Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
エラーバジェットのアラートのタイミングを考える.pdf
Search
KairiM
June 17, 2026
Technology
220
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
エラーバジェットのアラートのタイミングを考える.pdf
KairiM
June 17, 2026
More Decks by KairiM
See All by KairiM
はじめてのDatadog
kairim0
0
440
Other Decks in Technology
See All in Technology
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
620
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
2
930
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
510
20260720_クラウド女子会×PyLadiesTokyoコラボ Amazon Bedrock ハンズオン用資料
yuuka51
1
110
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
140
文字起こし基盤の信頼性
abnoumaru
0
120
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
440
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
160
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
480
「休む」重要さ
smt7174
6
1.6k
Type-safe IaC for Dart
coborinai
0
180
Featured
See All Featured
The Curse of the Amulet
leimatthew05
2
13k
We Have a Design System, Now What?
morganepeng
55
8.2k
The Mindset for Success: Future Career Progression
greggifford
PRO
0
430
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Everyday Curiosity
cassininazir
0
260
Automating Front-end Workflow
addyosmani
1370
210k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Speed Design
sergeychernyshev
33
1.9k
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
Transcript
JDDUG TOKYO エラーバジェットの アラートタイミングを考える 1
JDDUG Ryukyu (沖縄 ) 運営 丸山 海理 所属 役職 出身地
