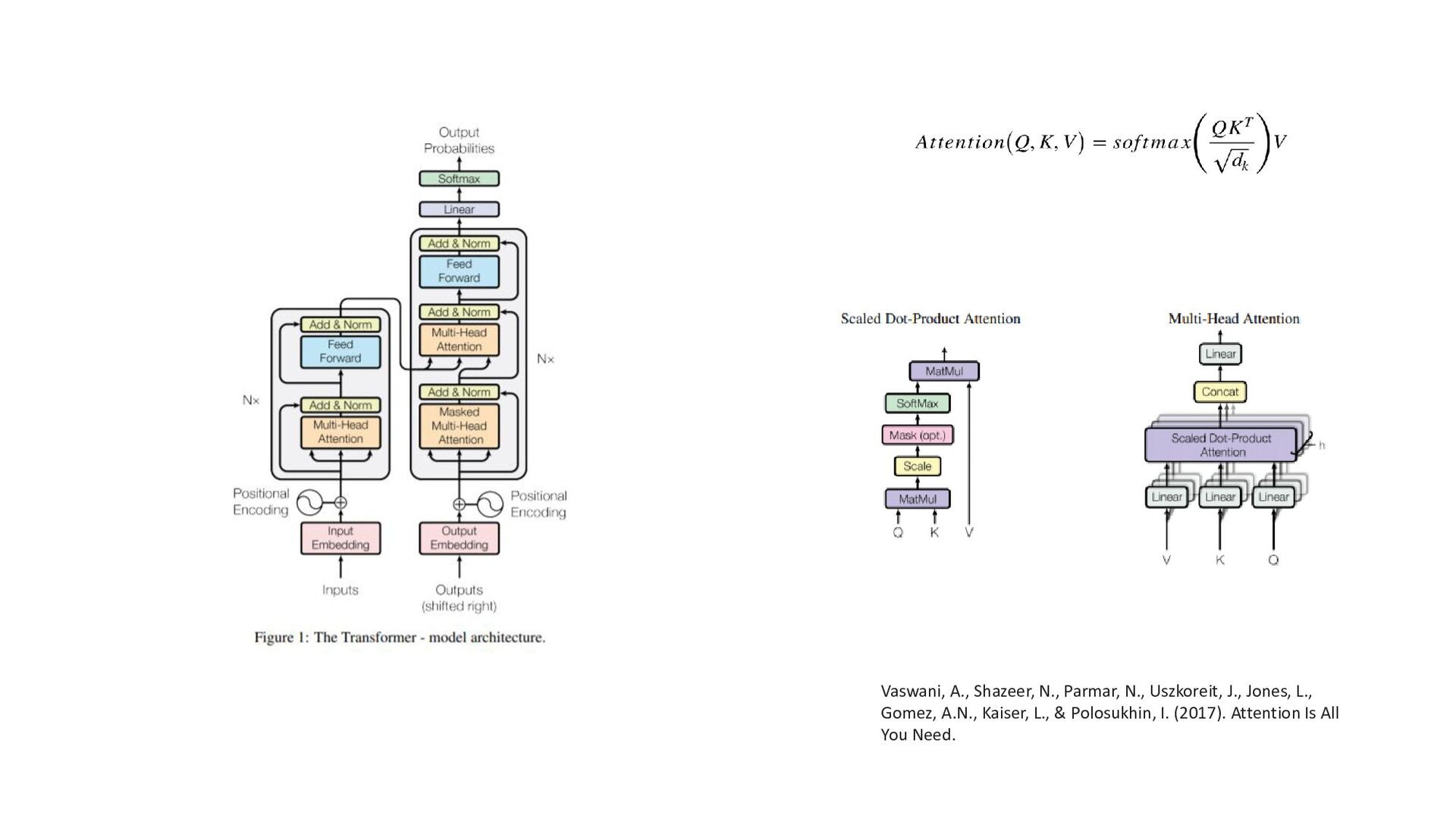
Transfomer Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J. (2020). WiMLDS Paris Paper study sessions 17/12/2020
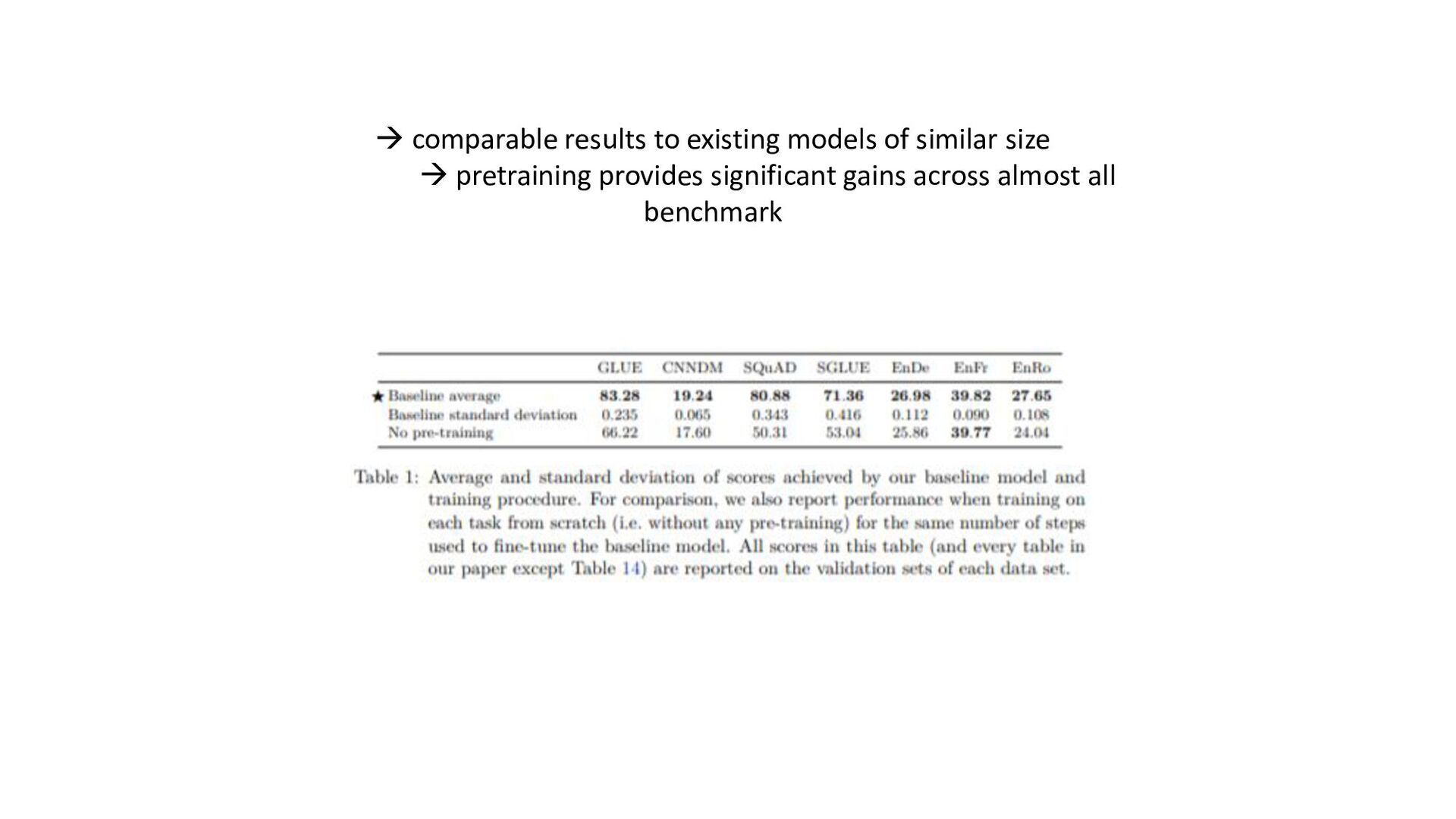
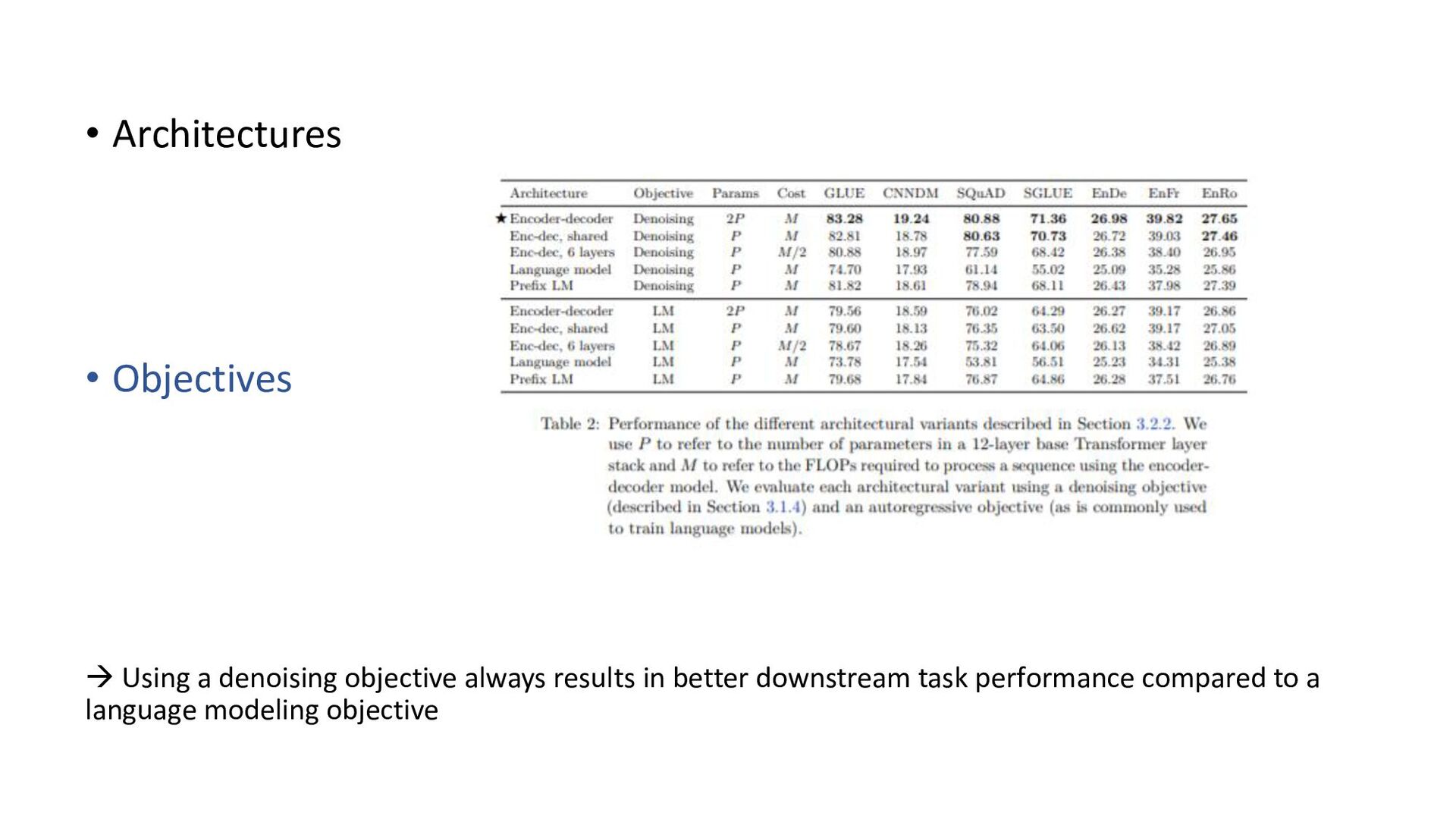
