paradigm inspired by biological nervous systems, such as our brain Structure: large number of highly interconnected processing elements (neurons) working together Like people, they learn from experience (by example)
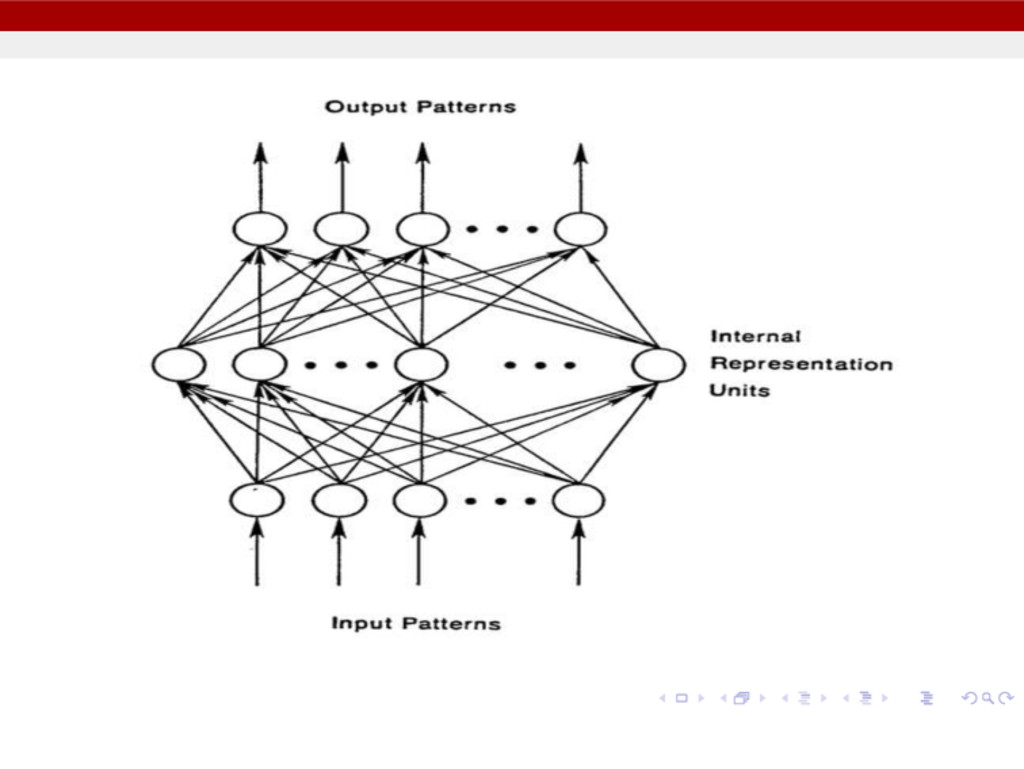
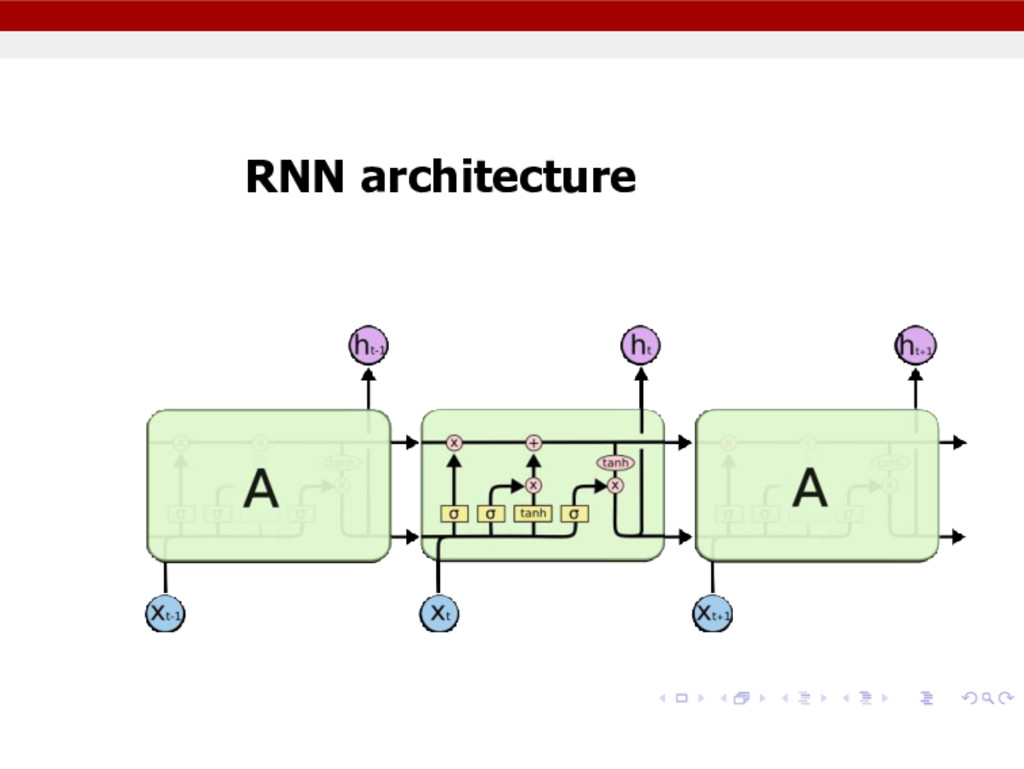
units represents the raw information that is fed into the network. Hidden Layer - The activity of each hidden unit is determined by the activities of the input units and the weights on the connections between the input and the hidden units. Output Layer - The behavior of the output units depends on the activity of the hidden units and the weights between the hidden and output units.
