#HA #DR
지난 10월 15일, 카카오가 사용하고 있던 SKC&C 판교 데이터센터에 화재가 났습니다. 이로 인해 카카오 전체 서버의 1/3의 전원이 꺼지면서 서비스에 장시간 장애가 발생하여, 이용자분들에게 많은 불편을 드렸습니다.
그 후 카카오는 '데이터센터 단위로 어떻게 다중화를 해야 이번과 같은 화재시에도 장애를 최소화 할 수 있는지' 광범위하고 깊은 원인 분석을 했고, 해결책을 고민하고 오늘도 계속 보완/실행해가고 있습니다.
이번 이프카카오에서 '1015장애 회고' 트랙을 통해, 각 시스템 레이어별로 어떻게 다중화할지 그 방안을 상세히 공유드리고자 합니다.
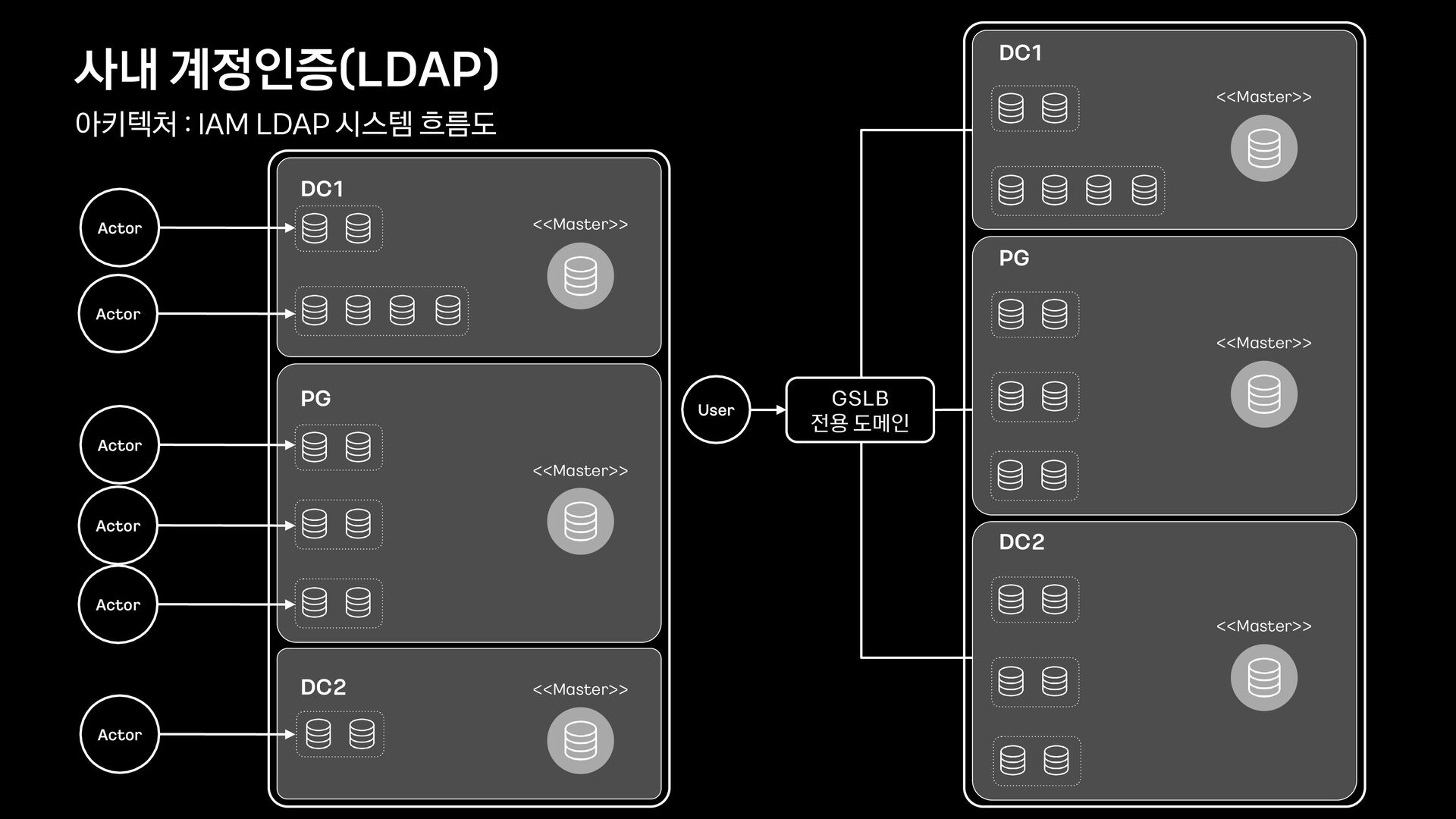
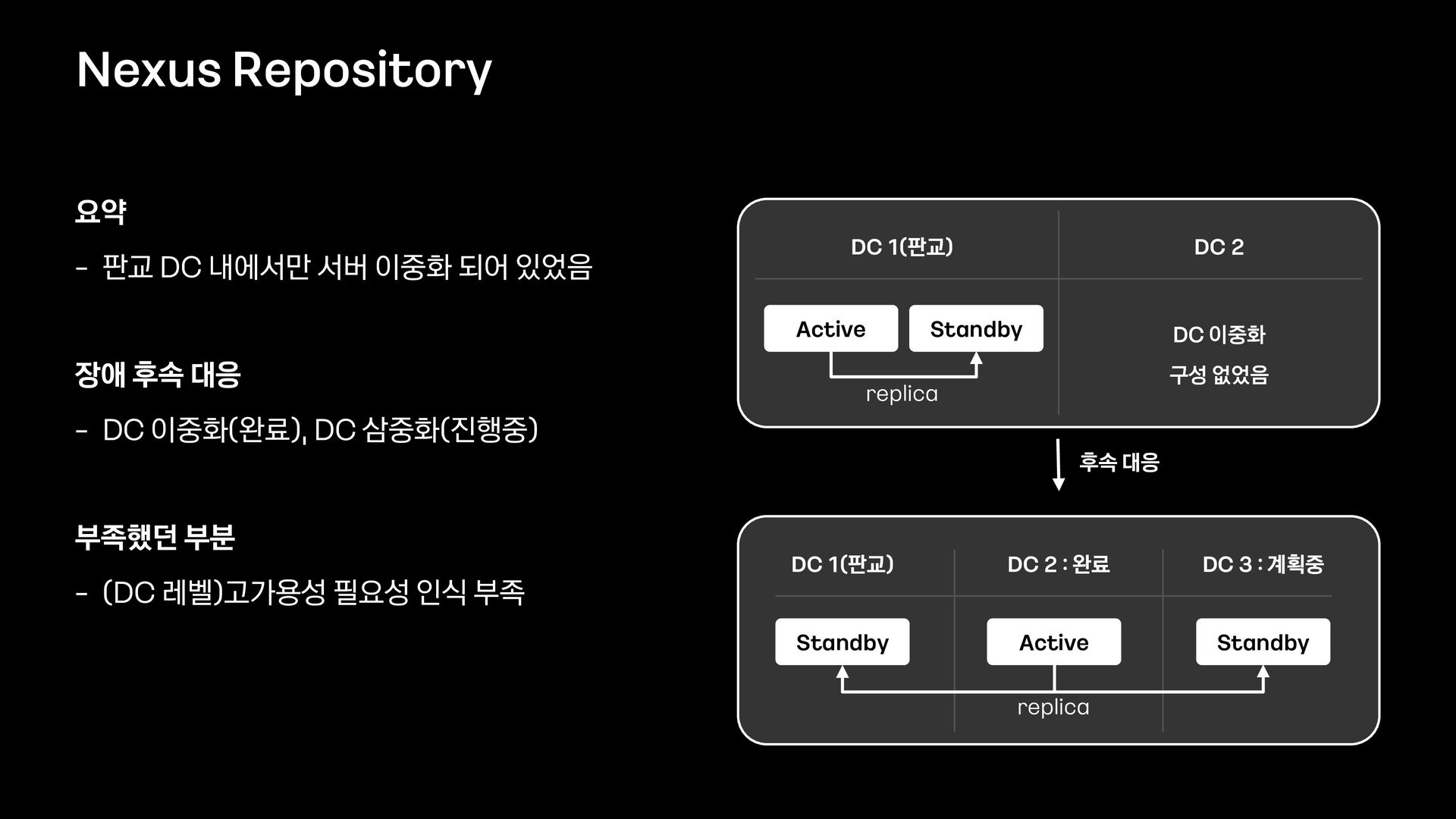
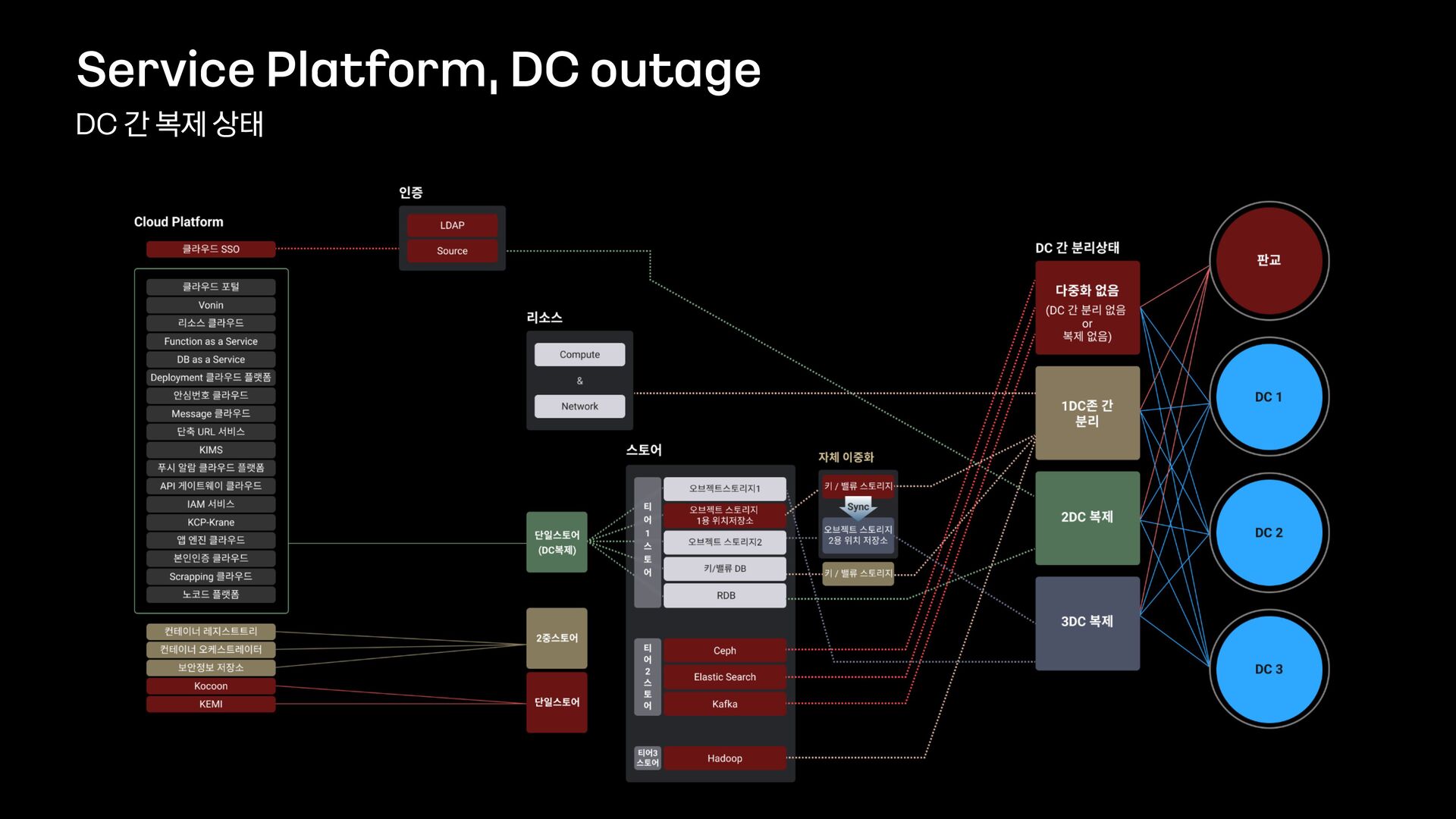
