800+ Amazon accounts as an Amazon Direct Connect Delivery Partner n 2024 Japan Amazon Top Engineer (Networking) n Favorite Amazon Services: n Amazon Direct Connect n Amazon Transit Gateway n Amazon Lambda Kazuki Fujiwara Senior Associate - Network Engineer Nomura Research Institute, Ltd.
n partial or intermittent disruptions in performance, in contrast to a complete failure, where a device or system becomes wholly unresponsive e.g. intermittent packet loss on a particular network link, fluctuating latency n a network problem that is difficult to detect and diagnose * Even if you have redundant Direct Connect as per the resiliency models, there is a possibility that traffic will not be automatically switched to the backup circuit in the event of such failures.
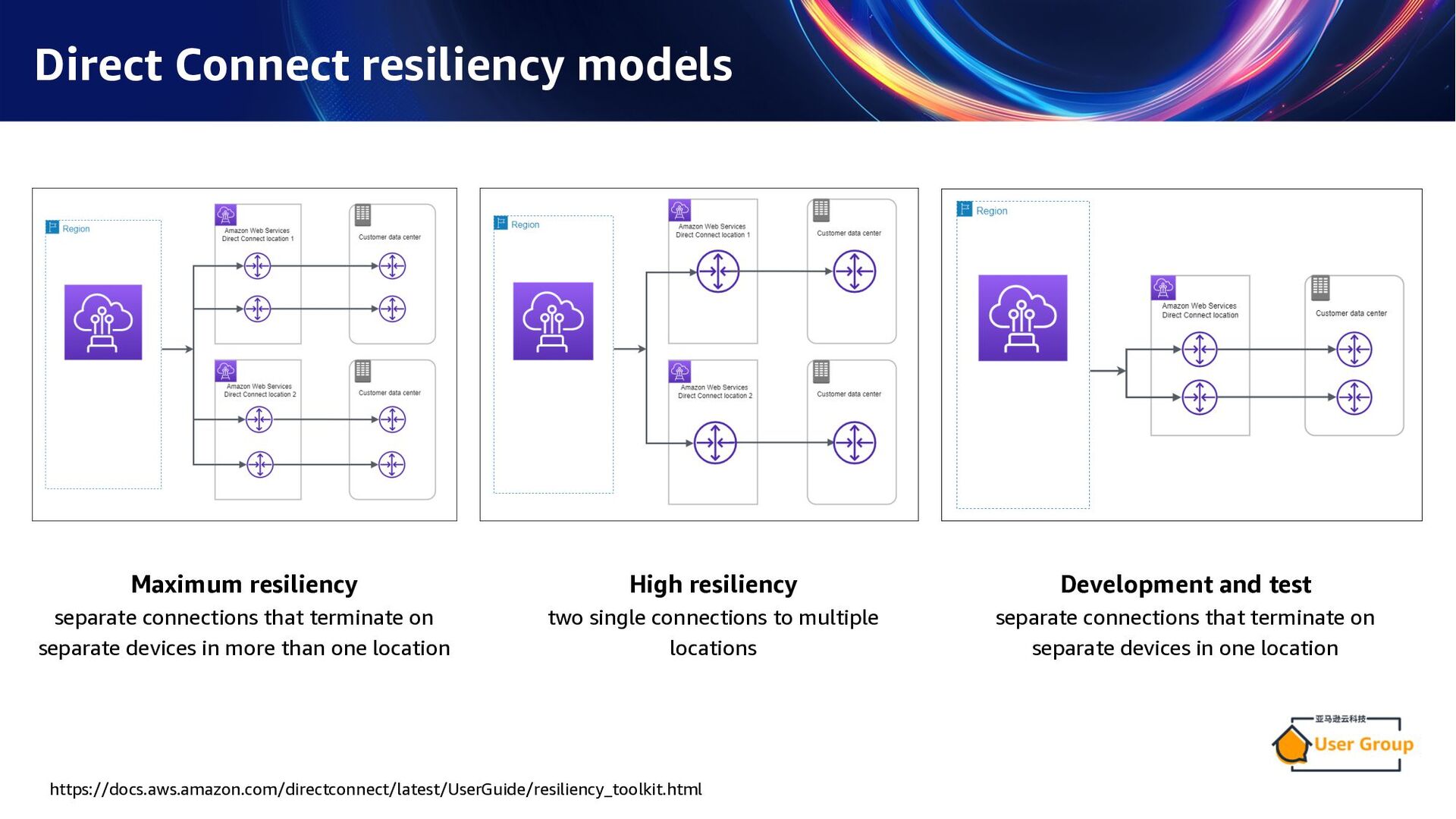
