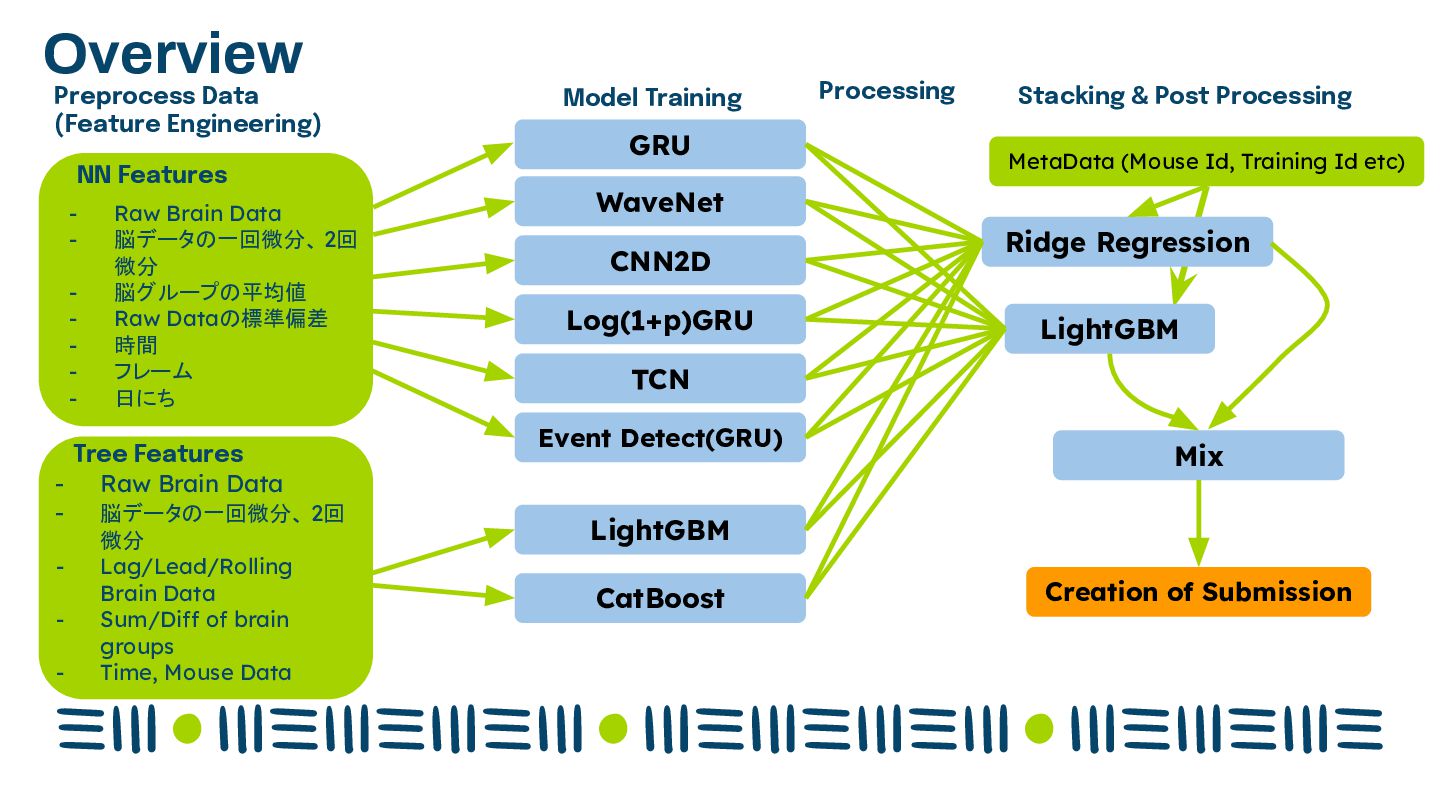
Data - 脳データの一回微分、 2回 微分 - Lag/Lead/Rolling Brain Data - Sum/Diff of brain groups - Time, Mouse Data GRU WaveNet CNN2D Log(1+p)GRU TCN Event Detect(GRU) LightGBM CatBoost Stacking & Post Processing MetaData (Mouse Id, Training Id etc) Processing Ridge Regression LightGBM Mix Creation of Submission - Raw Brain Data - 脳データの一回微分、 2回 微分 - 脳グループの平均値 - Raw Dataの標準偏差 - 時間 - フレーム - 日にち NN Features Model Training
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}