出身校 趣味 好きなAWS サービス SNS (株)サンエー 情報システム部 課長 京都府 琉球大学 法文学部 経済 スポーツ観戦(サッカー/野球) KIRO cli @KairiM0kinawa 2
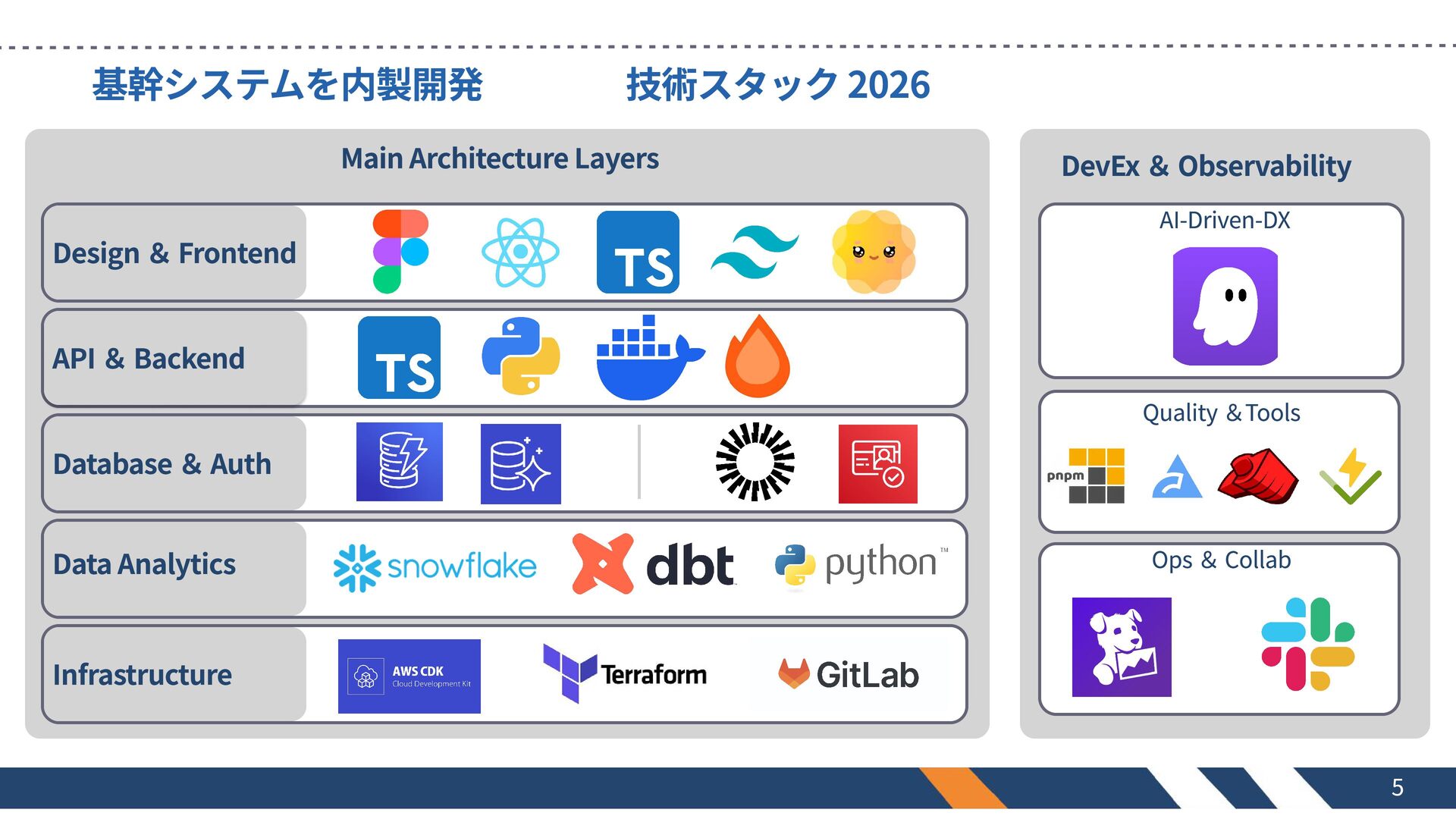
基幹システムを内製開発 技術スタック 2026 Main Architecture Layers Design & Frontend API &
Backend Database & Auth Data Analytics Infrastructure DevEx & Observability AI-Driven-DX Quality &Tools Ops & Collab 5
やりたいこと SLI、SLO、エラーバジェットを定義した。 次のアクションとして 対応すべきインシデントにできるだけ早く気付き、 かつ対応時間にゆとりがあり、ユーザー体験に 影響が出る前に解決できるようにしたい。 適切なアラートタイミングを決めたい。 6
google sre workbook にベストプラクティス書いて るよ! 今日の話は Chaptaer 5 の個人解釈の話です https://sre.google/workbook/table-of-contents/
7
アラートのタイミングで考慮すべきこと 再現率(Recall) 発生した重大な事象のうち、ア ラートが検知できた割合。100% に近いほど、見逃しがない。 検知時間(Detection time) 問題が発生してから通知が届くま での時間 リセット時間(Reset
