Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[論文紹介] wav2vec 2.0: A Framework for Self-Superv...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
jumon
June 12, 2021
Research
2.3k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[論文紹介] wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
jumon
June 12, 2021
Other Decks in Research
See All in Research
Vector Map as Language: Toward Unified Remote Sensing Vector Mapping
satai
3
120
SLAMはどこまで解決されたのか?
tomonom
0
880
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
170
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
4.5k
オーストリア流 都市の公共交通サービス水準評価@公共交通オープンデータ最前線2026
trafficbrain
0
210
業界横断 副業コンプライアンス調査 三者(副業者・本業先・発注者)におけるトラブル認知ギャップの構造分析
fkske
0
1.3k
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
170
Sleuthcon Keynote - How Cybercriminals (ab)use AI
fr0gger
0
260
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.3k
某助成金プロジェクト採択に向けて企業研究所のアウトリーチ専任者がやったこと
afroscript
0
120
GLIM とMegaParticles:正規分布近似の限界とタイトカップリング&パーティクルフィルタの進展 / GLIM and MegaParticles : Progress of the distribution representation in SLAM
koide3
0
620
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
350
Featured
See All Featured
My Coaching Mixtape
mlcsv
0
180
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
200
Discover your Explorer Soul
emna__ayadi
2
1.2k
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
660
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Mobile First: as difficult as doing things right
swwweet
225
10k
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Automating Front-end Workflow
addyosmani
1370
210k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
420
Docker and Python
trallard
47
4k
Transcript
1 野崎 樹⽂(Jumon Nozaki) 2021 年 6 ⽉ 9 ⽇
研究室輪講 wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations [Baevski et al. NeurIPS2020] 京都⼤学 ⾳声メディア研究室 修⼠⼀回⽣
研究概要 • ⾳声データに対する新たな⾃⼰教師あり学習の枠組みである wav2vec 2.0 を提案 • ⾃⼰教師あり学習を⾏った wav2vec 2.0
をラベル付きデータで ファインチューニングすることで⾼い⾳声認識精度を達成 • Librispeech コーパスのわずか 10 分の教師データで学習し, 単語誤り率 4.8% の認識精度 2
研究背景 • 学習データを減らしたい • ディープラーニングの学習には⼤量のデータが必要 • 世界の多くの⾔語では学習に⼗分な量のデータの確保は困難 Ø ラベルなしデータから汎⽤的な表現を学習する⾃⼰教師あり学習へ •
⾃⼰教師あり学習の興隆 q ⾃然⾔語処理 • BERT [Delvin+, 2018], GPT-2 [Radford+, 2018] q コンピュータビジョン [Henfaff+, 2019] q ⾳声 • wav2vec [Schneider+, 2019], vq-wav2vec [Baevski+, 2020] Ø よりよい⾃⼰教師あり学習へ 3
