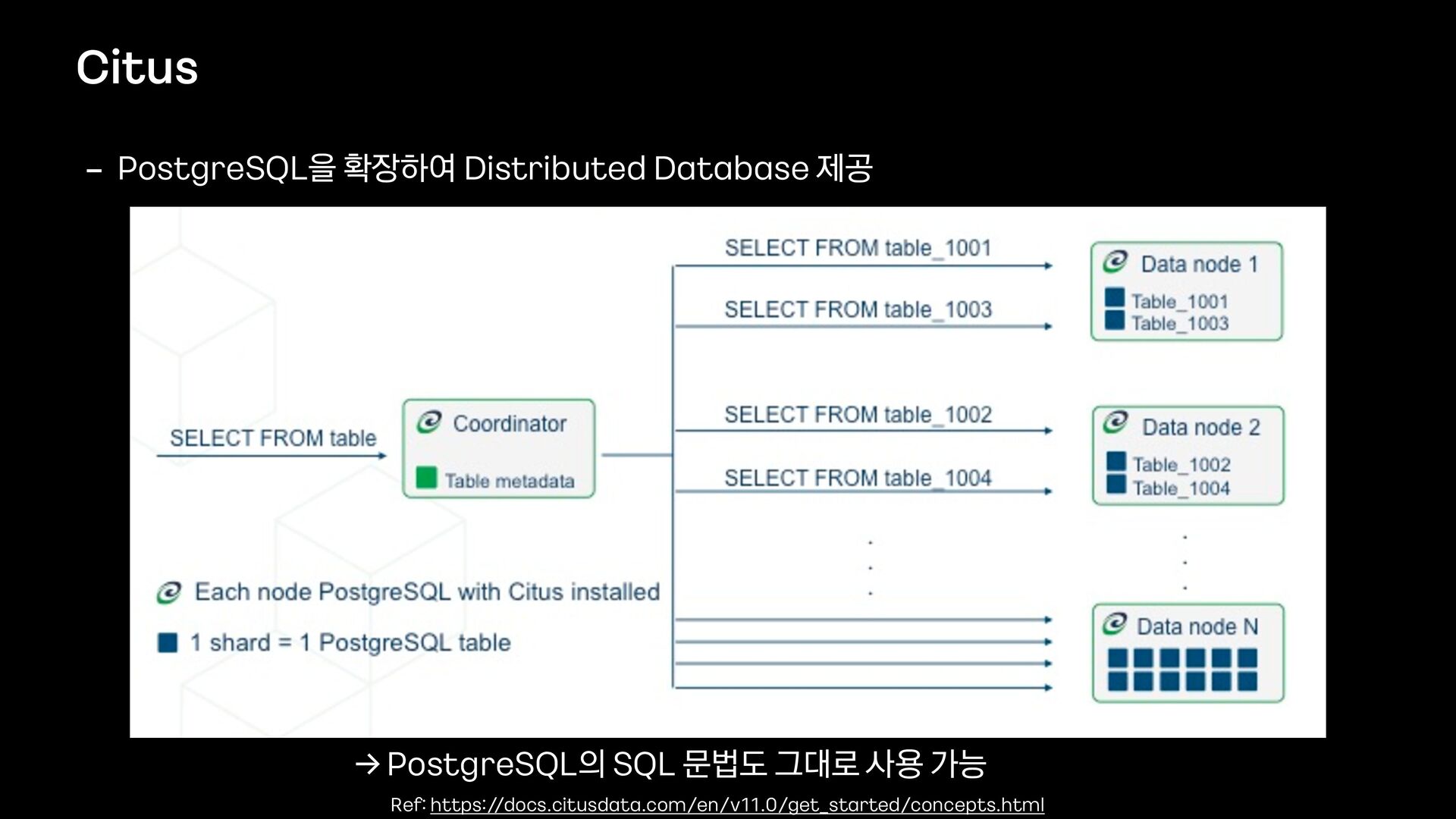
#Citus
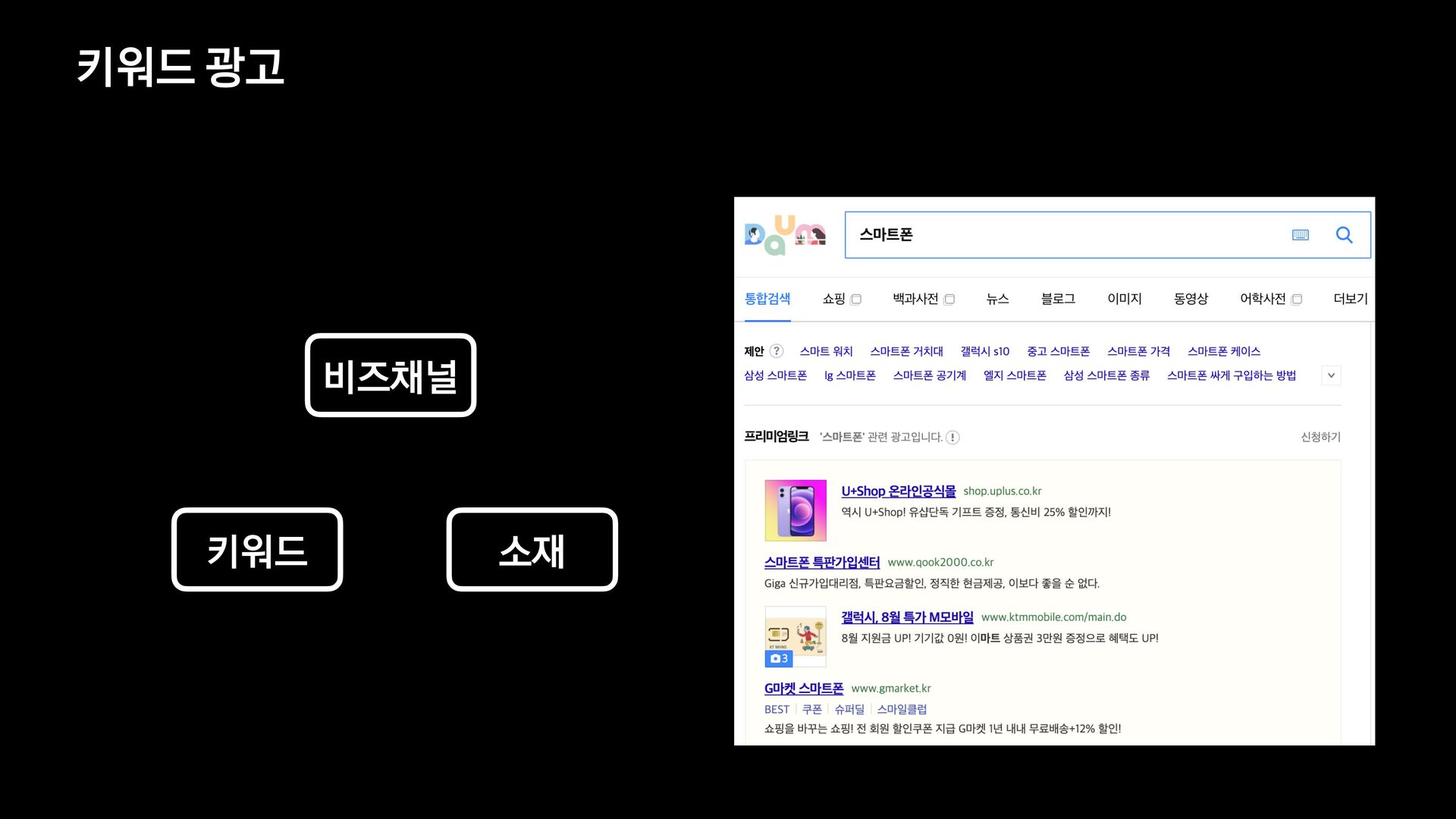
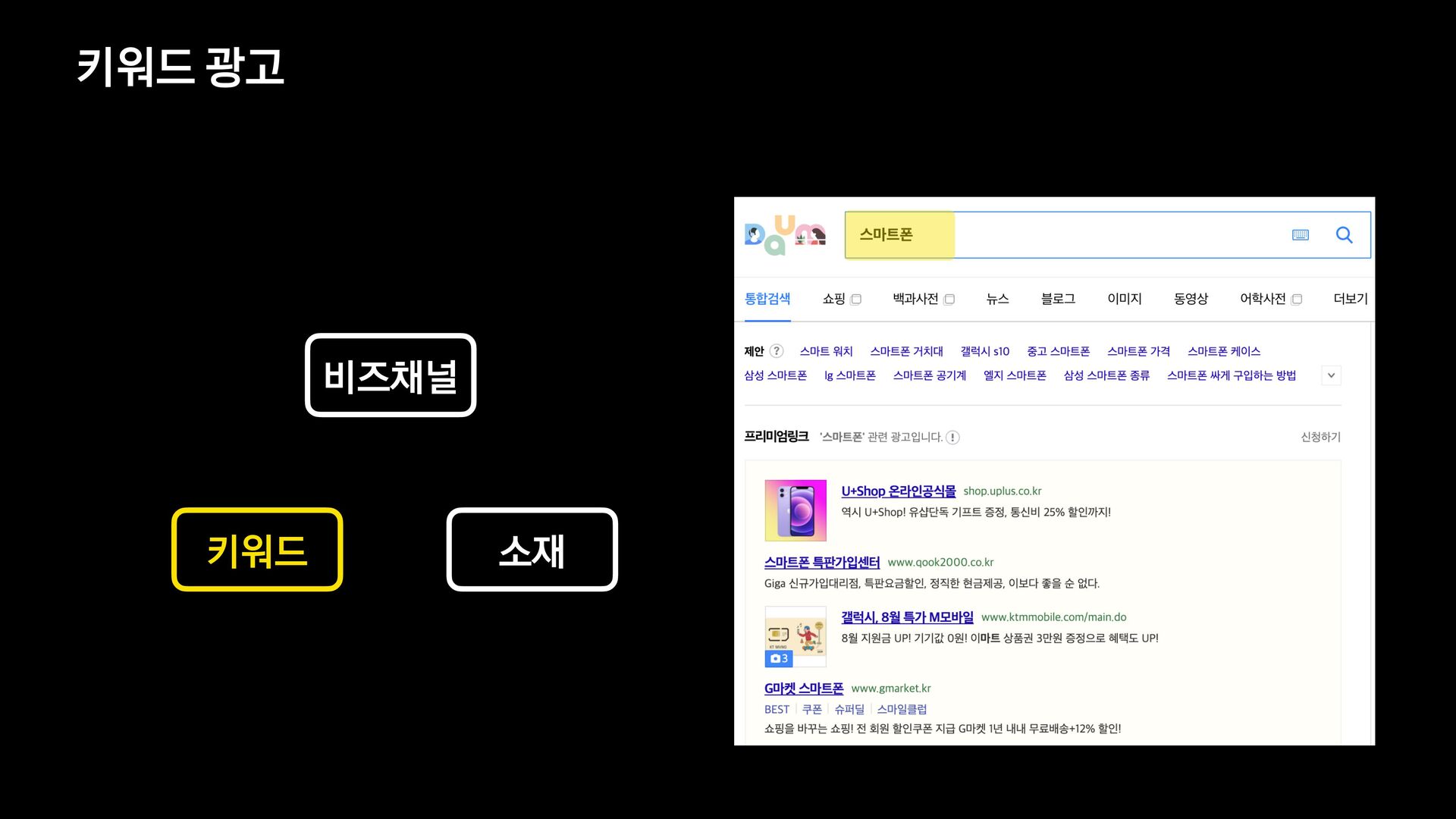