time) 問題が解決した後、アラートが停 止するまでの時間。長すぎると混 乱を招く。 完了判断時間は 適切か? 適合率(Precision) 検知した事象のうち、実際に重大 だったものの割合。100%に近い ほど、不要な通知(ノイズ)が少 ない。 不要なキャッチは していないか? 見逃しはないか? 検知は速いか? 8
6つの通知方法のメリット・デメリット 種類 ①ターゲットエラー率 ≧ SLO閾値 ②アラート期間(ウィンドウ)の 延長 ③持続時間( Duration)の 追加
実装 10分などの短い時間枠(ウィンド ウ)を指定し、その間の平均エラー 率がSLOの許容閾値を超えた場合に アラートを設定する。 判定する時間枠を36時間などの長期 間に拡大し、その長期平均エラー率 がSLOの許容閾値を超えた場合にア ラートを設定する。 短い時間枠(1分など)のエラー率 を 監視し、そ れが閾値を 「1時 間持 続」した場合に のみ通知する設定に する。 メリット 実装が非常に簡単で、システ ムが完全に停止したような大 規模障害を素早く検知できま す。 判定期間を長くすることでエ ラーが持続しているかを確認 でき、 方法1よりも誤報 を抑 えられます。 閾値を超えた 状態の 継続を 条 件にできるた め、 短時 間のノ イ ズに よる不要な 通知をカッ トできます。 デメリット 適合率が低く、エラー予 算に影響しない一時的な スパイクでも頻繁に誤報が 発生します。 障害が完全に 復旧した 後 も、 長期間(例:36時 間)に わたってアラートが 鳴り止まな くな ります。 深刻な全 断が 起きて も設定 時間まで 通知 されず、エ ラー率が 瞬間的に 下が る とタイ マーが リセットされ て検知で きな いリスクが あります。 9
