Aishwarya Kamath*♮, Zhe Gan*†♠, Pengchuan Zhang §, Jianfeng Wang†, Linjie Li†, Zicheng Liu†, Ce Liu†, Yann LeCun♮, Nanyun Peng‡, Jianfeng Gao†, Lijuan Wang† †Microsoft ‡University of California, Los Angeles ♮New York University *Equal Technical Contribution ♠Project Lead §Work done while at Microsoft 慶應義塾大学 杉浦孔明研究室 畑中駿平 Dou, Zi-Yi, et al. "Coarse-to-fine vision-language pre-training with fusion in the backbone." NeurIPS 2022.
{kind=link}
{kind=link}
![▸ 現在VLPで高い性能が報告されているタスク(UNITER [Chen+, ECCV20]、LXMERT [Tan+, EMNLP19] など) ▹ Visual Question](https://files.speakerdeck.com/presentations/5a6900fb4b8140b7827a57e1617d04eb/slide_2.jpg){kind=link}
![▸ Visualのみのタスクの例:画像分類・物体検出 ▸ VLタスクとして位置づけることで恩恵を得られることが示されている ▹ MDETER [Kamath+, ICCV21] ▹ GLIP](https://files.speakerdeck.com/presentations/5a6900fb4b8140b7827a57e1617d04eb/slide_3.jpg){kind=link}
{kind=link}
![6 関連研究:画像・領域レベルに分類される タスク 手法 概要 画像レベル ALBEF [Li+, NeurIPS21] ユニモーダルな表現を融合する前に画像表現とテキスト表現](https://files.speakerdeck.com/presentations/5a6