Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20250916_第65回 コンピュータビジョン勉強会
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
KeiichiIto1978
November 15, 2025
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
20250916_第65回 コンピュータビジョン勉強会
KeiichiIto1978
November 15, 2025
More Decks by KeiichiIto1978
See All by KeiichiIto1978
20260618_CVPR読み会.pdf
keiichiito1978
0
110
20260208_第66回 コンピュータビジョン勉強会
keiichiito1978
0
590
CVPR勉強会後半
keiichiito1978
0
610
AnomalyNCD Towards Novel Anomaly Class Discovery in Industrial Scenarios
keiichiito1978
0
51
Featured
See All Featured
We Are The Robots
honzajavorek
0
280
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
Tell your own story through comics
letsgokoyo
1
1k
Thoughts on Productivity
jonyablonski
76
5.3k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.3k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
RailsConf 2023
tenderlove
30
1.5k
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
410
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
Transcript
Confidential & Proprietary AnimeGamer Infinite Anime Life Simulation with Next
Game State Prediction
2 産総研発の 外観検査AI スタートアップ © 2024 Adacotech Incorporated. All Right
Reserved 会社名 代表取締役 事業内容 取引実績 主要株主 社員数 株式会社アダコテック(設立:2012年3月12日) 河邑 亮太 産総研特許技術を基軸とした外観検査AIソフトウェ ア・アルゴリズムの開発・販売 自動車OEM/Tier1メーカー 、大手電子部品・半導 体、インフラ、警備会社 等 東京大学エッジキャピタルパートナーズ、東大IPC、 DNX Ventures、リアルテックファンド、Spiral Capital 他 約20名 Mission テクノロジーで 生産現場を エンパワーメントする
3 自己紹介 学生時代は、産業技術総合研究所で卒業研究を実施。 その縁で、AIST認定ベンチャーに入社。 その後、25年以上AIの研究開発に従事。 主に取り組んだ研究開発事例 ・GAによる光学機器の自動調整、半導体設計の最適化 ・動画/静止画/センサ/音の異常検知 2012年 弊社創業と同時に入社
2014年 現職
4 論文の選定理由 無邪気に仕事と関係ないテーマの論文を選びたくなった。 ゲームとかアニメとかがタイトルに入っていたり、ゲーム関連の事業やって いる会社の論文とか取り上げてみよう!! 見つけた!← 今ココ!
5 世の中に無限ゲームという概念があります 有限ゲーム ルール、勝敗、終了条件が明確に 定義される。 生成AI活用はあるが、あらかじめ固定 されたゲーム環境やルール内での利用 例:マリオ、チェス、将棋 無限ゲーム 終わりがなく、プレイを続けるこ
とが目的。世界そのものが継続的 に変化生成される 例:Minecraft、Second Life? 生成AIとの融合 → Generative Infinite Game ゲーム要素、グラフィック、ルールをAIが都度生成し、AIがゲーム 世界を継続的に作る