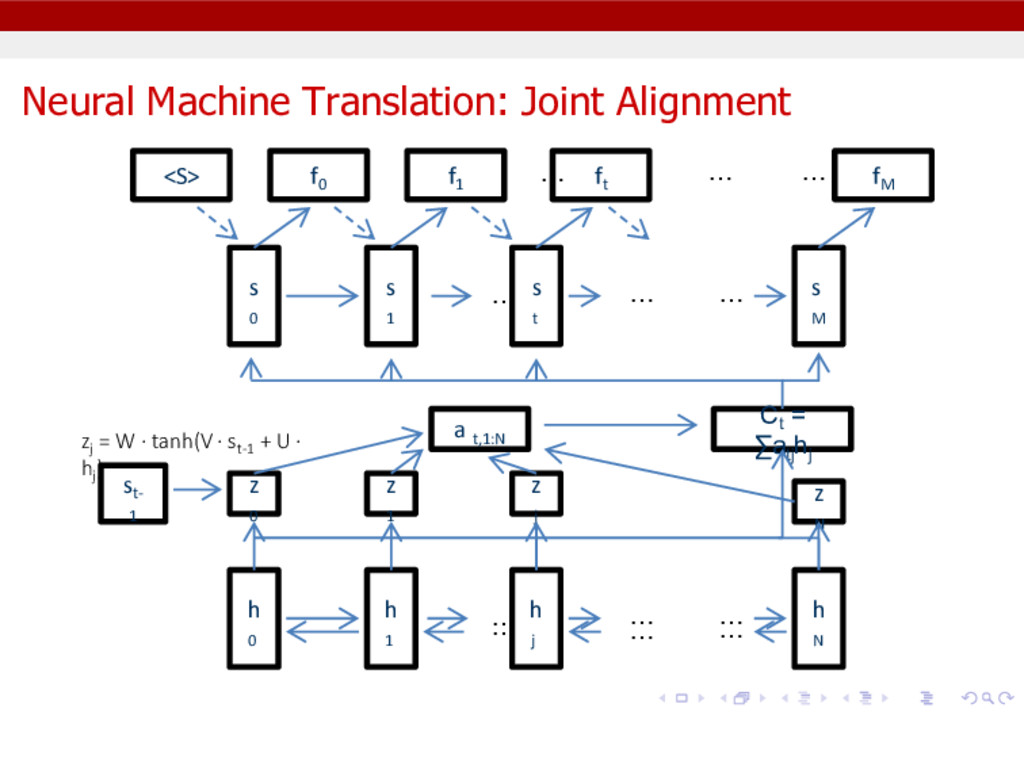
probability P(F|E) Equivalent to P(fn , fn-1 , …, f0 | em , em-1 , …, e0 ) -> a sequence conditioned on another sequence. Create an RNN architecture where the output of on RNN (decoder) is conditioned on another RNN (encoder). We can connect them using a joint alignment and translation mechanism. Results in a single gestalt Machine Translation model which can generate candidate translations.
