#RecommenderSystem #SequentialRecommendationSystem #ML
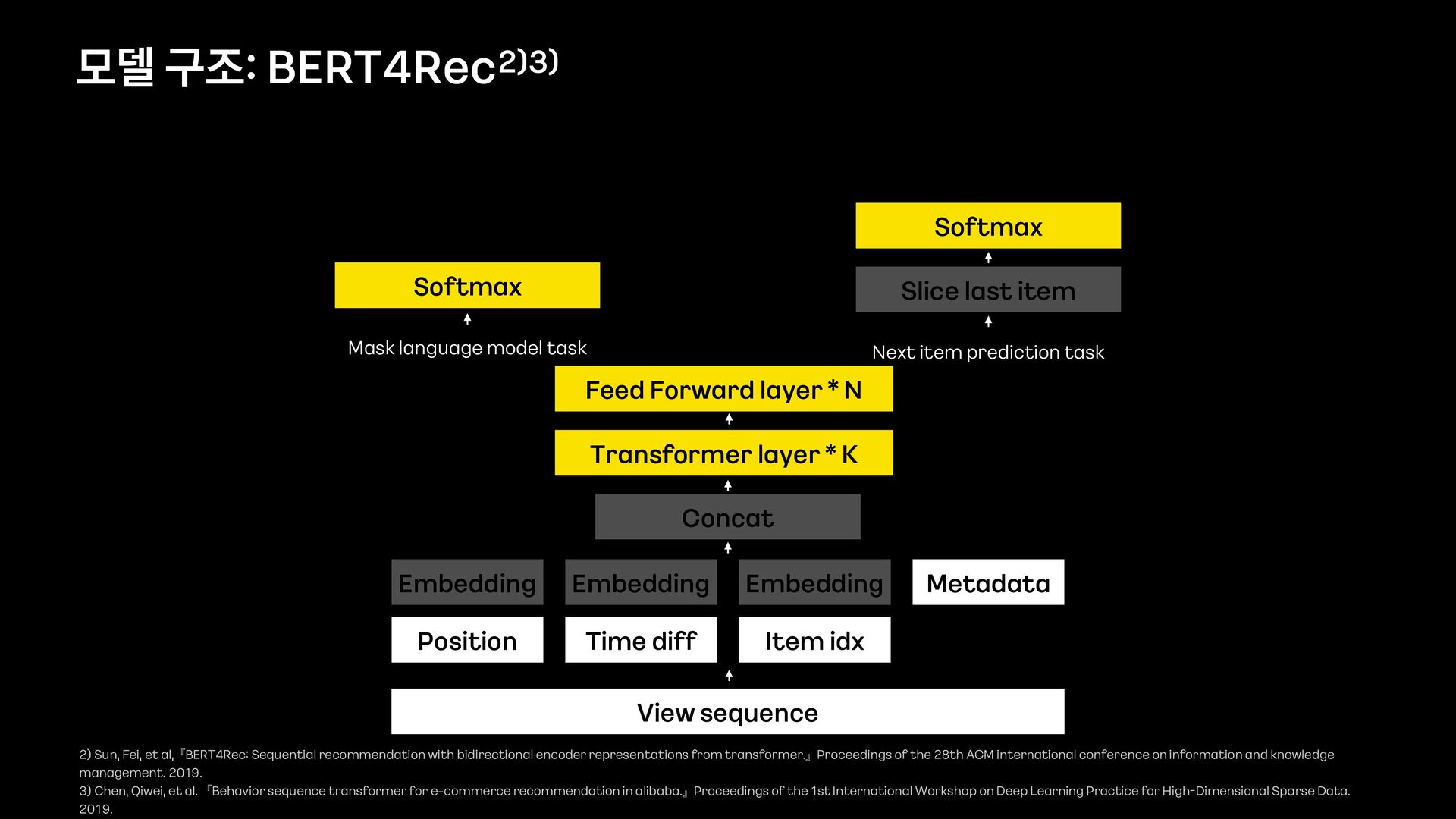
