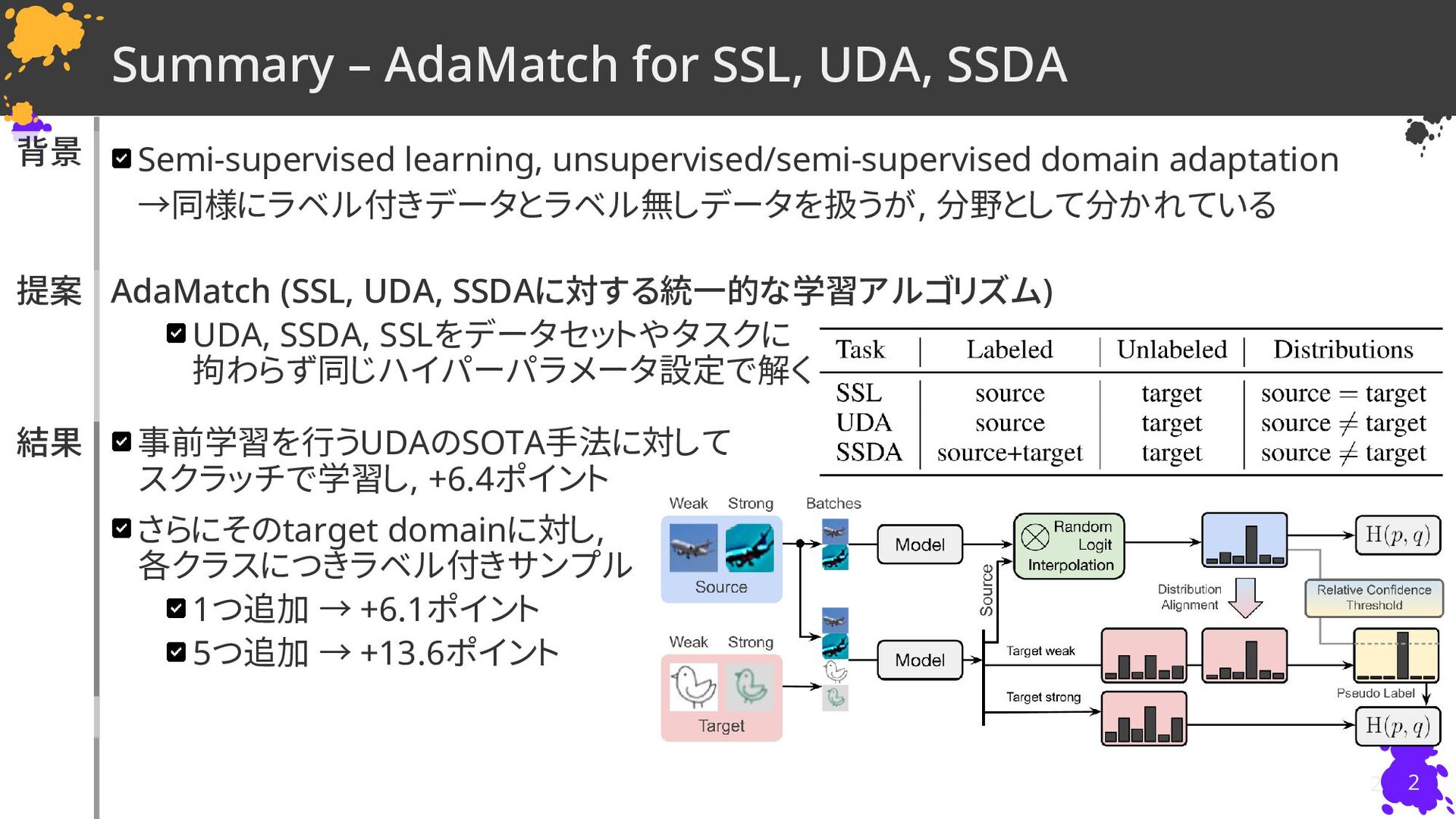
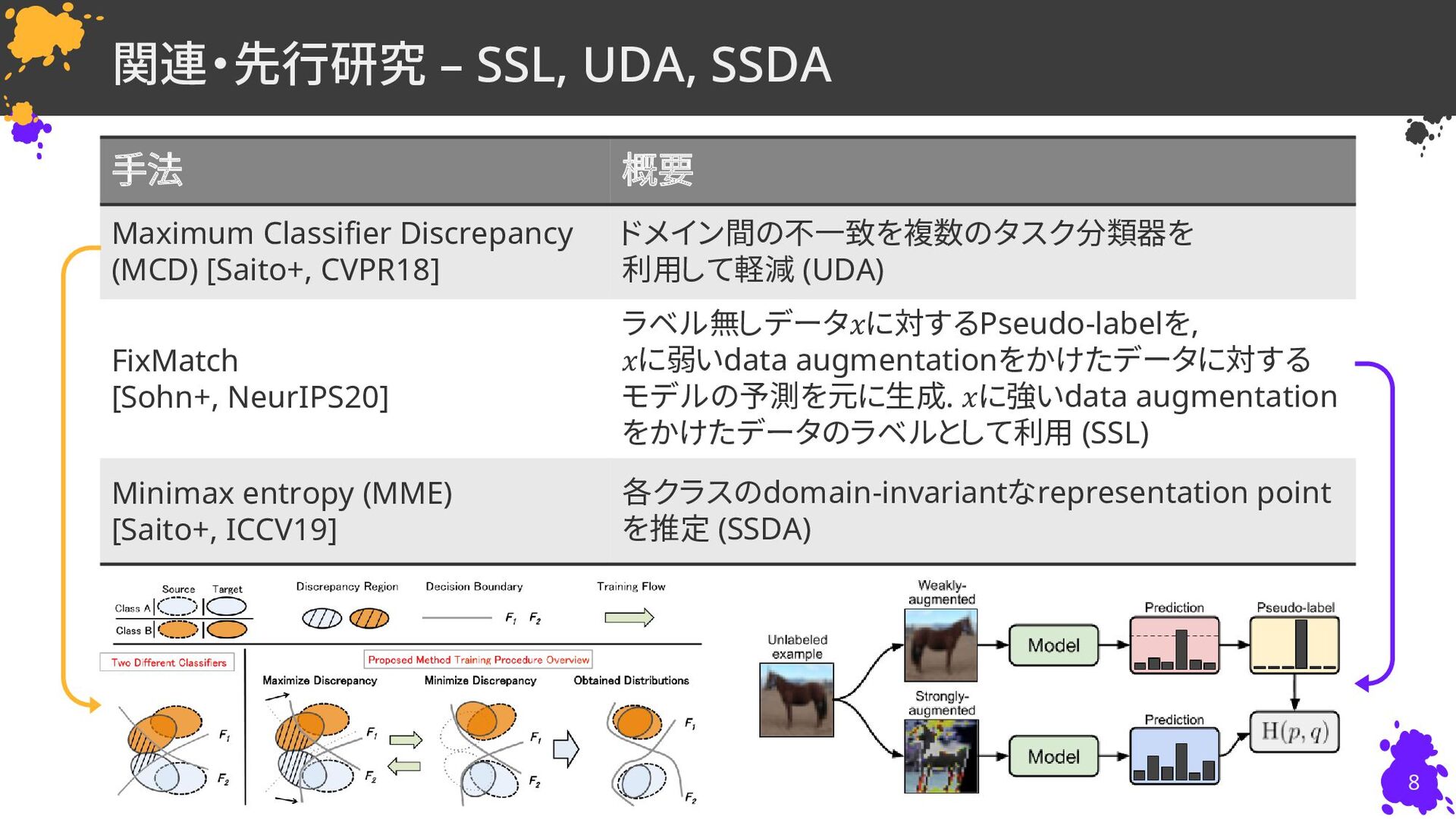
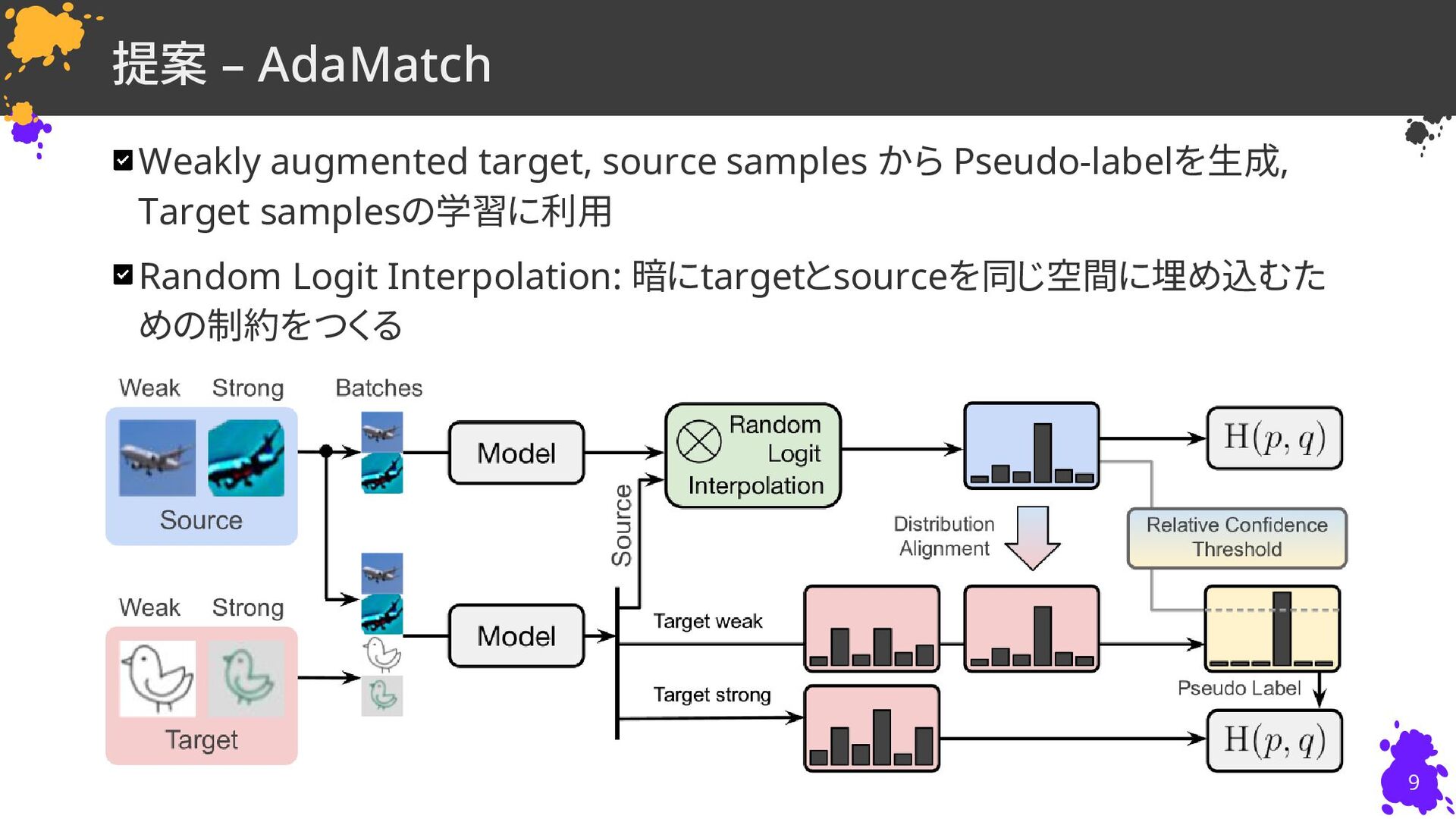