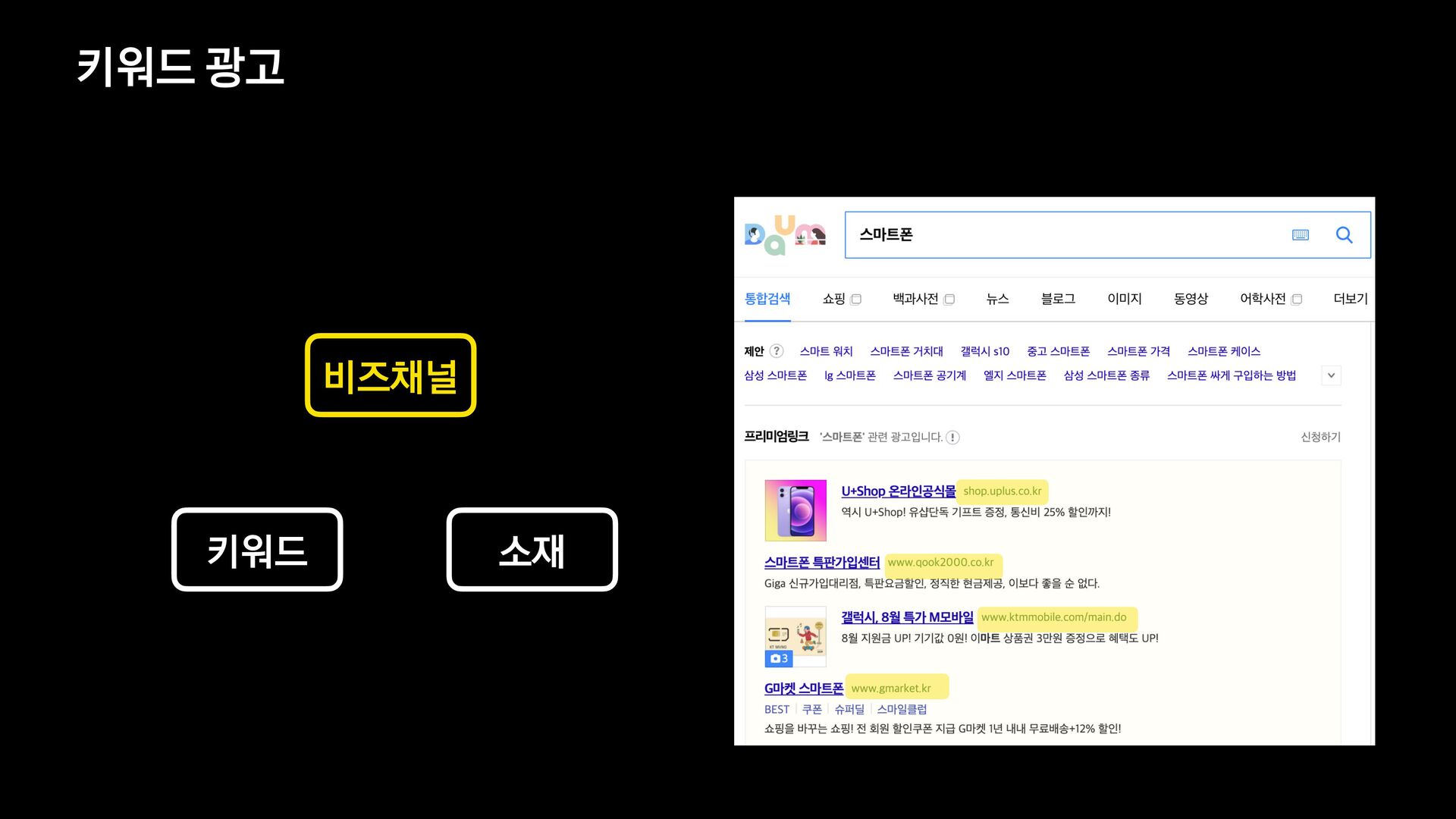
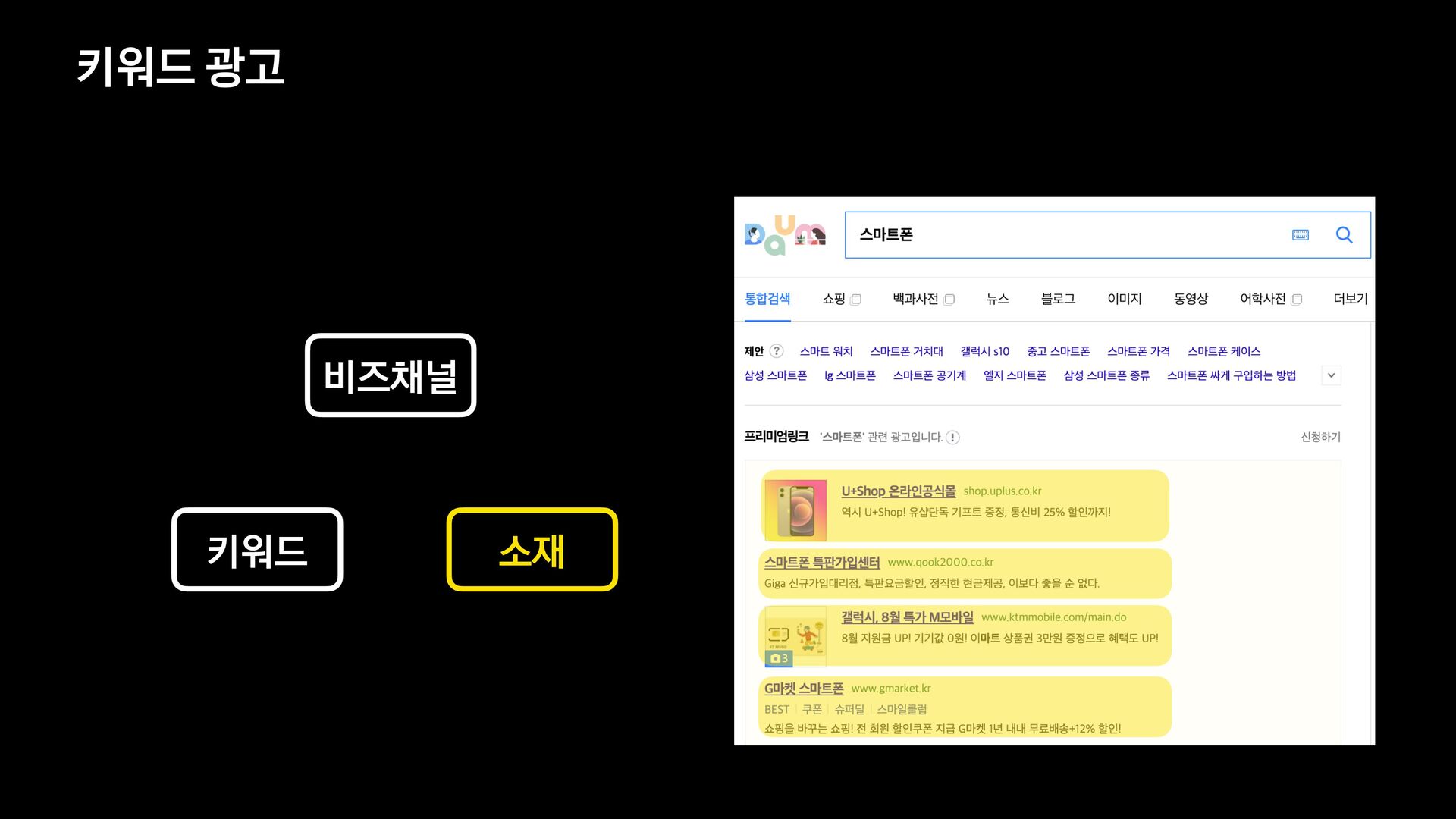
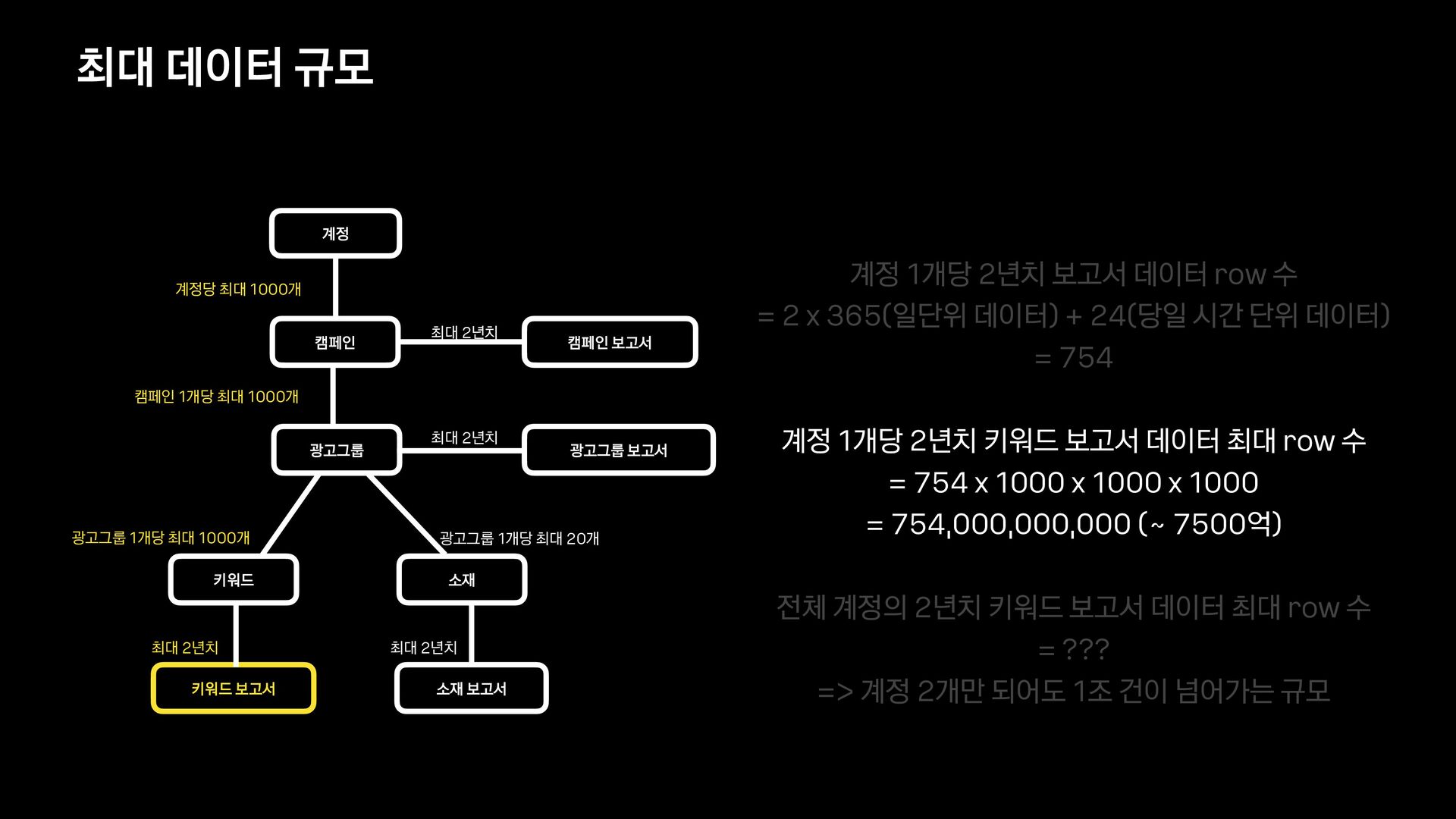