6 従来技術の課題 従来手法の例:Unbounded(2024)のアプローチ LLMがテキスト履歴を読んで静止画キャプションを出力する。 T2Iモデルで画像を生成し、ユーザとの対話を継続する。 課題 ① 視覚的一貫性の欠如 過去の視覚情報を保持しない ため、キャラクターや背景の
一貫性が毎ターン崩れる。 ② 動的シーン遷移の困難 静止画のみの生成で、連続し た「動的なシーン遷移」がで きない。 ③ ゲーム的進行の欠如 キャラクターの状態が固定さ れ、「ゲーム的な進行」(因 果律)がない。 結果として、「動くけれど続かないゲーム世界」しか作れない。
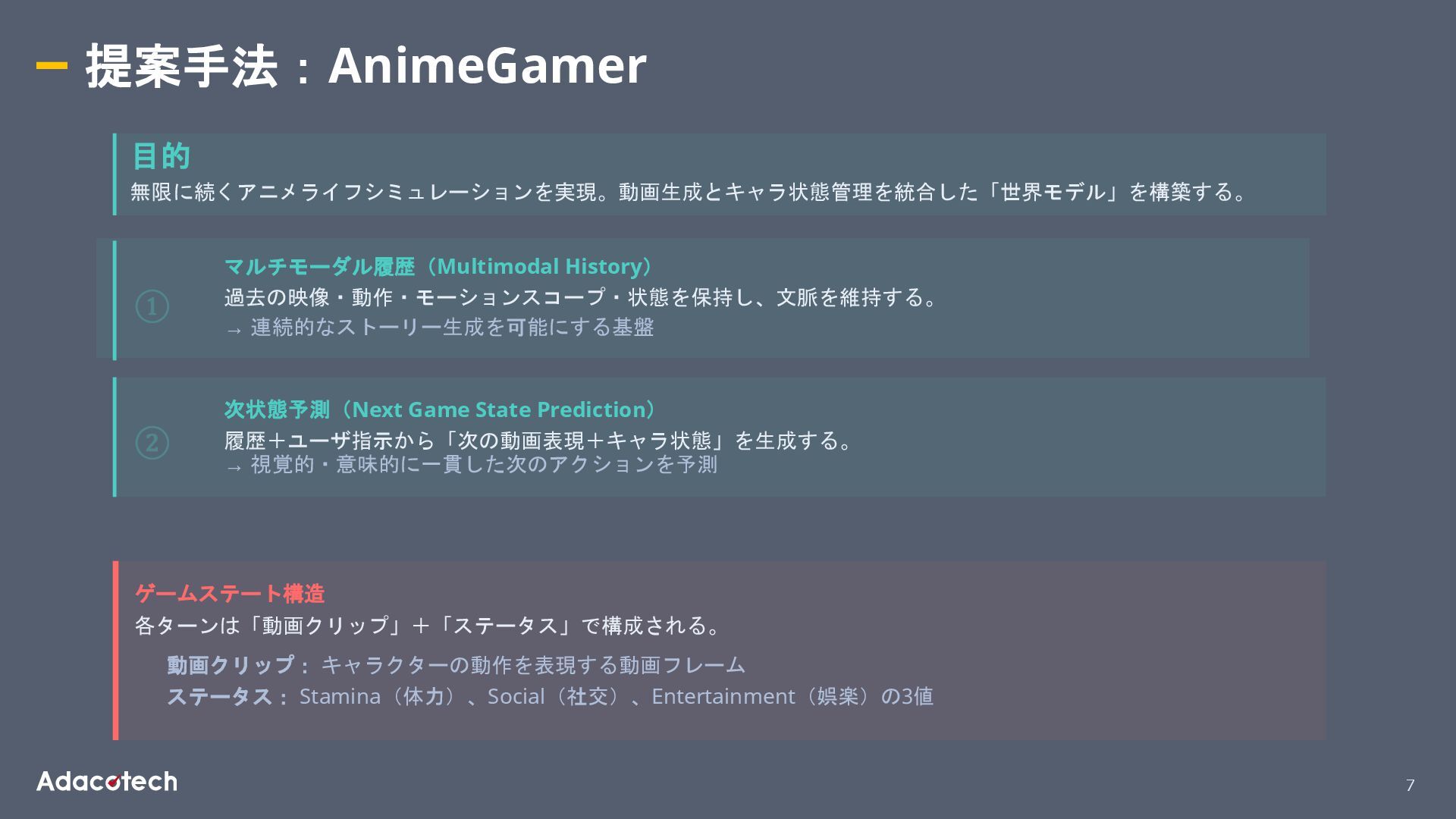
7 提案手法:AnimeGamer 目的 無限に続くアニメライフシミュレーションを実現。動画生成とキャラ状態管理を統合した「世界モデル」を構築する。 マルチモーダル履歴(Multimodal History) 過去の映像・動作・モーションスコープ・状態を保持し、文脈を維持する。 → 連続的なストーリー生成を可能にする基盤 次状態予測(Next
Game State Prediction) 履歴+ユーザ指示から「次の動画表現+キャラ状態」を生成する。 → 視覚的・意味的に一貫した次のアクションを予測 ゲームステート構造 各ターンは「動画クリップ」+「ステータス」で構成される。 動画クリップ: キャラクターの動作を表現する動画フレーム ステータス: Stamina(体力)、Social(社交)、Entertainment(娯楽)の3値
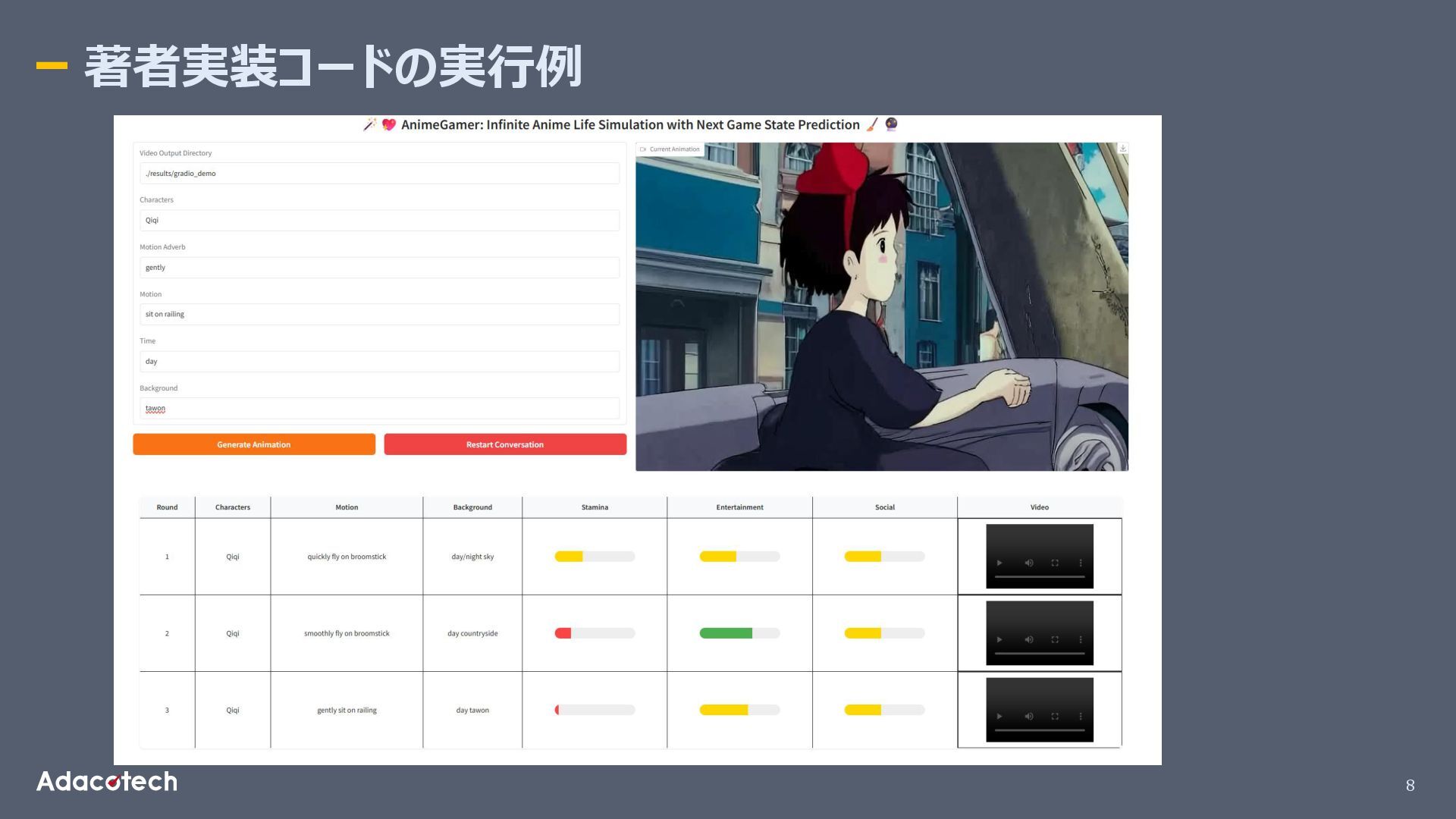
8 著者実装コードの実行例
9 生成した動画例 Character: Qiqi; Motion: quickly flying on broomstick; Background:
day sky. Character: Qiqi; Motion: smoothly fly on broomstick; Background: day countryside. Character: Qiqi; Motion: gently sit on railing; Background: day town.
