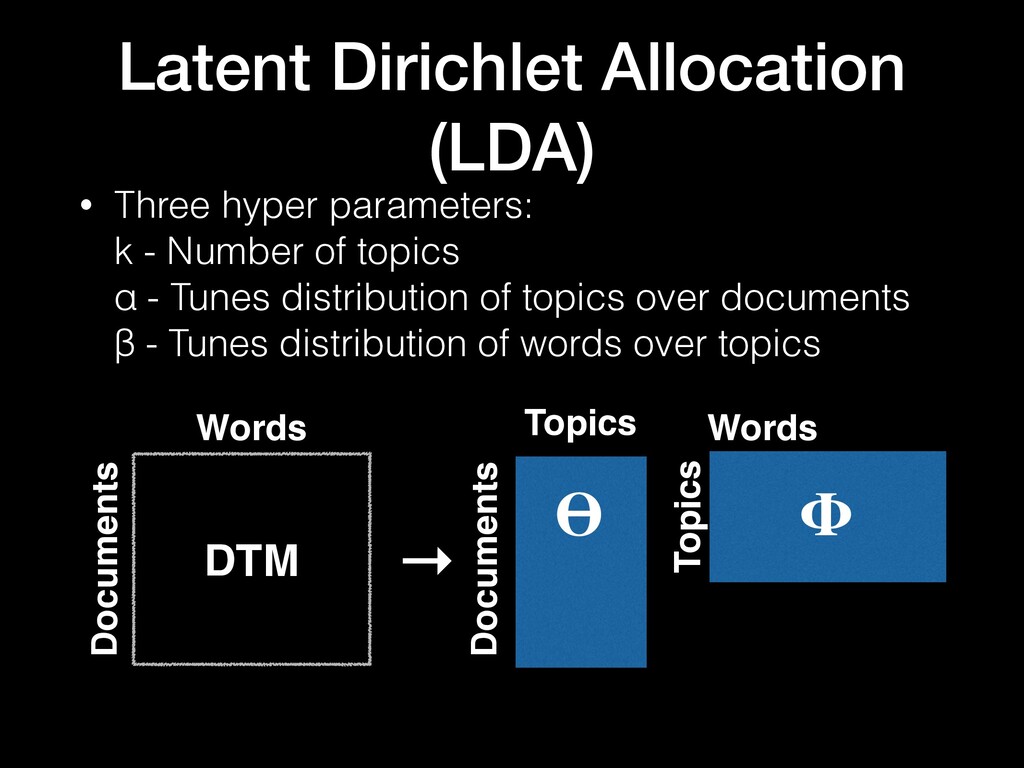
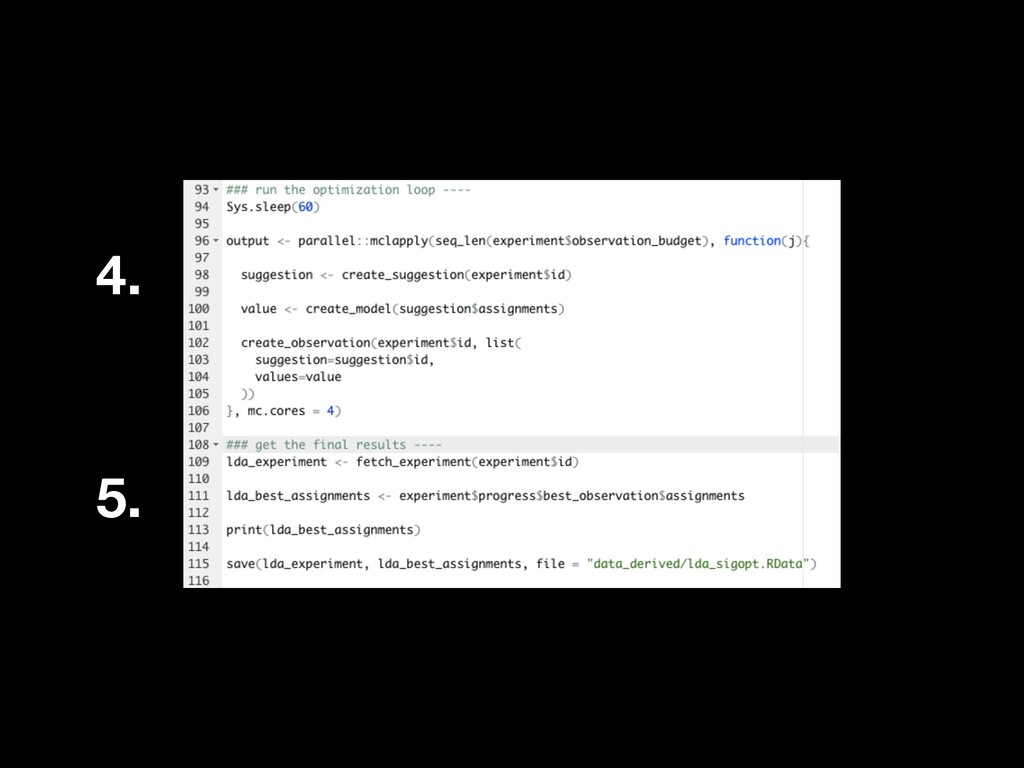
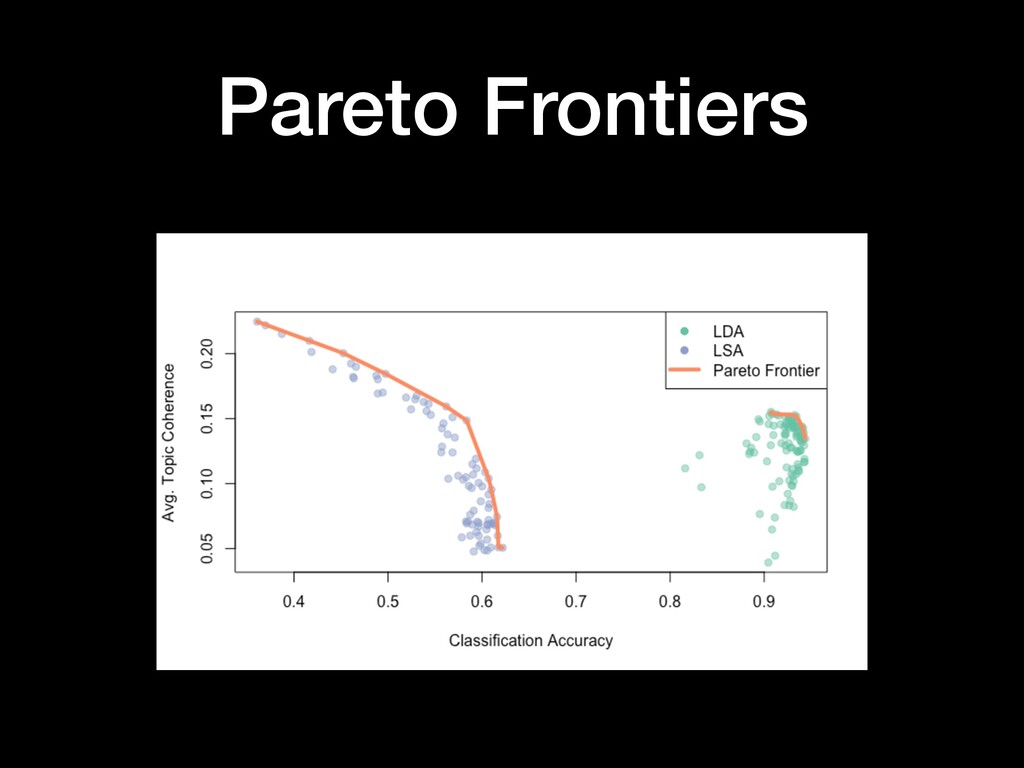
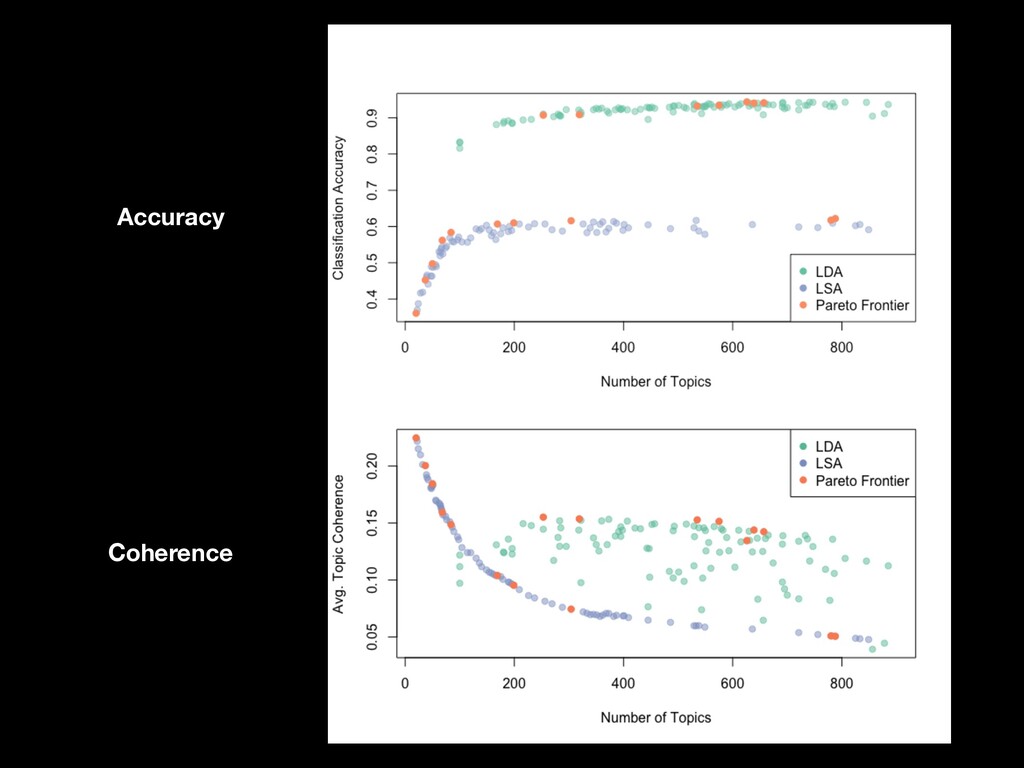
Topic models are hard to evaluate as the variables they measure are latent, i.e. unobserved. Most topic model evaluation has focused on coherence metrics to mimic human judgment or preference. Yet topic models are often not used merely for the pleasure of the human eye. Instead, topic models are often used to support classification tasks, where ground truth exists. In this research, I compare LDA and LSA on how well they support a simple classification task. I use a Bayesian optimization service—SigOpt—to aid choosing the hyperparameters for each model, allowing each to be at its best. I optimize for both coherence of the topic model as well as classification accuracy on held-out data. All code is performed in R using primarily the textmineR, randomForest, and SigOptR packages and available on GitHub.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You • [email protected] • twitter: @thos_jones • http://www.biasedestimates.com •](https://files.speakerdeck.com/presentations/d5be205523924f0286f704d9be269a80/slide_34.jpg){kind=link}