Alexander Bukharin1, Pengcheng He3, Yu Cheng3, Weizhu Chen3, Tuo Zhao1 1: Georgia Institute of Technology, 2: Princeton University, 3: Microsoft Azure AI 慶應義塾大学 杉浦孔明研究室 小槻誠太郎 ICLR23 Poster Q. Zhang, M. Chen, A. Bukharin, P. He, Y. Cheng, W. Chen, and T. Zhao, "Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning," in ICLR, 2023.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![He et al. [He+, ICLR22 (spotlight)] LoRA, Prefix Tuningなどのパラメータ効率の良い学習手法を, 事前学習済みモデル](https://files.speakerdeck.com/presentations/60ab3881b844432081c7564528c69b36/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![重要度 の定義 𝑠(⋅)の定義: [Zhang+, ICML22] に従う 15 AdaLoRA – 2.](https://files.speakerdeck.com/presentations/60ab3881b844432081c7564528c69b36/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
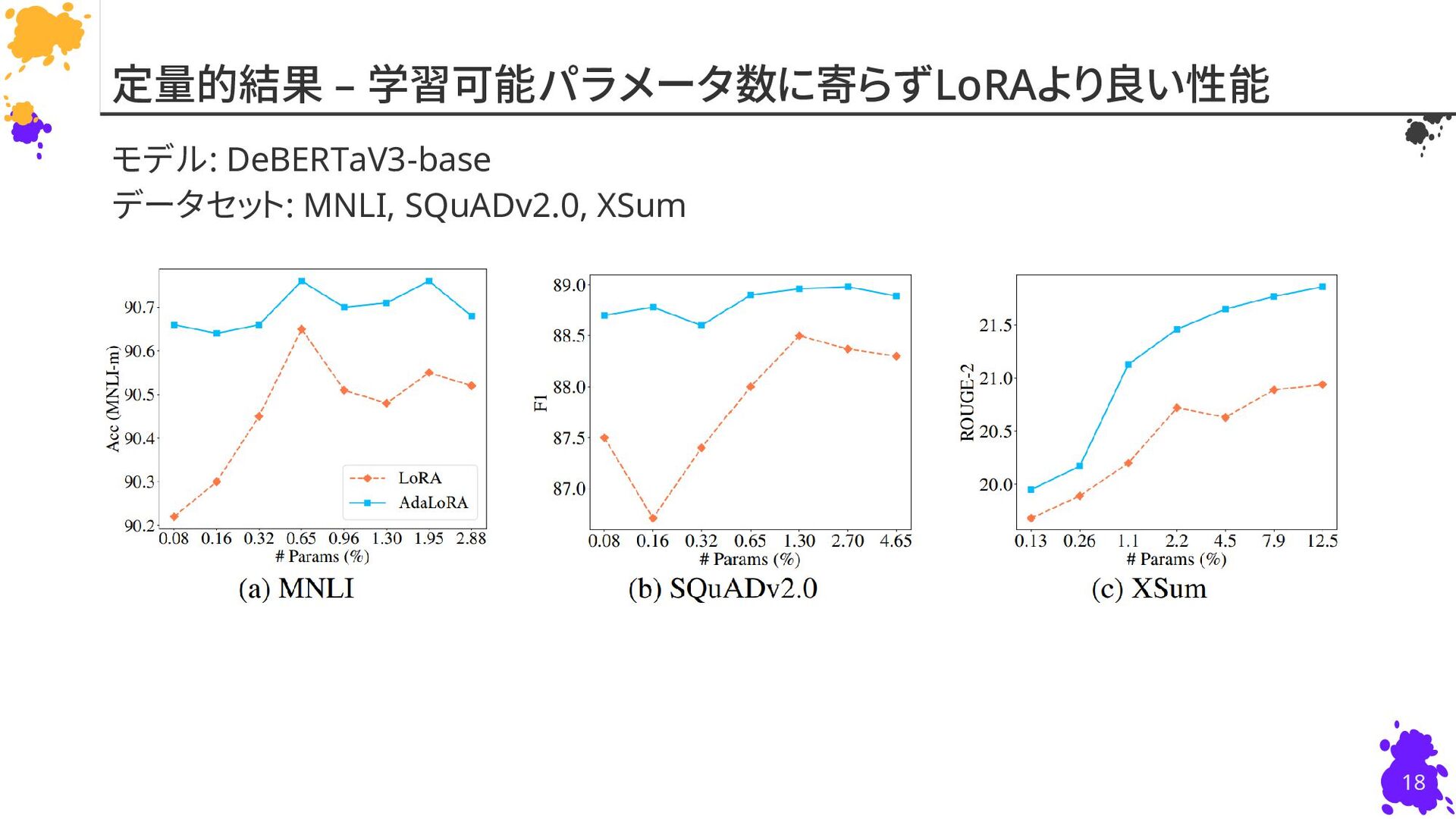{kind=link}
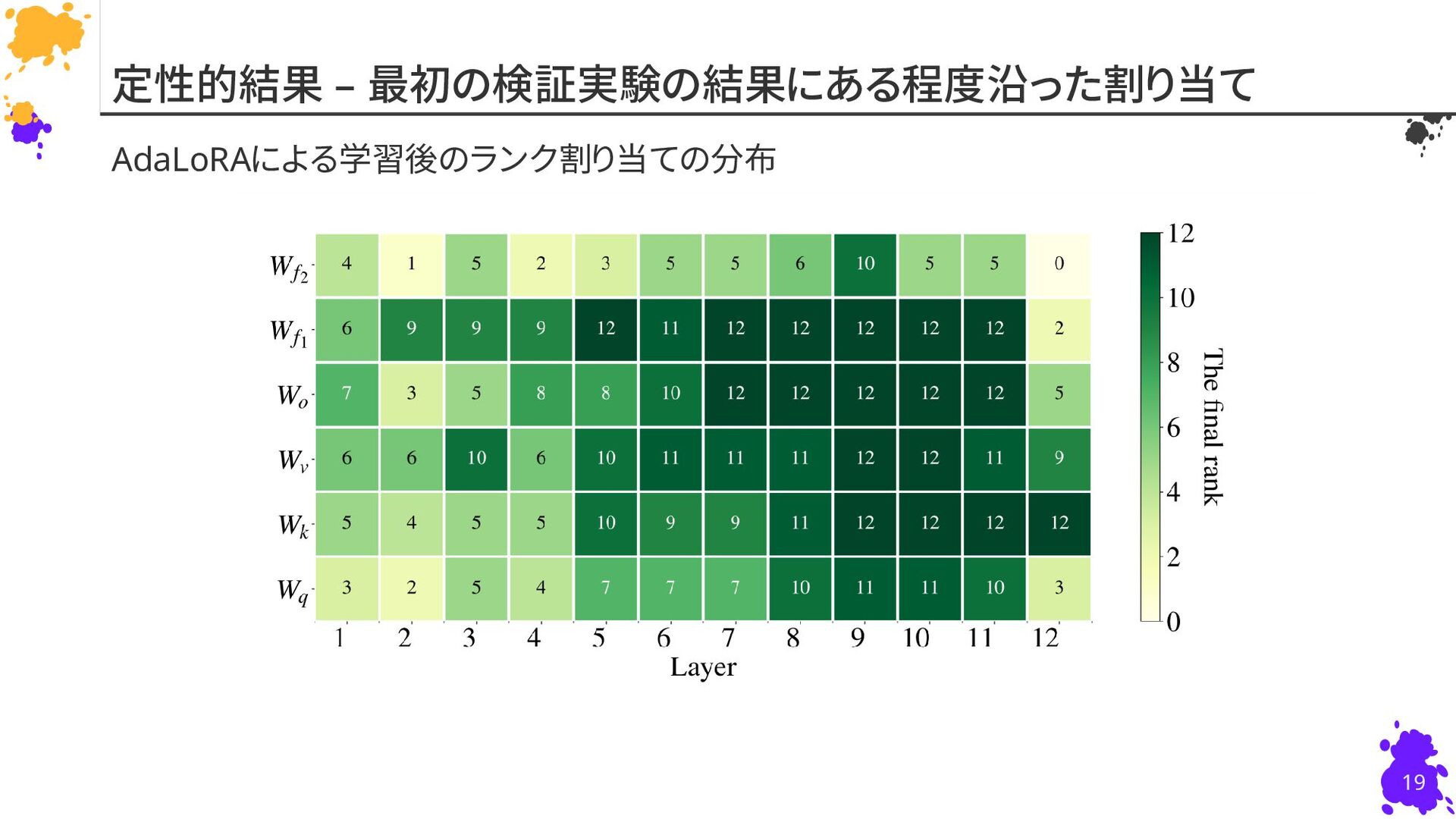{kind=link}
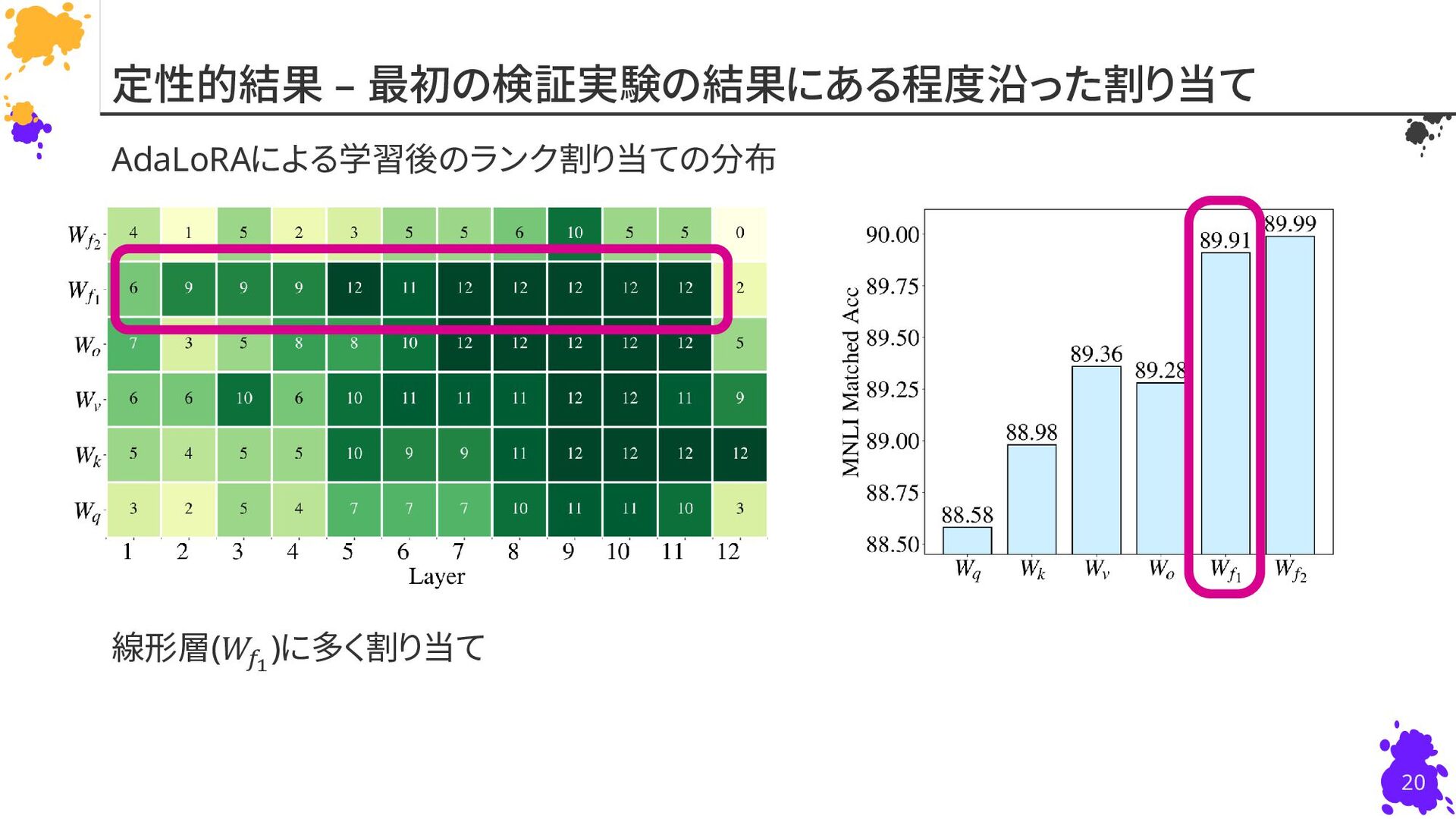{kind=link}
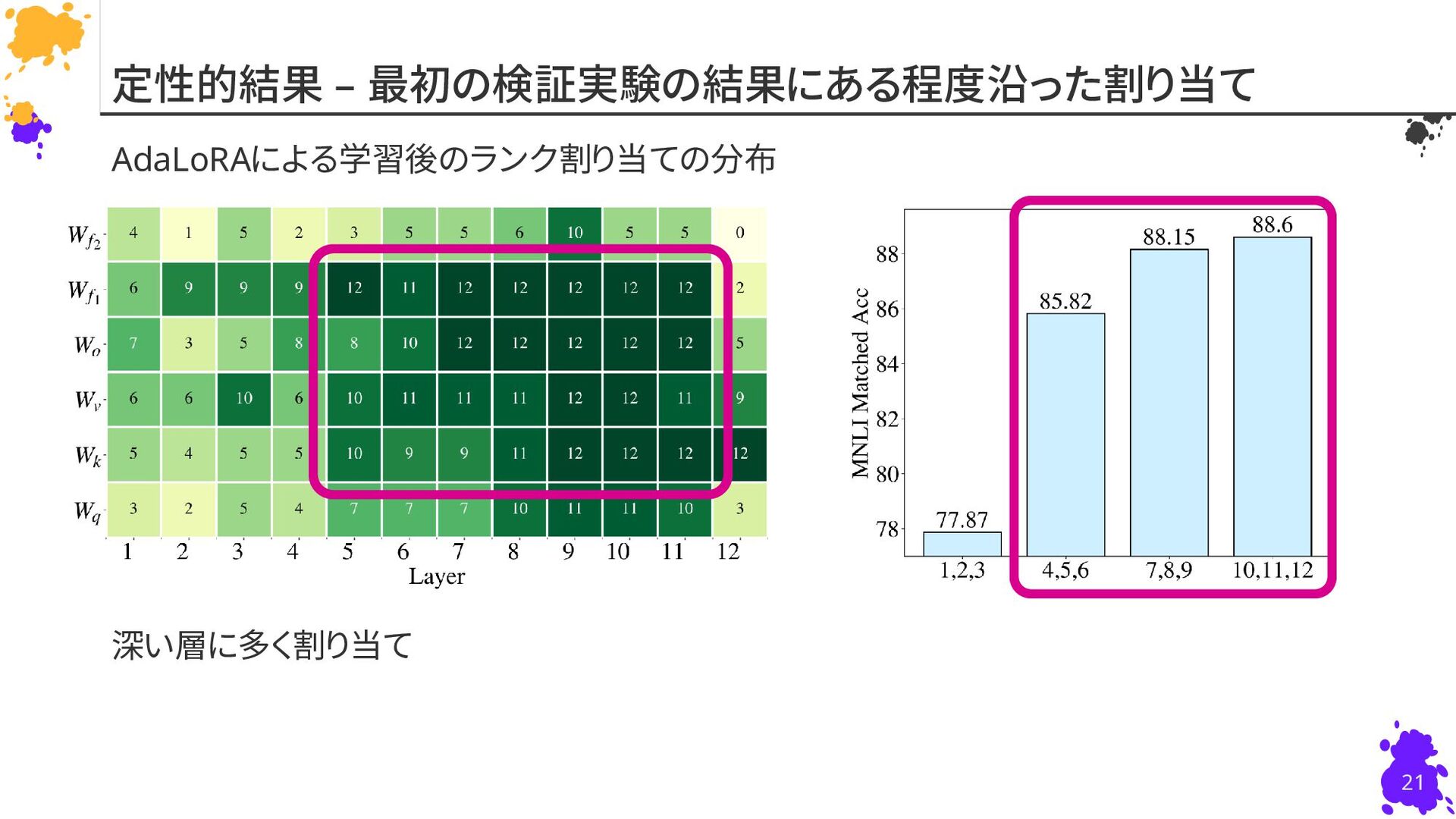{kind=link}
{kind=link}
{kind=link}
{kind=link}