• Offers distributed file system(HDFS) for storing massive amount of data across clusters. • MapReduce as a programming model for processing the large amount of data. • Adopted and used in production by 1000+ companies worldwide. • 20+ popular Hadoop-based subprojects and growing.
could notify interested clients about major HDFS events (like file creation, deletion, etc), MapReduce job end notification. • [HDFS-2760] talks about adding a PubSub system on HDFS for sending notification messages to clients subscribed to specific services. • [HDFS-7821] talks about an event notification system which – • Provide periodic updates to subscribed users • Provide the capability to let users specify 'interesting events'. • Provide a 'customizable' and 'configurable' interface such that user-defined parameters can also be 'subscribed' by the user.
for sending and receiving messages. • Three components – Publisher, Broker, Subscriber. • Supports both Persistence and Non Persistence. Apache Kafka • Developed by LinkedIn. • Three components – Producer, Broker, Consumer. • Supports both Persistent and Non Persistent Messaging. • Uses Zookeeper for co- ordination.
of running jobs among multiple Hadoop services. • Hadoop services can take the role of either a publisher or a subscriber. • Example – • TaskTrackers only notifying JobTracker their status where there is a status change.
about the completion of some other job on which they are dependent. • No need to poll the NameNode for data availability in the HDFS. • Multiple subscribed services or jobs can be notified when the data is available.
be chained based on events occurring in the Hadoop cluster. • Easier for workflow managers to chain jobs and trigger workflows automatically. • Automatic setting of job dependency for heavily chained MapReduce jobs in order to accomplish a complex computation.
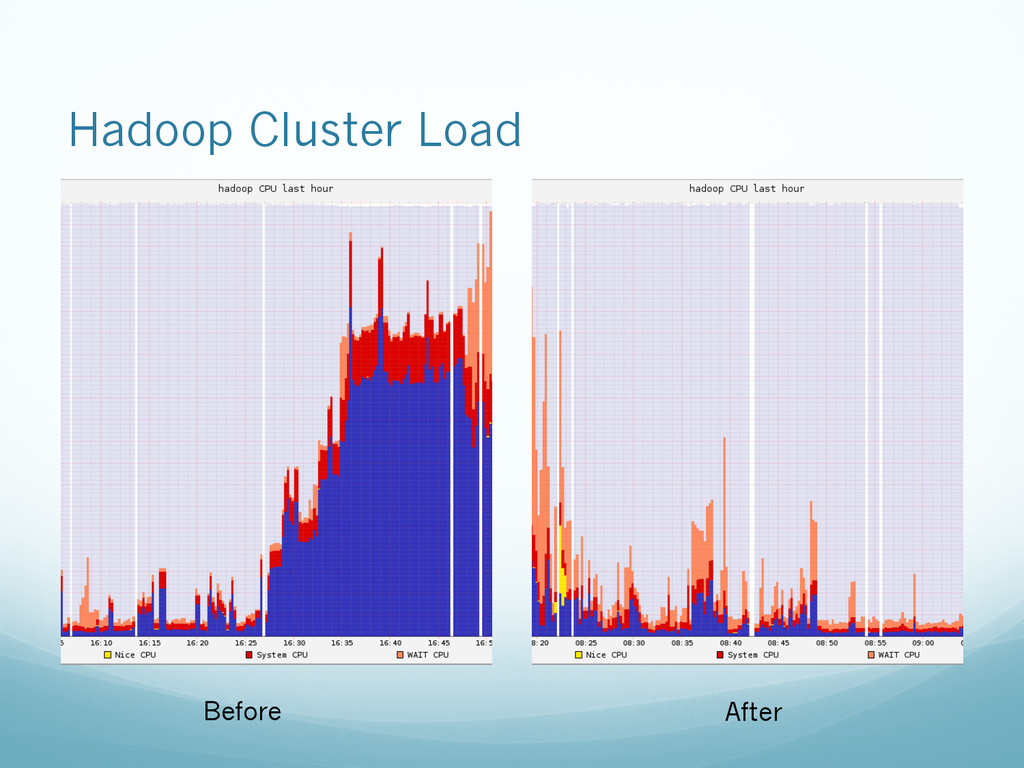
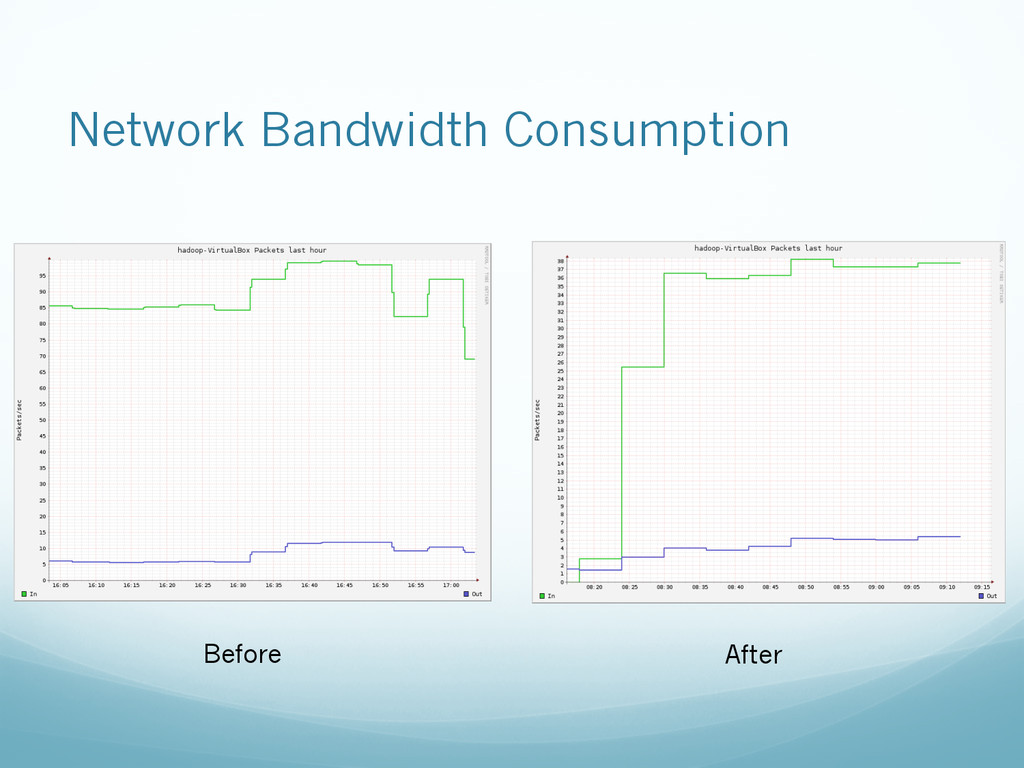
model. • Can be used to pass messages between services, notify subscribed clients and chain multiple jobs. • Reduces cluster load and network