on separate devices in more than one location High resiliency two single connections to multiple locations Development and test separate connections that terminate on separate devices in one location https://docs.aws.amazon.com/directconnect/latest/UserGuide/resiliency_toolkit.html
the Tokyo (AP-NORTHEAST-1) Region on September 2, 2021 n Direct Connect traffic to the Tokyo region experienced intermittent connectivity issues and an increase in packet loss despite redundancy in Direct Connect. n It took approximately 6 hours from the time of failure to full recovery. n 07:30 AM : Connectivity issues started to occur gradually Direct Connect customers experienced intermittent connectivity issues and elevated packet loss for traffic destined to the Tokyo Region. n 12:30 PM : Customers started seeing recovery n 01:42 PM : Connectivity issues were fully resolved The impact of this failure, its causes, and the recovery process are detailed in the report below. Summary of Amazon Direct Connect Event in the Tokyo (AP-NORTHEAST-1) Region https://aws.amazon.com/jp/message/17908/
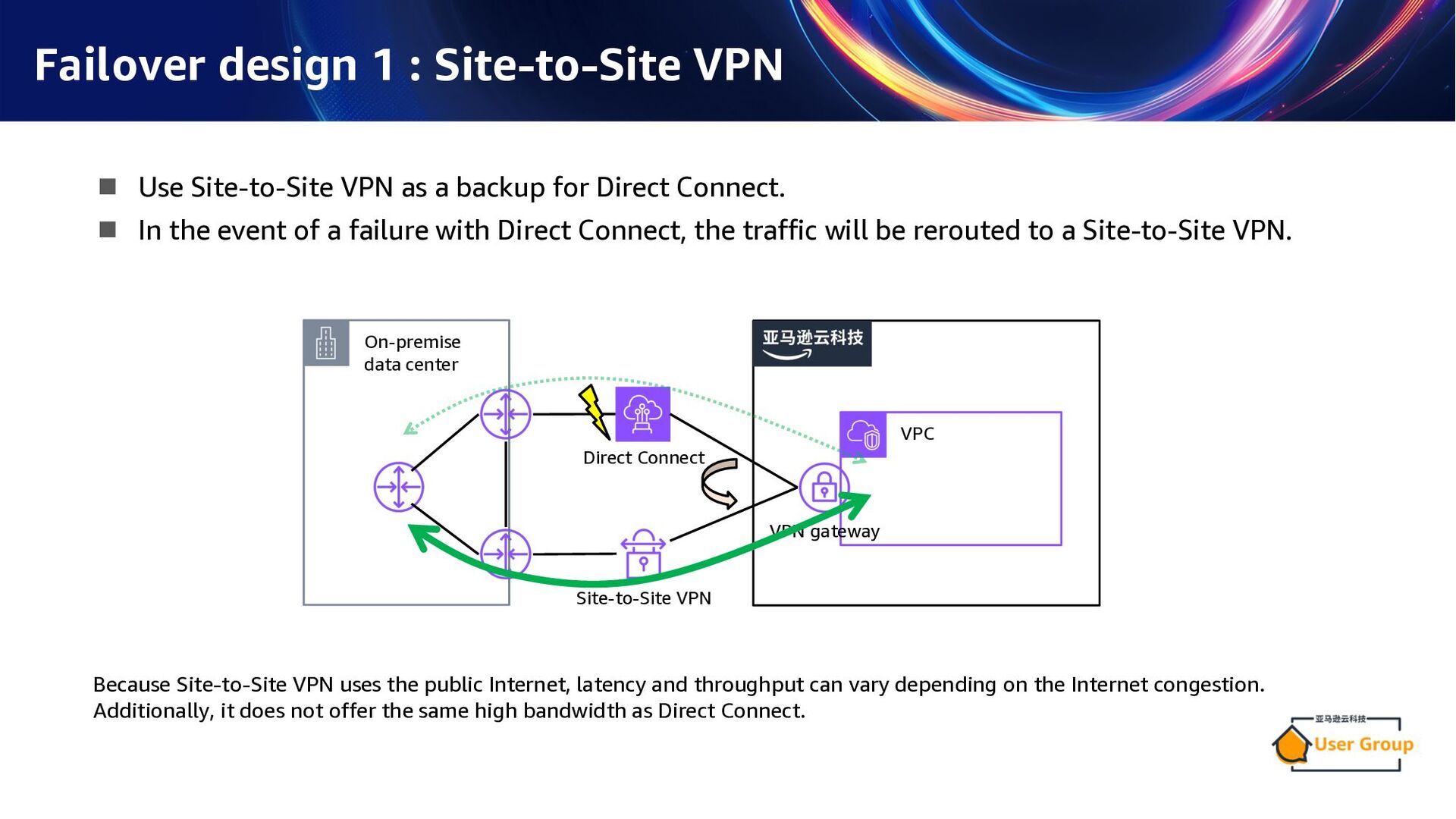
as a backup for Direct Connect. n In the event of a failure with Direct Connect, the traffic will be rerouted to a Site-to-Site VPN. On-premise data center Direct Connect VPC VPN gateway Site-to-Site VPN Because Site-to-Site VPN uses the public Internet, latency and throughput can vary depending on the Internet congestion. Additionally, it does not offer the same high bandwidth as Direct Connect.
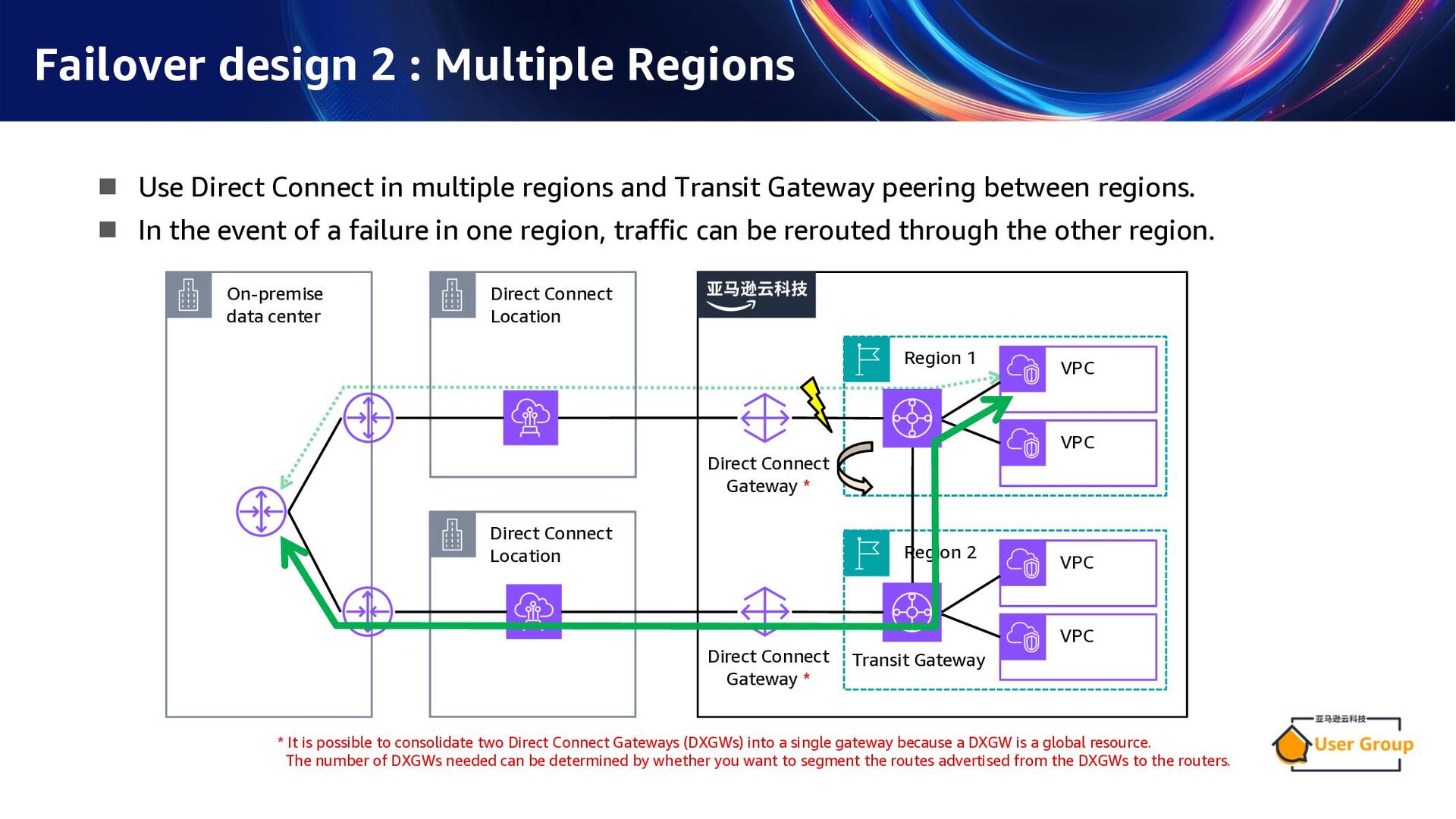
in multiple regions and Transit Gateway peering between regions. n In the event of a failure in one region, traffic can be rerouted