6つの通知方法のメリット・デメリット 種類 ④バーンレート(Burn Rate)に 基づくアラート ⑤複数のバーンレートによるア ラート ⑥マルチウィンドウ・マルチバー ンレート 実装
1時間などの固定枠を使い、エラー 予算を消費する速度(バーンレー ト)が計算上の閾値を超えた場合に アラートを設定する。 「1時間で2%消費」「3日間で10% 消費」など、複数の異なるバーン レートと時間枠のルールをそれぞれ 独立してシステムに設定する。 各バーンレートに 対し、「 長い 窓 (1時間)」と「短い 窓( 5分)」を AND条件で 組み合わ せ、両 方の時間 枠で閾値を 超えた 場合にの み通知す るよう設定する。 メリット エラー予算の消費速度を監視 するため、短い時間枠で高い 検知速度と精度を両立できま す。 急激な予算消費に は即時 通 知、 緩やかな消費に はチケッ ト 起票とい った、 緊急度に 応 じた 柔軟な 運用が可能です。 誤報が 極めて少なく、 障害が 復旧した 後は短い時間枠の 判 定によ って数 分でアラートが 自動停止します。 デメリット 閾値をわずかに下回るよ うな「じわじわ進むエ ラー」を見落とし、気づ かぬうちに予算を使い果 たす可能性があります。 管理す べき閾値 や時間枠の 数が 増える ほか、 長期ウィ ン ドウの 影響で 復旧後の リセット時間が 長くなり ます。 複数の時間枠と 条件を複 雑に 組み合わ せるため、 監視ツールの設定やロ ジックの管理に手間がか かります。 10
前提条件 ・今回アラートを検討してたサービスは認証基盤 ・ユーザー体験として認証できないということを課題とする リクエストの中で認証エラーのものを設定 単純な入力間違いなどは除外 ※ここも議論の余地あり・・・・ ・リカバリーコードの登録・PWリセットなども同サービスに含まれる 11
