Talk given at OSCON 2014: http://www.oscon.com/oscon2014/public/schedule/detail/34094
The ability to understand the behavior of a software system so as to be able to answer questions about its health, while important has always been a challenge for software developers. System tools or language debuggers and profilers tend to be myopic in their scope and cumbersome to understand, setup and use; More so when applied to a distributed system. Specifically, requiring recompilation of software with additional instrumentation, adding a non-trivial performance overhead, and, equally importantly, requiring an elaborate setup renders tools unfit to be used in production.
This talk describes a new, low overhead, full stack tool (based on the Linux perf profiler and infrastructure built into the Hotspot JVM) we’ve built at Twitter to help solve this problem of dynamically profiling and tracing the behavior of the kernel and applications (including managed runtimes like the JVM) in production.
![Tracing & profiling services in production Kaushik Srenevasan [email protected] @ksrenev](https://files.speakerdeck.com/presentations/6ddbe9d0f90f0131a68716da8317d886/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
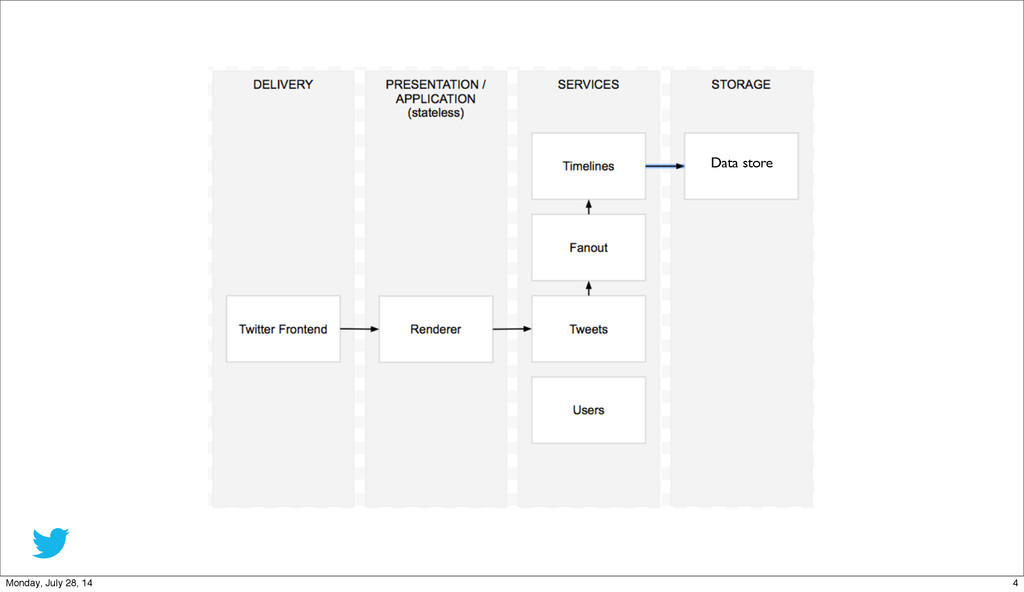{kind=link}
{kind=link}
{kind=link}
{kind=link}
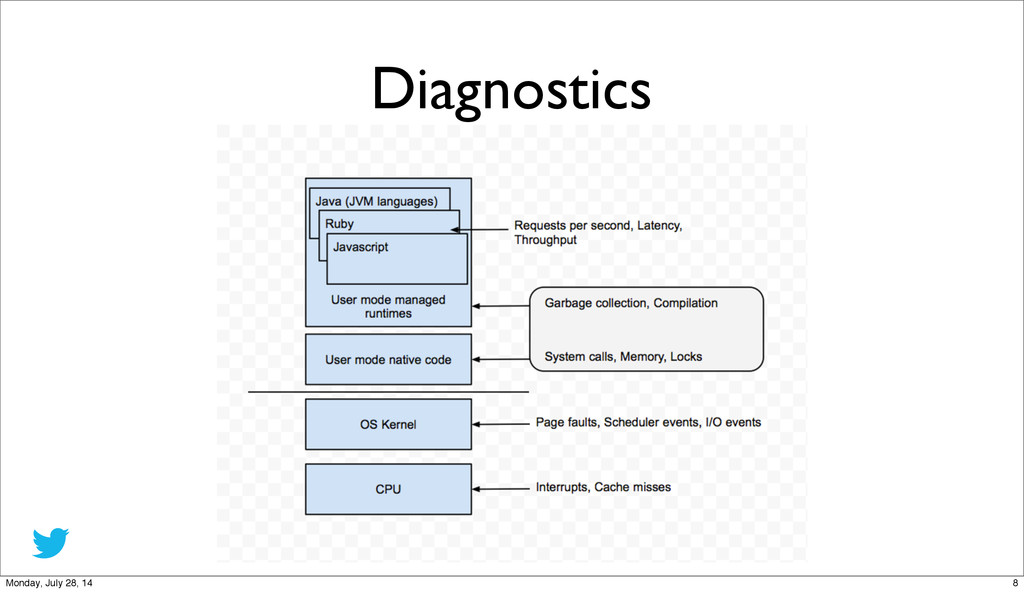{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
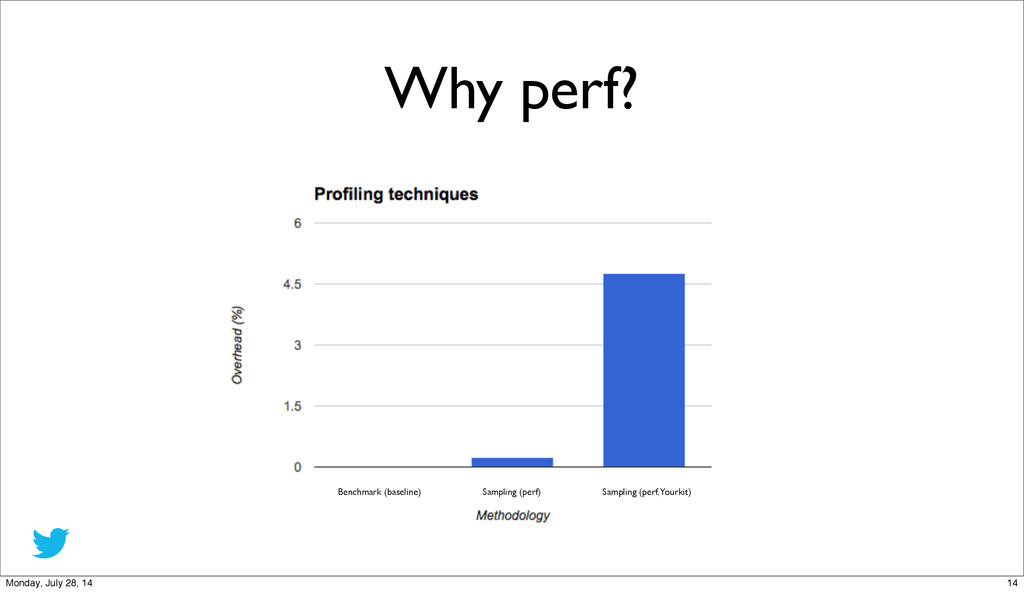{kind=link}
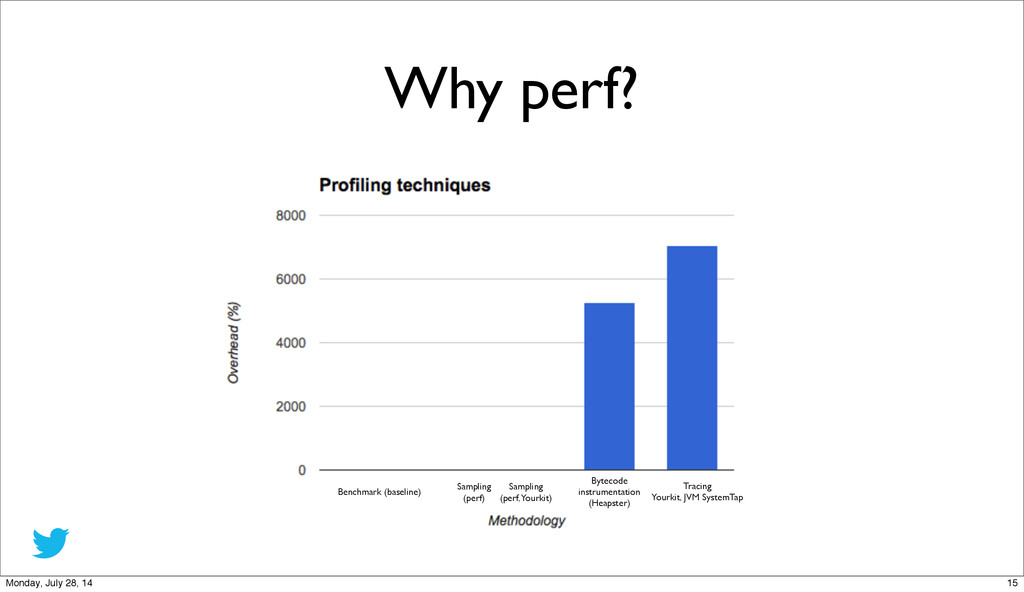{kind=link}
{kind=link}
{kind=link}
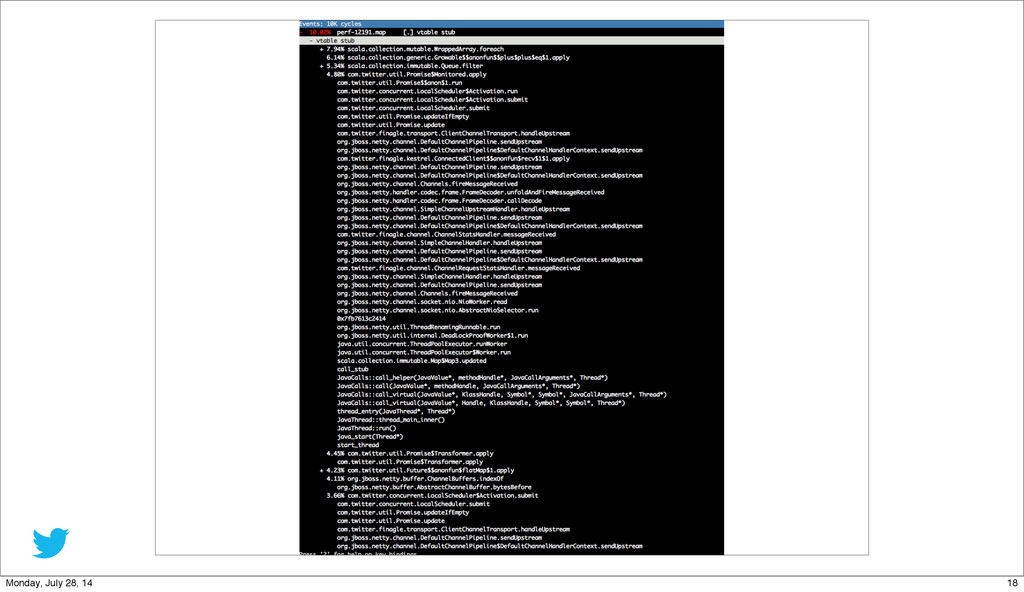{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
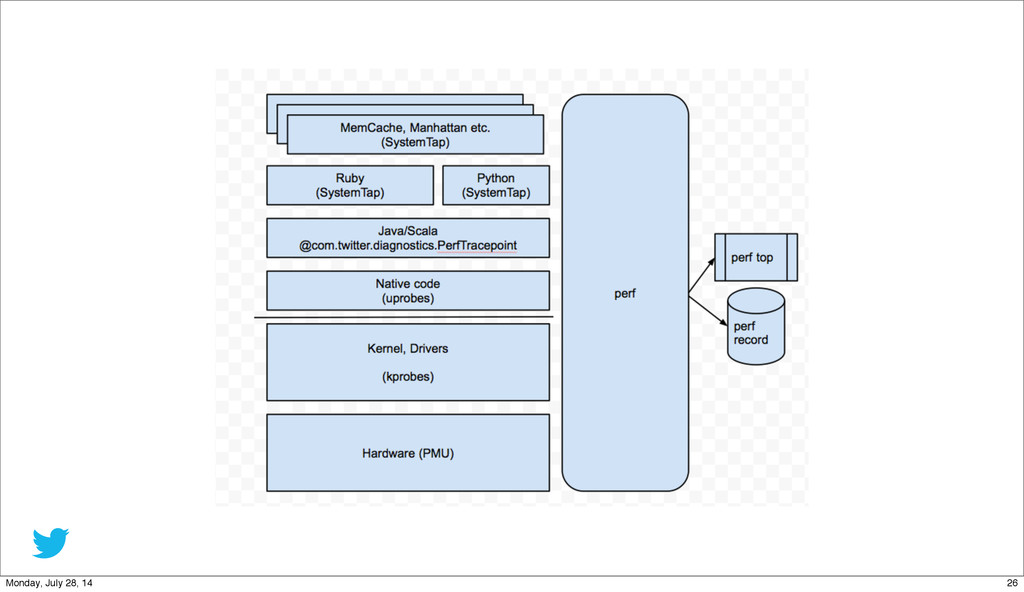{kind=link}
{kind=link}
{kind=link}