through the other region. * It is possible to consolidate two Direct Connect Gateways (DXGWs) into a single gateway because a DXGW is a global resource. The number of DXGWs needed can be determined by whether you want to segment the routes advertised from the DXGWs to the routers. Region 1 VPC VPC Direct Connect Gateway * Region 2 Transit Gateway VPC VPC On-premise data center Direct Connect Location Direct Connect Location Direct Connect Gateway *
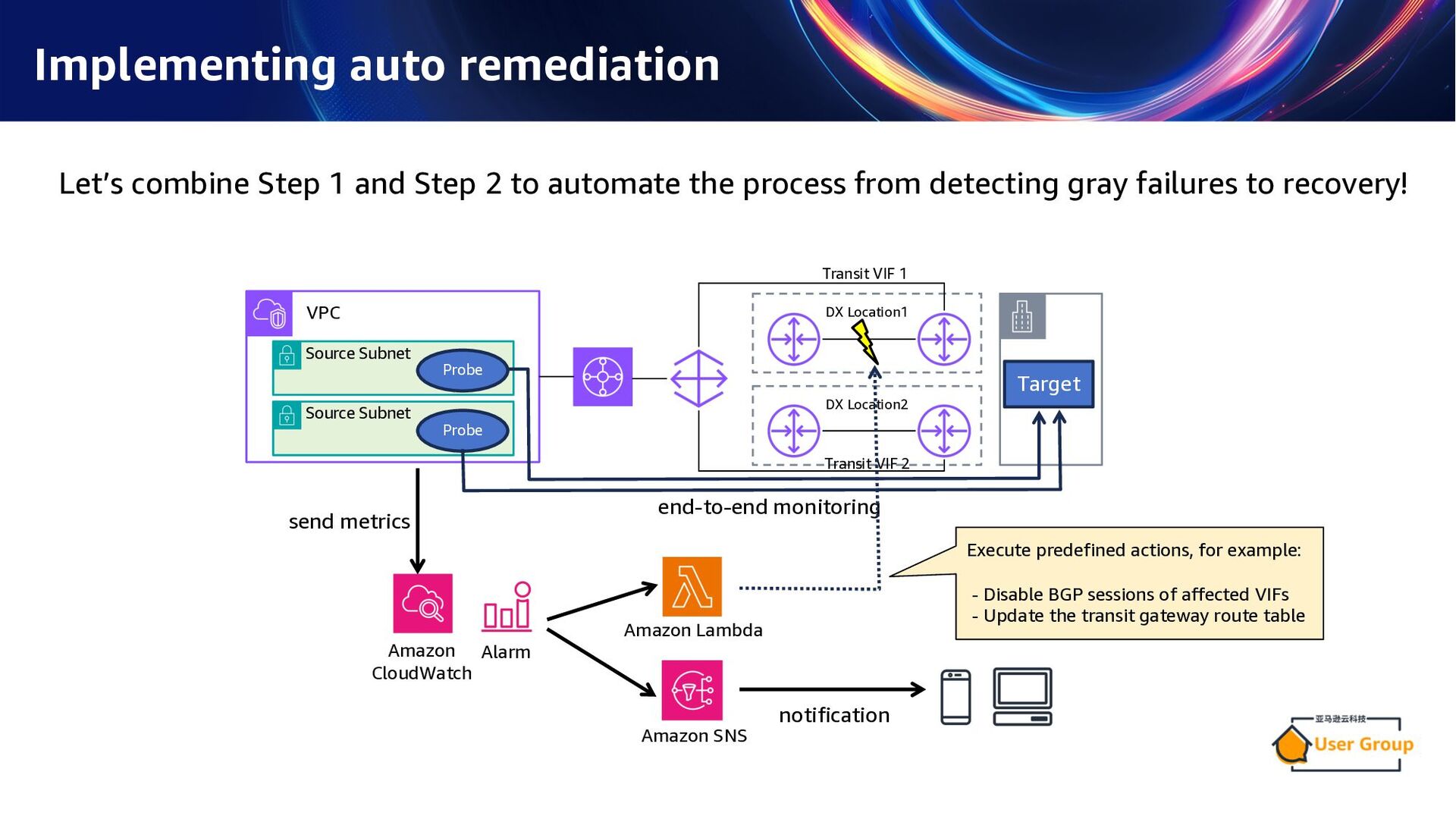
failures, perform the following two steps: Step 1: Define the recovery actions in advance Predefine the actions to be taken in case of a failure and prepare them for execution by a script. e.g. • Disable the VIF (Virtual Interface) experiencing quality degradation • Update the transit gateway route table • Update the routes advertised from