10 AnimeGamerの概要 • AnimeGamerは「過去の状態+行動指示」から「次の状態(動画+ステータス)」を生成する世界モデル。 • 一回の生成は「ゲームの1ターン」に対応し、プレイヤー操作に応じて次の映像とキャラ状態が生成される。 • 生成内容は、動的なアニメーションショット(動画)とキャラのステータス(体力・社交・娯楽値)で構成。 • 背景やキャラクター外観が一貫して維持され、連続的なストーリーを形成。
• モデルが過去の視覚情報を保持して次状態を予測することで、整合性のあるアニメ世界が継続する。
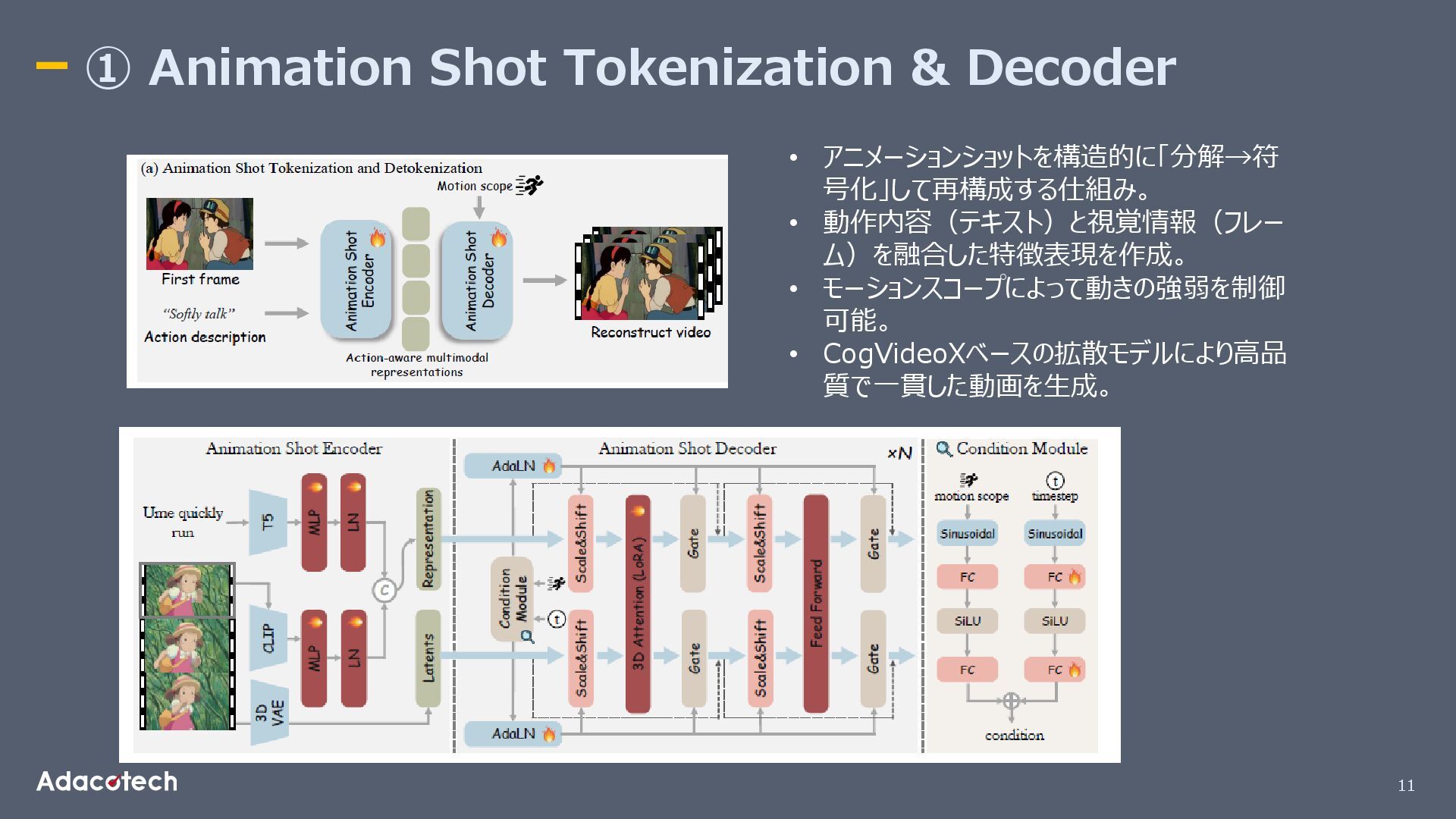