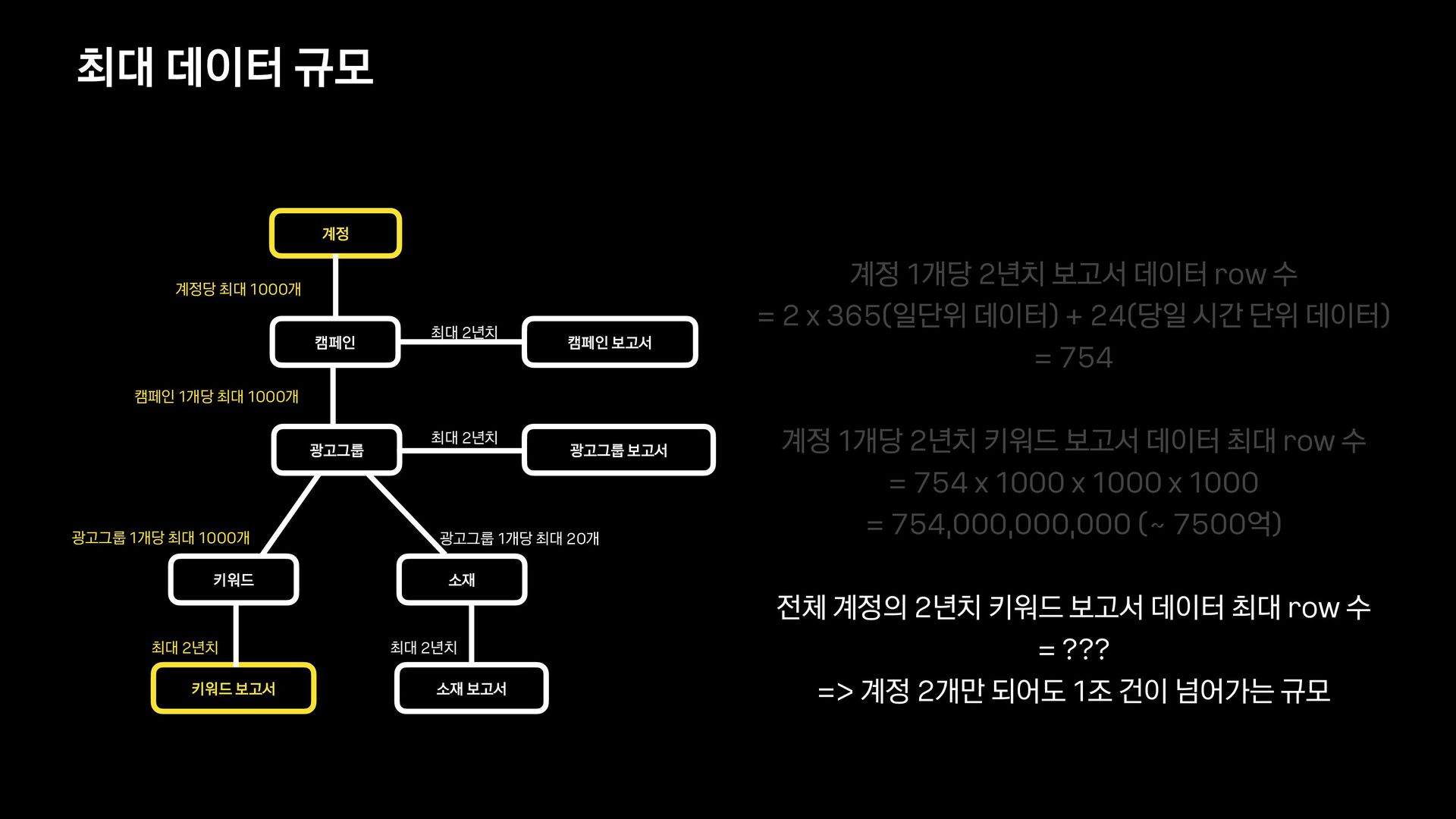
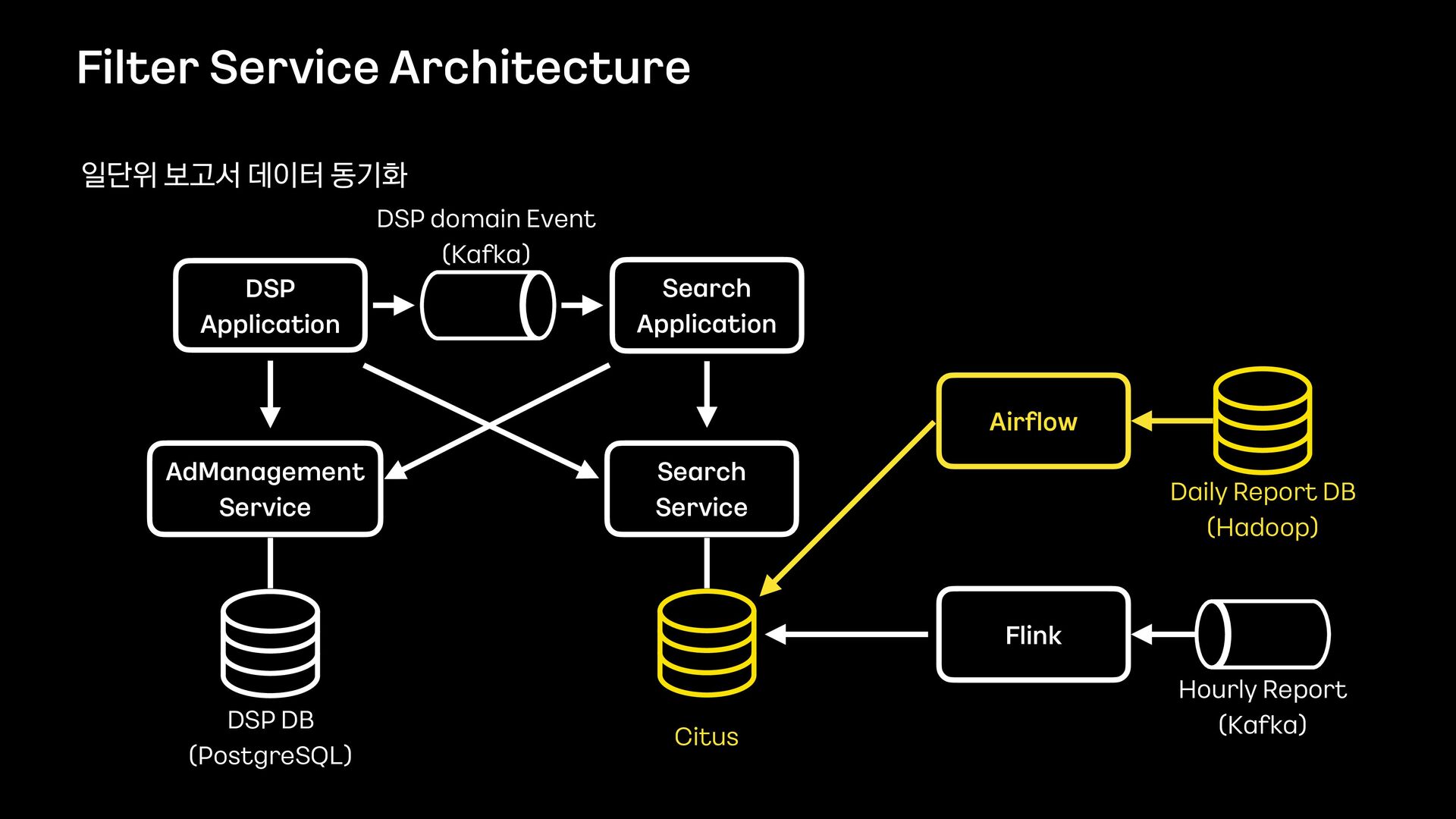
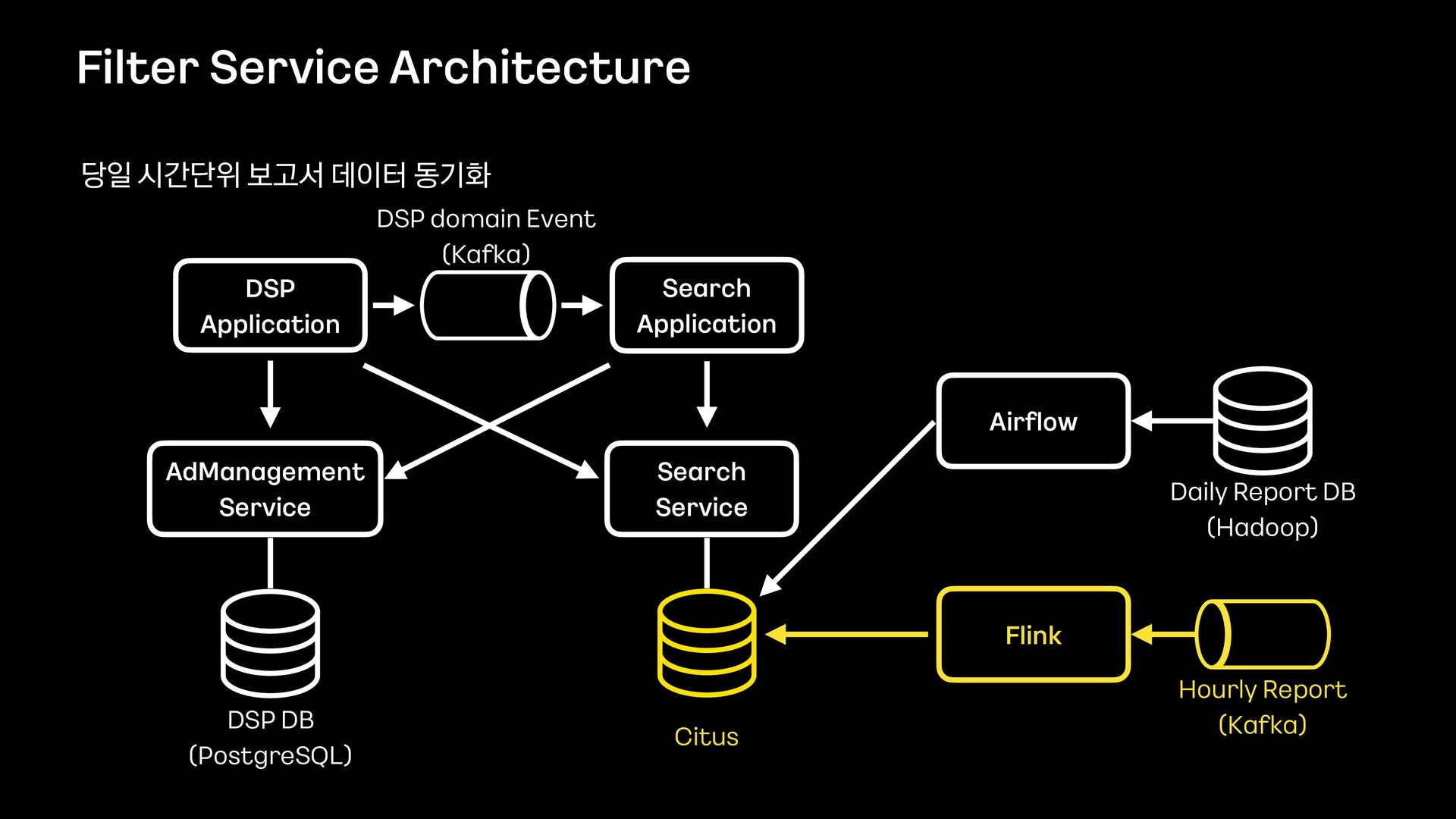