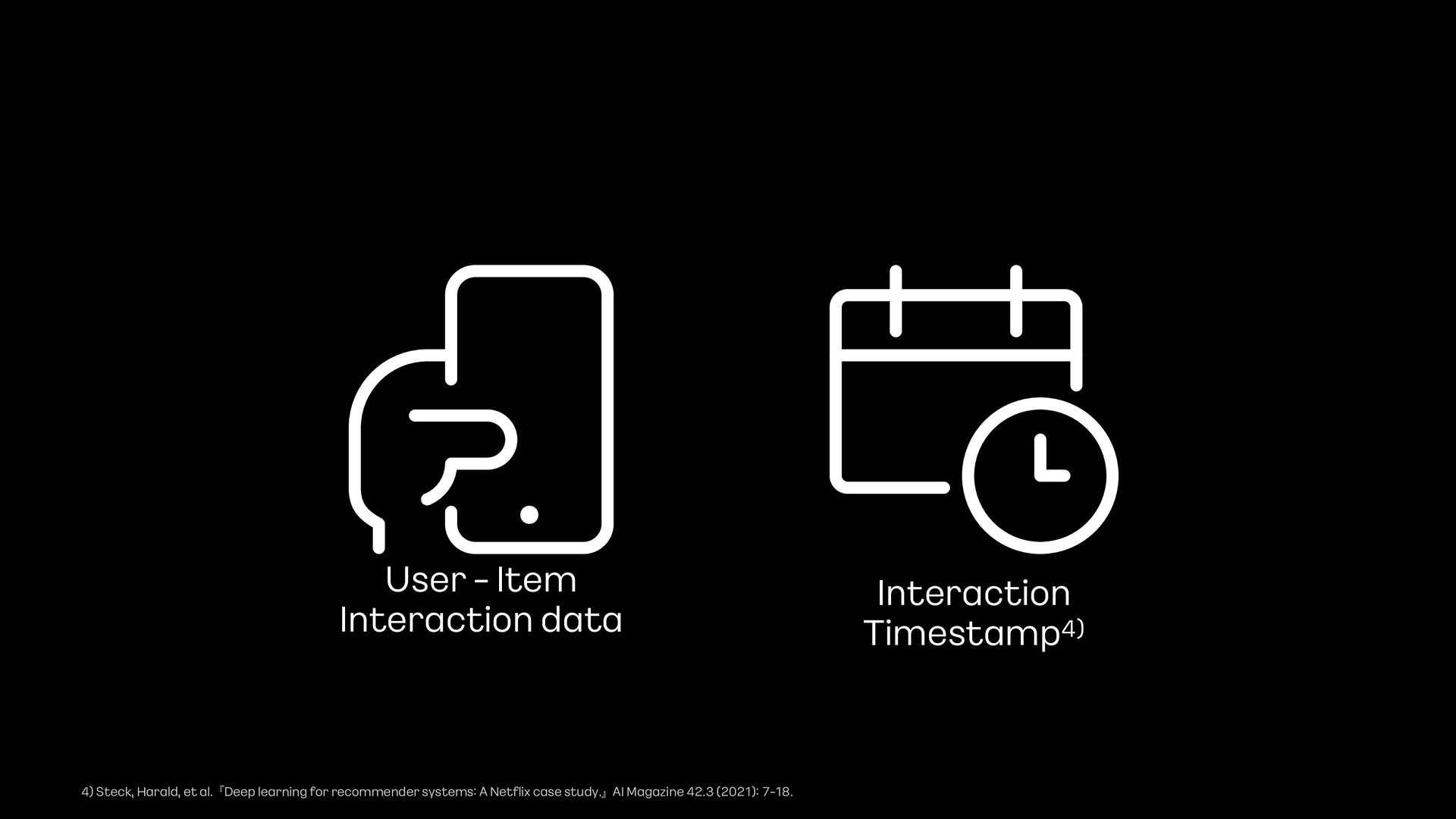
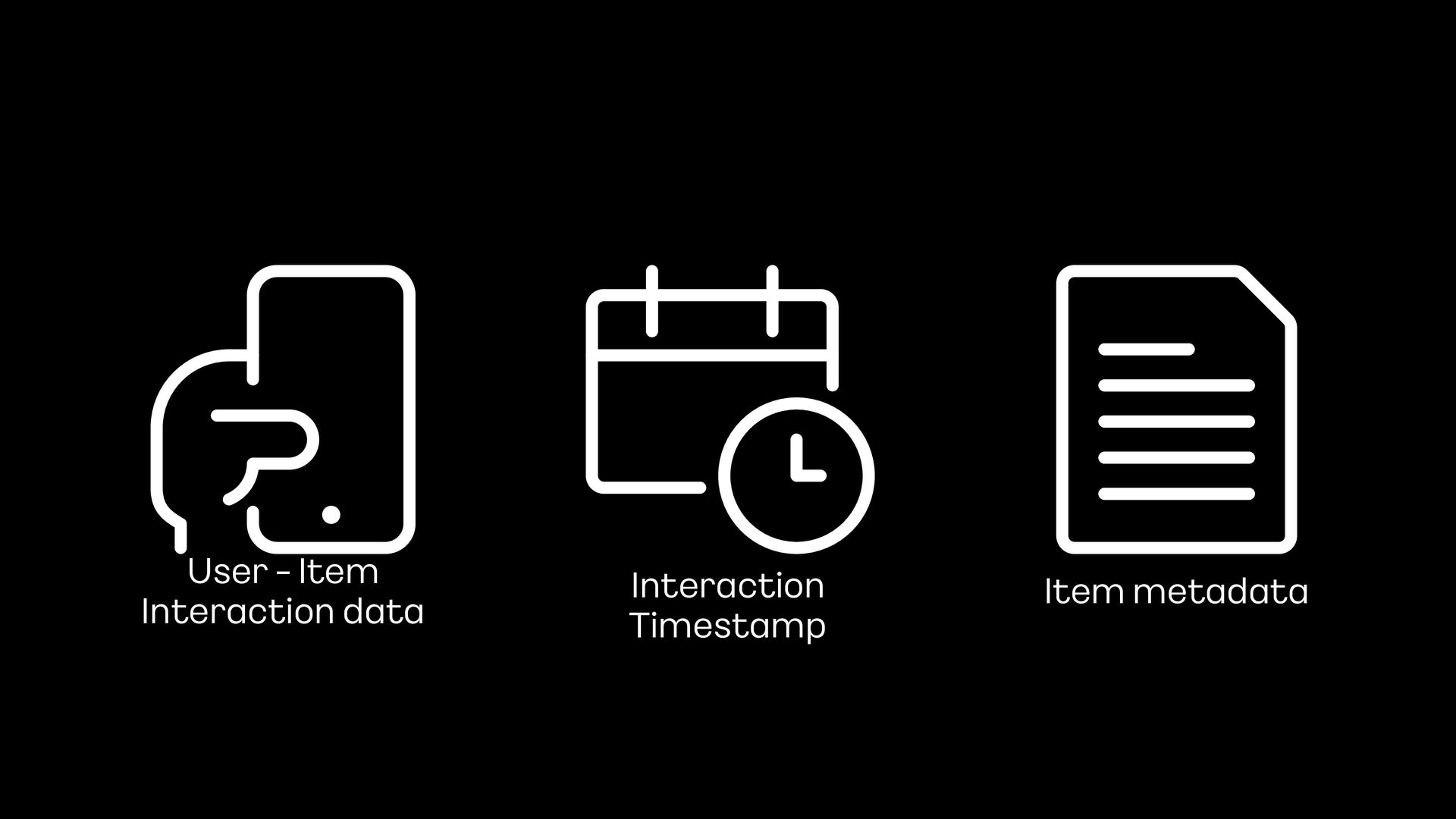
Sequential Recommendation System은 유저의 history의 순서와 시간을 보존하여 다음에 소비할 아이템을 예측하는 추천 시스템 입니다.
