変数 について3 つのタイプが考えられる。 1. 個人 と時点 の両方に依存: 年収、家賃、労働時間など 2. 個人間で異なるが、時点では固定: 性別、母国語、個人の先天的資質 3. 時点によって異なり、個人間では共通: 消費税率、パンデミック化の行動制限(母集団全体に一律 に影響する変数) が観察できない変数であっても、上記のいずれかに分類される。 i i = 1, … , n t t = 1, … , T Xi,t i t Xi,t 4 / 48
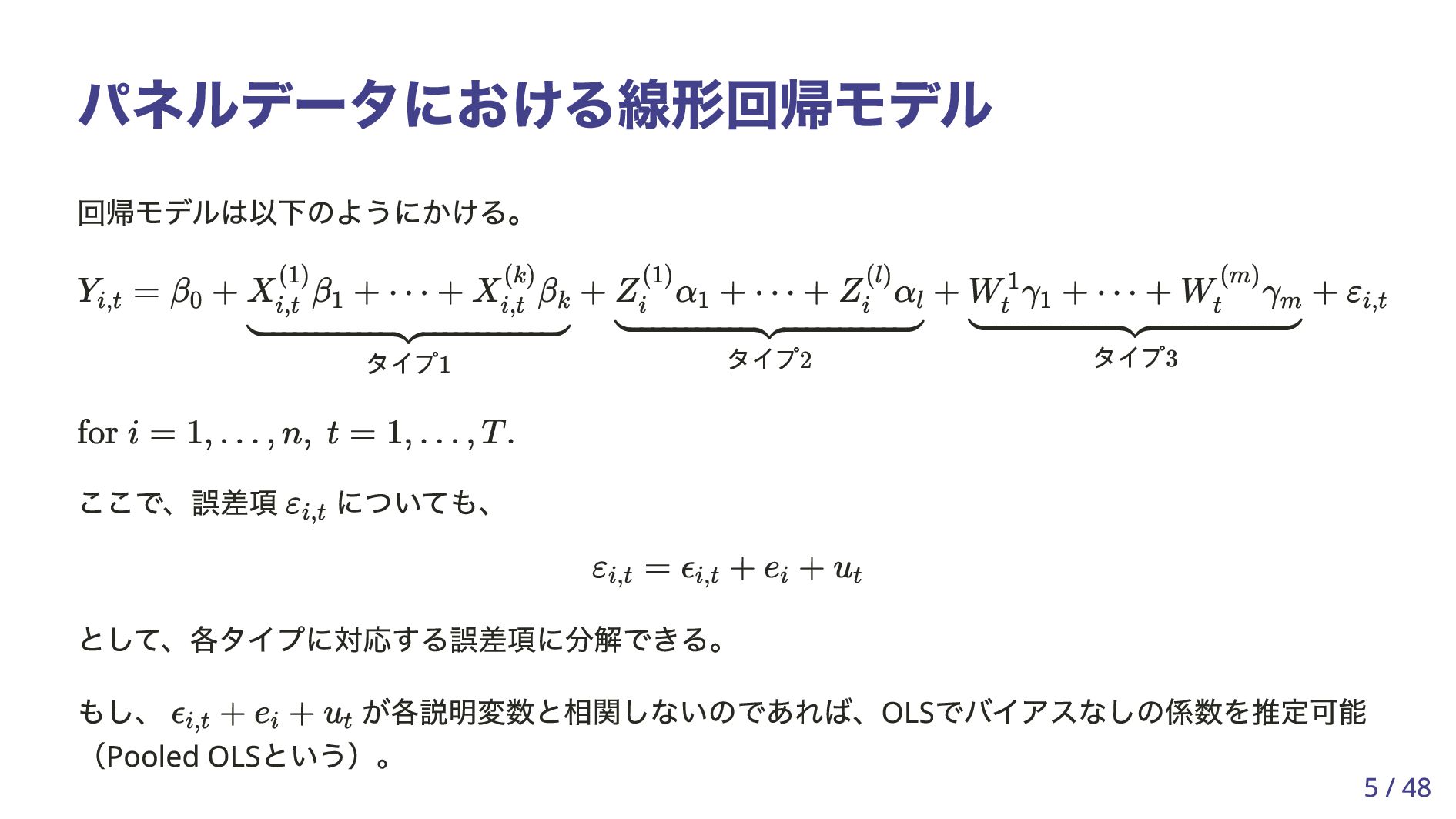