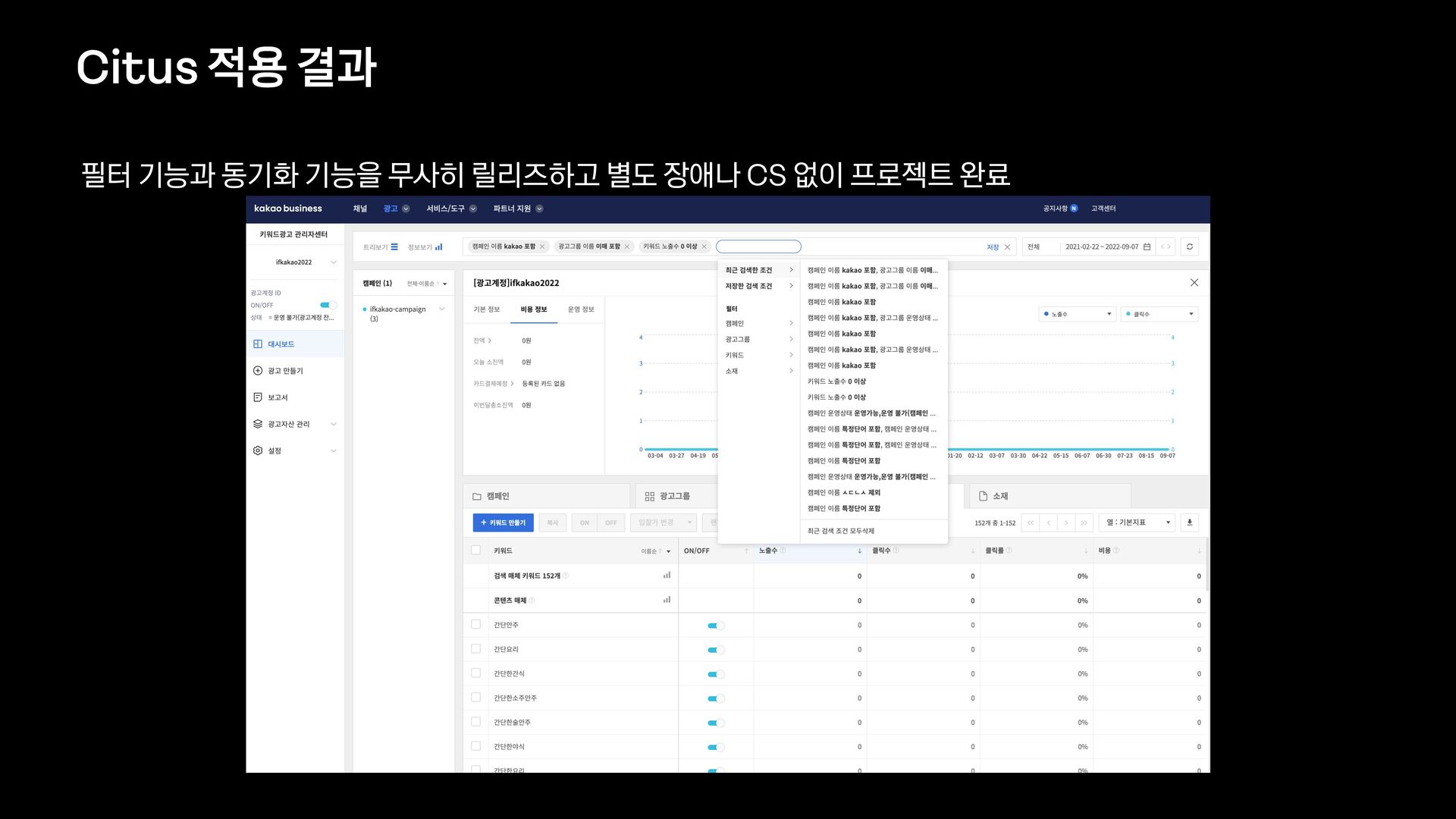
신규 키워드 광고 플랫폼을 오픈하고 나서, 대량의 광고데이터에 대해 다양한 필터 조건들을 적용하여 데이터를 보고 싶다는 요구사항이 확인되어 프로젝트를 진행하게 되었습니다.