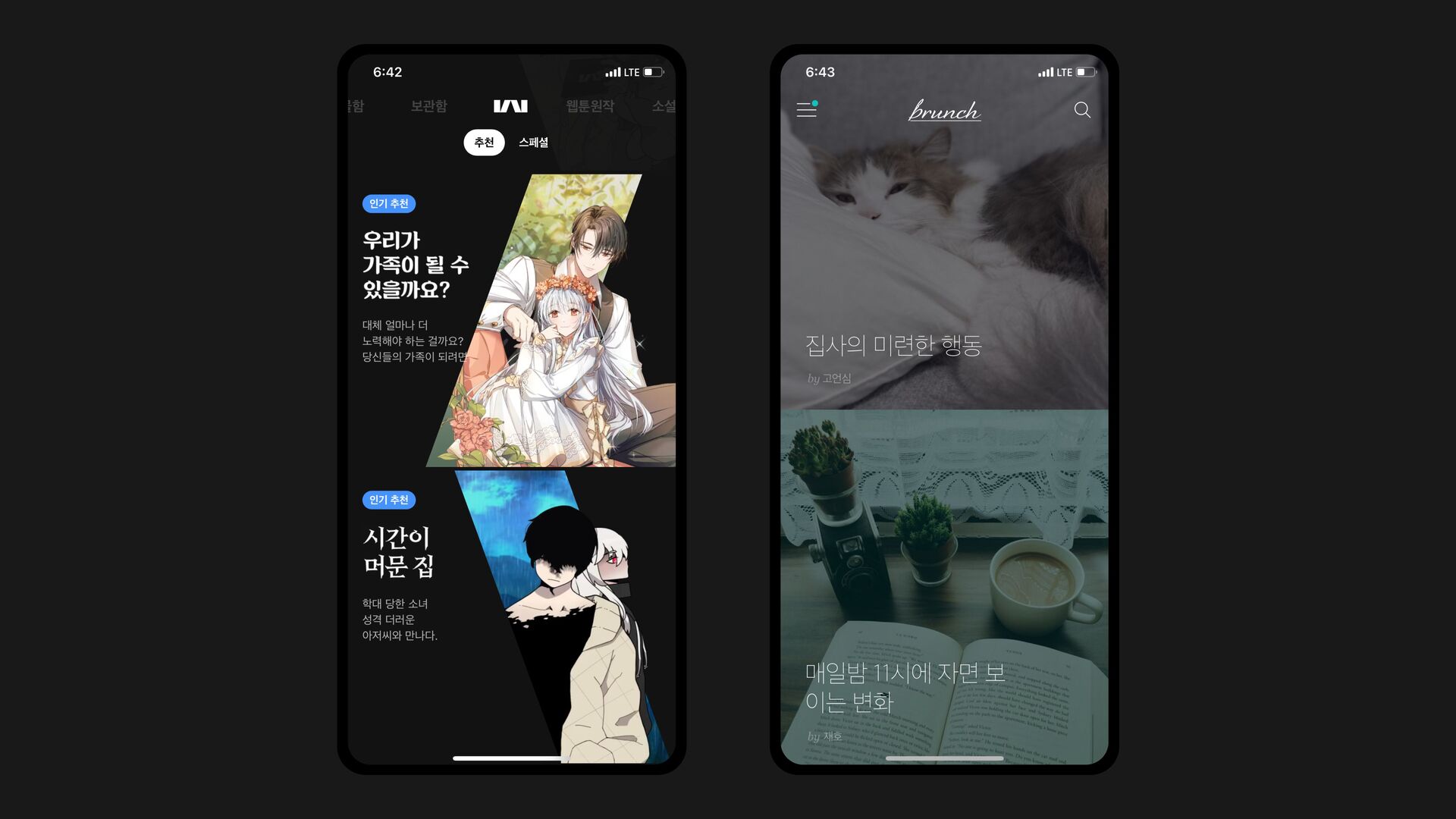
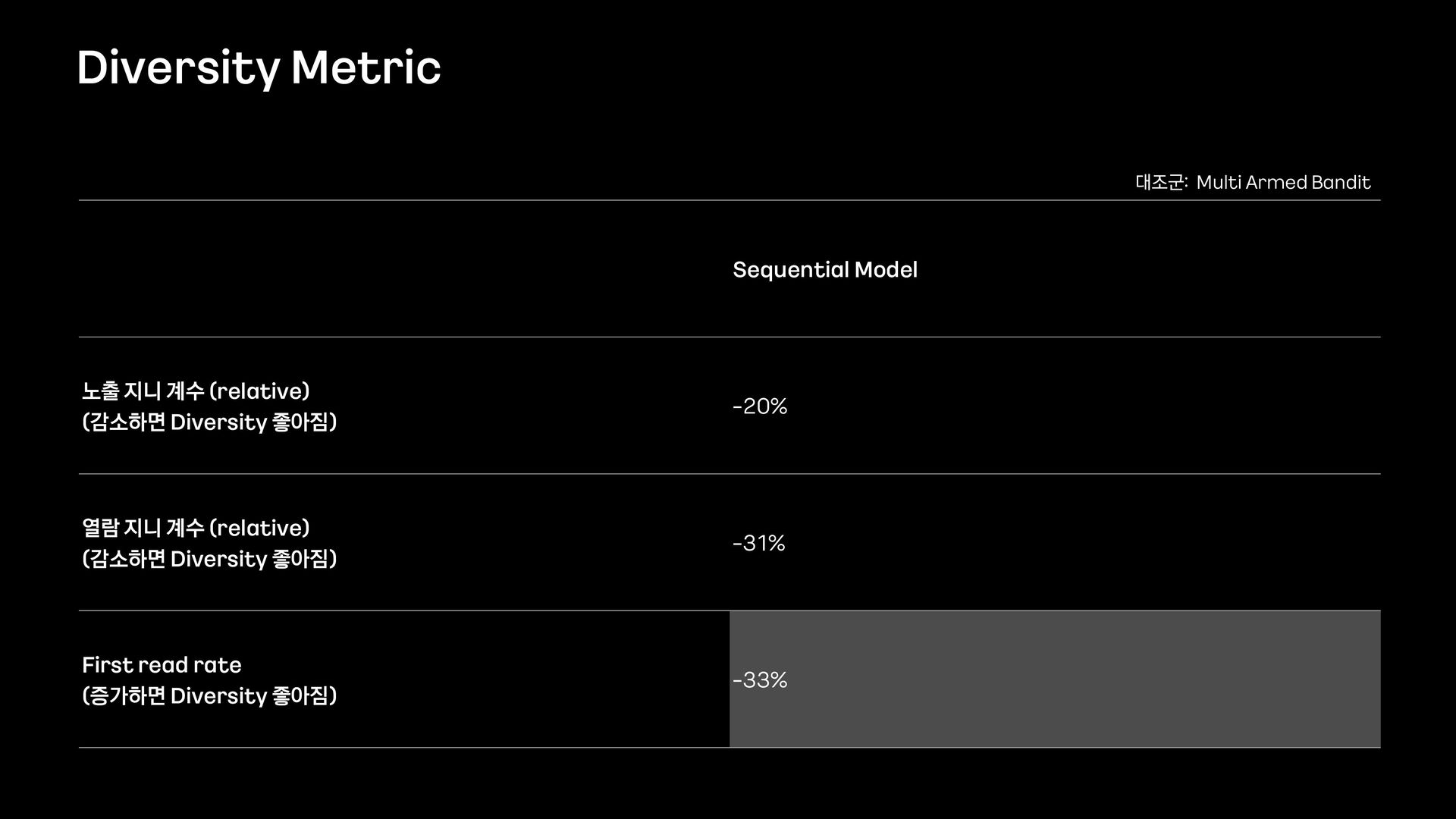
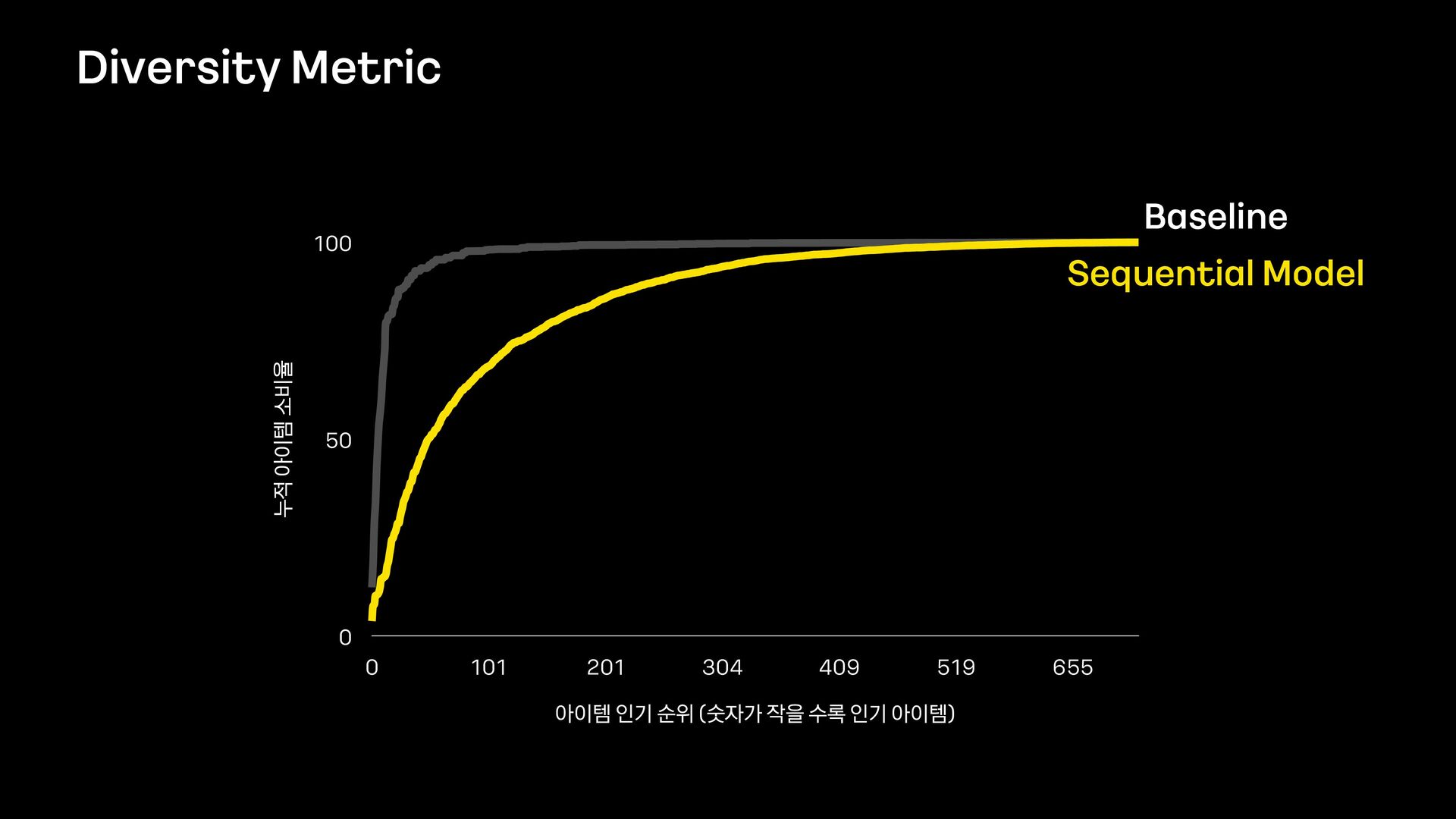
- 카카오 웹툰에 Sequential model을 적용해서 CTR, CVR, Diversity를 개선한 이야기를 해보려고 합니다.
- 카카오 웹툰 뿐만 아니라 카카오의 여러 서비스에 Sequential model을 적용해보면서 경험적으로 습득한 Sequential model이 잘 동작하는 구좌의 특성을 공유합니다.
- 또한, Sequential model의 성능을 더 끌어올리기 위해, timestamp를 적용하는 여러 실험에 대한 이야기를 추가로 해보려고 합니다.
발표자 : joel.j
카카오 추천팀에서 추천 시스템 연구/개발중인 Joel입니다.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}