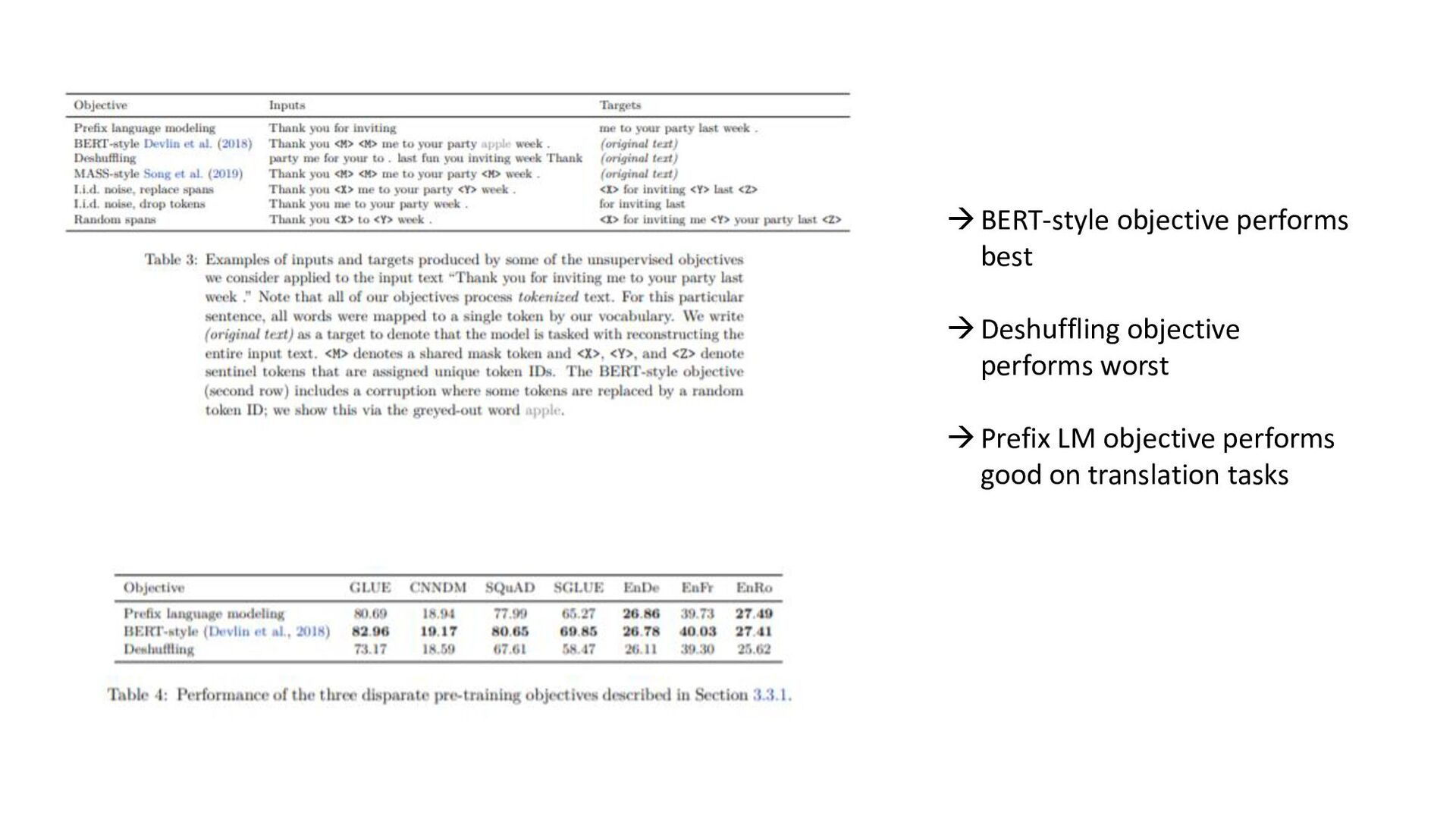
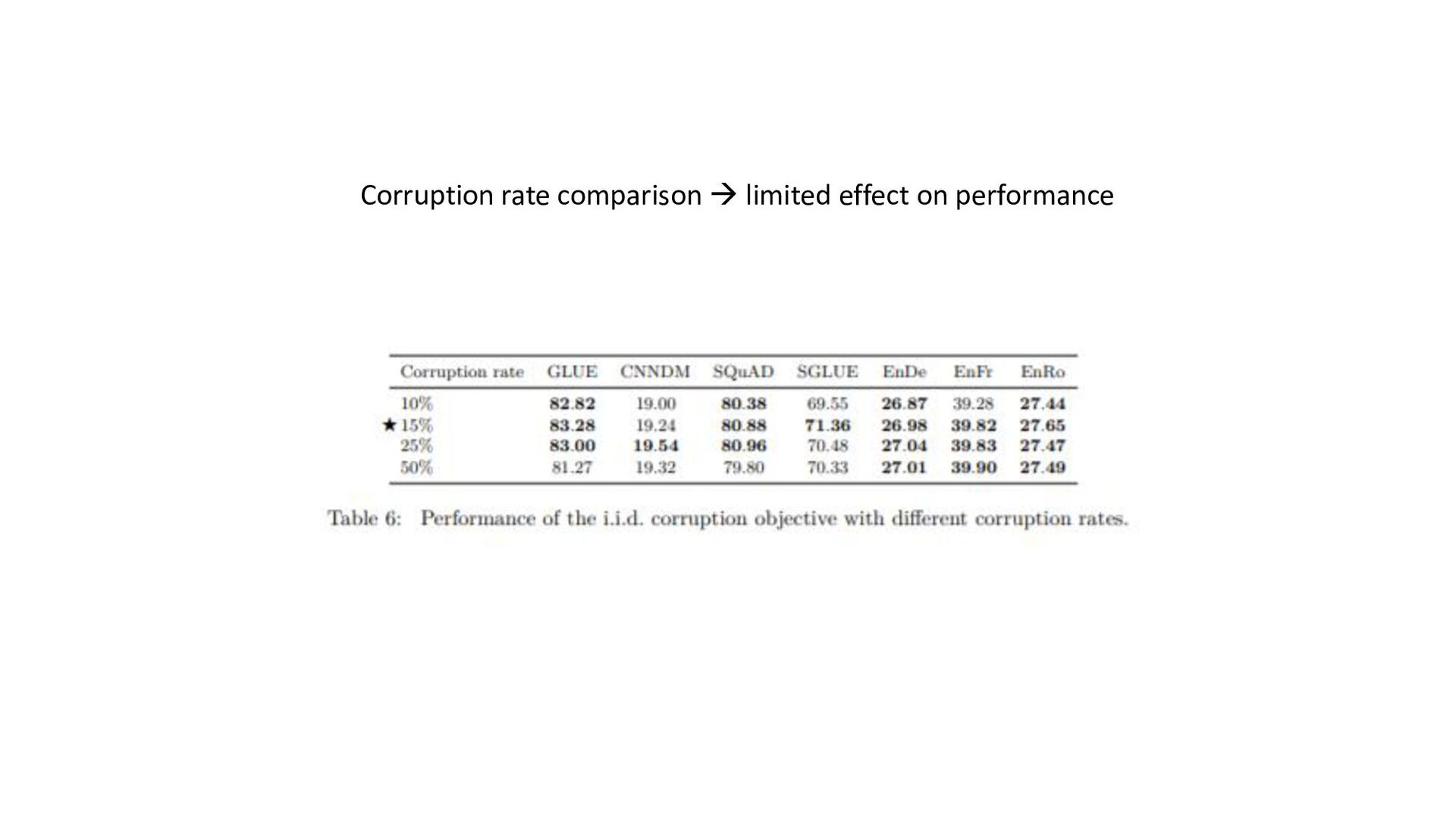
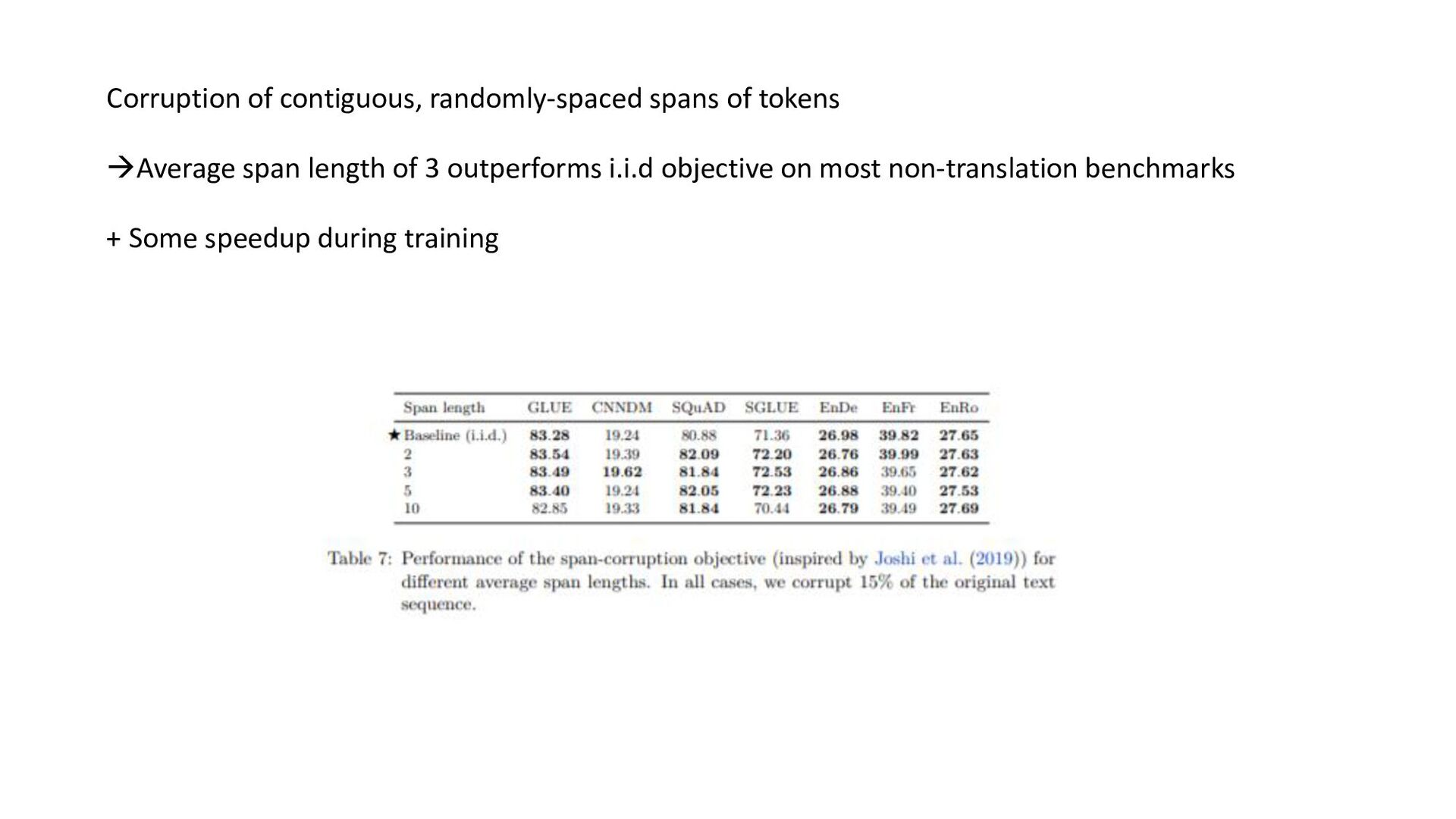
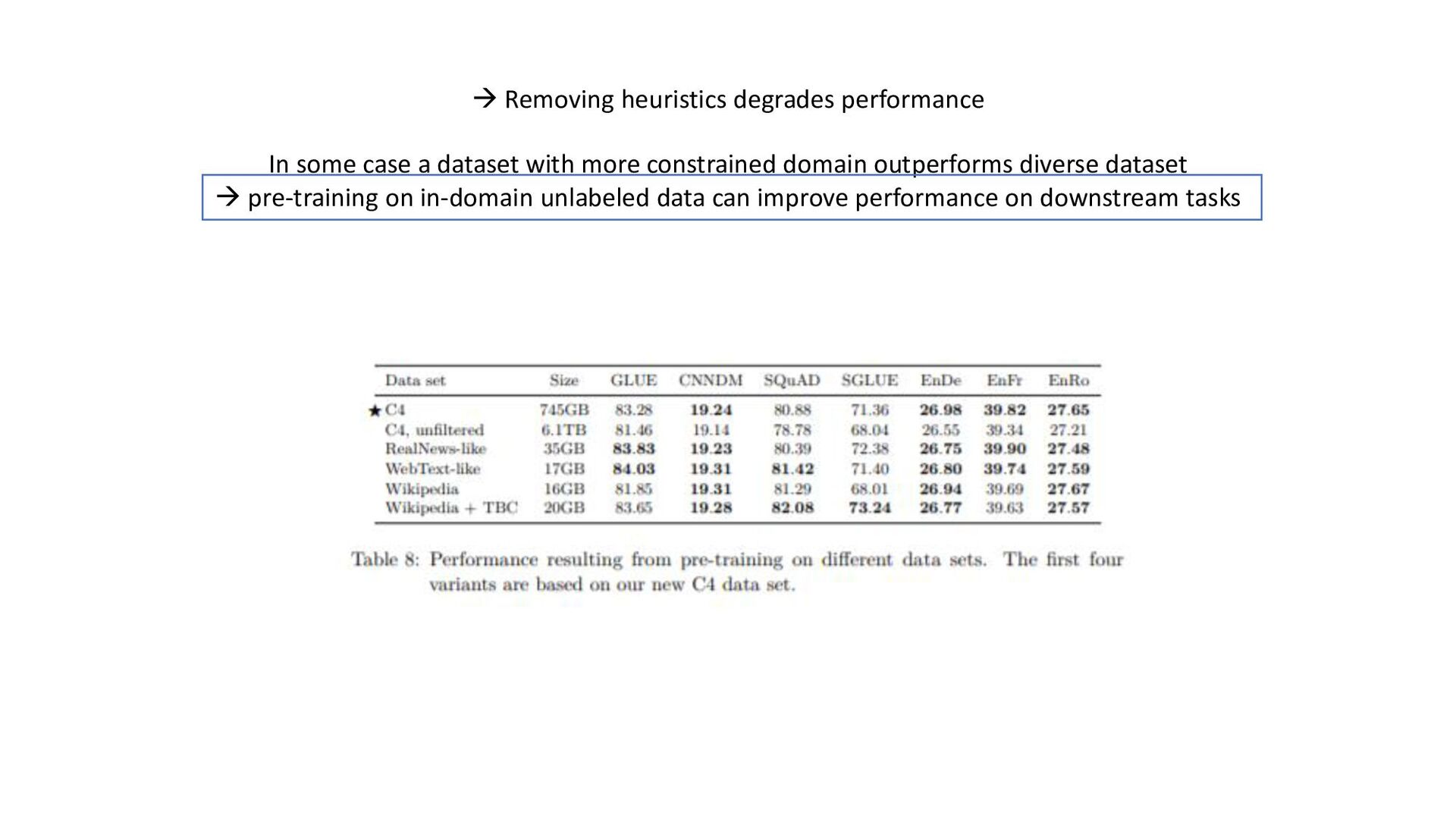
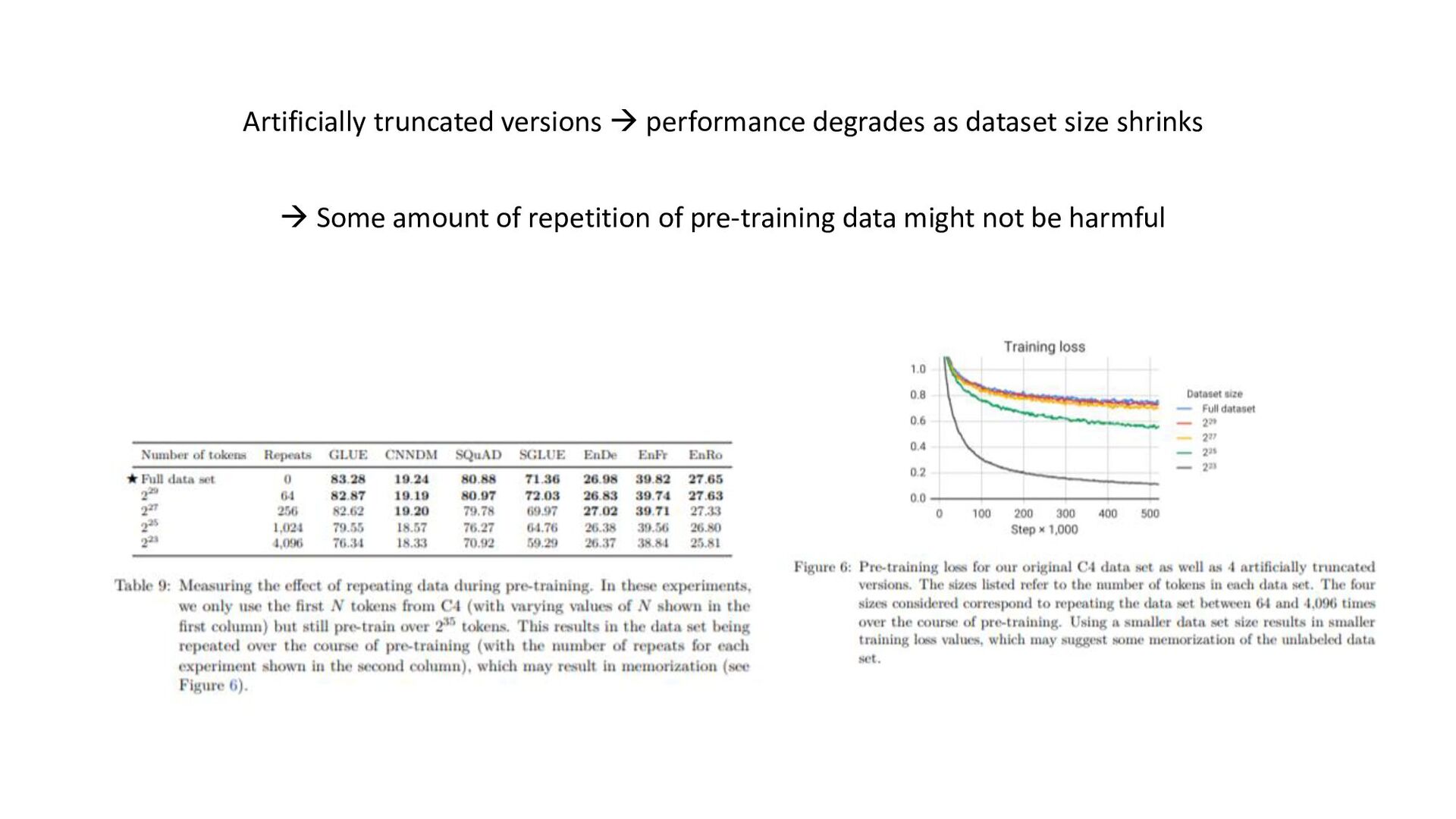
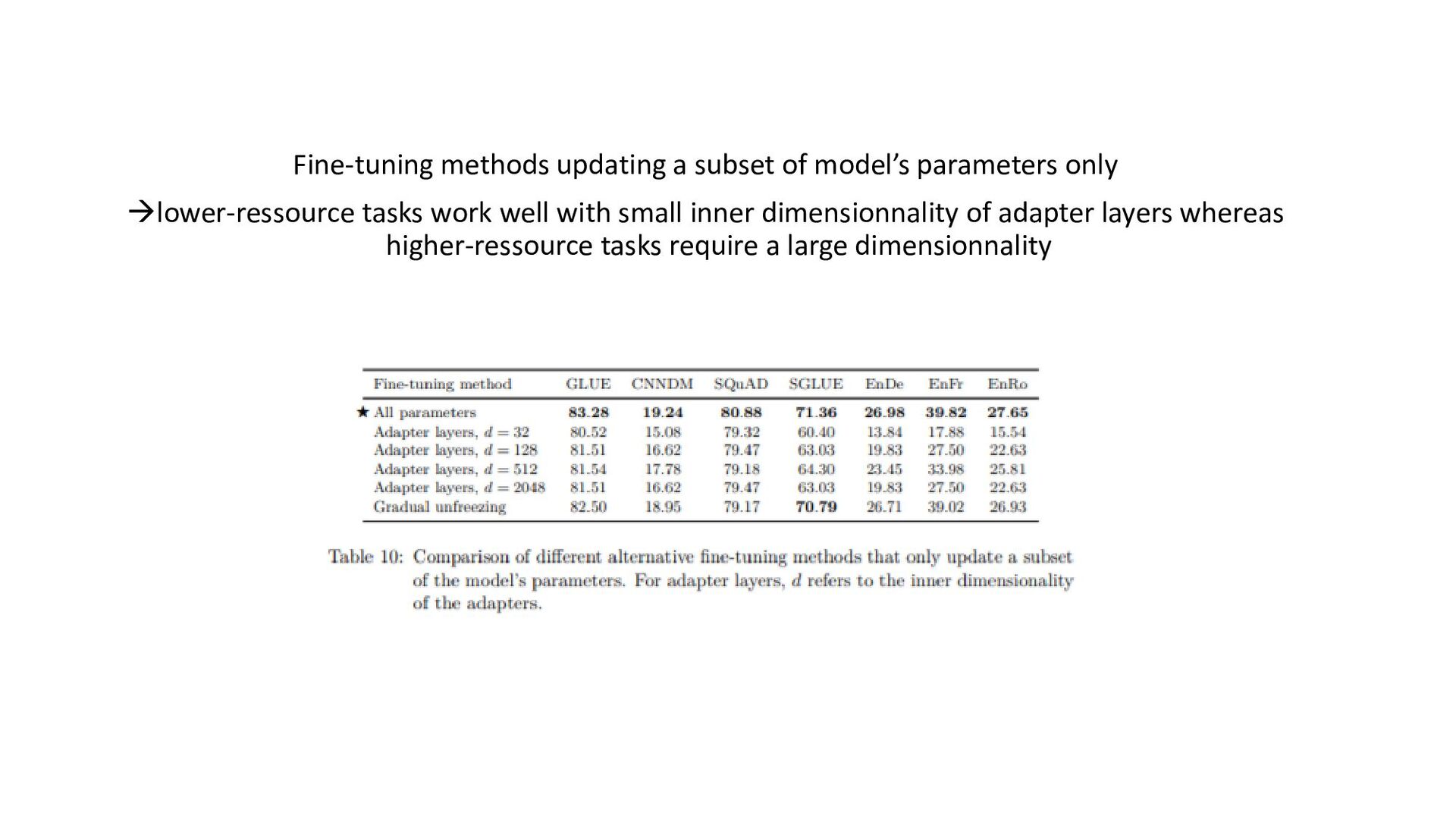