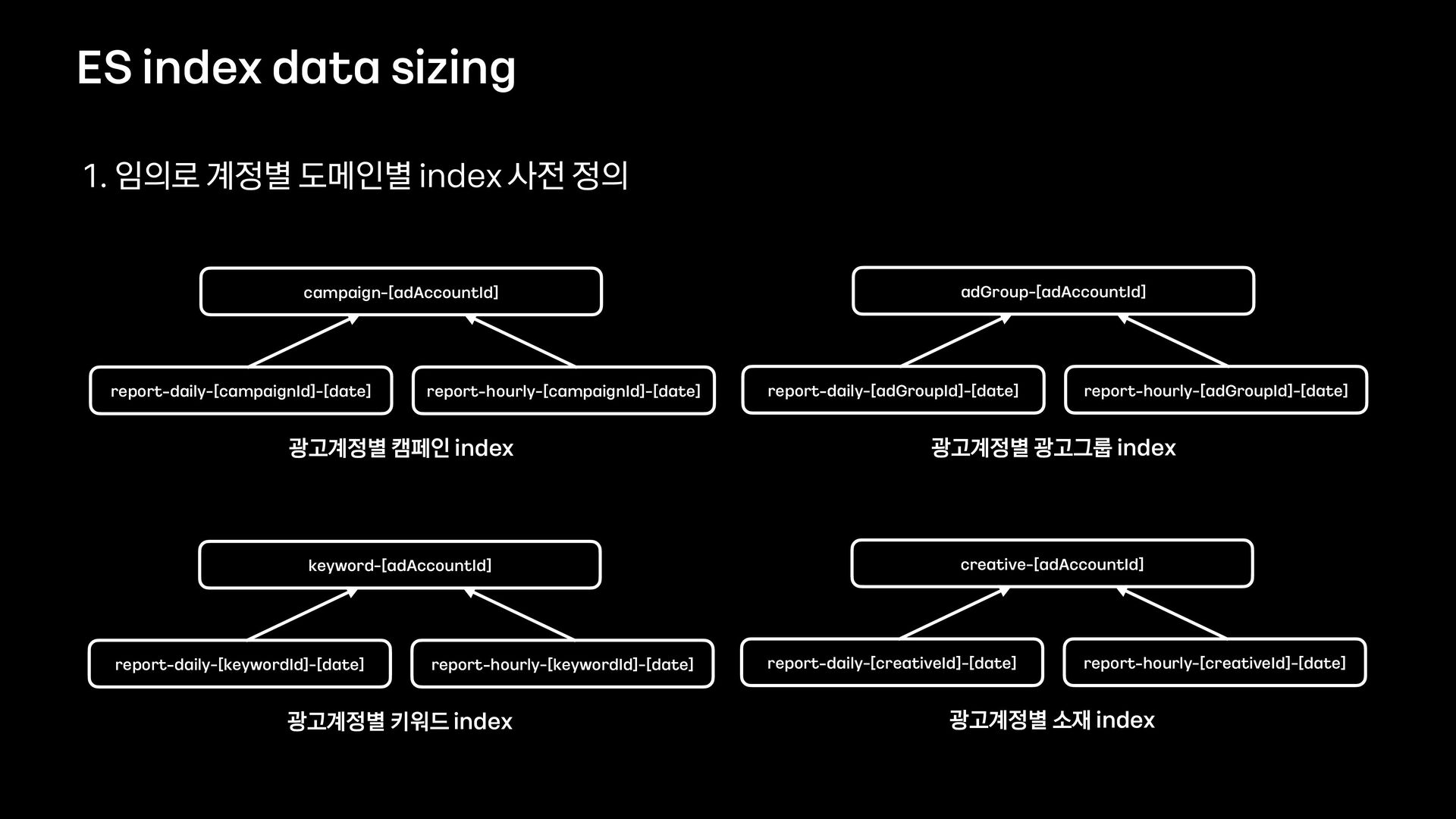
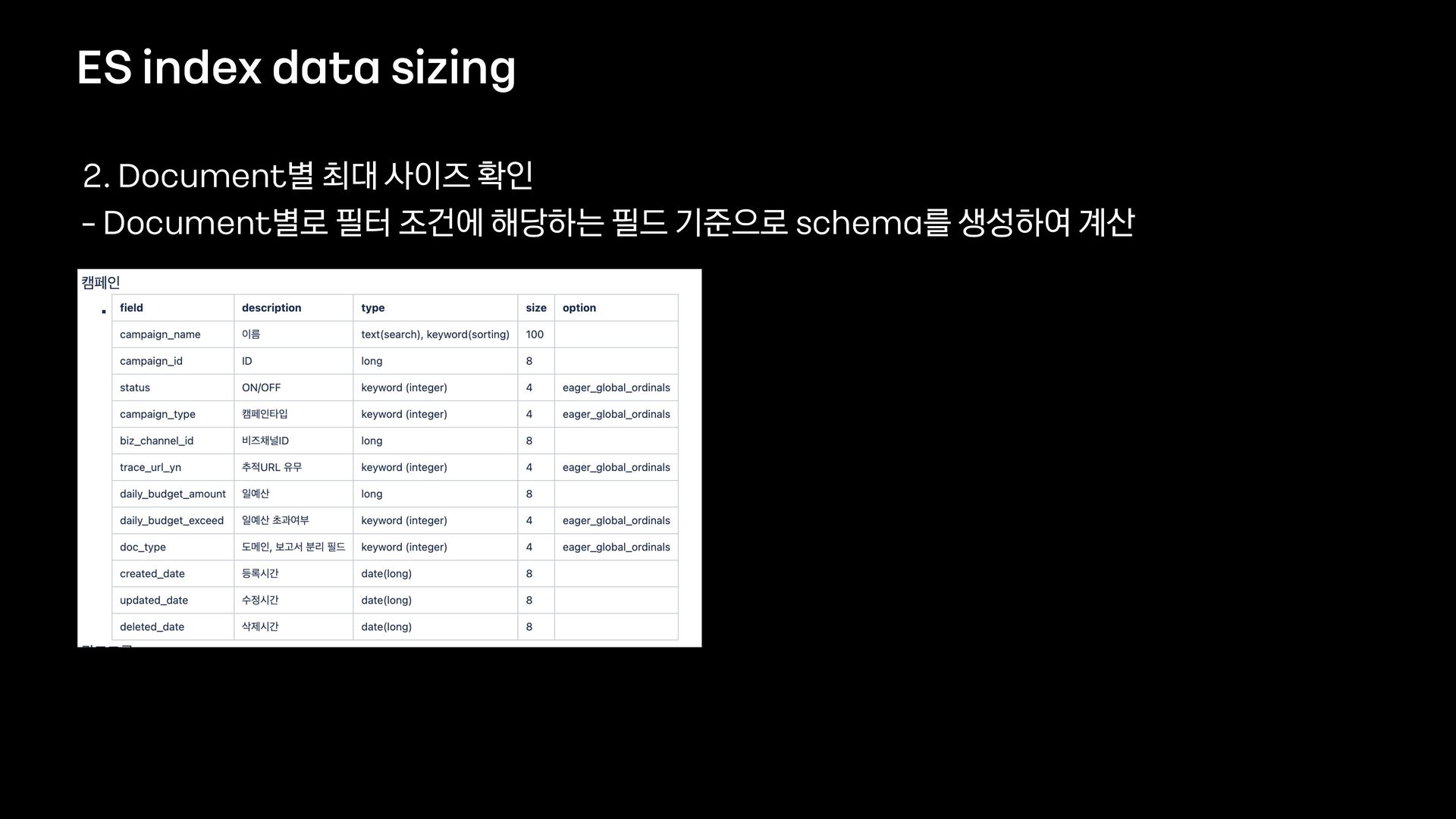
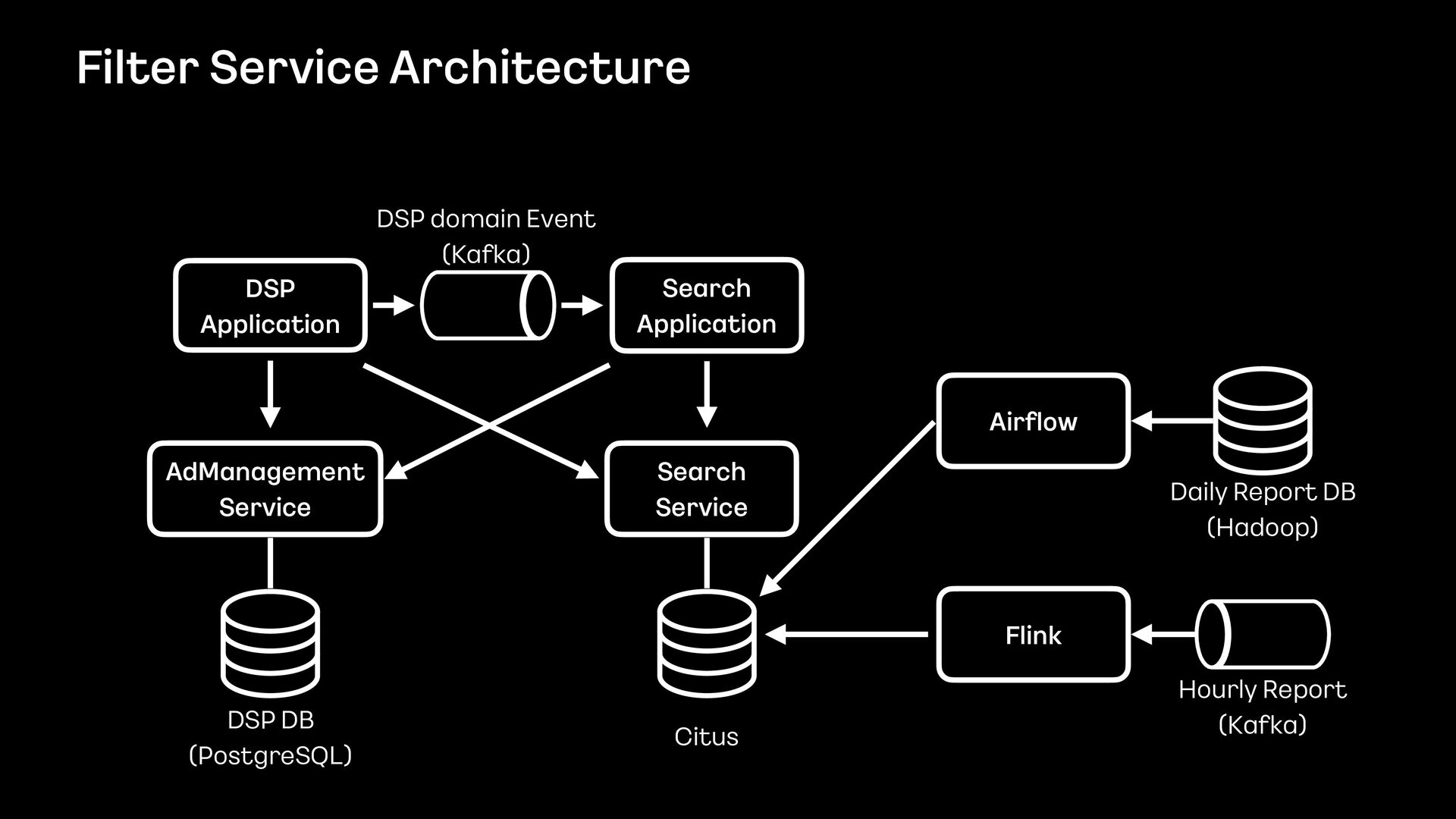
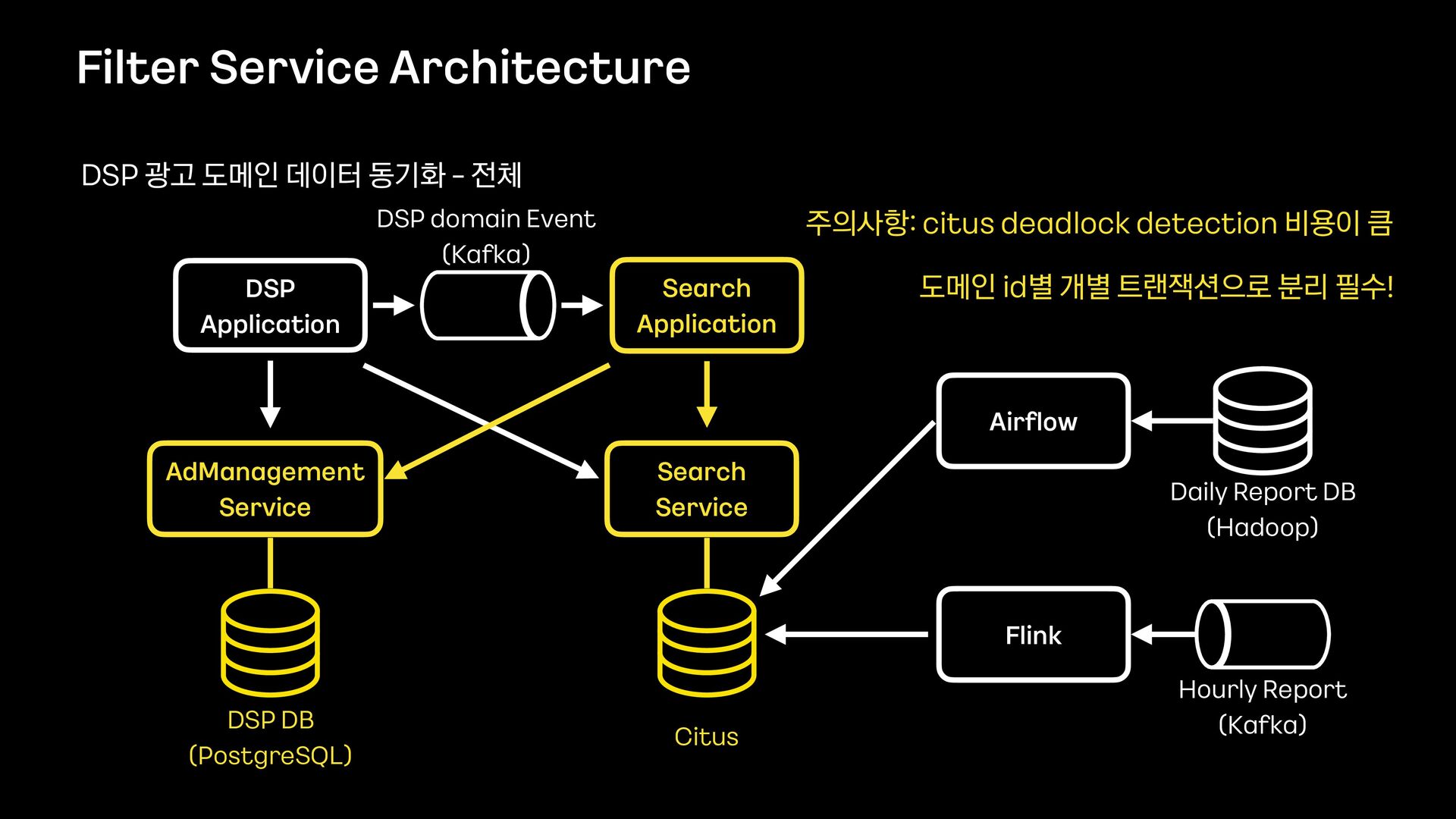