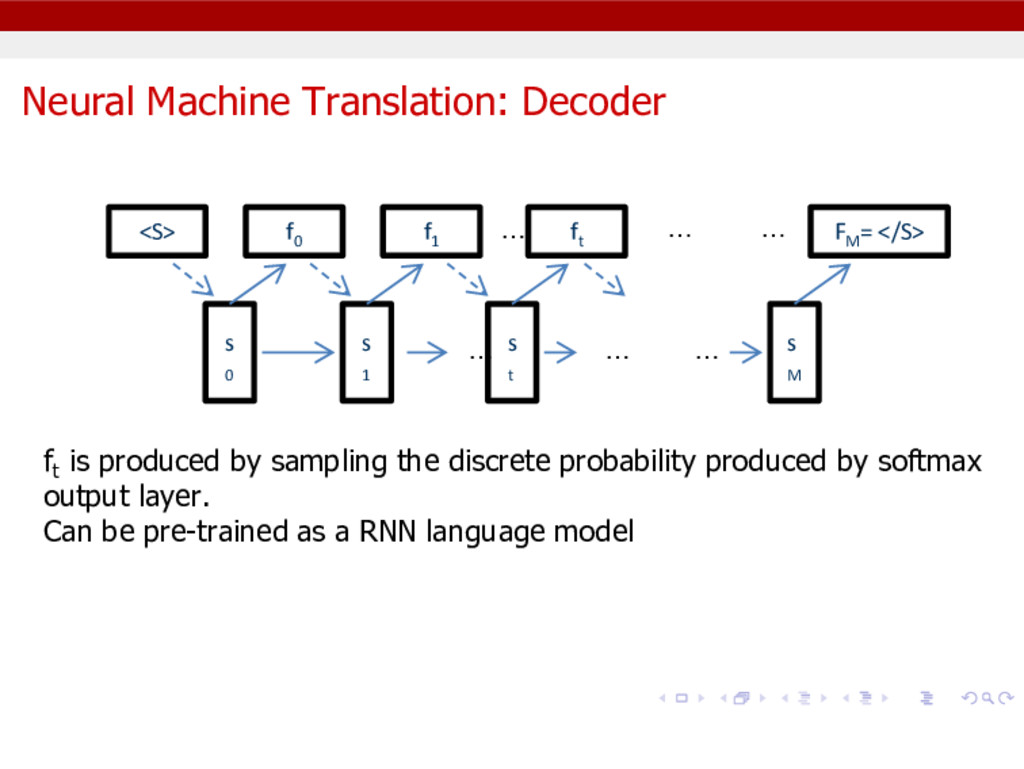
s M … … f0 f1 ft FM = </S> … … … … <S> ft is produced by sampling the discrete probability produced by softmax output layer. Can be pre-trained as a RNN language model
cross-entropy error function. Encoder and Decoder learn to represent source and target sentences in a compact, distributed manner Does not make conditional independence assumptions to separate out translation model, alignment model, re-ordering model, etc… Does not pre-align words by bootstrapping from simpler models. Learns translation and joint