bandwidth consumption significantly resulting optimal use of hardware and resources. • Can be scaled to large Hadoop cluster, > 100/1000 nodes for handling heavily inter-dependent jobs.
{kind=link}
{kind=link}
![Distributed Notification System • [HDFS-1742] talks about a system that](https://files.speakerdeck.com/presentations/8d382248122c4fce8f56333ebd2e295c/slide_2.jpg){kind=link}
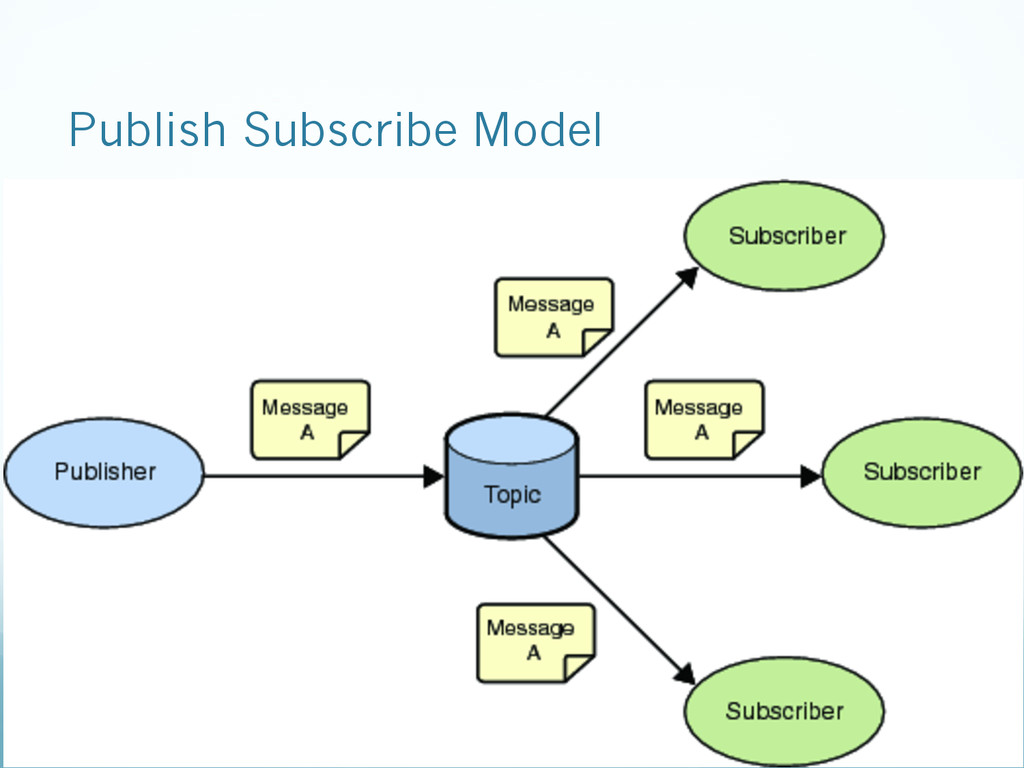{kind=link}
{kind=link}
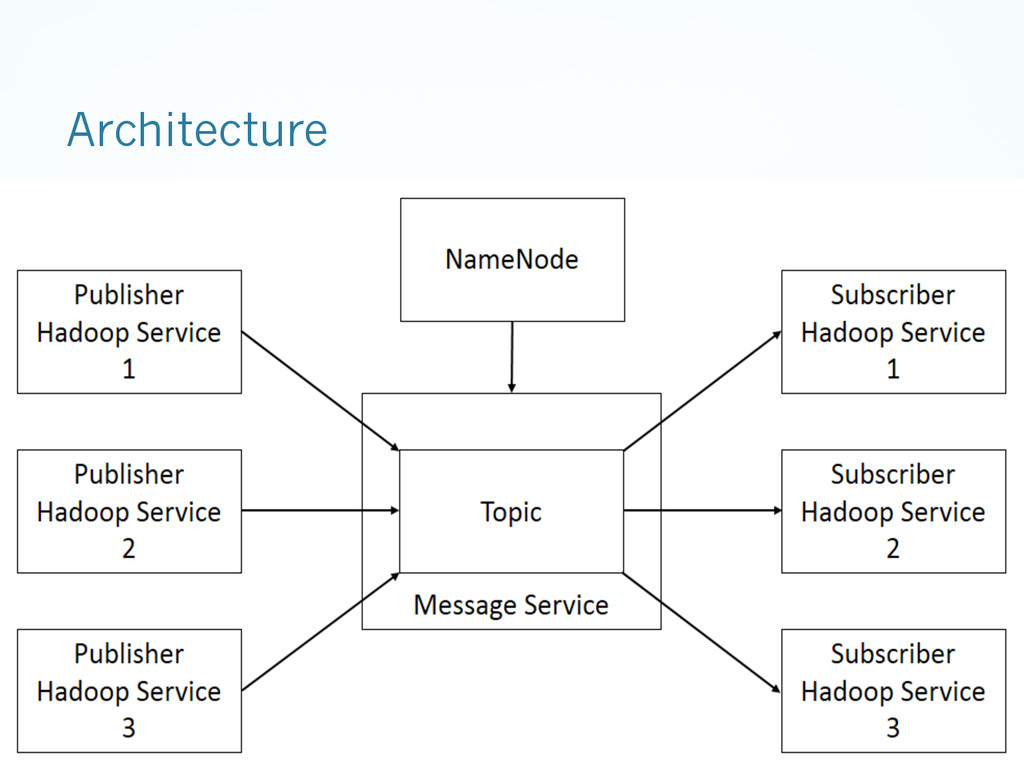{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
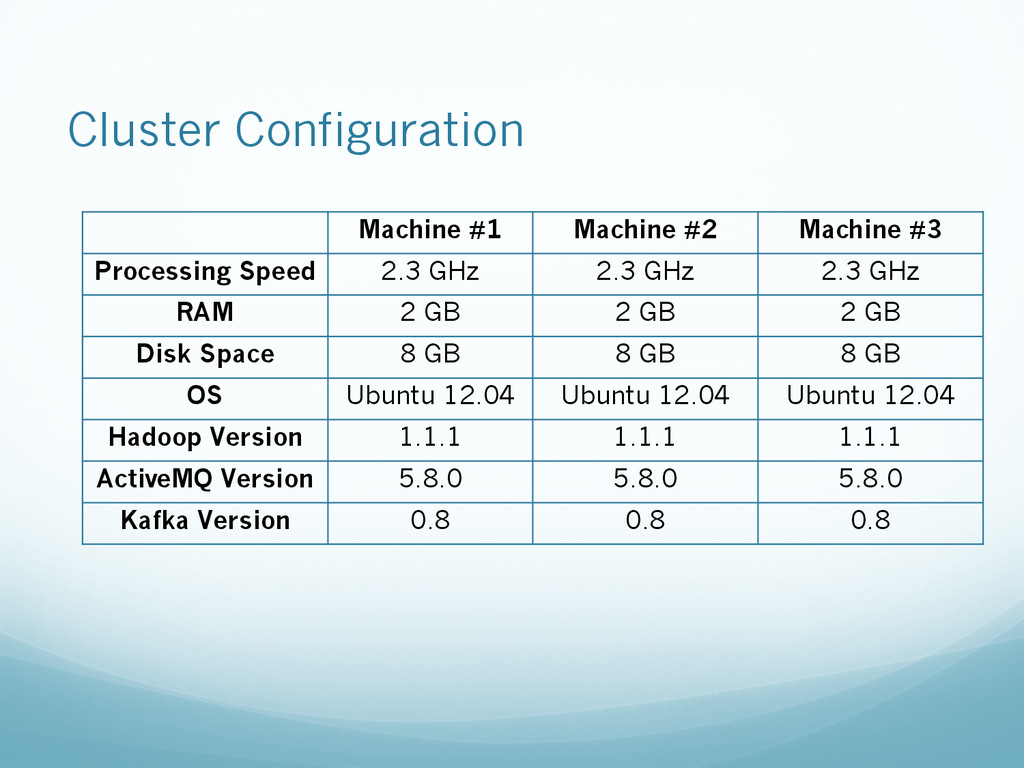{kind=link}
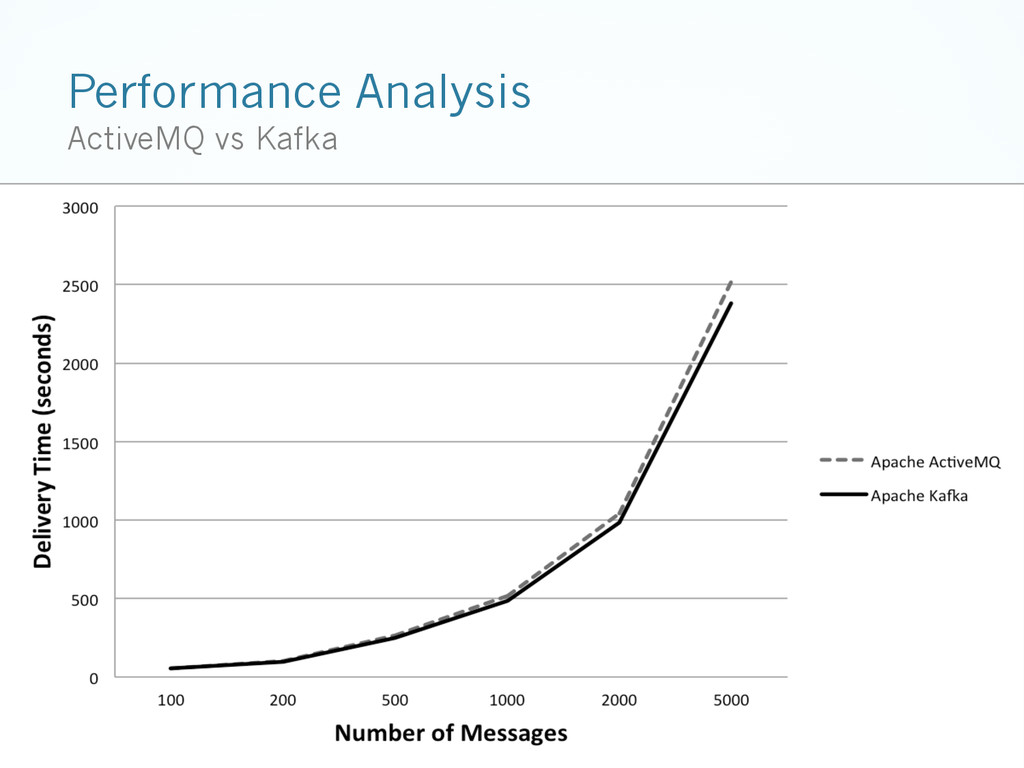{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}