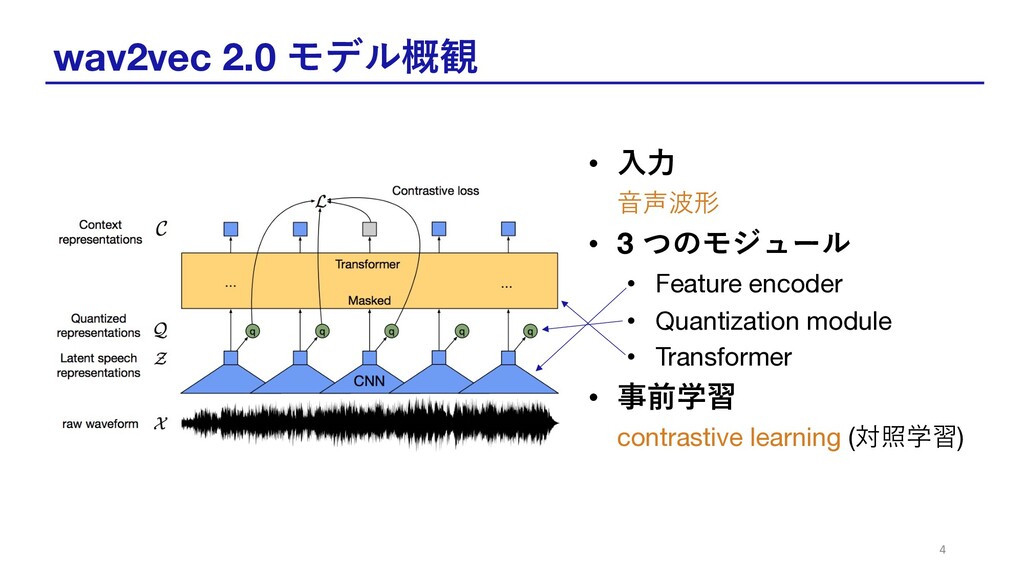
wav2vec 2.0 モデル概観 • ⼊⼒ ⾳声波形 • 3 つのモジュール •
Feature encoder • Quantization module • Transformer • 事前学習 contrastive learning (対照学習) 4
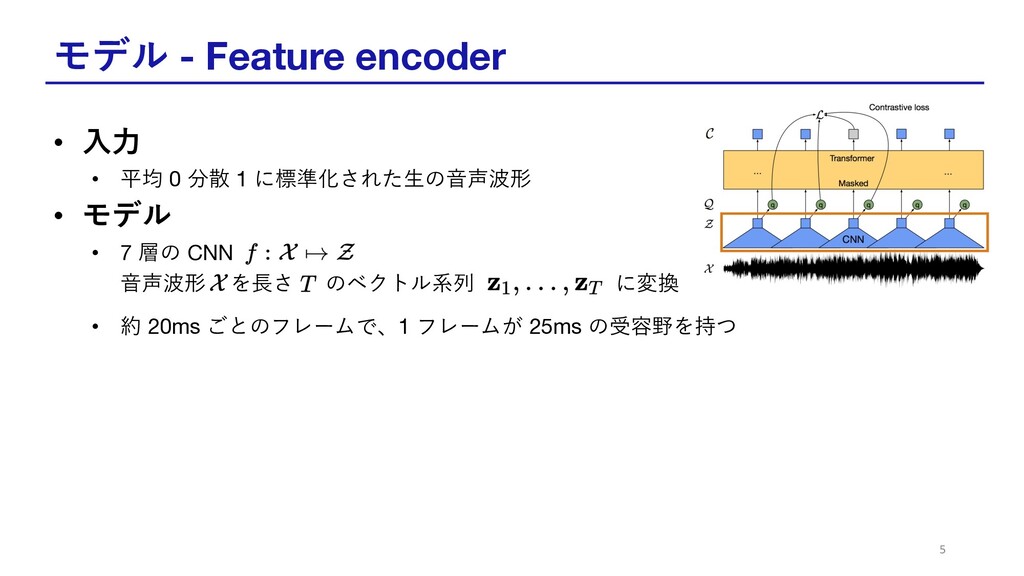
モデル - Feature encoder • ⼊⼒ • 平均 0 分散
1 に標準化された⽣の⾳声波形 • モデル • 7 層の CNN ⾳声波形 を⻑さ のベクトル系列 に変換 • 約 20ms ごとのフレームで、1 フレームが 25ms の受容野を持つ 5
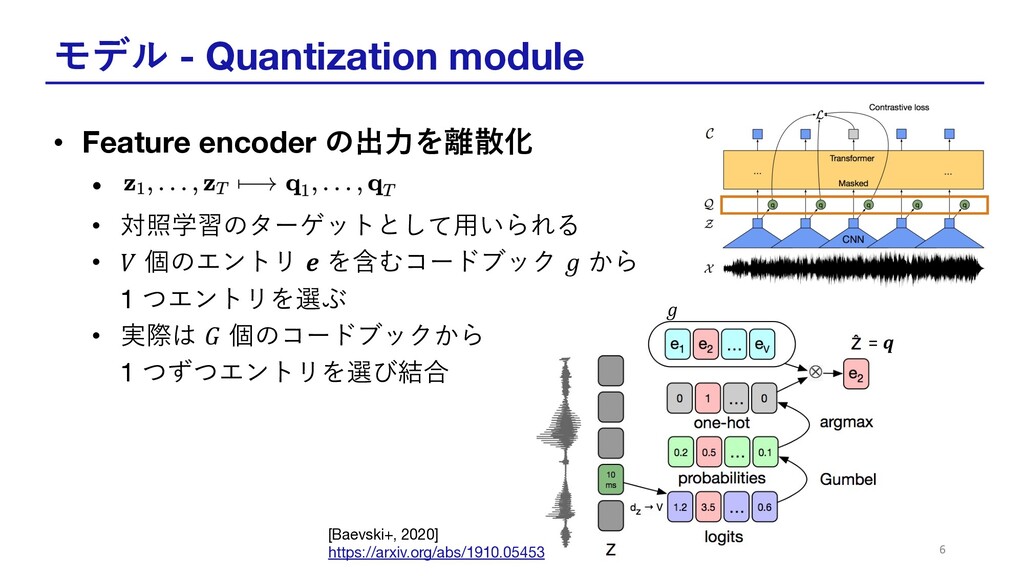
モデル - Quantization module • Feature encoder の出⼒を離散化 • •
対照学習のターゲットとして⽤いられる • 𝑉 個のエントリ 𝒆 を含むコードブック 𝑔 から 1 つエントリを選ぶ • 実際は 𝐺 個のコードブックから 1 つずつエントリを選び結合 6 = 𝒒 𝑔 [Baevski+, 2020] https://arxiv.org/abs/1910.05453
モデル - Quantization module – Gumbel-Softmax • Gumbel-Softmax [Jang+, 2016]
の使⽤ • 微分可能な形でコードブックからのサンプリングを⾏う • Feature encoder の出⼒ 𝑧 を線形層で に変換(𝑉: エントリ数) • 学習時はエントリ 𝑗 を選ぶ確率 を以下の様に求める • : (0, 1) の⼀様分布からのサンプル • : softmax 温度, ハイパーパラメータ • forward 時は の argmax をとる backward 時は で勾配を近似 ( : one-hot vector) = straight-through estimator 7 = 𝒒 𝑔 [Baevski+, 2020] https://arxiv.org/abs/1910.05453 ,
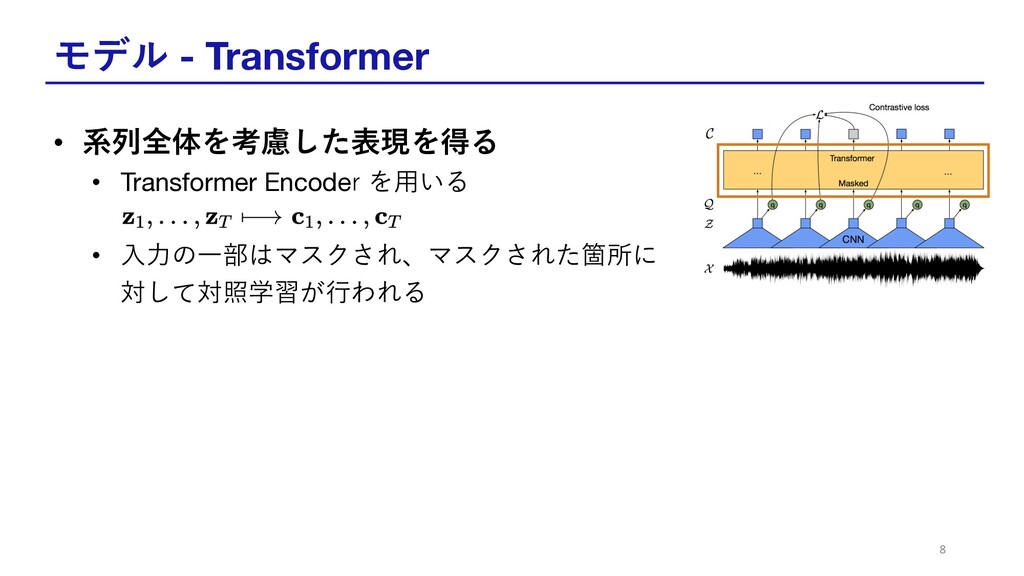
モデル - Transformer • 系列全体を考慮した表現を得る • Transformer Encoder を⽤いる •
⼊⼒の⼀部はマスクされ、マスクされた箇所に 対して対照学習が⾏われる 8