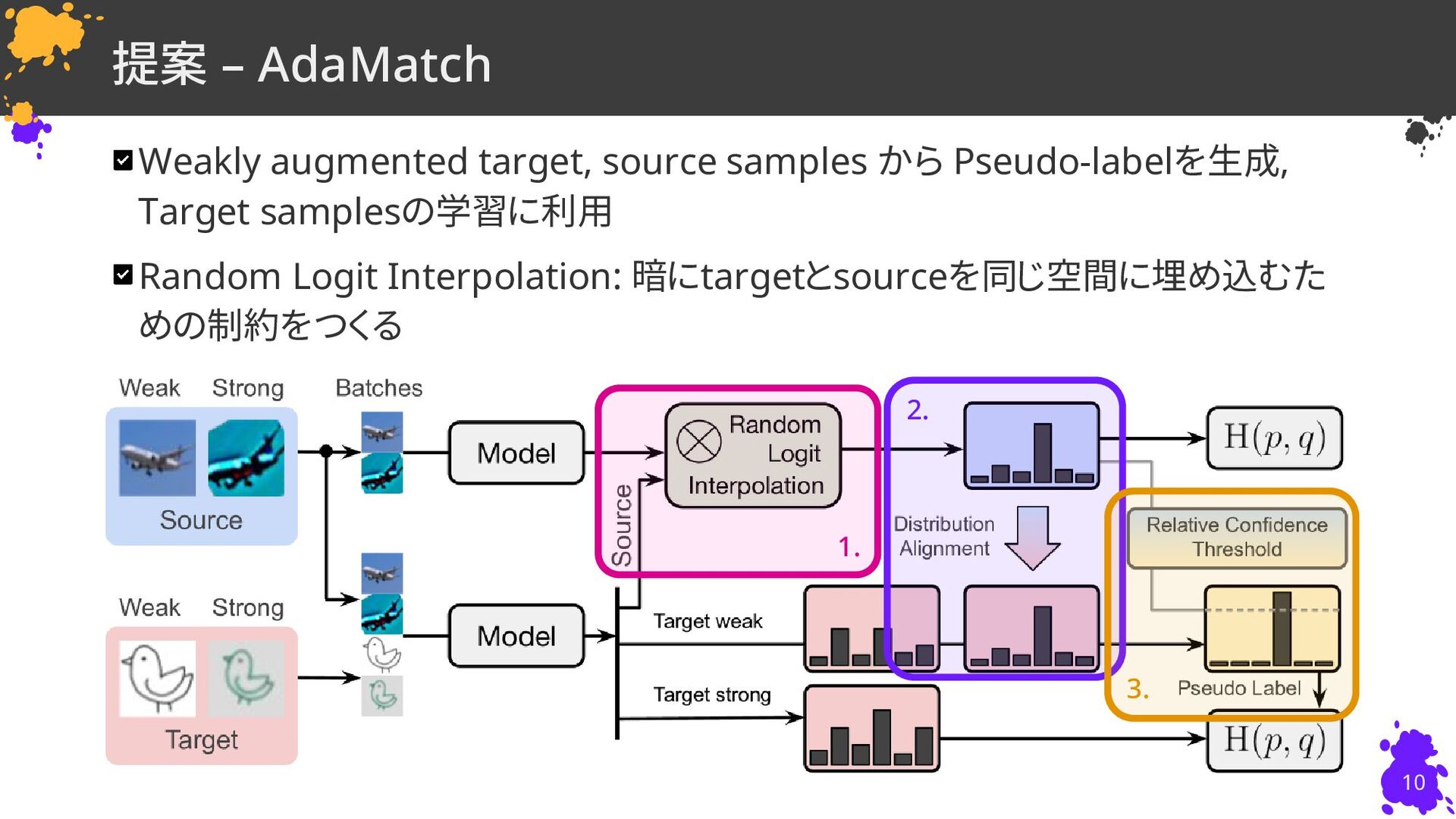
David Berthelot†∗, Rebecca Roelofs†∗, Kihyuk Sohn†, Nicholas Carlini†, Alex Kurakin† † Google Research, (∗ Equal contribution) 慶應義塾大学 杉浦孔明研究室 小槻誠太郎 ICLR22 Poster D. Berthelot, R. Roelofs, K. Sohn, N. Carlini, and A. Kurakin, “AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation,” in ICLR, 2022.