11 ① Animation Shot Tokenization & Decoder • アニメーションショットを構造的に「分解→符 号化」して再構成する仕組み。
• 動作内容(テキスト)と視覚情報(フレー ム)を融合した特徴表現を作成。 • モーションスコープによって動きの強弱を制御 可能。 • CogVideoXベースの拡散モデルにより高品 質で一貫した動画を生成。
12 ② Next Game State Prediction • MLLMがゲームエンジンとして「次のアニメショット+キャラ状態」を予測。 • 履歴コンテキストを考慮して、一貫した映像生成を実現。
• LoRAを利用して軽量学習を実施し、推論コストを抑制。 • ステータス(体力・社交・娯楽)も同時に出力し、ゲーム的連続性を担保。
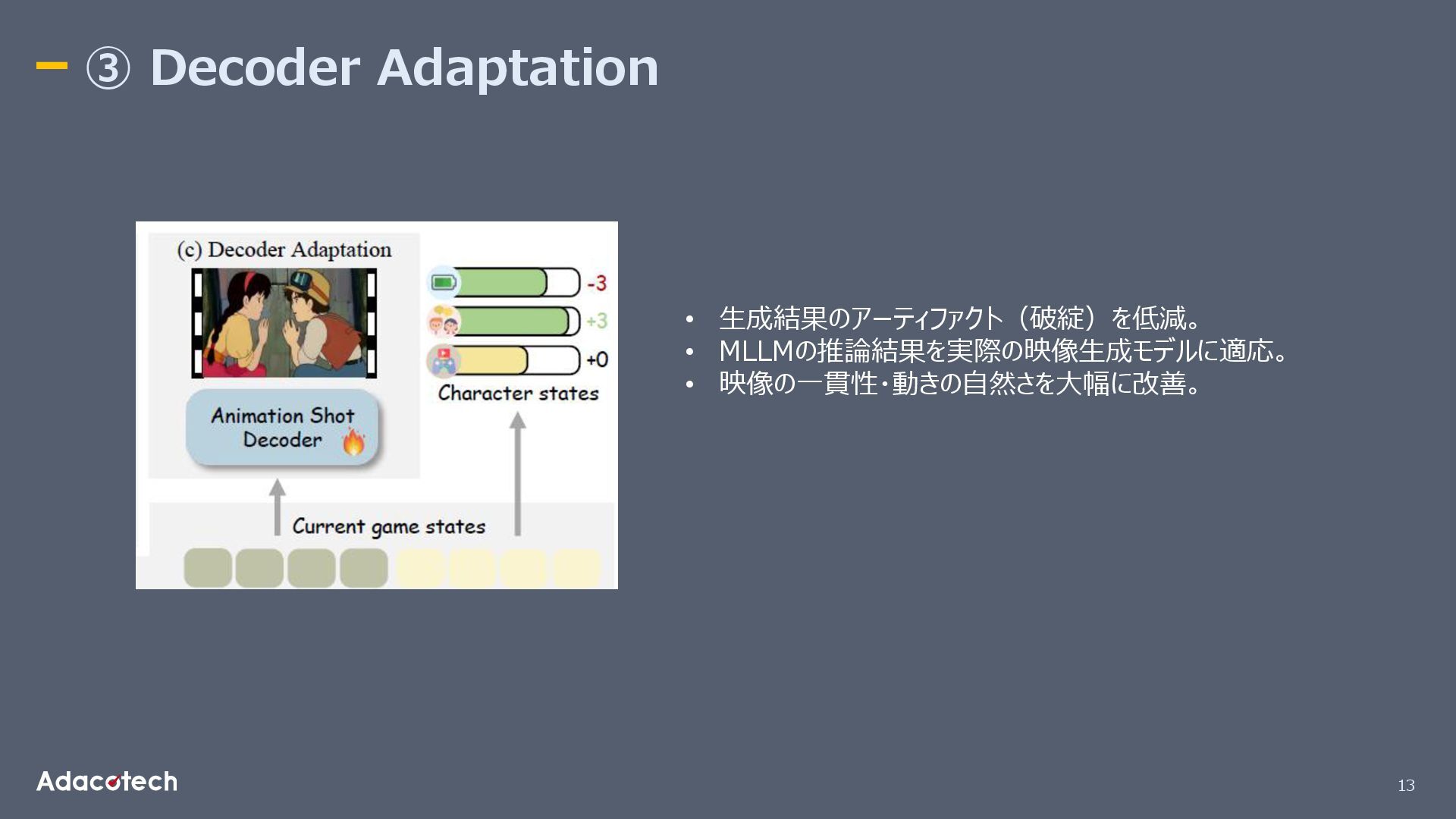