Bits Chat (Bits Assistant) でやってみよう!!! 1カ月で8時間のエラーバジェットを用意する。 なのでSLIは98.89%。 (全断でも8H就業時間内で仕事を終わらせたい・・・) 12
Bits Chat (Bits Assistant) でやってみよう!!! まずはhttps://sre.google/workbook/alerting-on-slos/ のサイトの内容を よく読んで理解してください。 1 2
3 4 5 6 申し訳ありませんが、私は外部のウェブサイトにアクセスしてコンテンツを読む機能を持っていません。 https: //sre.google/workbook/alerting-on-slos/ を直接閲覧することはできません。 ただし、このページはGoogle SRE Workbookの**「Alerting on SLOs」**の章であり、私のトレーニングデータ にその内容の知識があります。 すでに知ってた!?!?!!? 13
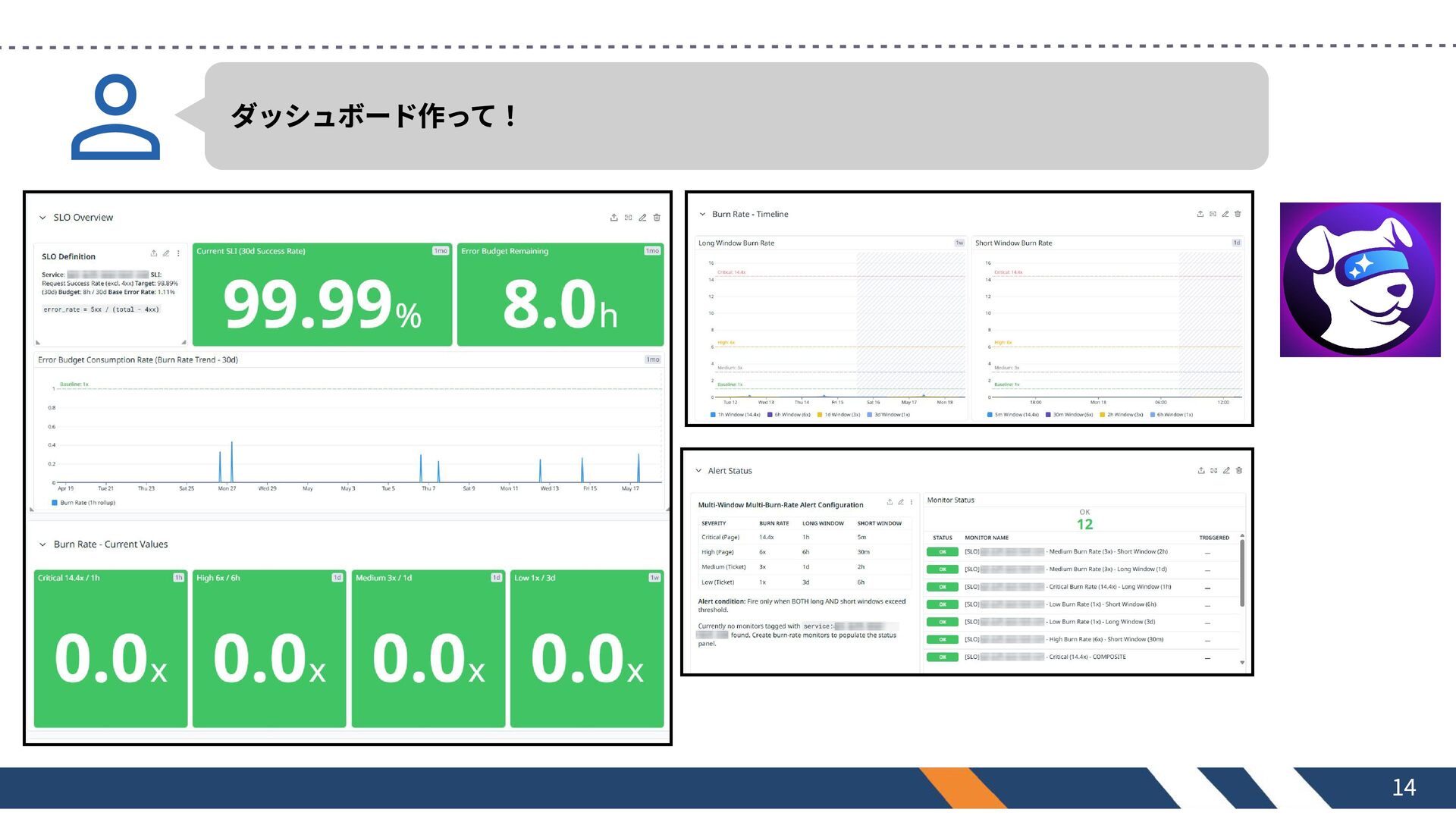
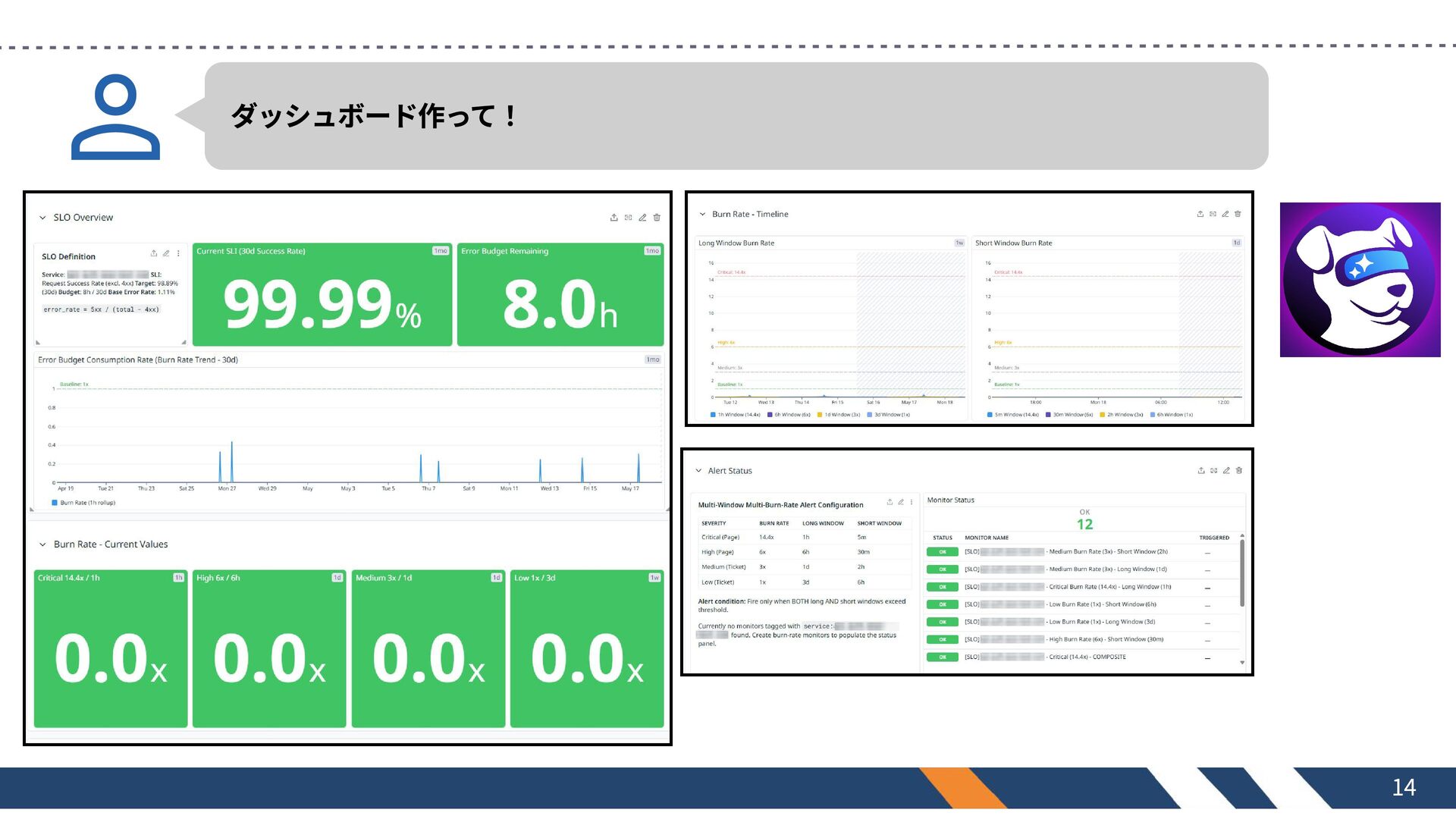
ダッシュボード作って! 14
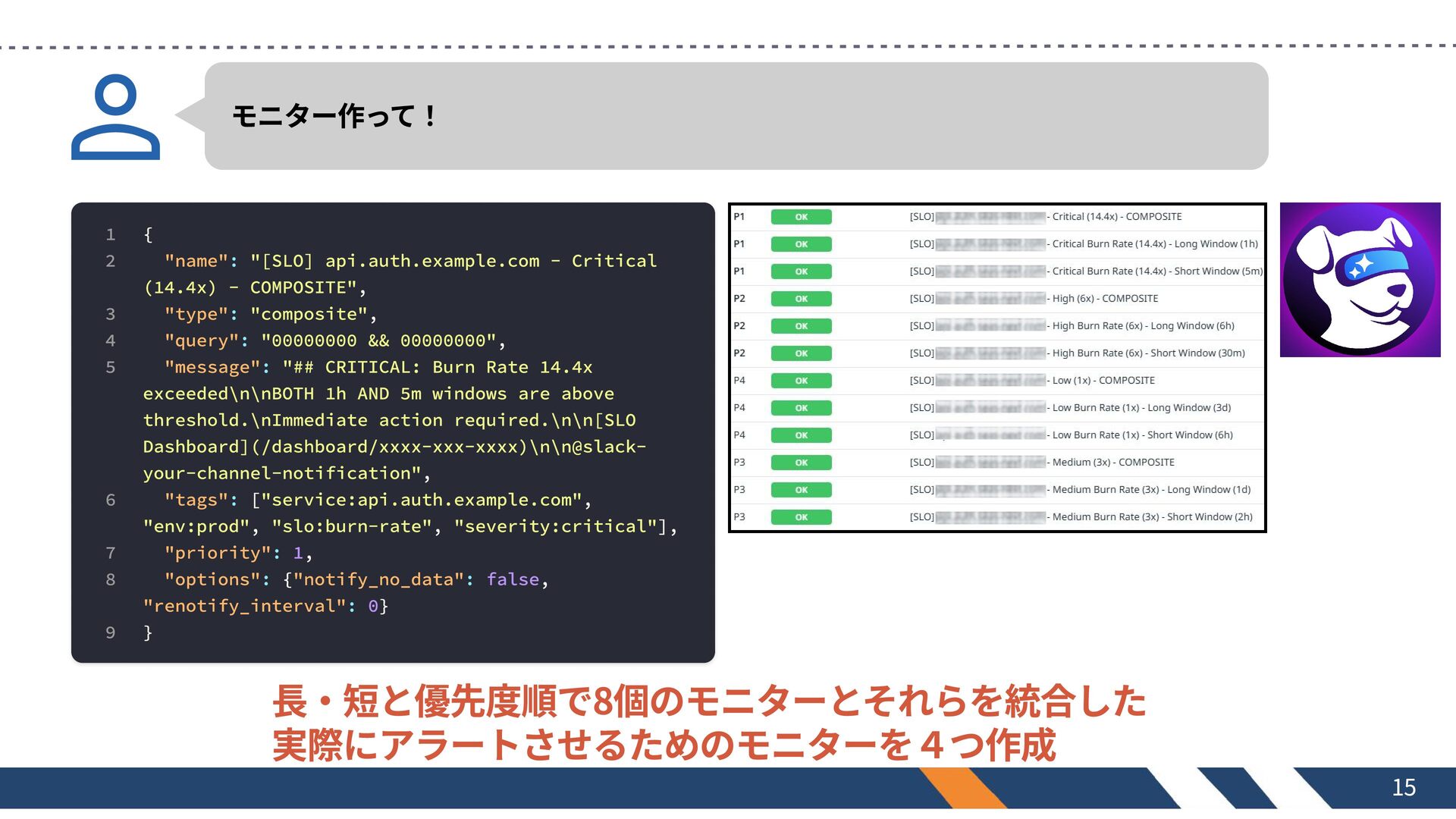
モニター作って! 1 2 3 4 5 6 7 8 9
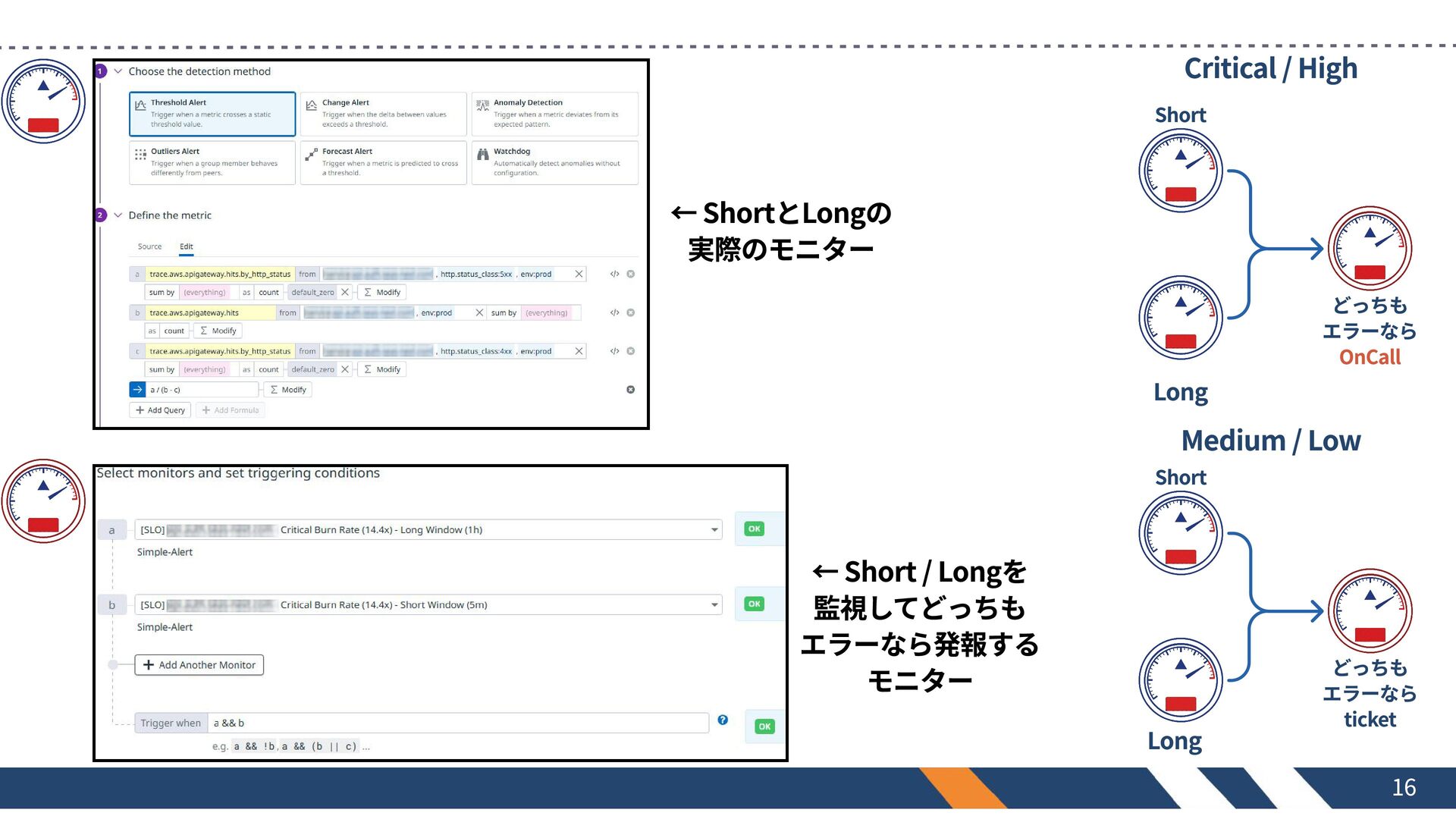