という)。 Y i,t = β 0 + X (1) i,t β 1 + ⋯ + X (k) i,t β k タイプ1 + Z (1) i α 1 + ⋯ + Z (l) i α l タイプ2 + W 1 t γ 1 + ⋯ + W (m) t γ m タイプ3 + ε i,t for i = 1, … , n, t = 1, … , T . ε i,t ε i,t = ϵ i,t + e i + u t ϵ i,t + e i + u t 5 / 48
のみを無限に大きくする (i.e., ): 金融データ Big Data 3. と のどちらも無限に大きくする (i.e., ) どの枠組みを採用するかによって、選択可能な分析方法も変化する。 Unbalanced panel data: 個人ごとに観察できる時期や期間が異なる場合 Balanced panel data: 全ての個人について同一の時期・期間で観察できる場合 本書ではタイプ1 & Balanced panel data について考える。 n × T n n → ∞, T < ∞ T n < ∞, T → ∞ ⊆ n T n → ∞, T → ∞ 6 / 48
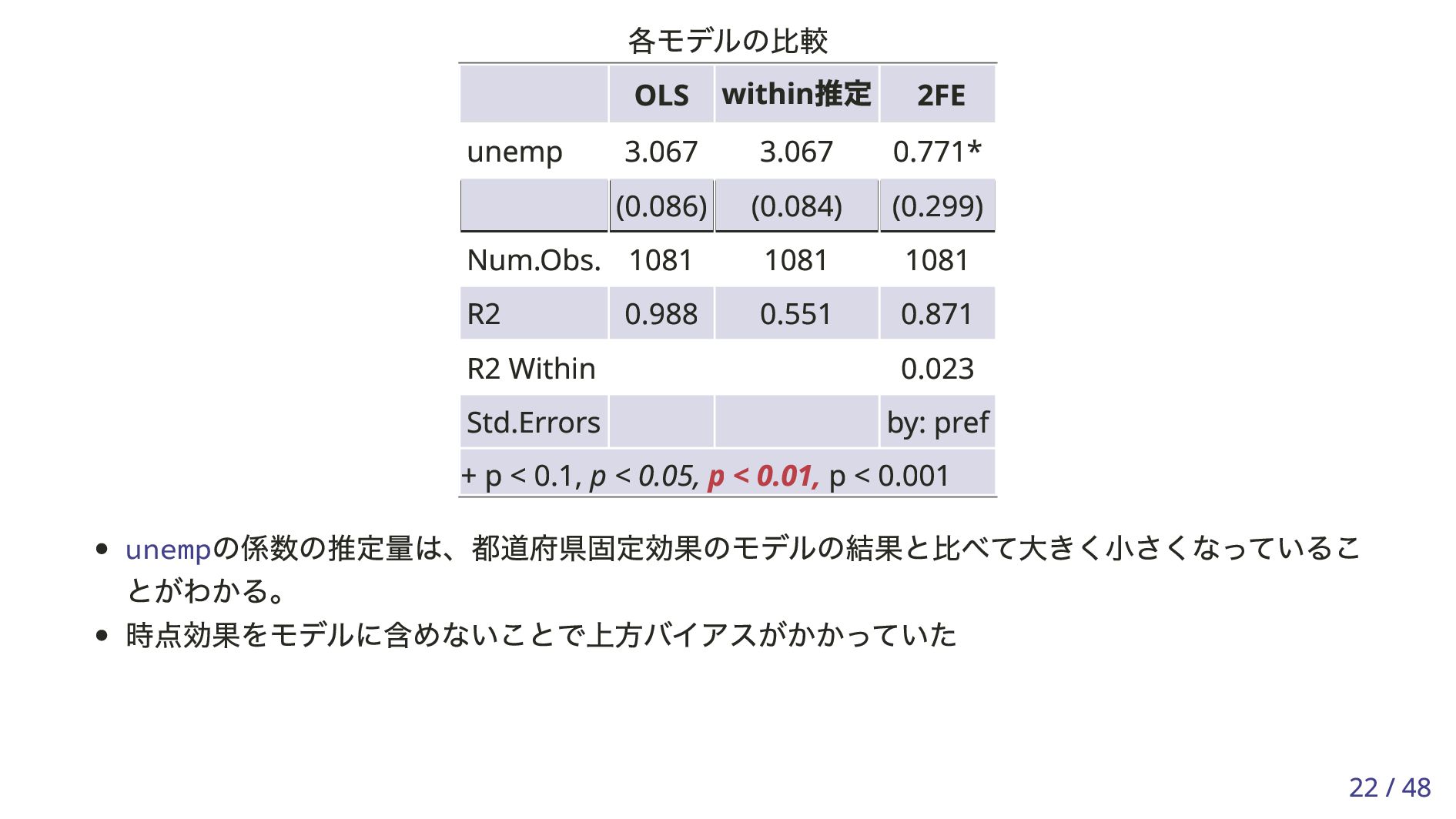
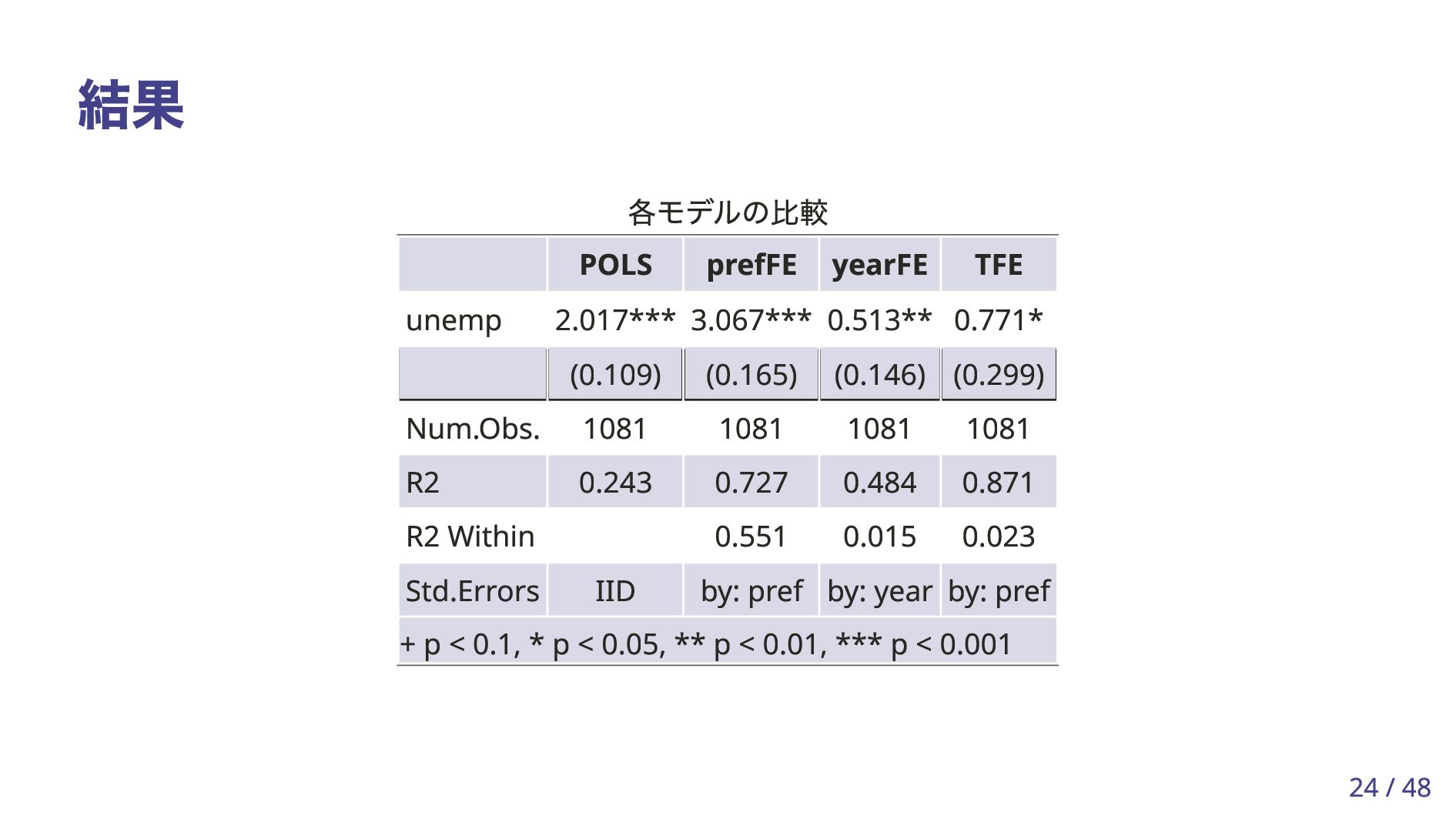
を正しく推定するには と が無相関である必要。