13 ③ Decoder Adaptation • 生成結果のアーティファクト(破綻)を低減。 • MLLMの推論結果を実際の映像生成モデルに適応。 • 映像の一貫性・動きの自然さを大幅に改善。
14 実験条件 学習データセット アニメ映画から抽出した キャラクター中心のマルチターン動画データ(約2万クリップ) を用いて学習。 各クリップには、マルチモーダルモデル InternVLでキャラ・動作・背景・ステータス(体力/社交/娯楽)情報を 付与。 学習対象は「次のゲームステート(アニメーションショット+キャラ状態)」の予測。
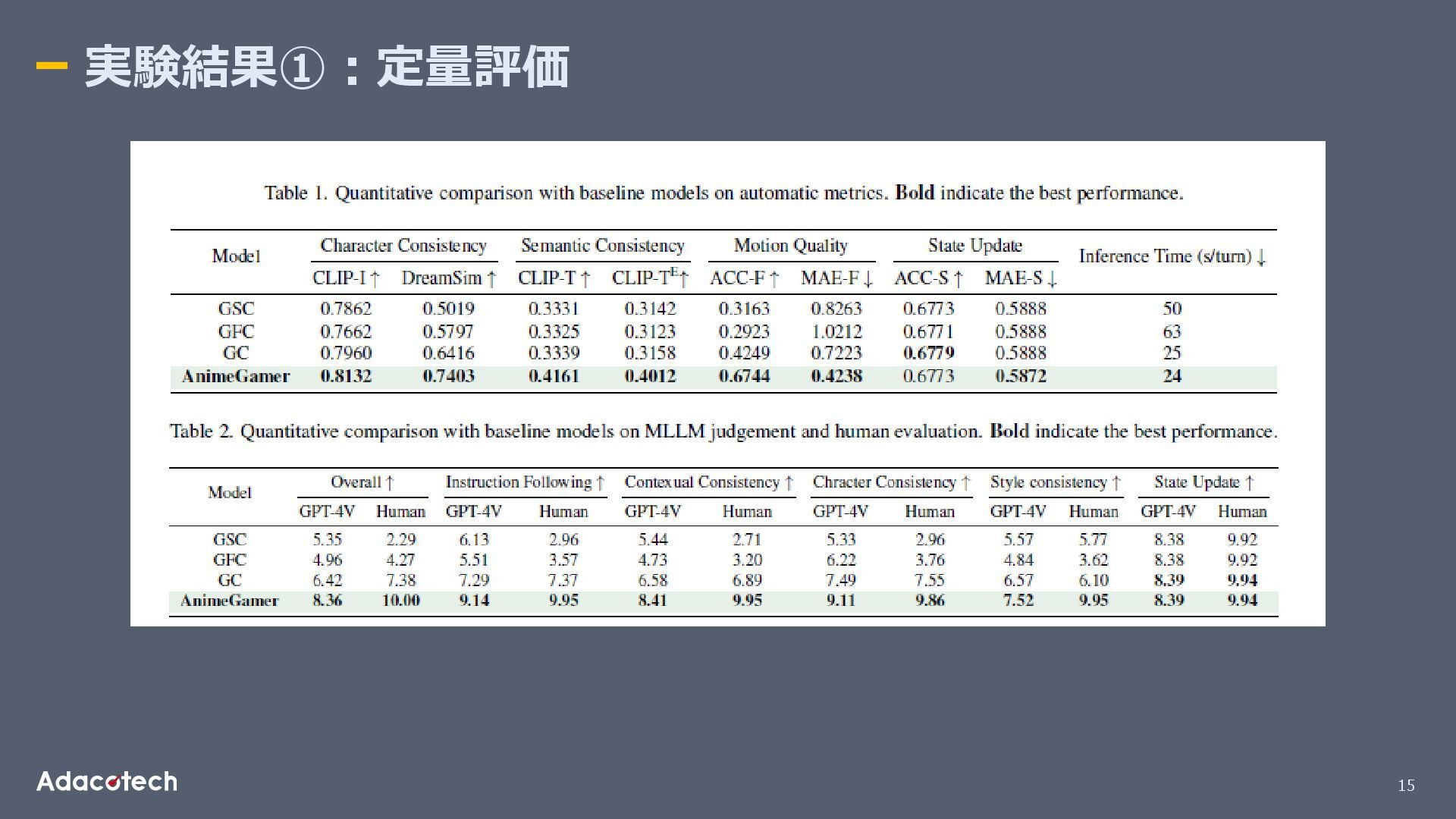