the Transit Gateway to the DXGW (Direct Connect Gateway) * It is strongly recommended to regularly test whether the predefined actions function correctly. Step 2: Monitor network performance and trigger the predefined actions Use CloudWatch Network Monitor to diagnose network degradation via Direct Connect, and trigger the predefined actions when there is a performance issue.
failover test is used to verify whether traffic is correctly switched to a redundant connection in the event of a failure. n It can also be used to temporarily disable a VIF (Virtual Interface) when the performance of a specific interface degrades. n The failover test can be conducted in the following two steps. ① Select [Actions] > [Bring down BGP] on the console of the target VIF ② Specify the duration for which the BGP session should be disabled and confirm. Then, the status of the VIF changes to “testing,” and the BGP session is disabled. ① ② The failover test can also be executed via API. To use API, see the following documents. https://docs.aws.amazon.com/directconnect/latest/APIReference/API_StartBgpFailoverTest.html
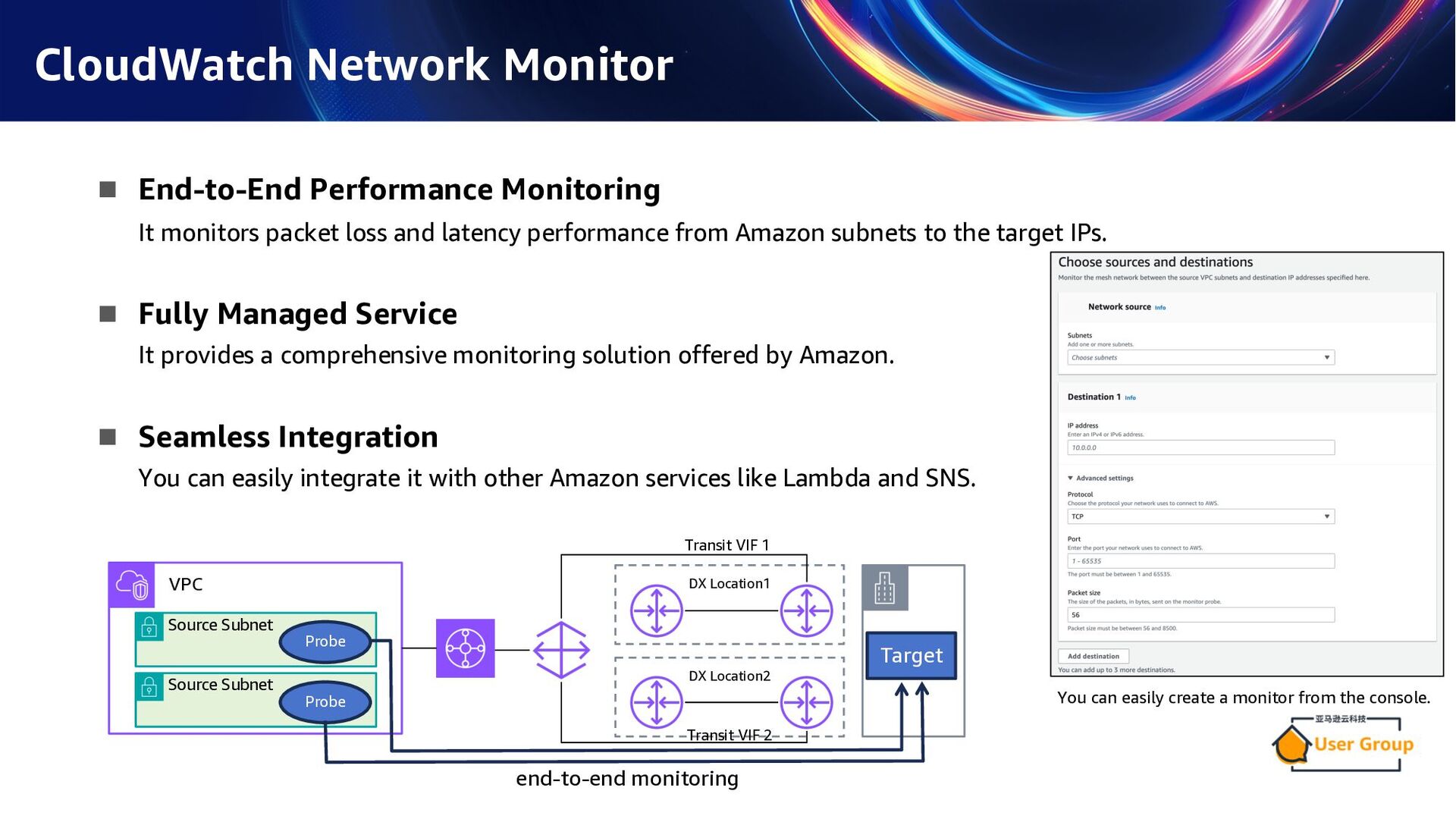
loss and latency performance from Amazon subnets to the target IPs. n Fully Managed Service It provides a comprehensive monitoring solution offered by Amazon. n Seamless Integration You can easily integrate it with other Amazon services like Lambda and SNS. You can easily create a monitor from the console. VPC DX Location1 DX Location2 Target Source Subnet Probe Source Subnet Probe Transit VIF 1 Transit VIF 2 end-to-end monitoring "Network Monitor" was renamed to "Network Synthetic Monitor" on December 1, 2024.