ここで は、 年 に依存せず新規求人数に影響を与える、観察できない地域 固有の要因 「地域の潜在的能力」「交通の利便性」など パネルデータが利用可能であれば、IV を使用せずとも を正しく推定することができる。 Yi,t = β0 + Xi,t β1 + Zi α + Wt γ + ϵi,t + ei + ut for i = 1, … , n, t = 1, … , T . Yi,t i t Xi,t β1 Xi,t ϵi,t + ei + ut ei t i β1 8 / 48
t i β0 ϕi = β0 + Zi α + ei t ψt = Wt γ + ut Yi,t = Xi,t β1 + ϕi + ψt + ϵi,t for i = 1, … , n, t = 1, … , T . Ii,j = 1{i = j}, δt,k = 1{t = k} Y i,t = X i,t β 1 + n ∑ j=1 I i,j ϕ j + T ∑ k=1 δ t,k ψ k + ϵ i,t for i = 1, … , n, t = 1, … , T . 9 / 48
Yi,t = Xi,t β1 + n ∑ j=1 Ii,j ϕj + ϵi,t i = 1, … , n, t = 1, … , T . (12.3) i T ¯ ¯ ¯ ¯ ¯ Yi = T ∑ t=1 Yi,t , ¯ ¯ ¯ ¯ ¯ ¯ Xi = T ∑ t=1 Xi,t , ¯ ¯ ¯ ¯ ϵi = T ∑ t=1 ϵi,t . 