テストデータセット 同じアニメ映画群のうち、未使用シーンをテストに利用。 テスト時は GPT-4oを用いて複数キャラ・環境・動作を含む「10ターンの状態遷移」をシミュレーション。 評価ベンチマーク構成:20キャラクター、940種類の動作、133種類の環境、合計2,000ラウンドの生成評価。 評価方法 ① 自動評価指標 キャラ一貫性:CLIP-I, DreamSim 意味一貫性:CLIP-T, CLIP-TE 動作品質:ACC-F, MAE-F(光学フロー) ステータス更新精度:ACC-S, MAE-S 推論時間:1ターンあたり秒数 ② MLLM評価(GPT-4V)+人手評価 総合品質、指示追従、一貫性、キャラ/スタイル整合性、状態更新を10点満点で採点。
15 実験結果①:定量評価
16 実験結果②:定性評価
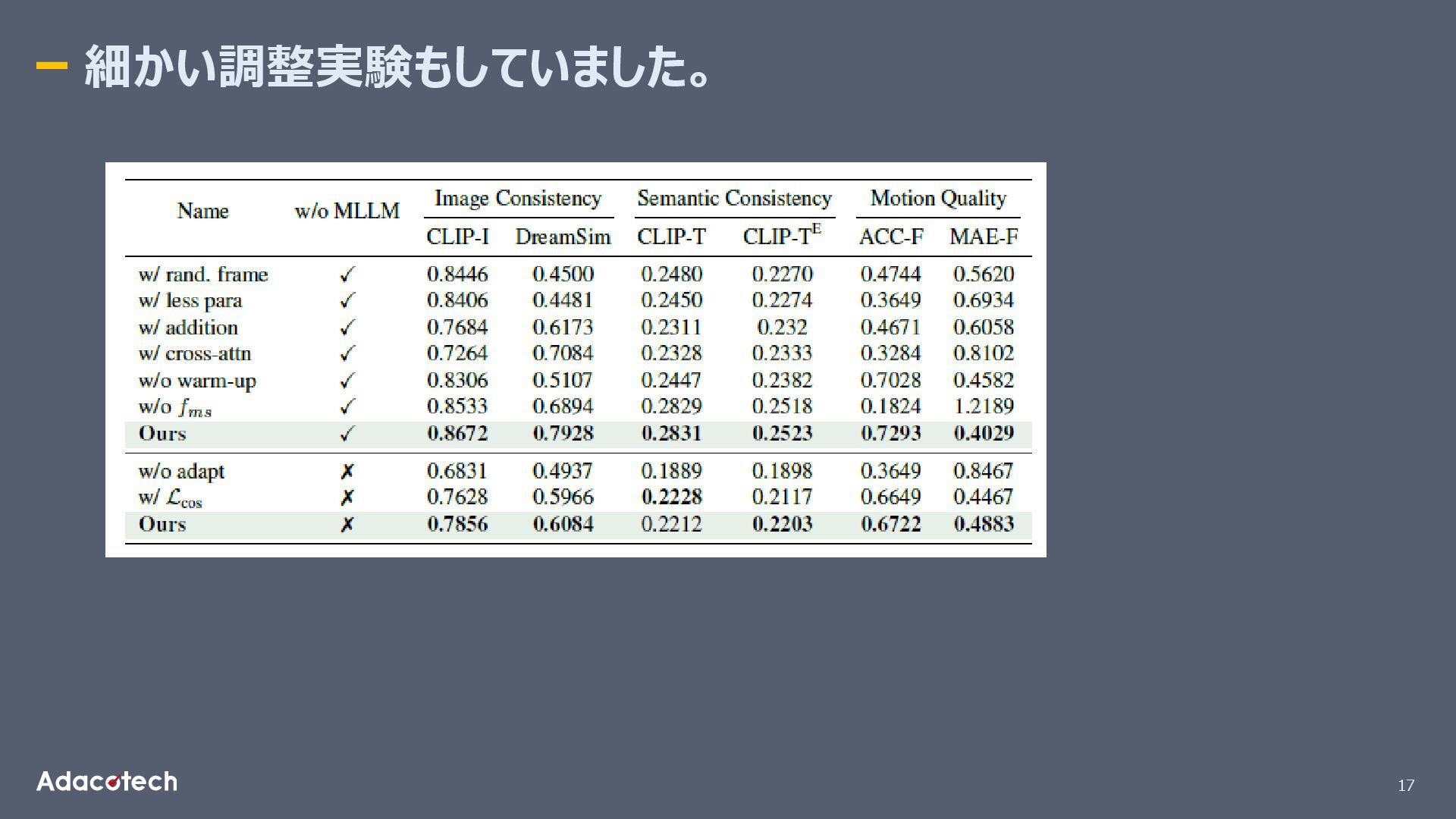
17 細かい調整実験もしていました。
18 おわりに 過去のステータスや生成情報を再帰的に入力するというアプローチが最近ま でなかったことは以外だった。 けど、それだけ技術の発展が目覚ましく1年前の状況がかなりイニシエの事だ と感じただけかもしれないと思いました。
19 採用情報 アダコテックではぷろだくとエンジニアを募集しています! 是非、一度カジュアル面談におこしください!
Confidential & Proprietary 20 Thank you very much for your
time!!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}