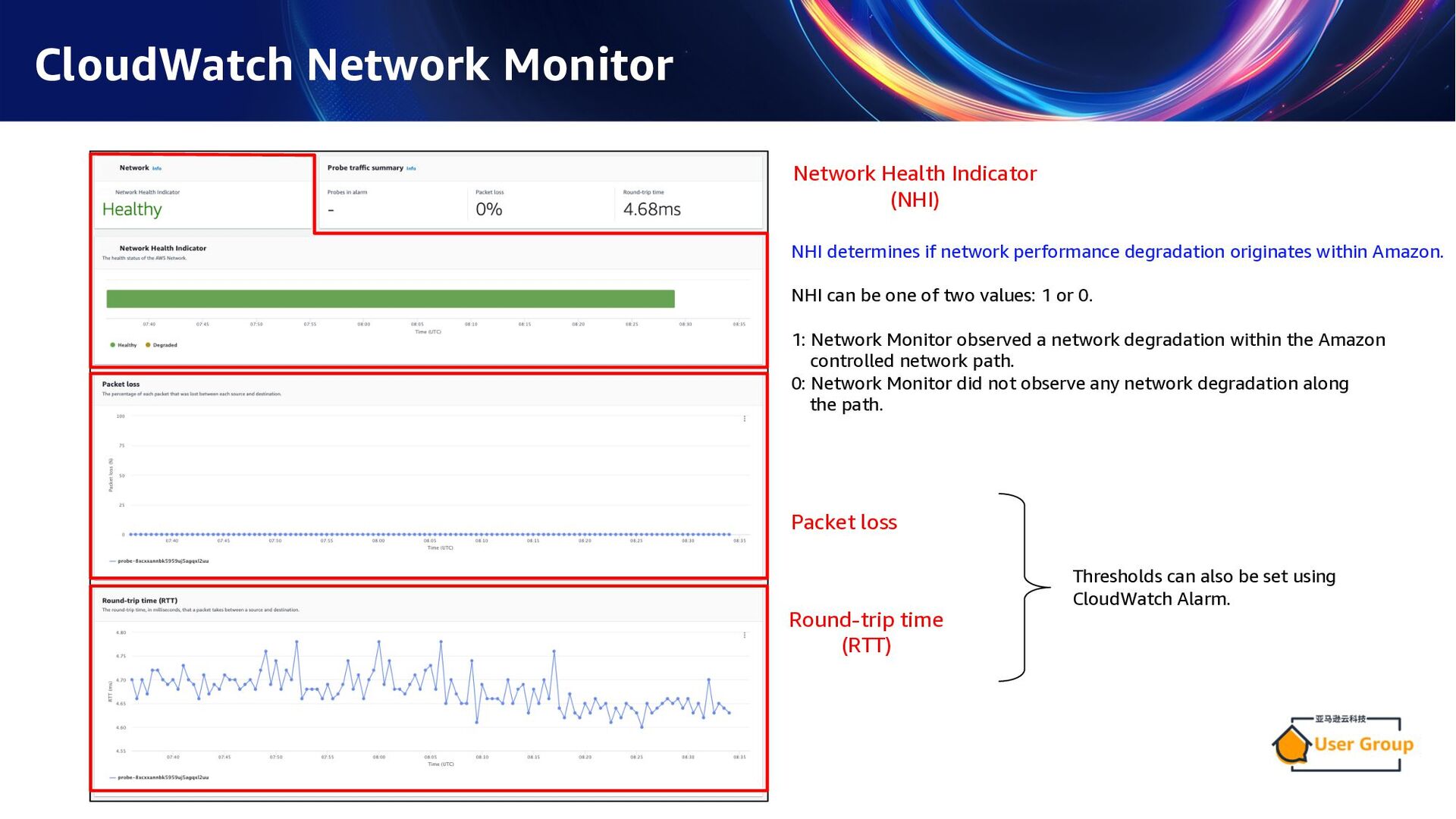
Indicator (NHI) NHI determines if network performance degradation originates within Amazon. NHI can be one of two values: 1 or 0. 1: Network Monitor observed a network degradation within the Amazon controlled network path. 0: Network Monitor did not observe any network degradation along the path. Thresholds can also be set using CloudWatch Alarm. "Network Monitor" was renamed to "Network Synthetic Monitor" on December 1, 2024.
following two steps: n Step 1: Define the recovery actions in advance Predefine the actions to be taken in case of a failure and prepare them for execution by a script. n Step 2: Monitor network performance and trigger the predefined actions Use CloudWatch Network Monitor to diagnose network degradation via Direct Connect, and trigger the predefined actions when there is a performance issue. n CloudWatch Network Monitor is a fully managed monitoring service that is useful for detecting gray faults, such as intermittent packet loss on a particular network link or fluctuating latency. "Network Monitor" was renamed to "Network Synthetic Monitor" on December 1, 2024.
Monitor https://aws.amazon.com/jp/blogs/networking-and-content-delivery/monitor-hybrid- connectivity-with-amazon-cloudwatch-network-monitor/ n Amazon Direct Connect monitoring and failover with Anomaly Detection https://aws.amazon.com/jp/blogs/networking-and-content-delivery/aws-direct- connect-monitoring-and-failover-with-anomaly-detection/ n Using Amazon CloudWatch Network Monitor https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/what-is-network- monitor.html "Network Monitor" was renamed to "Network Synthetic Monitor" on December 1, 2024.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}