alignment in a semantic space, not over surface forms. Conceptually easy to decode – complexity similar to speech processing, not SMT. Fewer Parameters – more memory efficient.
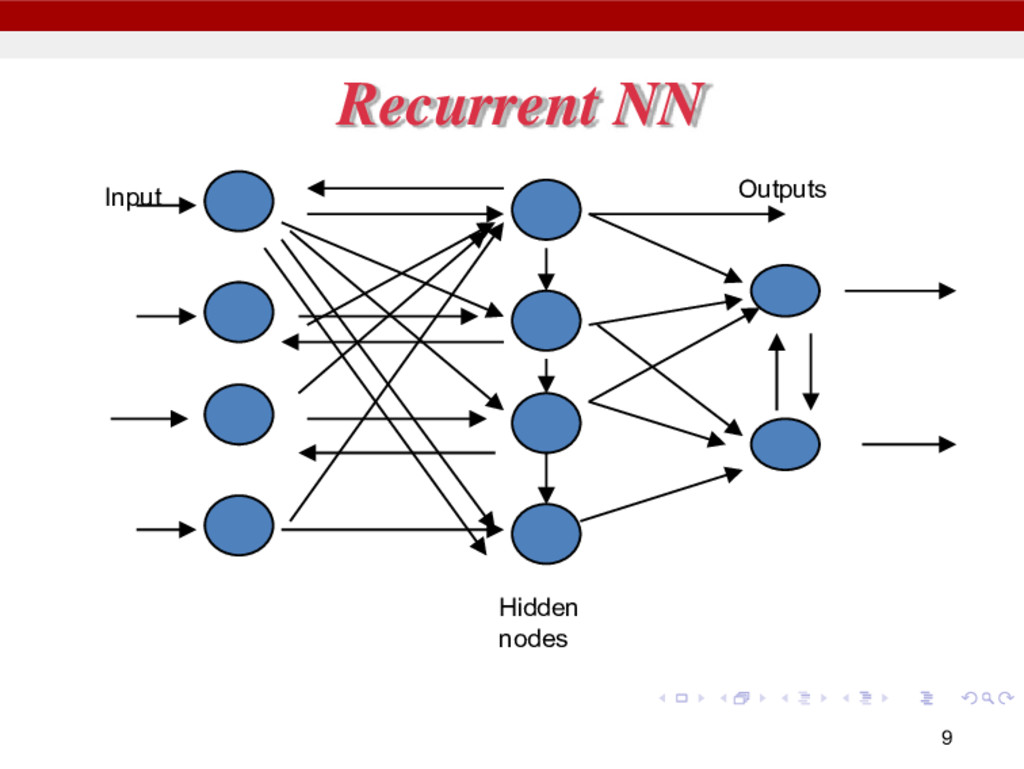
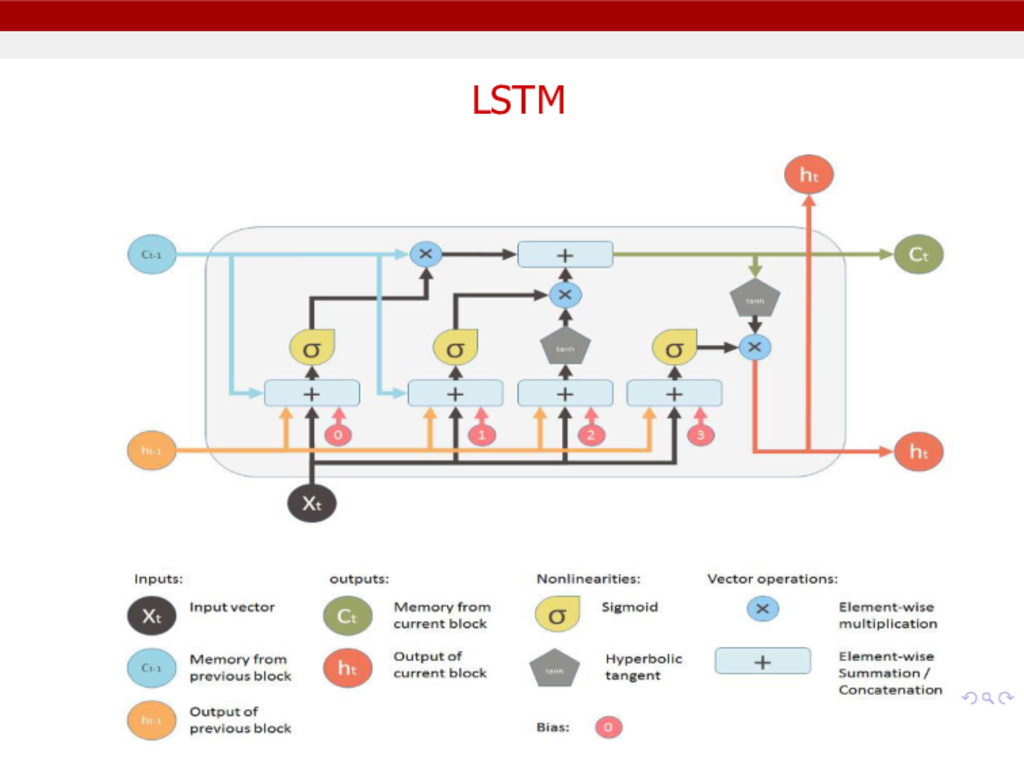
it from an usual neuron in a recurrent neural network. 1. It has control on deciding when to let the input enter the neuron. 2. It has control on deciding when to remember what was computed in the previous time step. 3. It has control on deciding when to let the output pass on to the next time stamp.