1 T 1 T 1 T ∑ n j=1 Ii,j ϕj t T ∑ n j=1 Ii,j ϕj (= ϕi ) 13 / 48
, Di ) : i = 1, … , n} ˆ ATET2 = ( ^ Y 2,D=1 − ^ Y 1,D=1 ) − ( ^ Y 2,D=0 − ^ Y 1,D=0 ) ^ Y t,D=1 = , ^ Y t,D=0 = ∑ n i=1 Di Yi,t ∑ n i=1 Di ∑ n i=1 (1 − Di )Yi,t ∑ n i=1 1 − Di 29 / 48
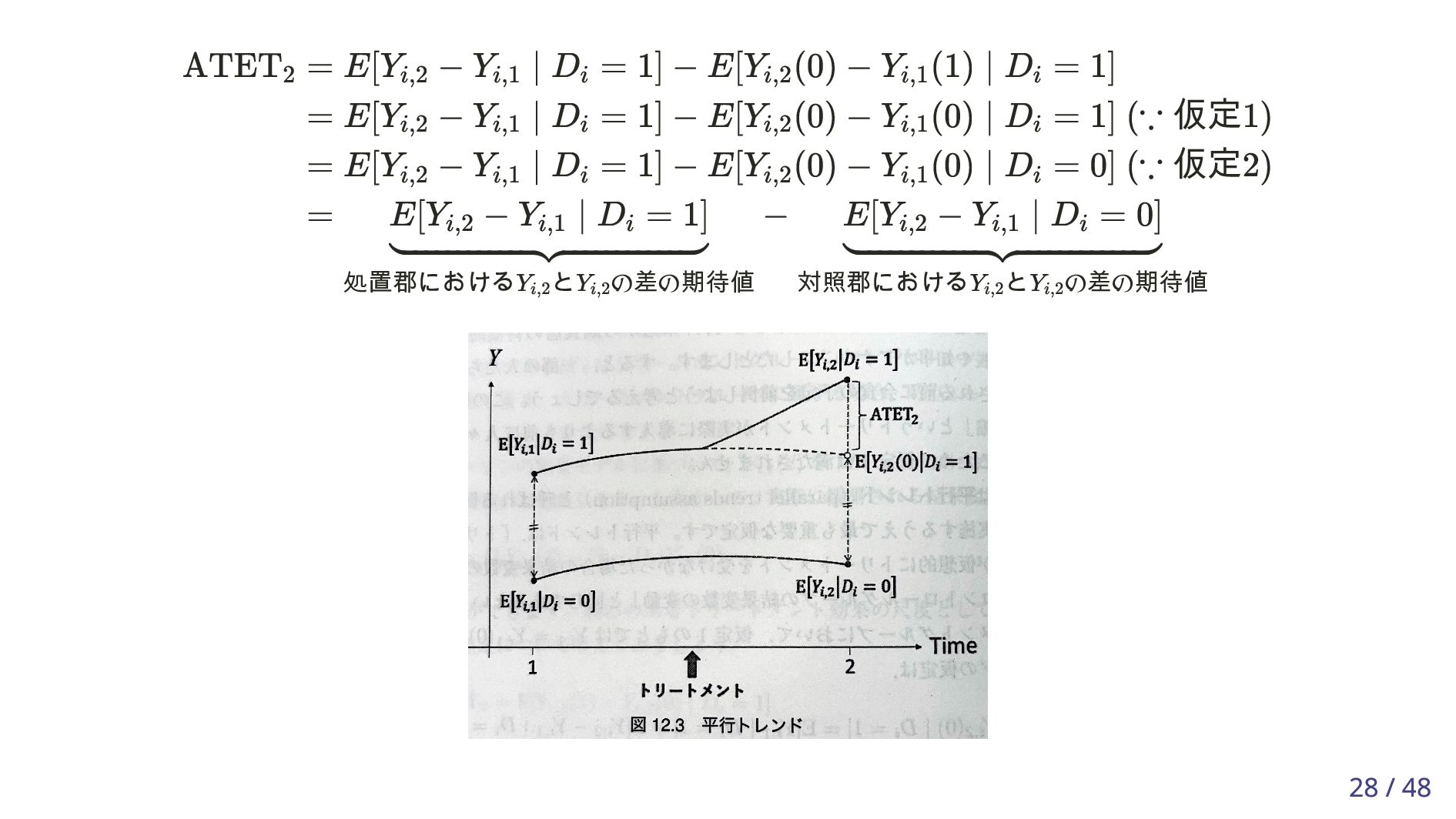