{ "name": "[SLO] api.auth.example.com - Critical (14.4x) - COMPOSITE", "type": "composite", "query": "00000000 && 00000000", "message": "## CRITICAL: Burn Rate 14.4x exceeded\n\nBOTH 1h AND 5m windows are above threshold.\nImmediate action required.\n\n[SLO Dashboard](/dashboard/xxxx-xxx-xxxx)\n\n@slack- your-channel-notification", "tags": ["service:api.auth.example.com", "env:prod", "slo:burn-rate", "severity:critical"], "priority": 1, "options": {"notify_no_data": false, "renotify_interval": 0} } 長・短と優先度順で8個のモニターとそれらを統合した 実際にアラートさせるためのモニターを4つ作成 15
成果物と考え方 重要度 BURN RATE 長期 Window 短期 Window Buget消費 エラー率閾値
🔴 Critical (Page) 🟠 High (Page) 🟡 Medium (Ticket) 🔵 Low (Ticket) 14.4X 6X 3X 1X 1時間 6時間 1日 3日 5分 30分 2時間 6時間 2% 5% 10% 10% 16.0% 6.67% 3.33% 1.11% 2/5/10ルールに準拠:緊急度に応じ、エラーバジェットを『2%・5%・10%』消費した時点でアラートを発火させる SREのベストプラクティス 17