学習 - pre-training • ⽬的関数 : Contrastive Loss : Diversity
Loss : ハイパーパラメータ 9
学習 - pre-training – Contrastive Loss • 対照学習 • マスクされた箇所の出⼒
を Ø 対応する (= 正例)に近づける Ø 同発話の他の箇所からサンプリングされた 𝐾 個の (= 負例)から遠ざける 10 : コサイン類似度 : 正例と 𝐾 個の負例の集合 : softmax の温度 (ハイパーパラメータ)
学習 - pre-training – Diversity Loss • Diversity Loss •
コードブックのエントリの⼀部しか 使⽤されないことを避ける • コードブック 𝑔 の 𝑉 個のエントリが同様に 使われるように Ø エントリが選ばれる確率分布のエントロピーを最⼤化 11 : コードブック 𝑔 のエントリ 𝑣 が選ばれる確率のバッチ内平均 𝐺 : コードブックの数
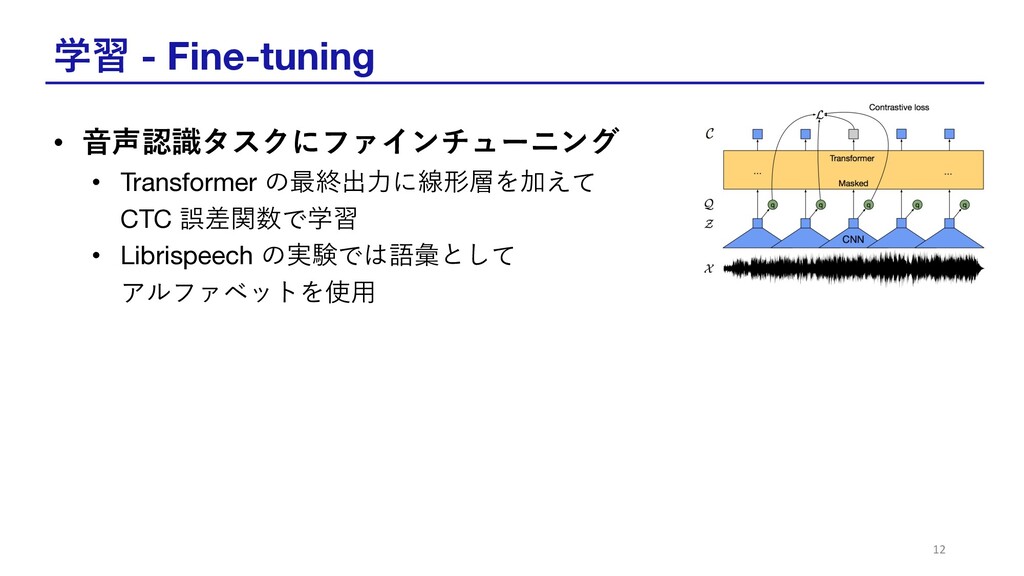
学習 - Fine-tuning • ⾳声認識タスクにファインチューニング • Transformer の最終出⼒に線形層を加えて CTC 誤差関数で学習
• Librispeech の実験では語彙として アルファベットを使⽤ 12
実験 – データセット • 事前学習 • ⾳声のみを使⽤(ラベルは使わない) • データ量の異なる 2
パターンの設定 • Librispeech (960 時間) • LisbriVox (約 60,000 時間) • ファインチューニング • ⾳声とラベルを使⽤ • データ量の異なる 5 パターンの Librispeech サブセット • 960 時間, 100 時間, 10 時間, 1 時間, 10 分 13
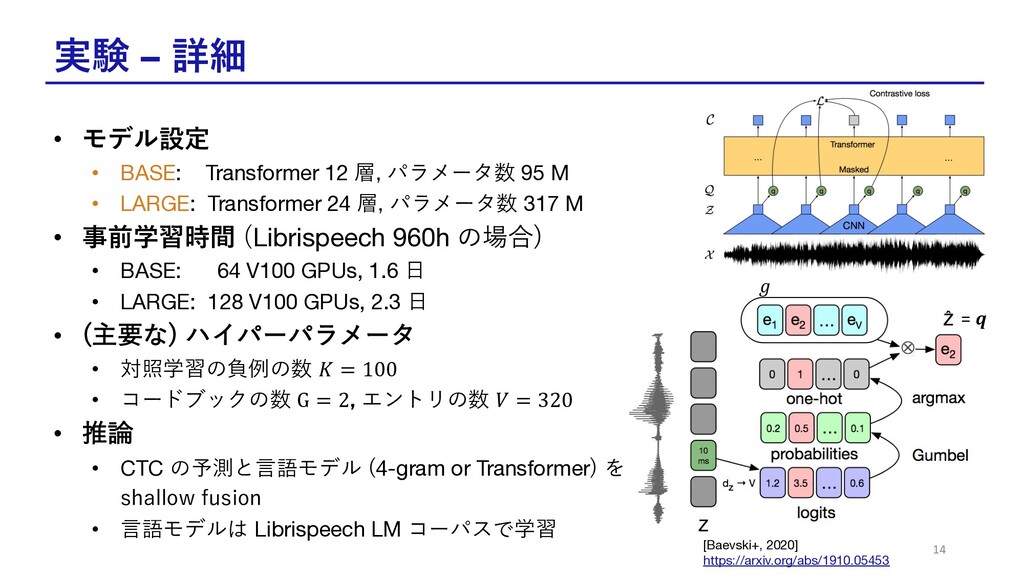
実験 – 詳細 • モデル設定 • BASE: Transformer 12 層,
パラメータ数 95 M • LARGE: Transformer 24 層, パラメータ数 317 M • 事前学習時間 (Librispeech 960h の場合) • BASE: 64 V100 GPUs, 1.6 ⽇ • LARGE: 128 V100 GPUs, 2.3 ⽇ • (主要な) ハイパーパラメータ • 対照学習の負例の数 𝐾 = 100 • コードブックの数 G = 2, エントリの数 𝑉 = 320 • 推論 • CTC の予測と⾔語モデル (4-gram or Transformer) を shallow fusion • ⾔語モデルは Librispeech LM コーパスで学習 14 = 𝒒 𝑔 [Baevski+, 2020] https://arxiv.org/abs/1910.05453