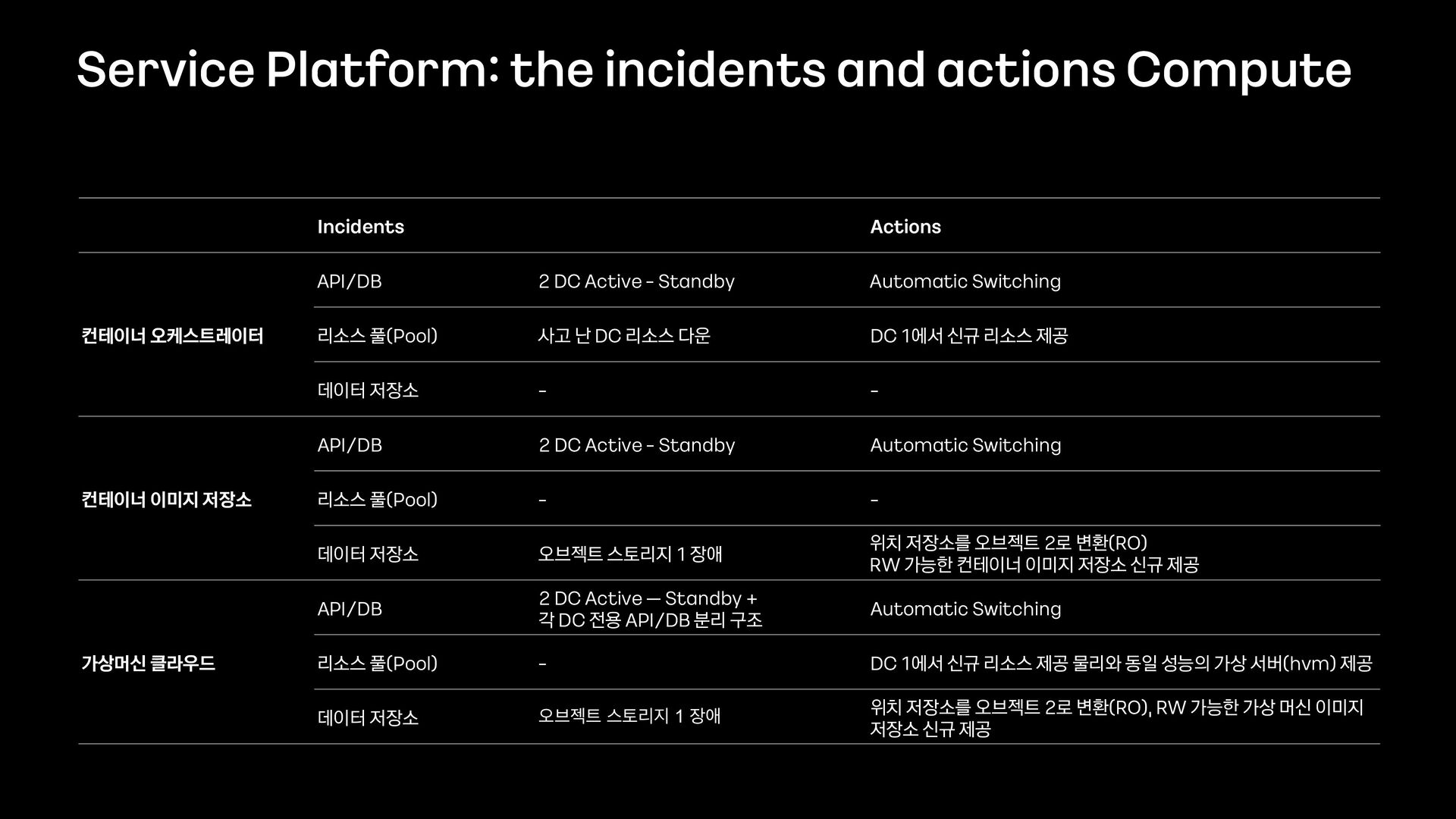
'1015장애 회고' 트랙은 다음과 같이 총 5개의 발표로 구성하였습니다. 이 영상은 카카오가 사용하는 서비스 플랫폼 레이어에 대한 다중화를 설명드립니다. 이 서비스 플랫폼 레이어애는 카카오내에서 사용하는 운영관리도구 / 클라우드 / Redis, ES, Kafka 와 같은 오픈소스기반의 플랫폼 등이 포함됩니다.
1. 데이터센터 단위의 다중화를 위한 고민
2. 인프라 설비 레이어 다중화
3. 데이터 레이어 다중화
4. 서비스 플랫폼 레이어 다중화
5. 애플리케이션 레이어 다중화
발표자 : andrew.kong
카카오 클라우드플랫폼팀 andrew 입니다.
chadwick.kang
카카오 시스템엔지니어링파트 chadwick 입니다.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}