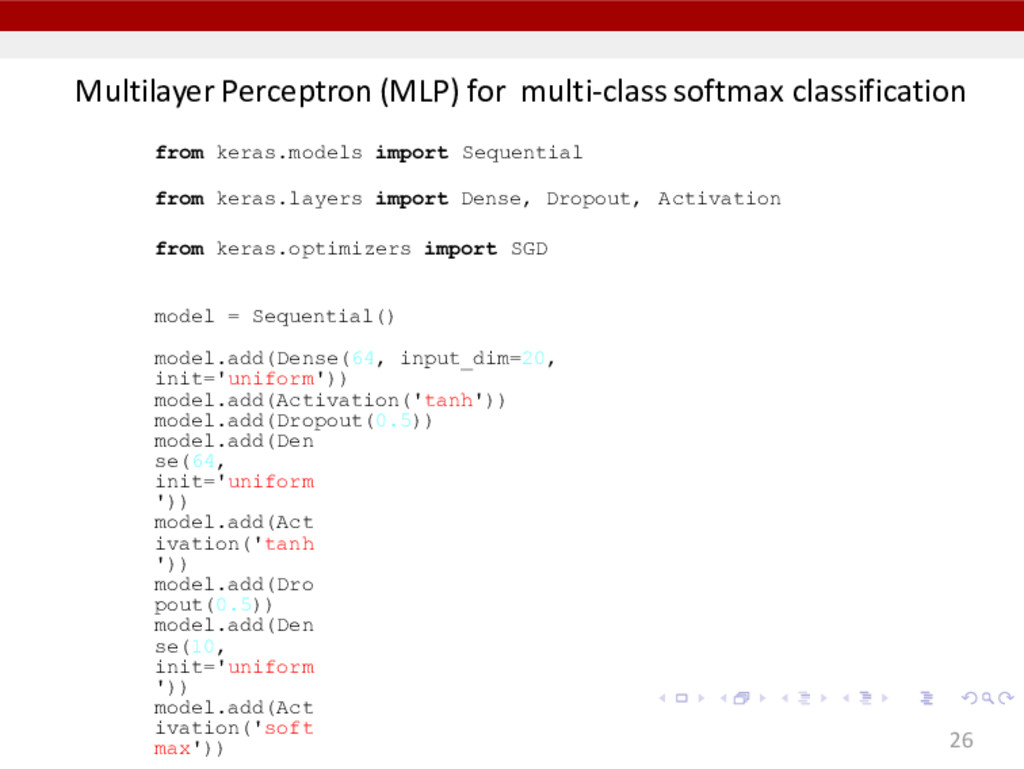
their input/output Prepare your inputs and output tensors Create first layer to handle input tensor Create output layer to handle targets Build virtually any model you like in between STAT 946
Sigmoid, tanh, ReLu, softplus, hard sigmoid, linear Advanced activations implemented as a layer (after desired neural layer) Advanced activations: LeakyReLu, PReLu, ELU, Parametric Softplus, Thresholded linear and Thresholded Relu STAT 946
mape, msle Hinge loss: squared hinge, hinge Class loss: binary crossentropy, categorical crossentropy Optimization: Provides SGD, Adagrad, Adadelta, Rmsprop and Adam All optimizers can be customized via parameters STAT 946