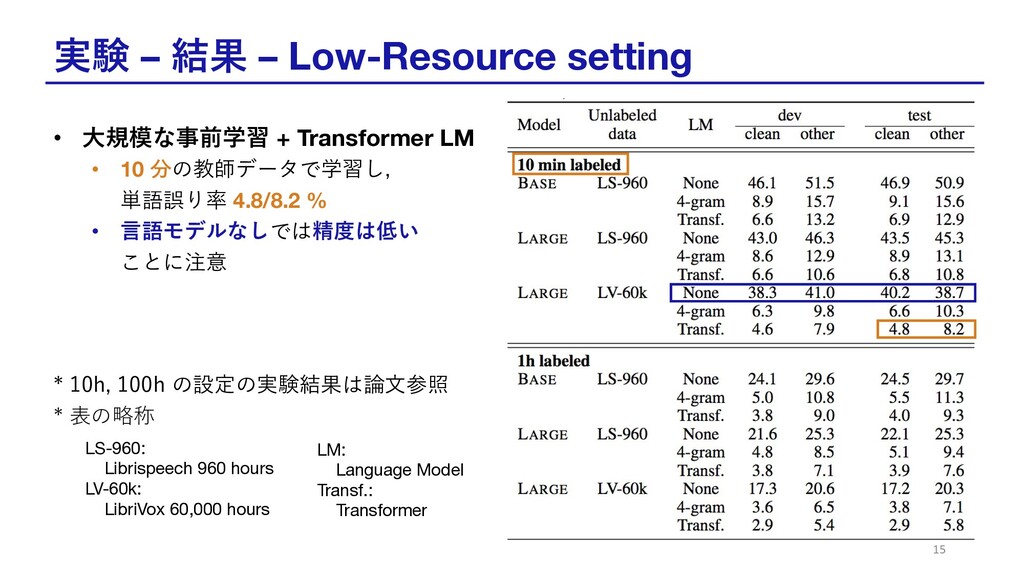
実験 – 結果 – Low-Resource setting • ⼤規模な事前学習 + Transformer
LM • 10 分の教師データで学習し, 単語誤り率 4.8/8.2 % • ⾔語モデルなしでは精度は低い ことに注意 * 10h, 100h の設定の実験結果は論⽂参照 * 表の略称 15 LM: Language Model Transf.: Transformer LS-960: Librispeech 960 hours LV-60k: LibriVox 60,000 hours
実験 – 結果 – High-Resource setting • 事前学習 + 960h
教師データ • 既存の教師あり⼿法より ⾼い精度 • 既存の半教師あり⼿法に 勝るとも劣らない精度 Ø wav2vec 2.0 はモデル構造が Seq2Seq ではないことを 考慮するとすごい 16 LM: Language Model Transf.: Transformer LS-960: Librispeech 960 hours LV-60k: LibriVox 60,000 hours CLM: CNN-base LM 既 存 ⼿ 法
まとめ • ⾳声データに対する新たな⾃⼰教師あり学習の枠組みである wav2vec 2.0 を提案 • 事前学習では離散化した⾳声をターゲットとした対照学習を⾏う • 事前学習後に
CTC Loss でファインチューニングすることで ⾼い⾳声認識精度を達成 • Librispeech コーパスのわずか 10 分の教師データで学習し, 単語誤り率 4.8% の認識精度 • ⼤量の教師データを⽤いた場合も事前学習の効果がある 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![モデル - Quantization module – Gumbel-Softmax • Gumbel-Softmax [Jang+, 2016]](https://files.speakerdeck.com/presentations/fc4176acb22e49fcac7afe4a25999ab4/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}