← ShortとLongの 実際のモニター ← Short / Longを 監視してどっちも エラーなら発報する モニター
Critical / High Short どっちも エラーなら OnCall Long Medium / Low Short どっちも エラーなら ticket Long 16
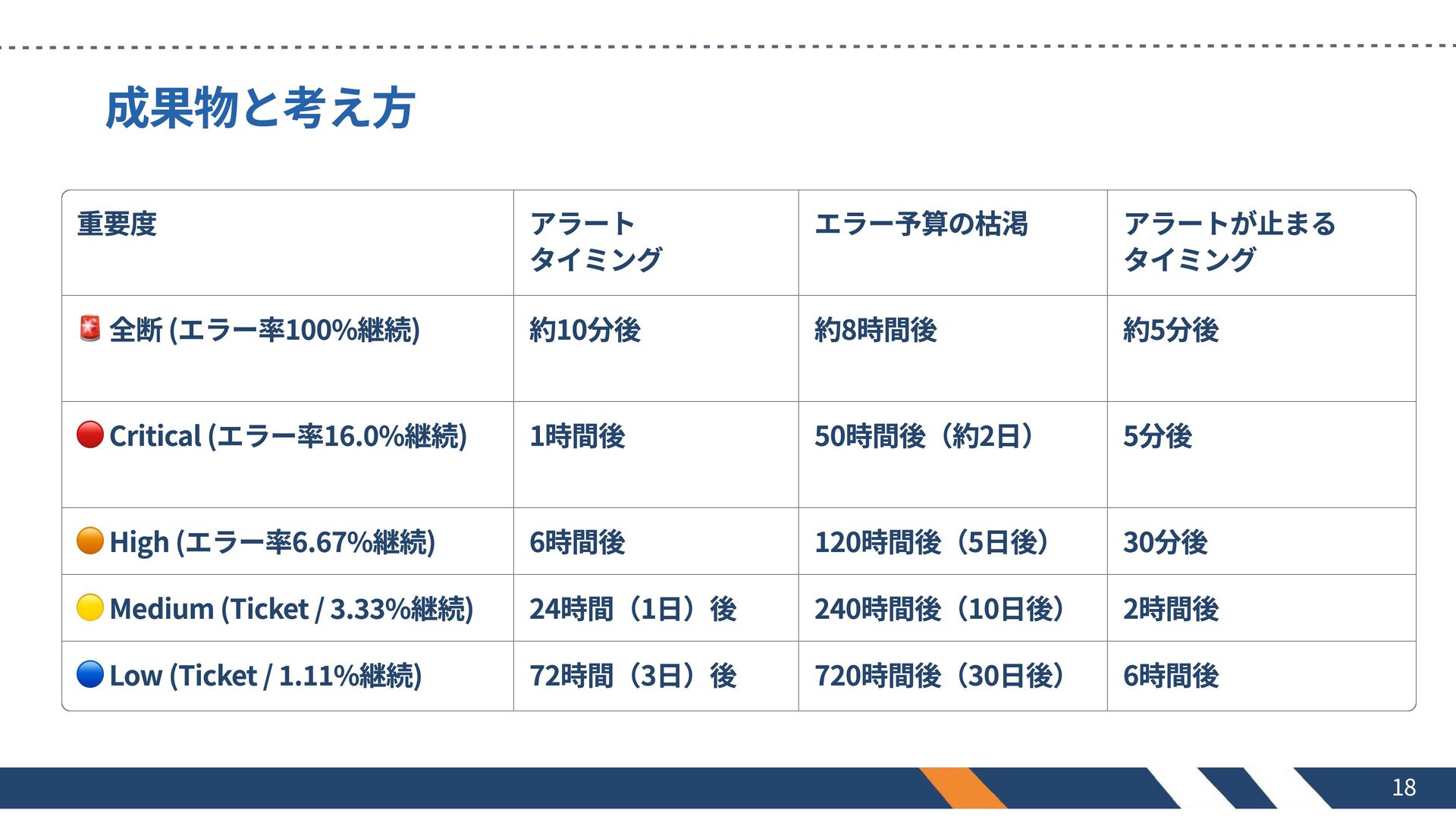
成果物と考え方 重要度 🚨 全断 (エラー率100%継続) アラート タイミング 約10分後 エラー予算の枯渇 約8時間後
アラートが止まる タイミング 約5分後 🔴 Critical (エラー率16.0%継続) 1時間後 50時間後(約2日) 5分後 🟠 High (エラー率6.67%継続) 🟡 Medium (Ticket / 3.33%継続) 🔵 Low (Ticket / 1.11%継続) 6時間後 24時間(1日)後 72時間(3日)後 120時間後(5日後) 240時間後(10日後) 720時間後(30日後) 30分後 2時間後 6時間後 18
まとめ Datadogなら簡単にMulti-window, Multi- burn-rateのアラート戦略ができる! 5分で説明できる分けもないのでZennに詳 細書きました。よかったらどうぞ→ https://zenn.dev/kairim/articles/f8b393773aec56 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}