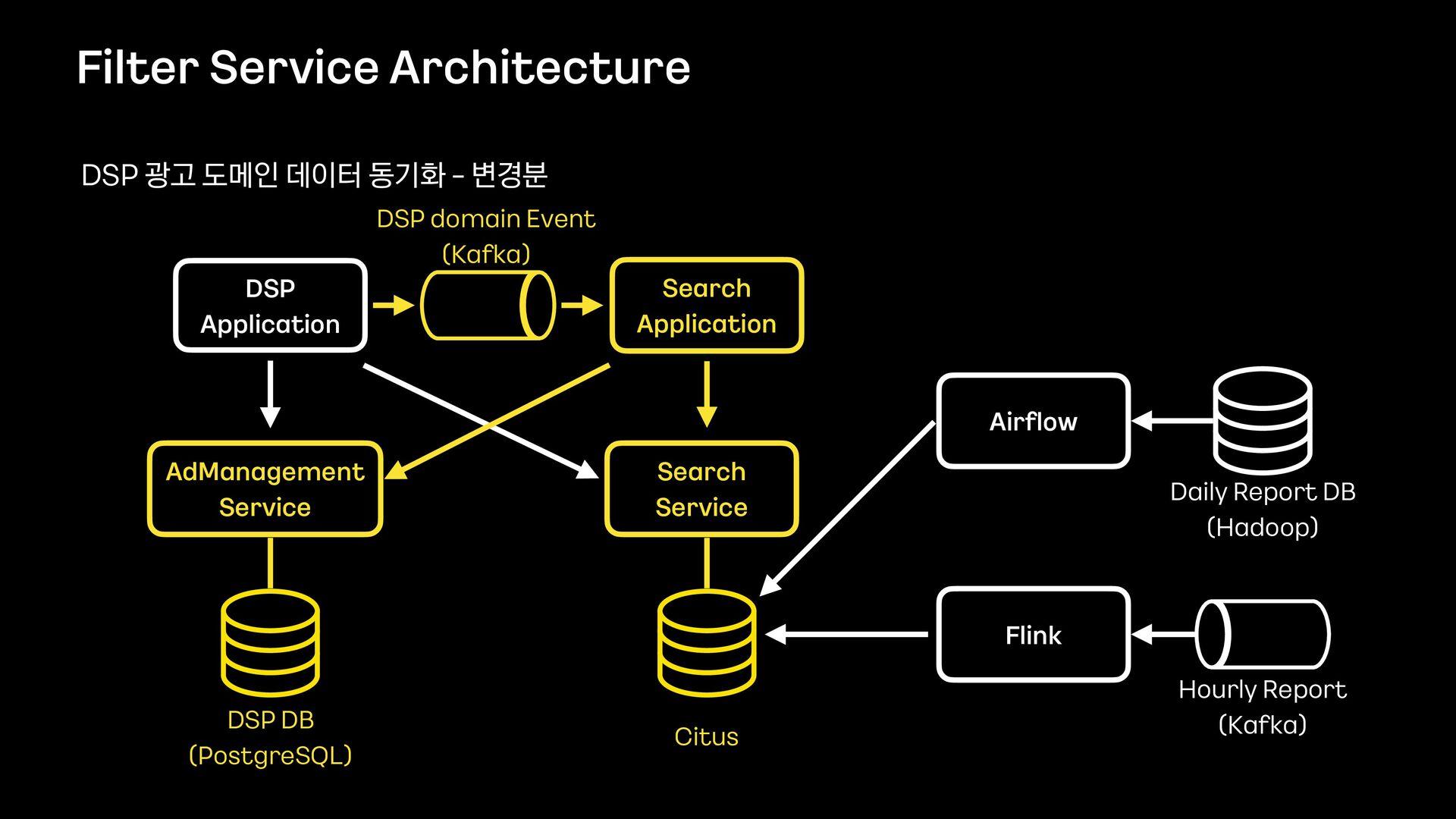
데이터의 양이 많았기 때문에 단순히 애플리케이션에서 모든 것을 처리할 수 없었고, 필터 기능을 위해 사용할 데이터 저장소부터 필터 관련 로직 설계까지 다시 고민해야 했습니다.
