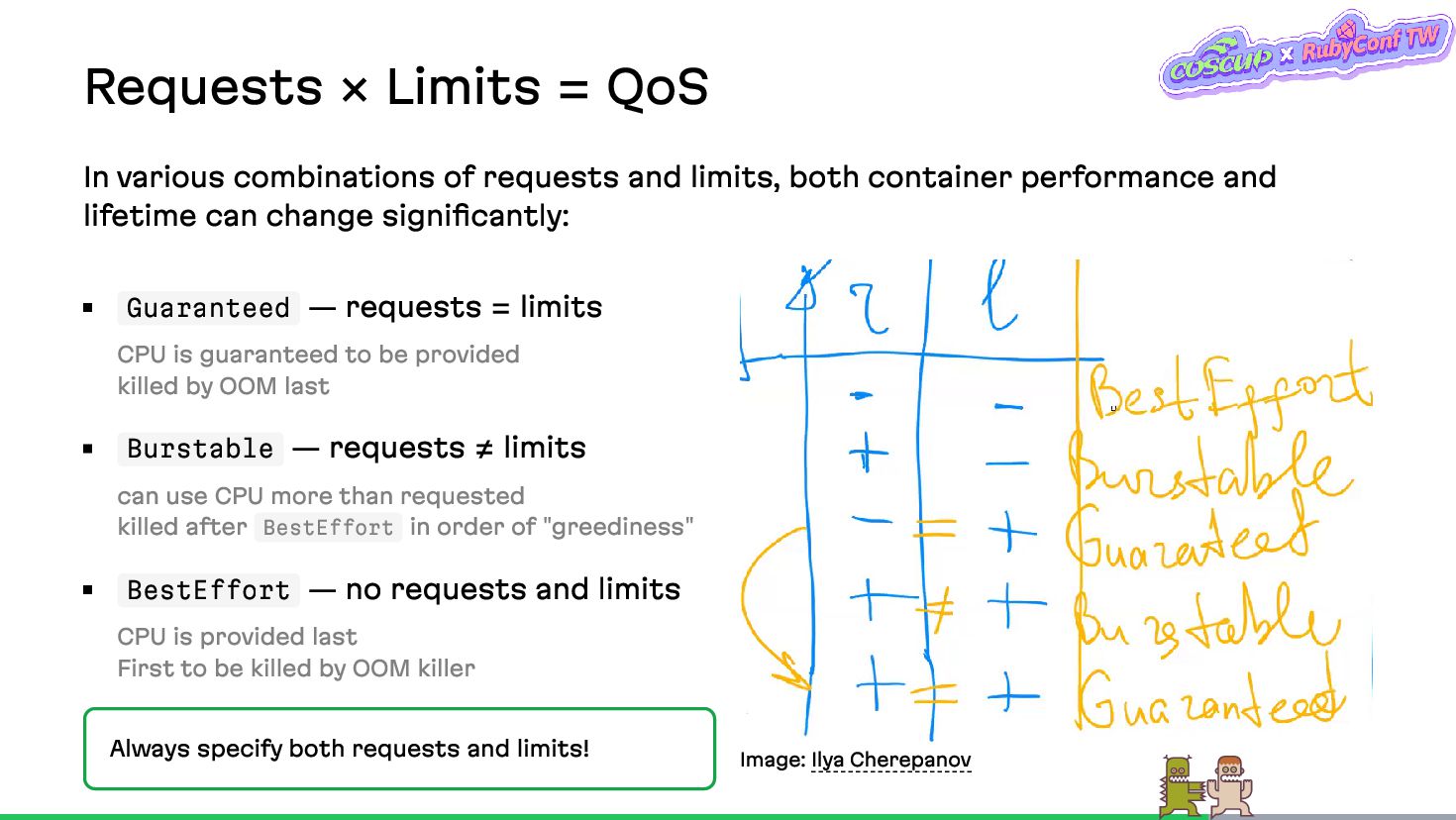{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! @Envek @Envek @[email protected] @envek.bsky.social github.com/Envek @evilmartians @evilmartians @[email protected]](https://files.speakerdeck.com/presentations/6723a77ae98f408cb74b40b70d4564cc/slide_35.jpg){kind=link}