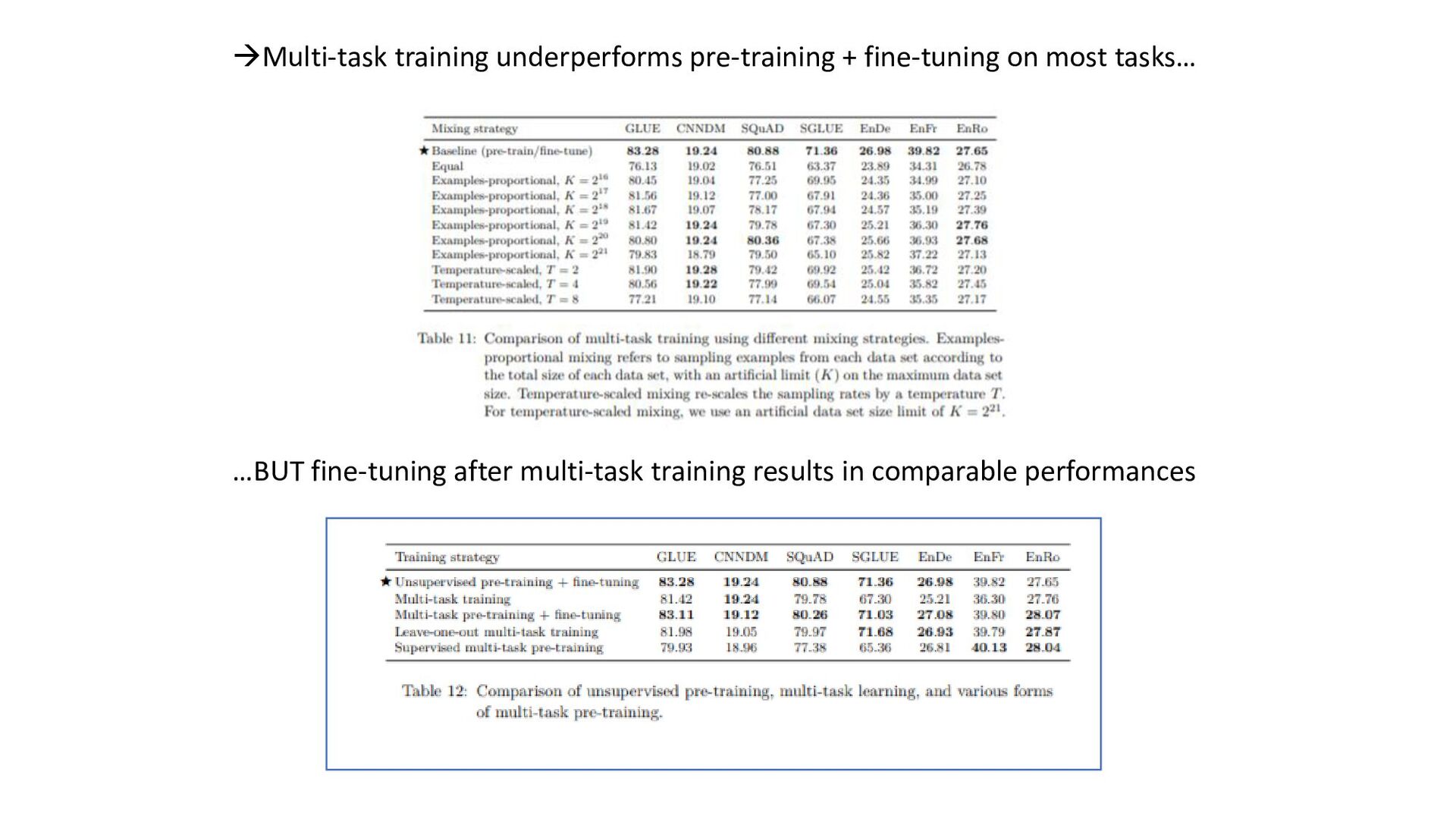
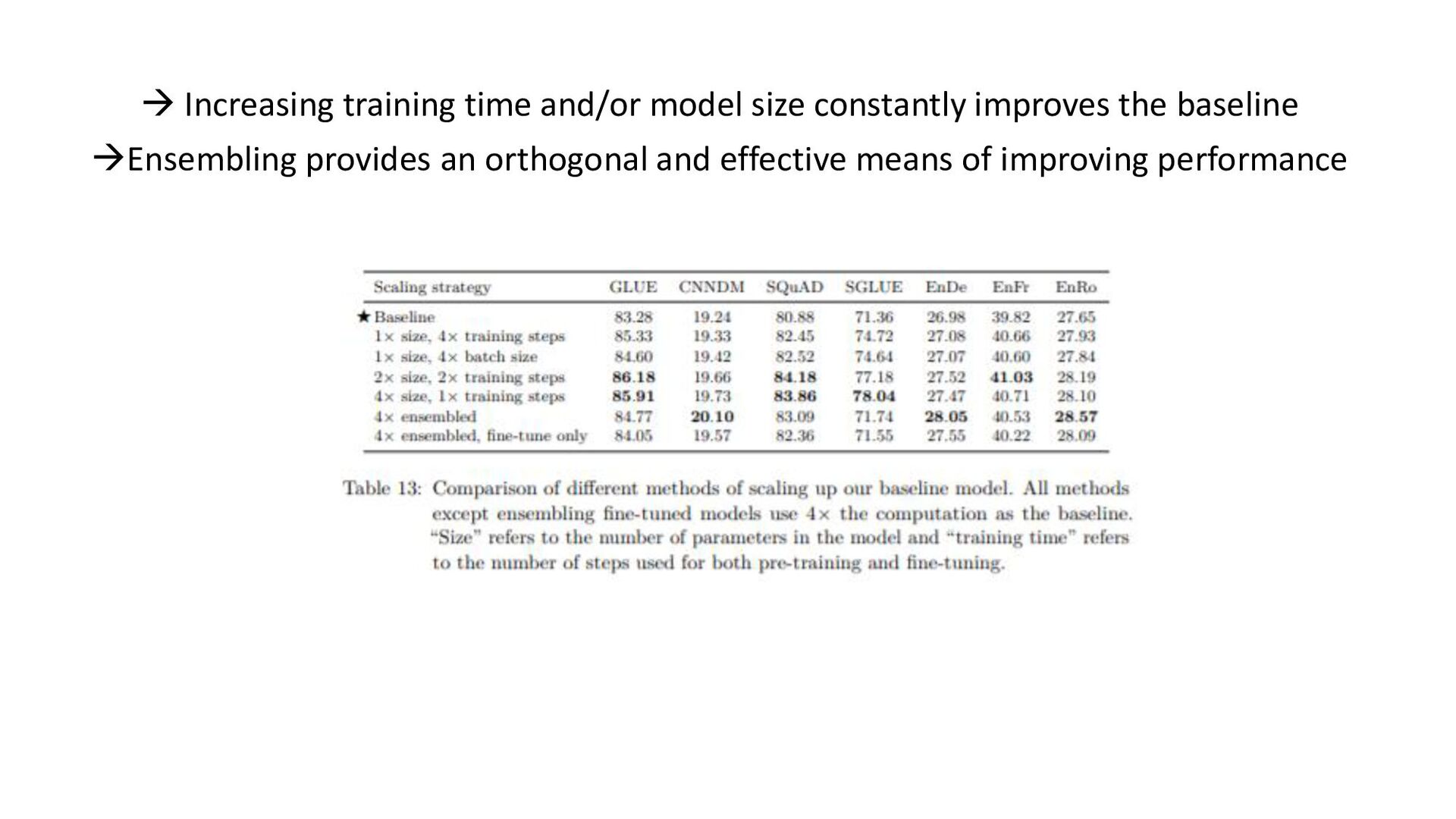
tasks before fine- tuning works as well as pre-training on unsupervised task; model can be trained on wide-variety of text tasks using same loss function and