common objects in six different domain. All domains include 345 categories (classes) of objects such as Bracelet, plane, bird and cello. > The domains include clipart: collection of clipart images; real: photos and real world images; sketch: sketches of specific objects; … 23
five most popular digit datasets, MNIST (mt) (55000 samples), MNIST-M (mm) (55000 samples), Synthetic Digits (syn) (25000 samples), SVHN (sv)(73257 samples), and USPS (up) (7438 samples). Each digit dataset includes a different style of 0-9 digit images. 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
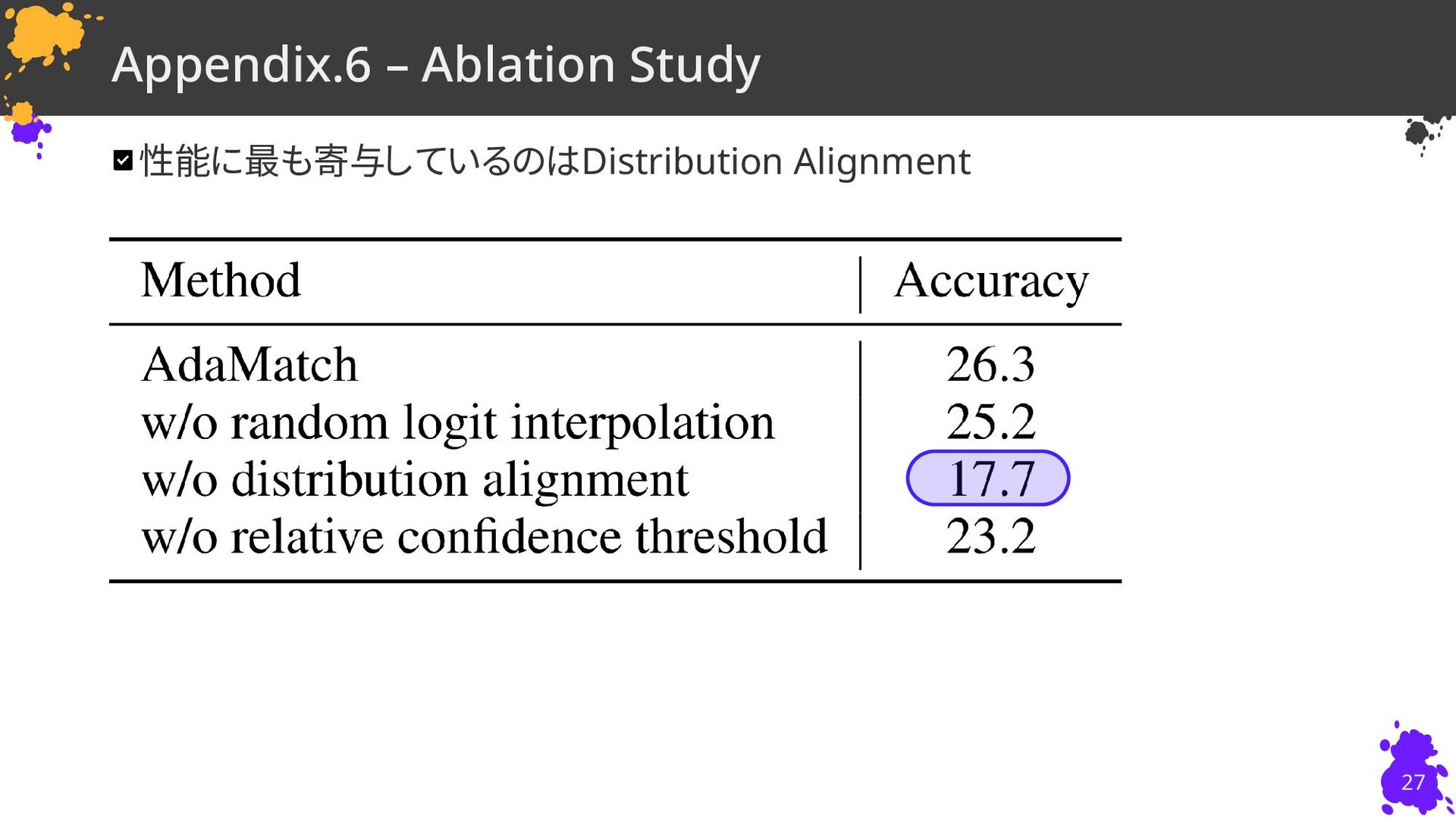{kind=link}