이번 세션을 통해서 필터 기능을 제공하기 위해 Elasticsearch를 먼저 검토했으나 결국에는 citus라는 데이터 저장소를 사용하는 것으로 결정하게 된 과정을 공유하고자 합니다.
발표자 : genos.lee
카카오 crux개발2셀에서 서버 개발을 담당하고 있는 제노스라고 합니다.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
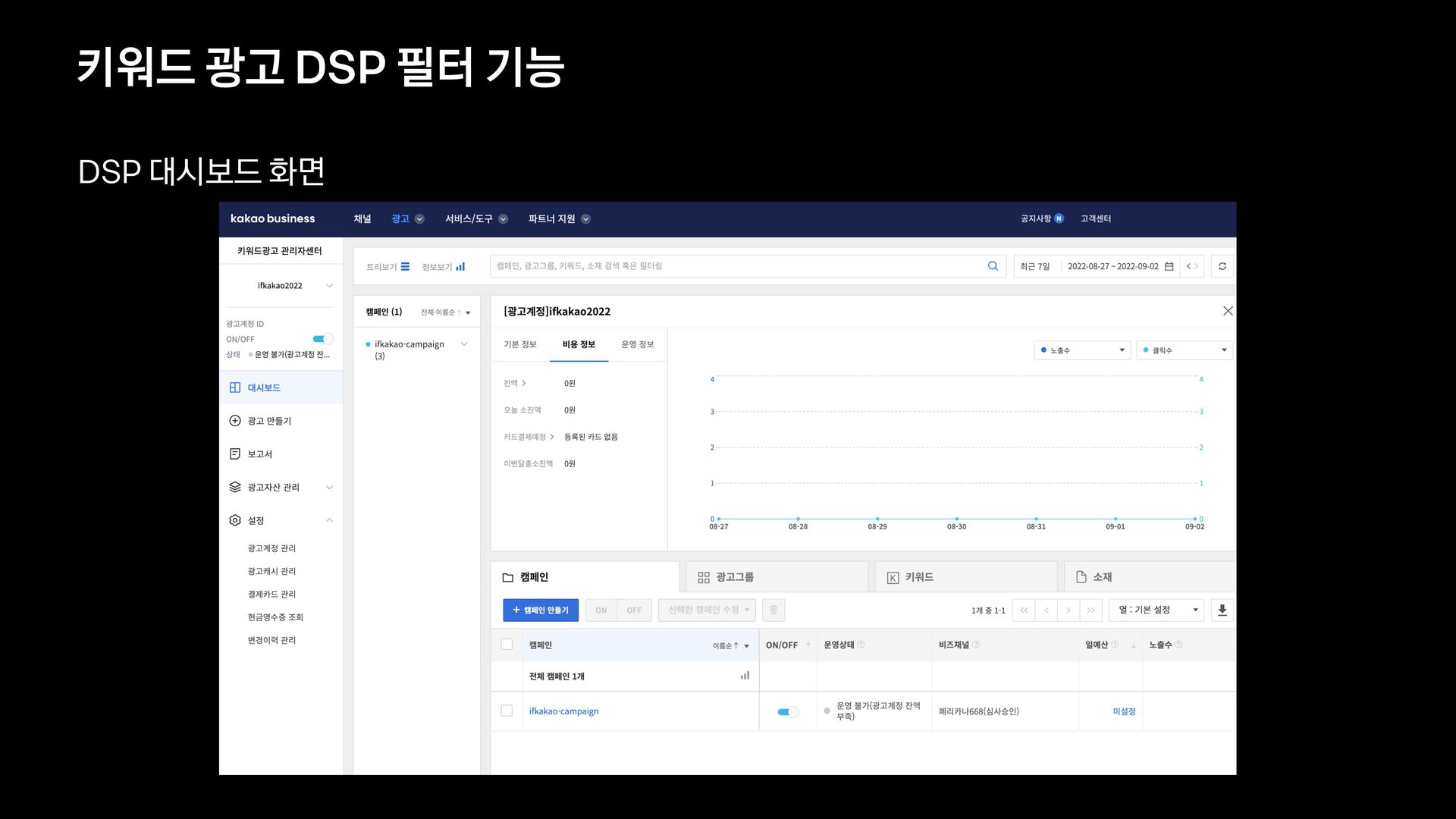{kind=link}