decoding procedure • Repeating data can be detrimental (think big), additionnal pre-training data can be helpful, domain-specific dataset can help for some tasks • Span-corruption objective is more computationally efficient; using objectives producing short target sequences is more computationnaly efficient for pre-training • Encoder-decoder model has similar computationnal cost as encoder or decoder-only; sharing parameters in encoder and decoder didn’t imply performance drop
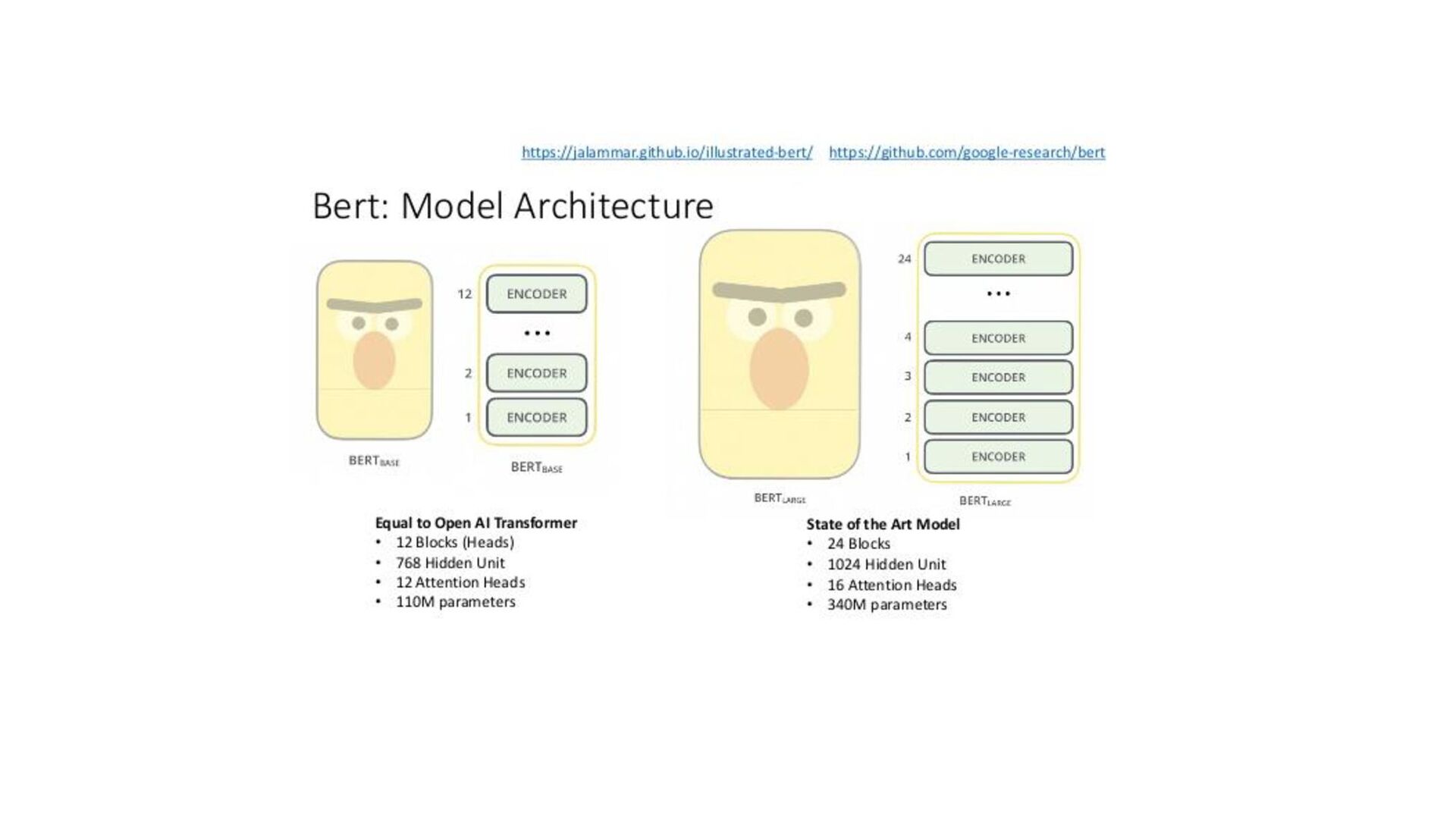
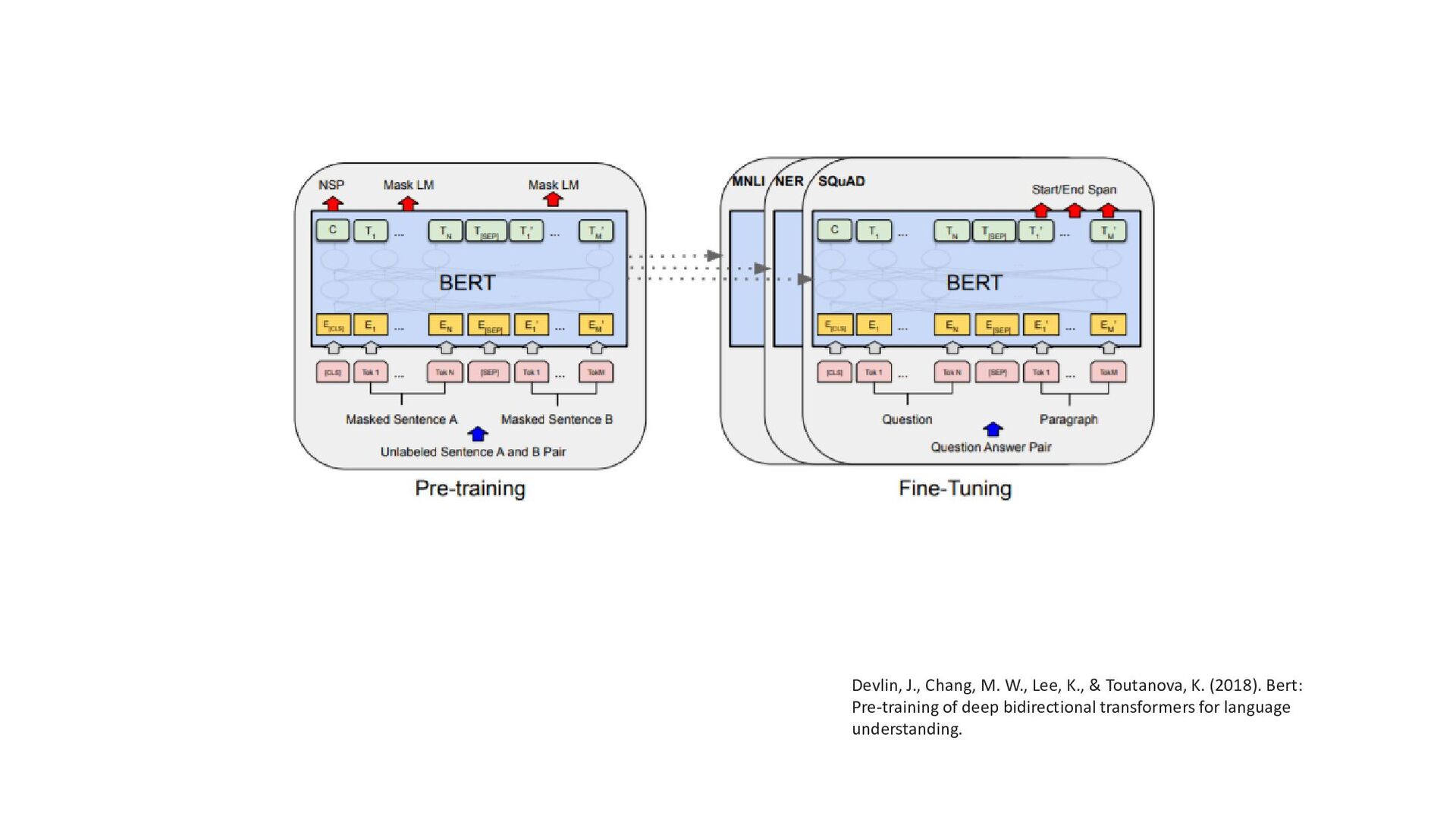
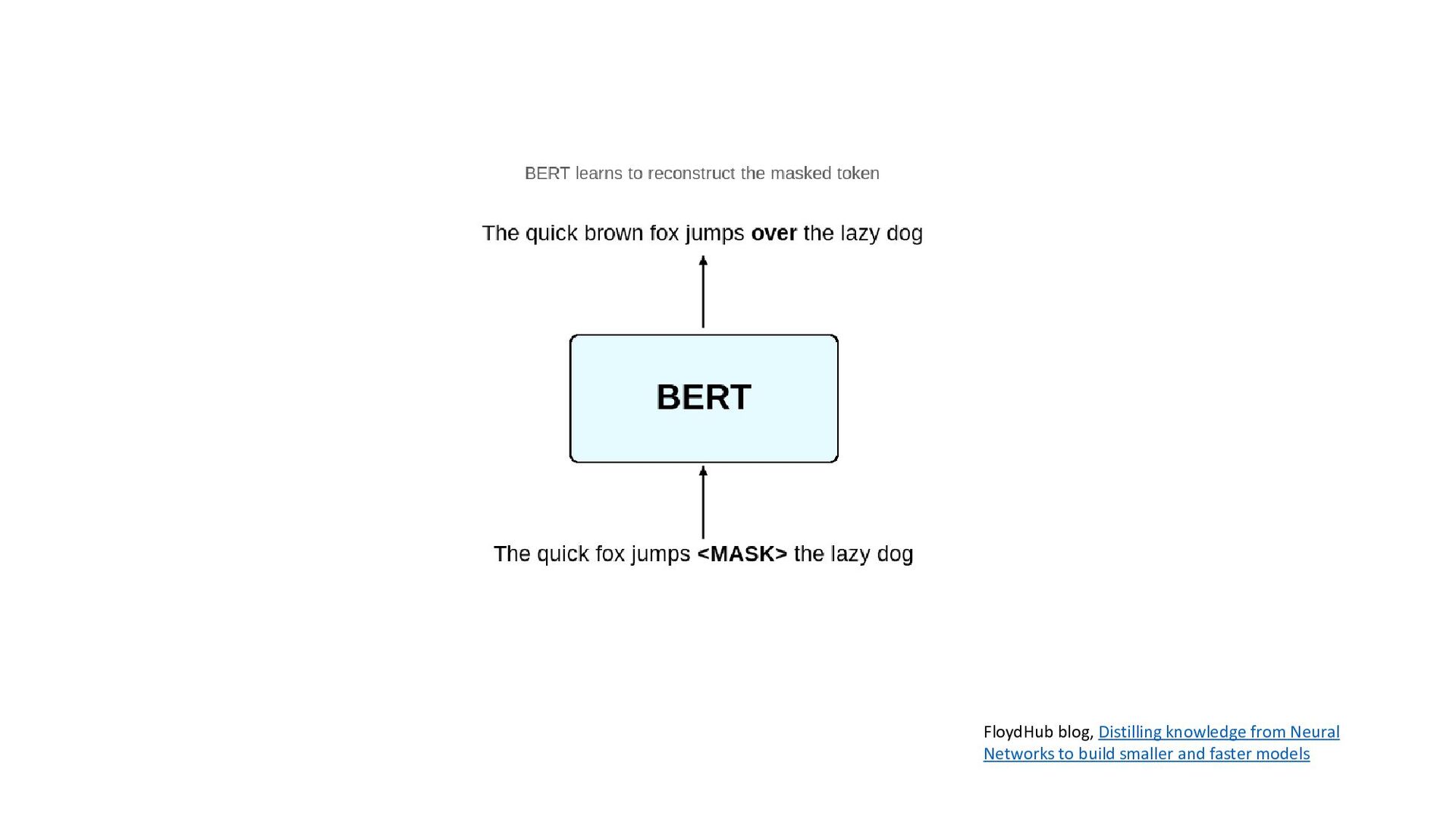
BERT Deconstructing BERT: Distilling 6 Patterns from 100 Million Parameters, Jesse Vig Deconstructing BERT, Part 2: Visualizing