called at different points of training (batch or epoch) Existing callbacks: Early Stopping, weight saving after epoch Easy to build and implement, called in training function, fit() STAT 946
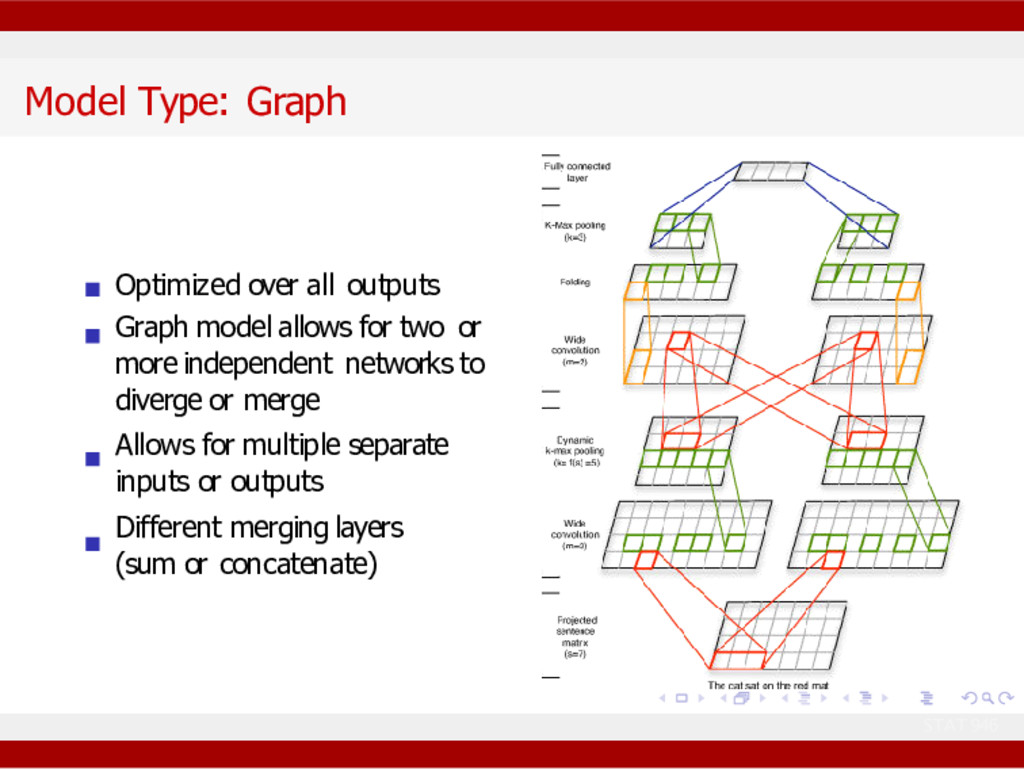
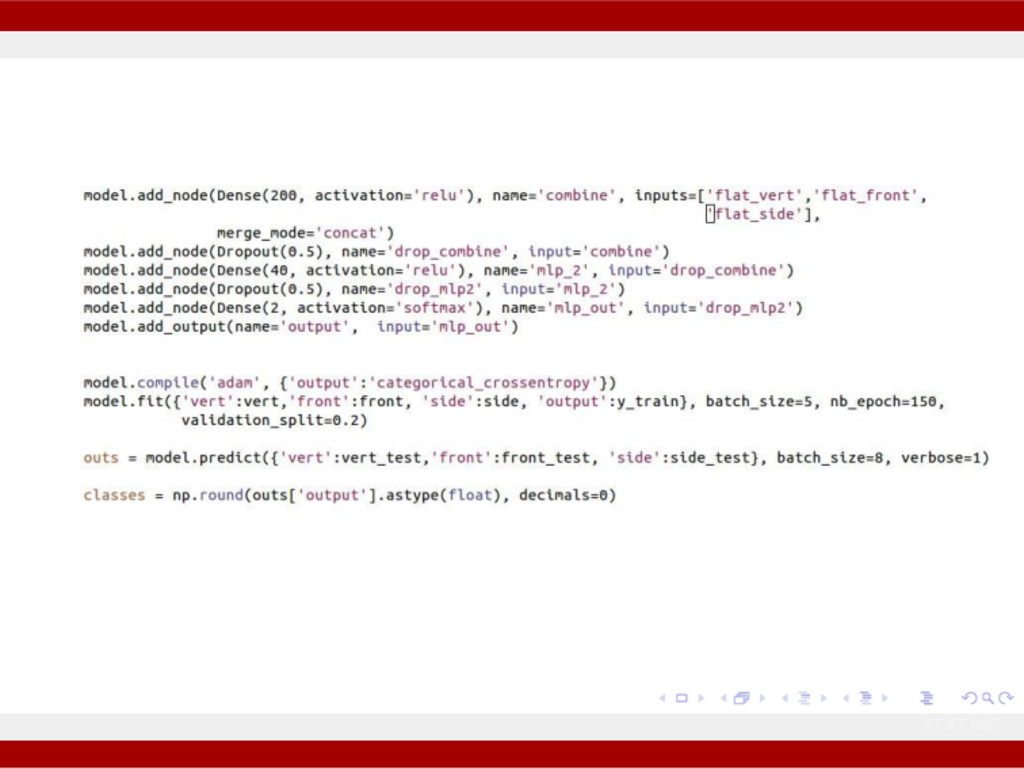
for two or more independent networks to diverge or merge Allows for multiple separate inputs or outputs Different merging layers (sum or concatenate) STAT 946
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? github.com/kashyap32/ twitter.com/kashyapraval3 2 Contact email : [email protected]](https://files.speakerdeck.com/presentations/fc33ff7156004349ba5ccc7e7eb30da5/slide_40.jpg){kind=link}