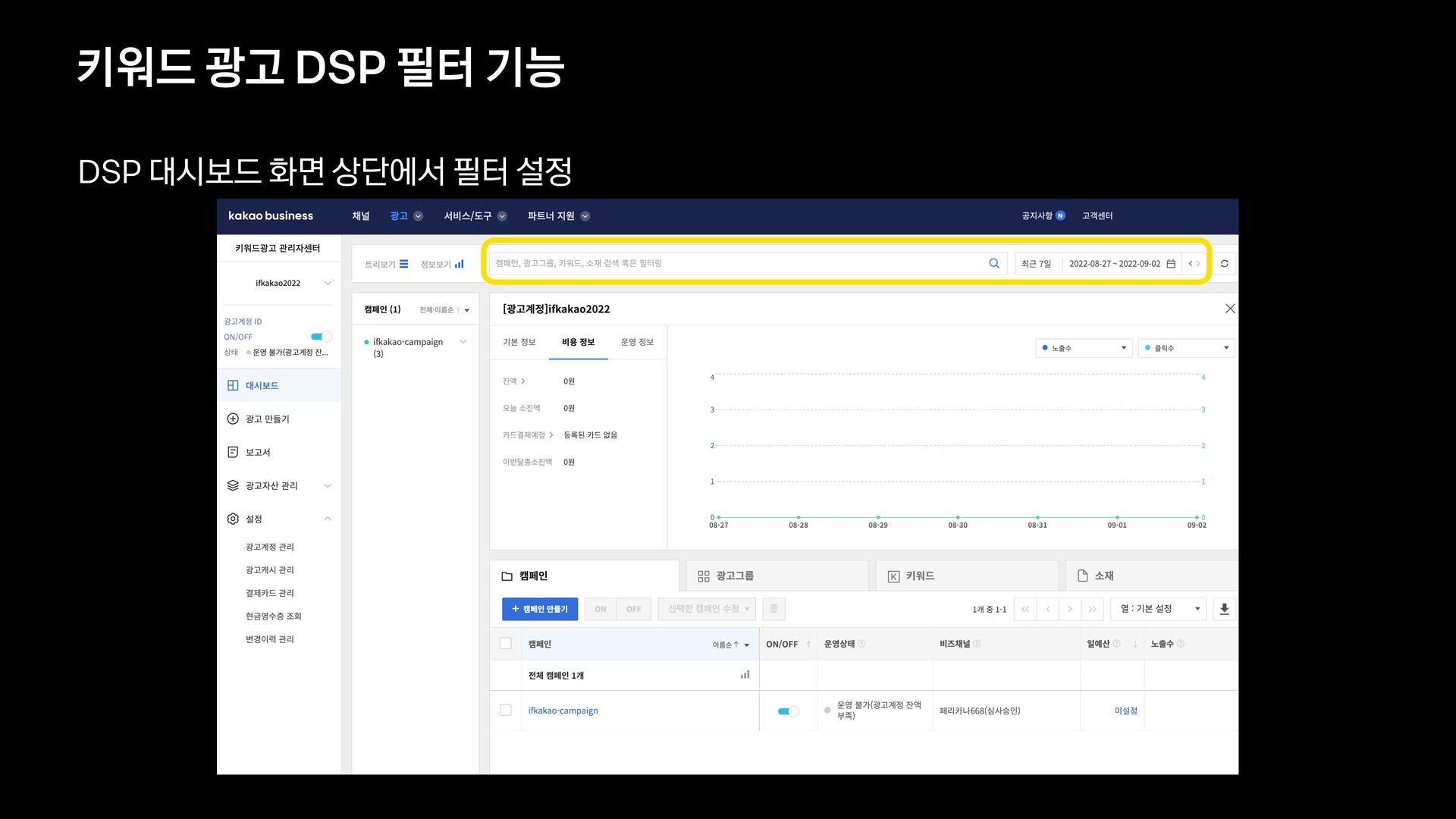{kind=link}
{kind=link}
{kind=link}
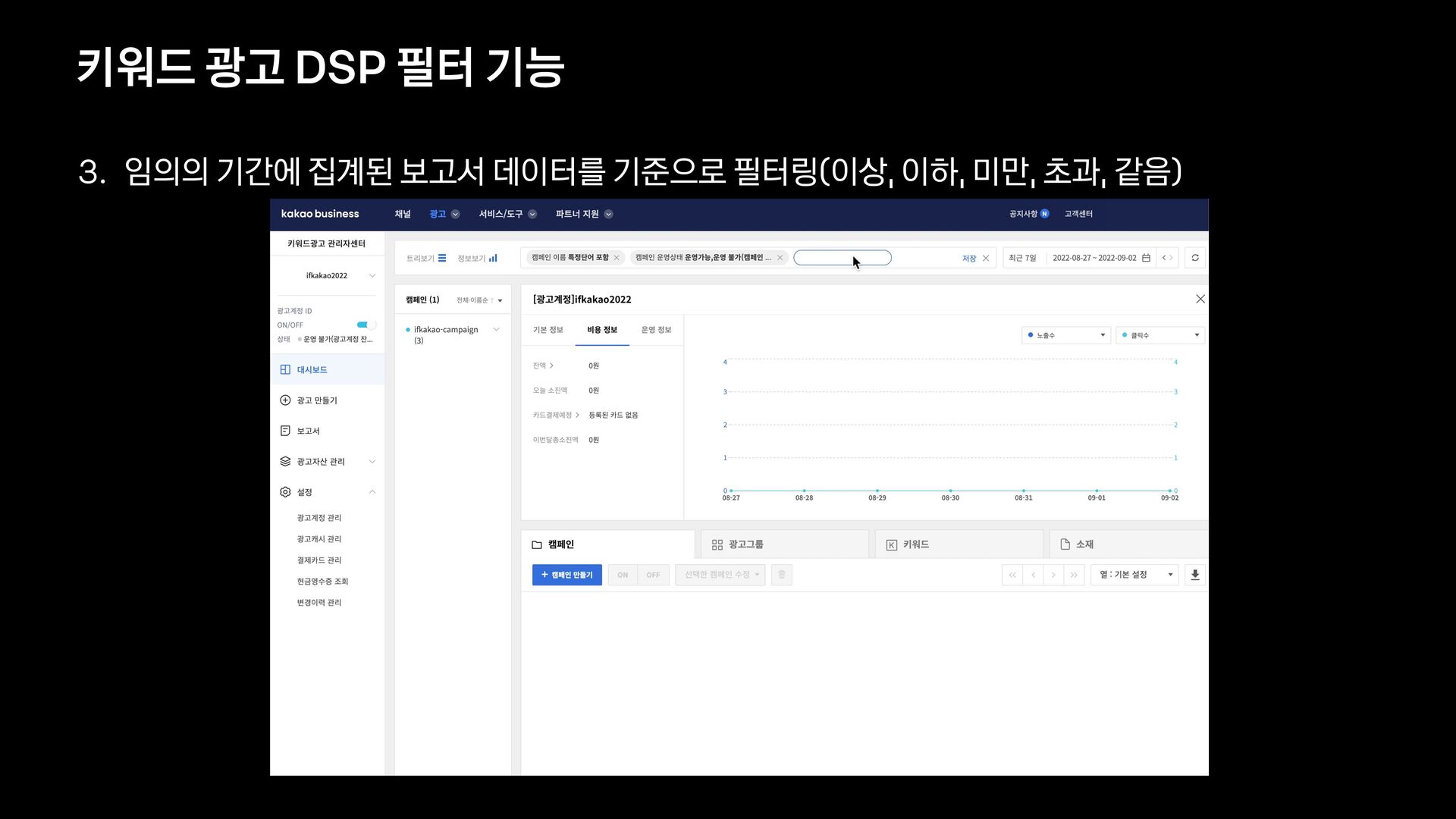{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
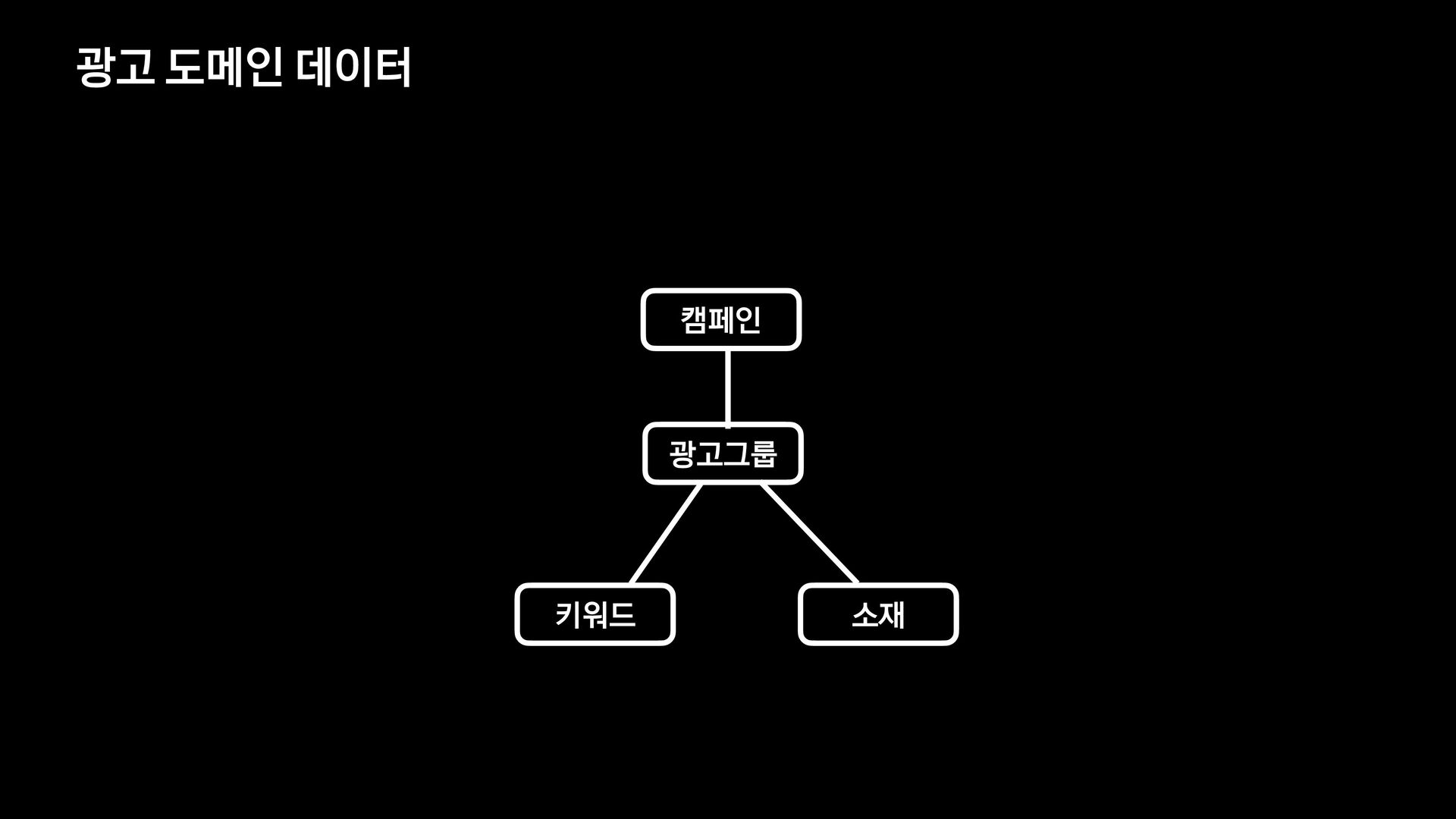{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}