the Inner Workings of Attention, Jesse Vig • T5 Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer, Google AI blog
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
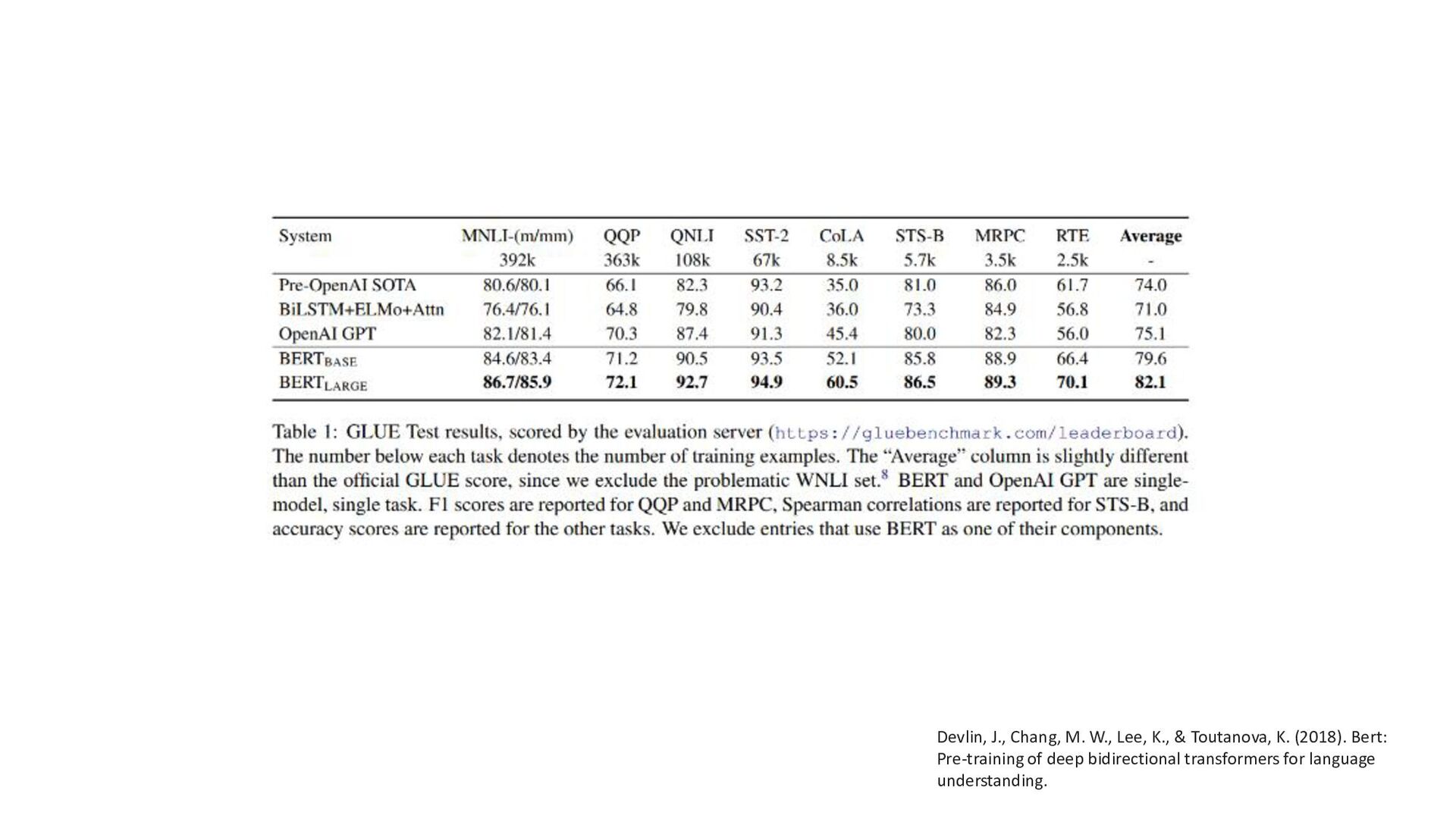{kind=link}