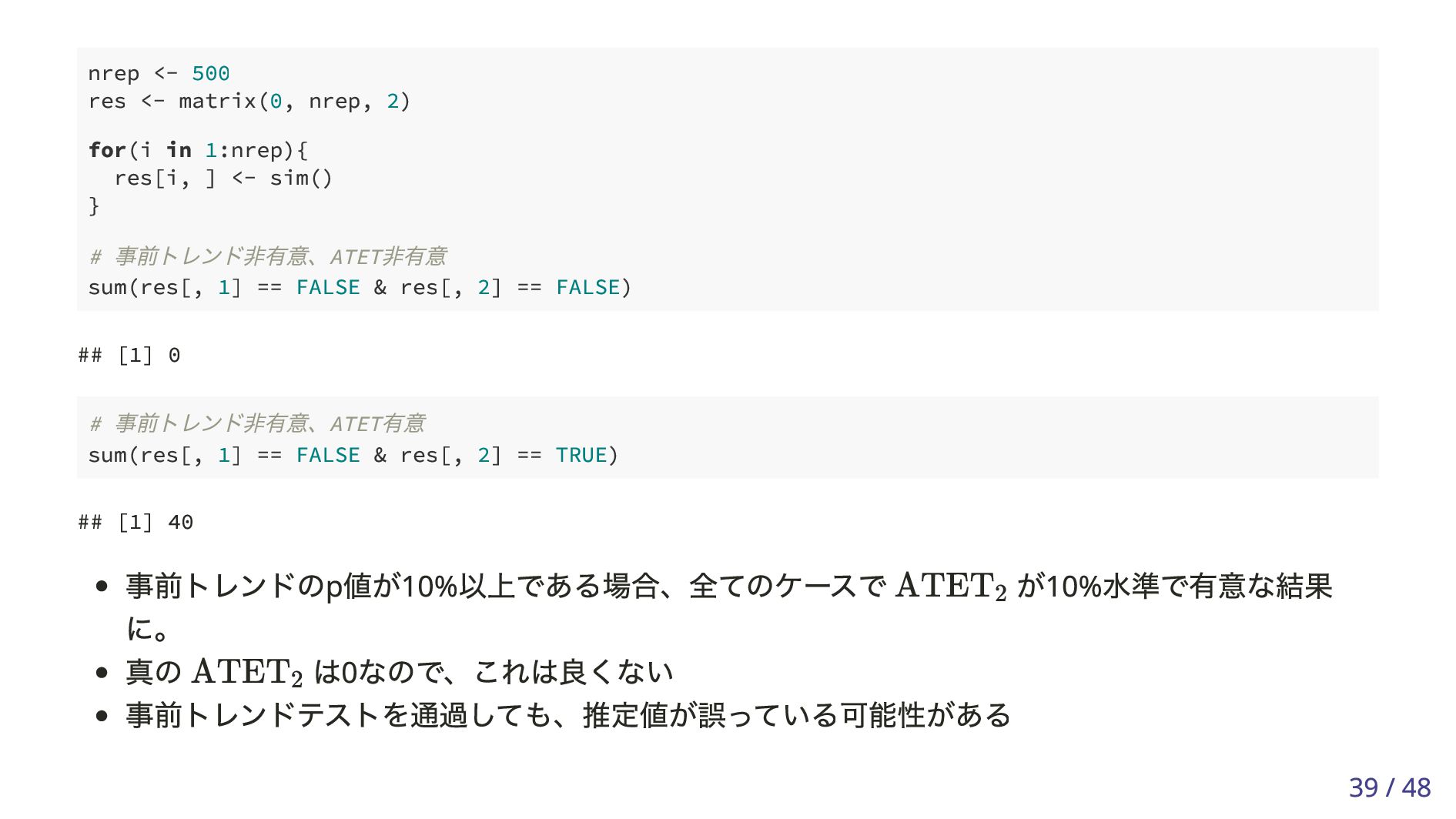
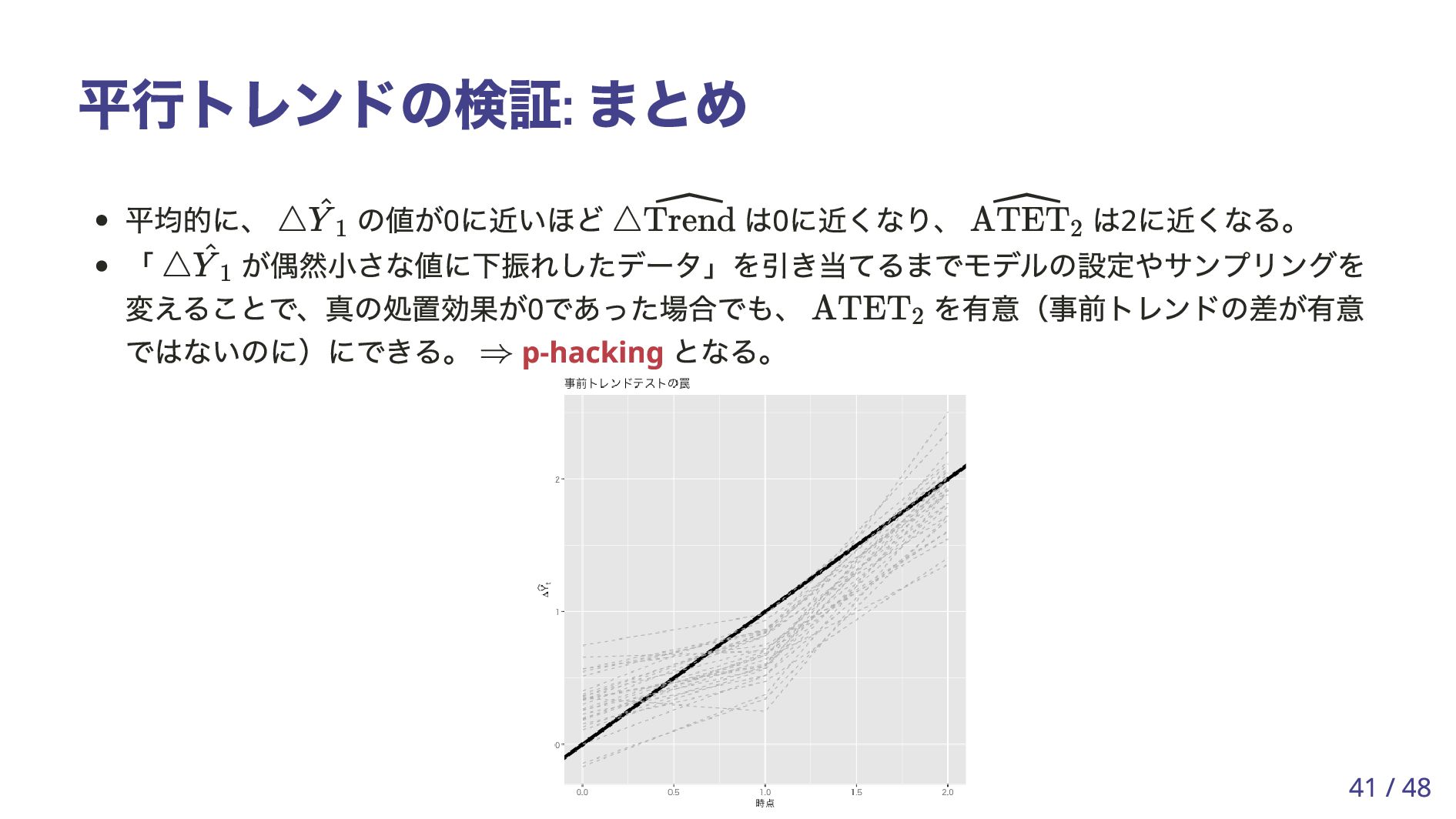
を通じて相関している。 t Yi,t (d) = ϕi + tDi + ϵi,t , i = 1, … , n, t = 0, 1, 2, d = 0, 1. E[Yi,t ∣ Di = 1] − E[Yi,t ∣ Di = 0] = t △ ^ Y t = ^ Y t,D=1 − ^ Y t,D=0 △ ^ Y t ≃ t △ ˆ Trend = ( ^ Y 0,D=1 − ^ Y 1,D=1) − ( ^ Y 0,D=0 − ^ Y 1,D=0) ˆ ATET 2 = ( ^ Y 2,D=1 − ^ Y 1,D=1 ) − ( ^ Y 2,D=0 − ^ Y 1,D=0 ) △ ˆ Trend = △ ^ Y 0 − △ ^ Y 1 , ˆ ATET2 = △ ^ Y 2 − △ ^ Y 1 △ ^ Y 1 △ ^ Y 1 40 / 48
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
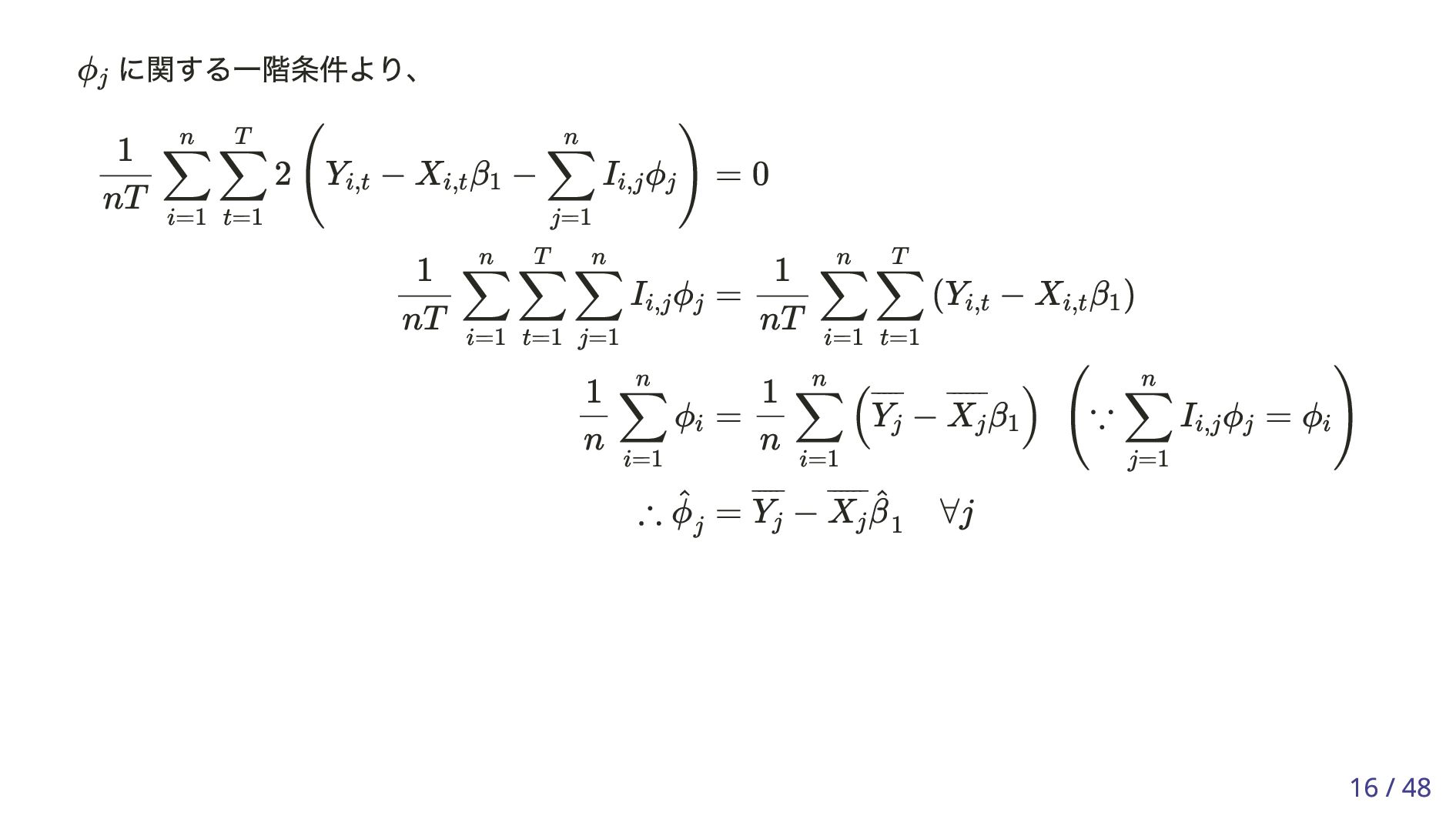{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}