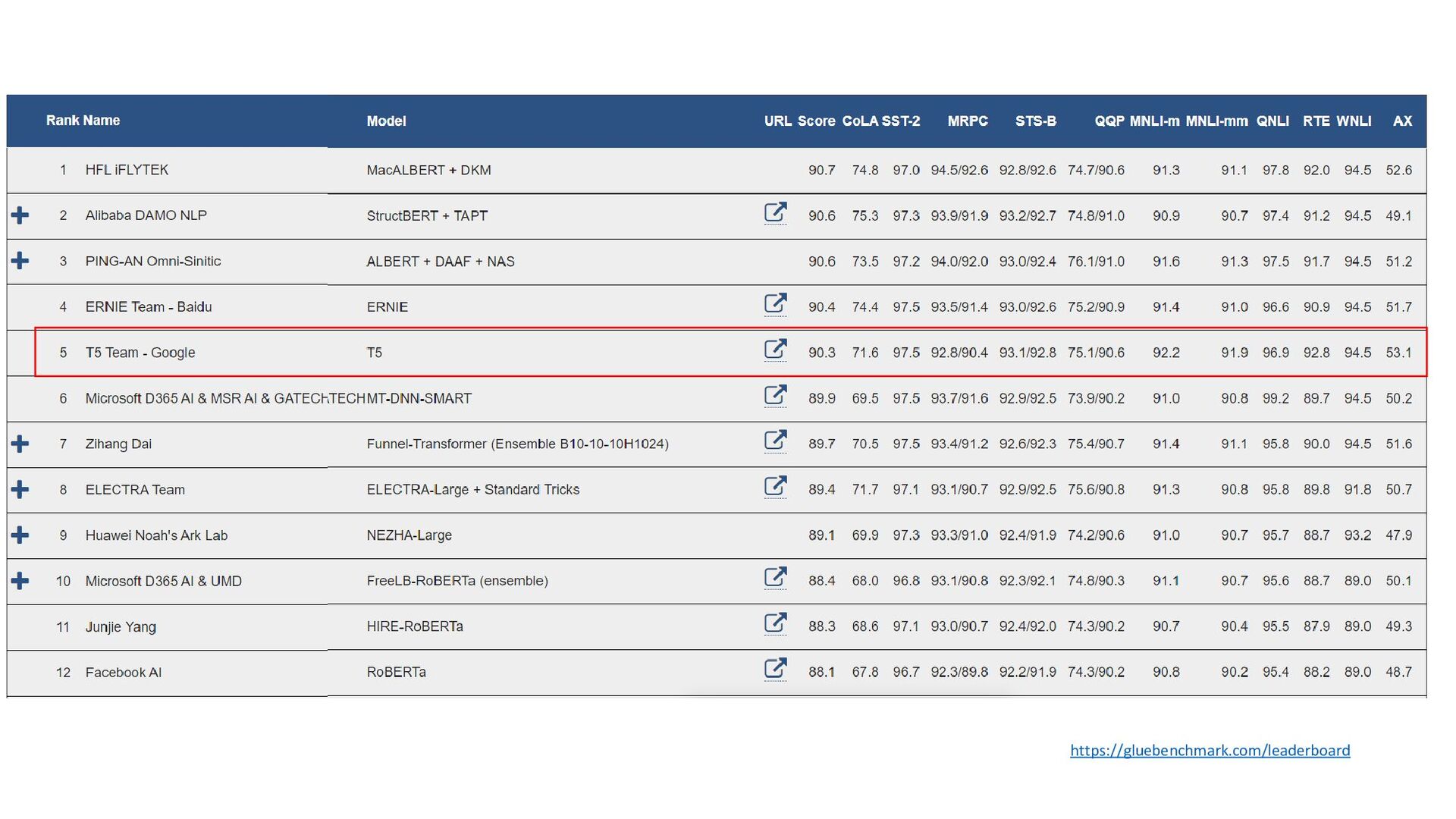{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
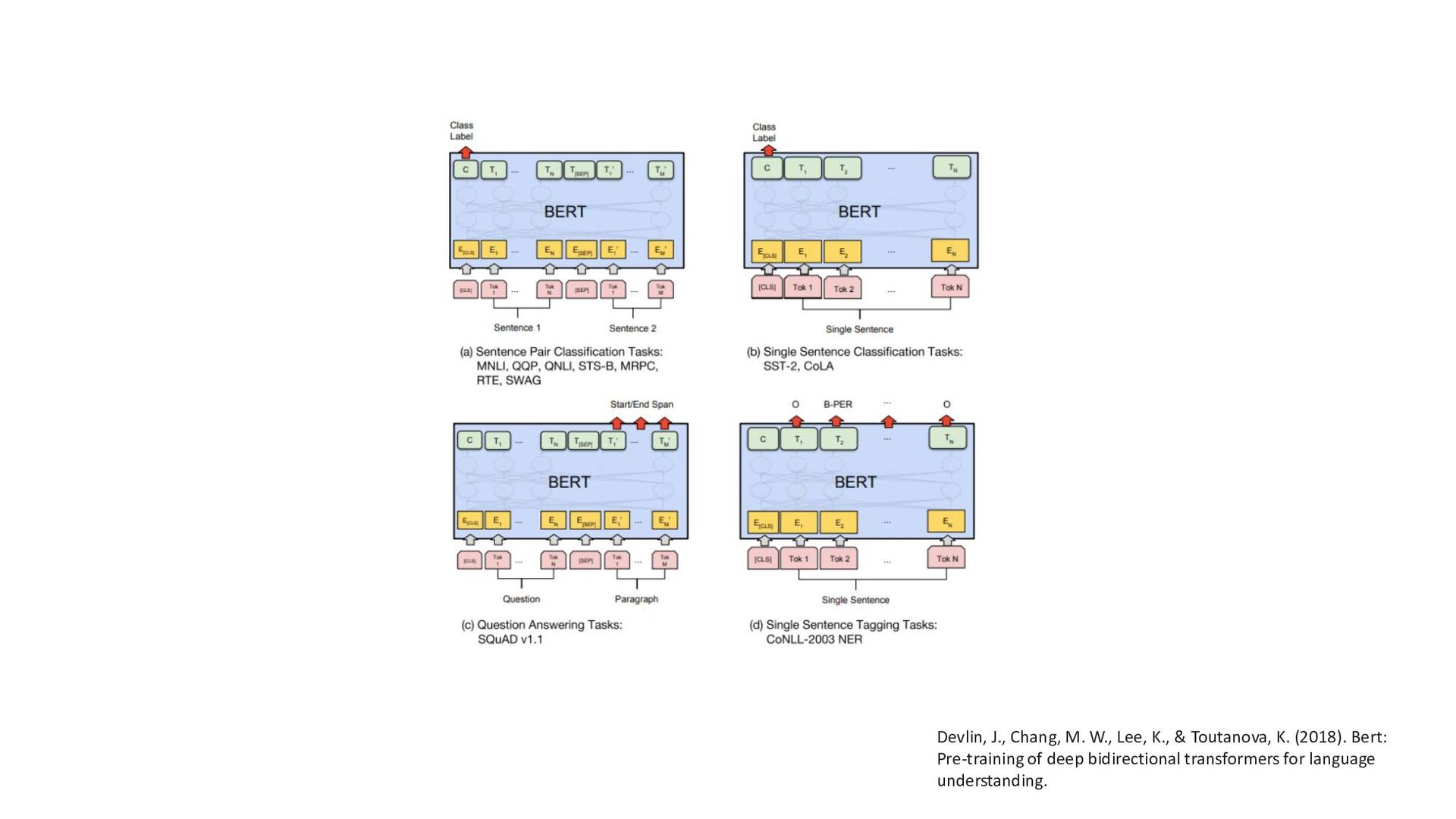{kind=link}
{kind=link}
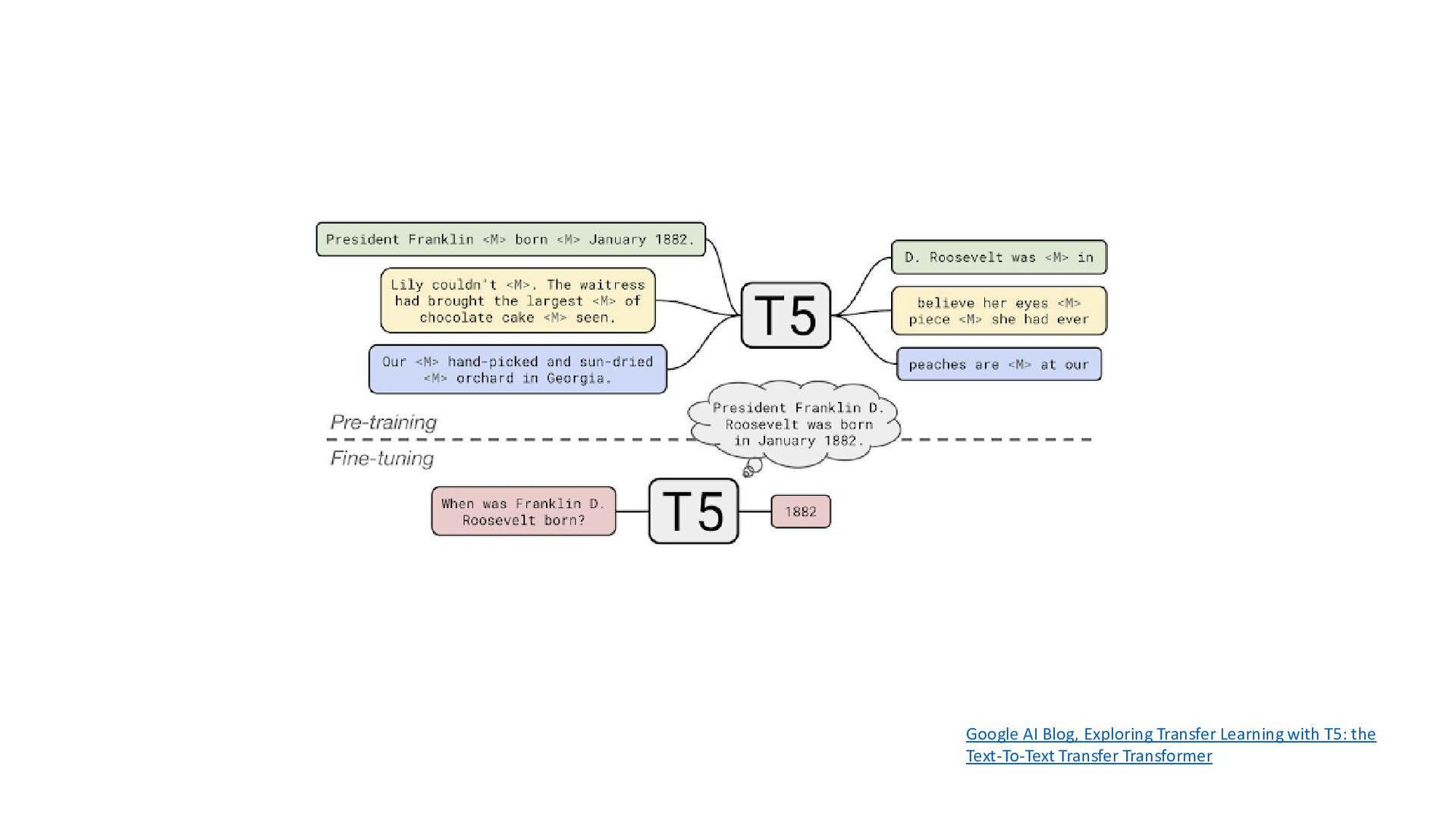{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}