900fb4b8140b7827a57e1617d04eb/slide_5.jpg){kind=link}
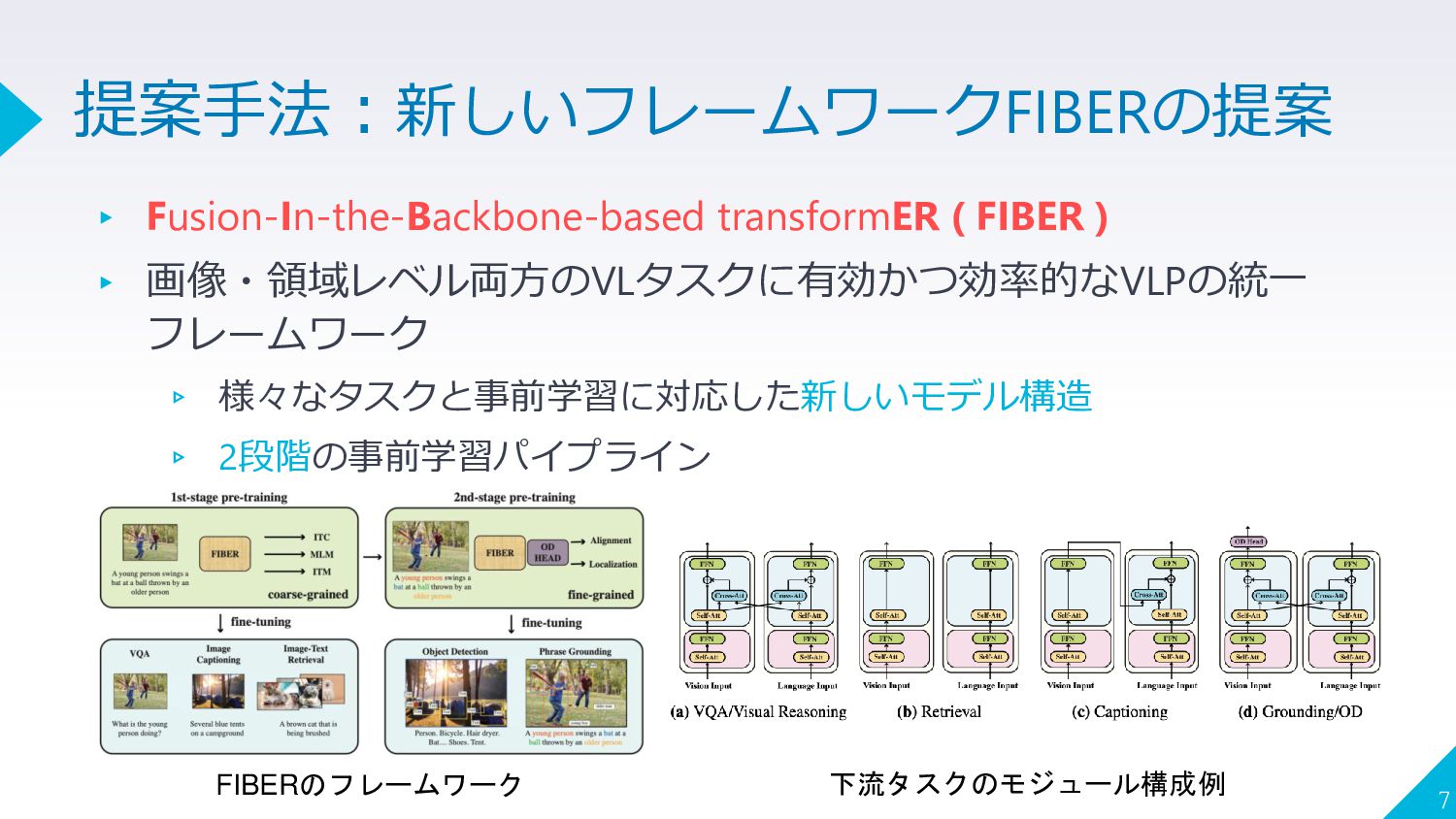{kind=link}
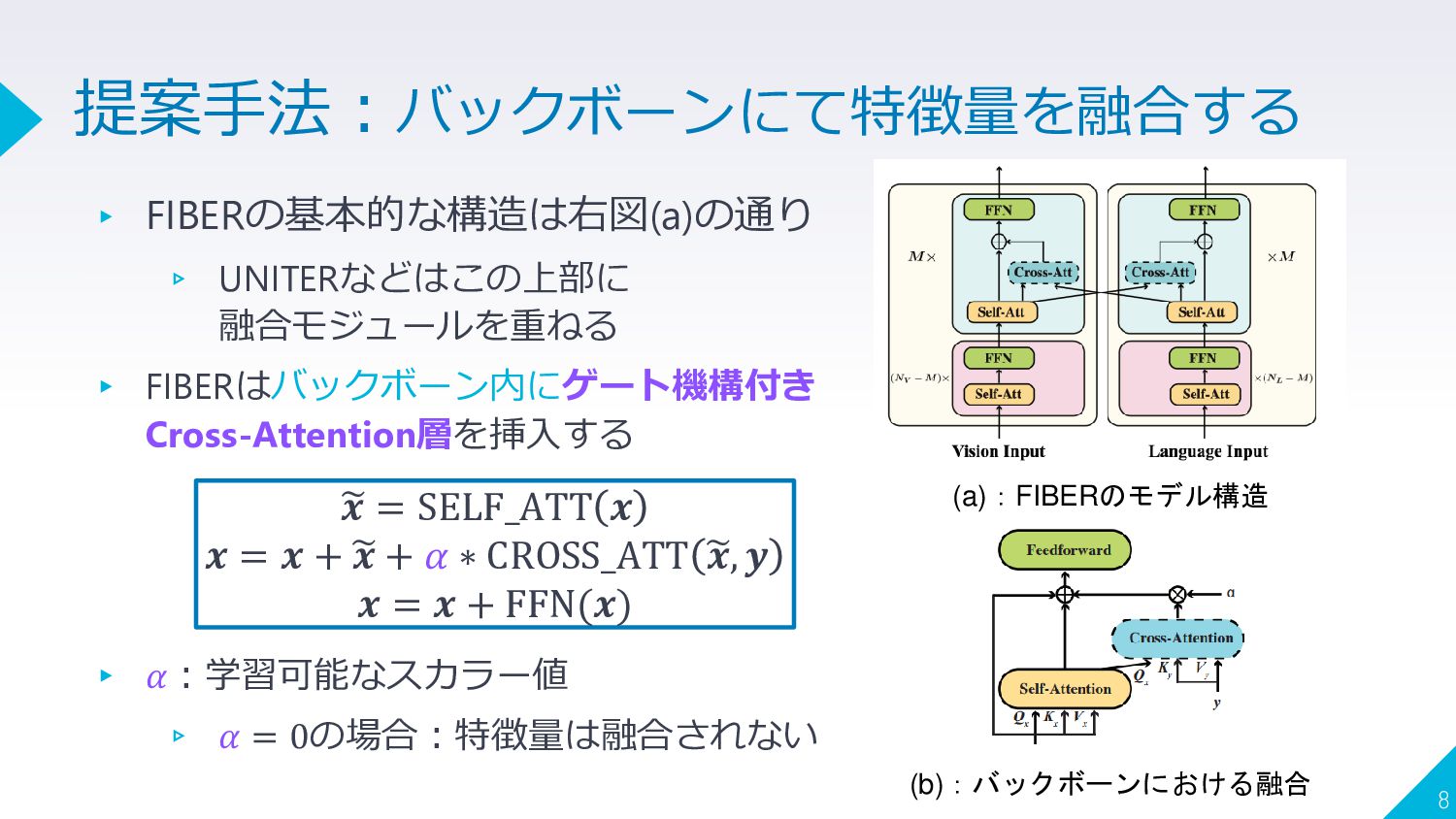{kind=link}
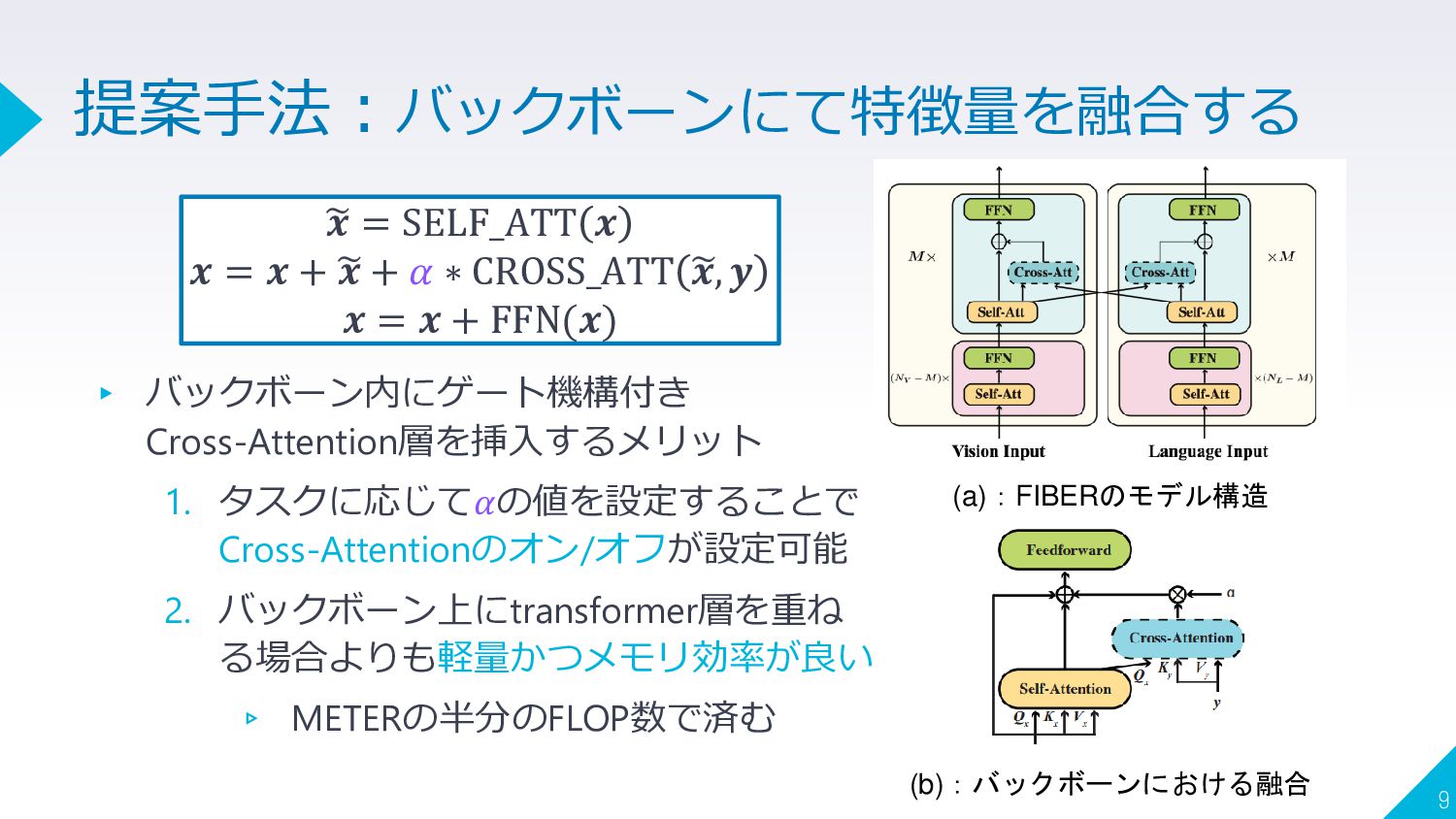{kind=link}
{kind=link}
{kind=link}
{kind=link}
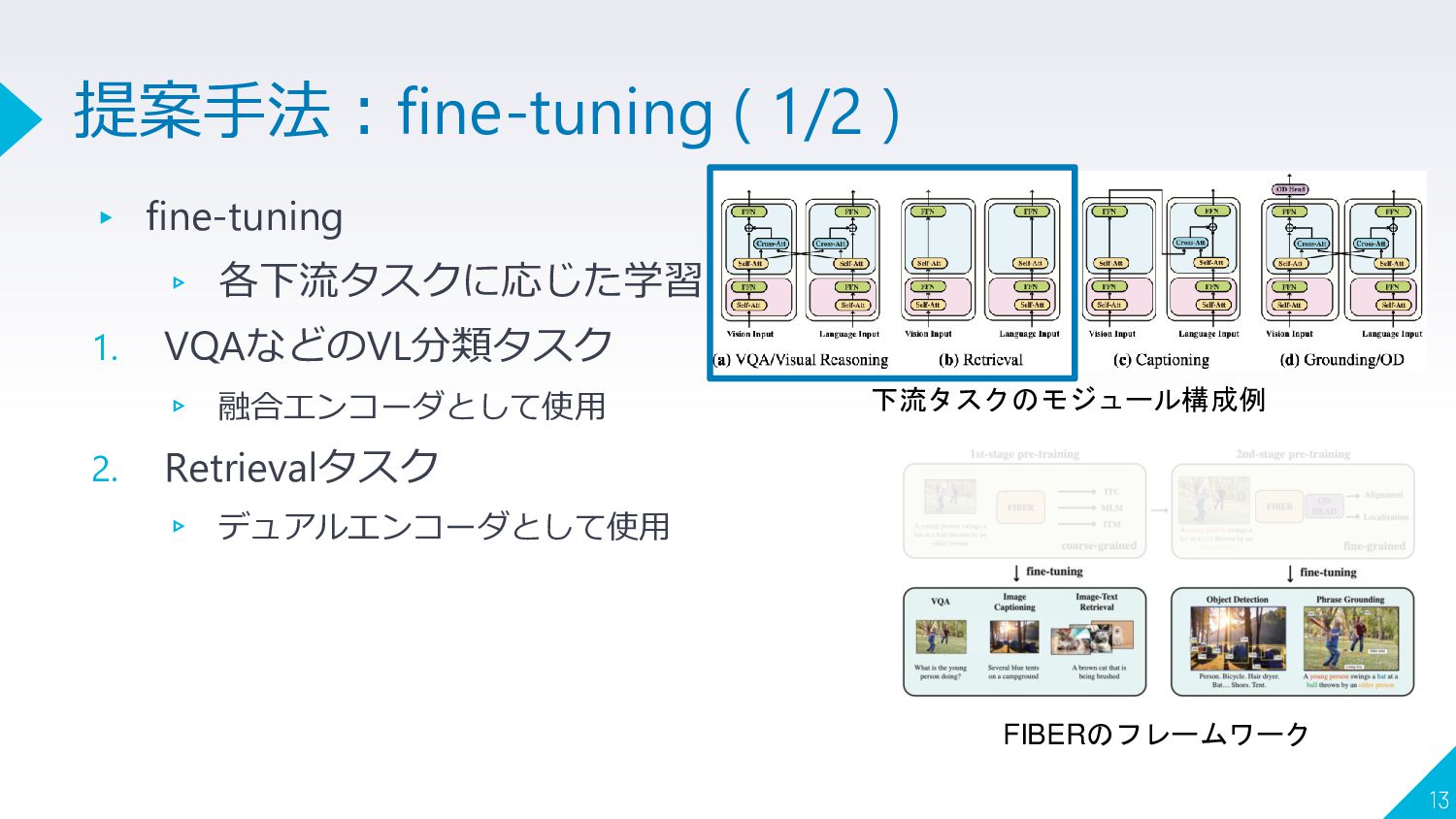{kind=link}
{kind=link}
{kind=link}
{kind=link}
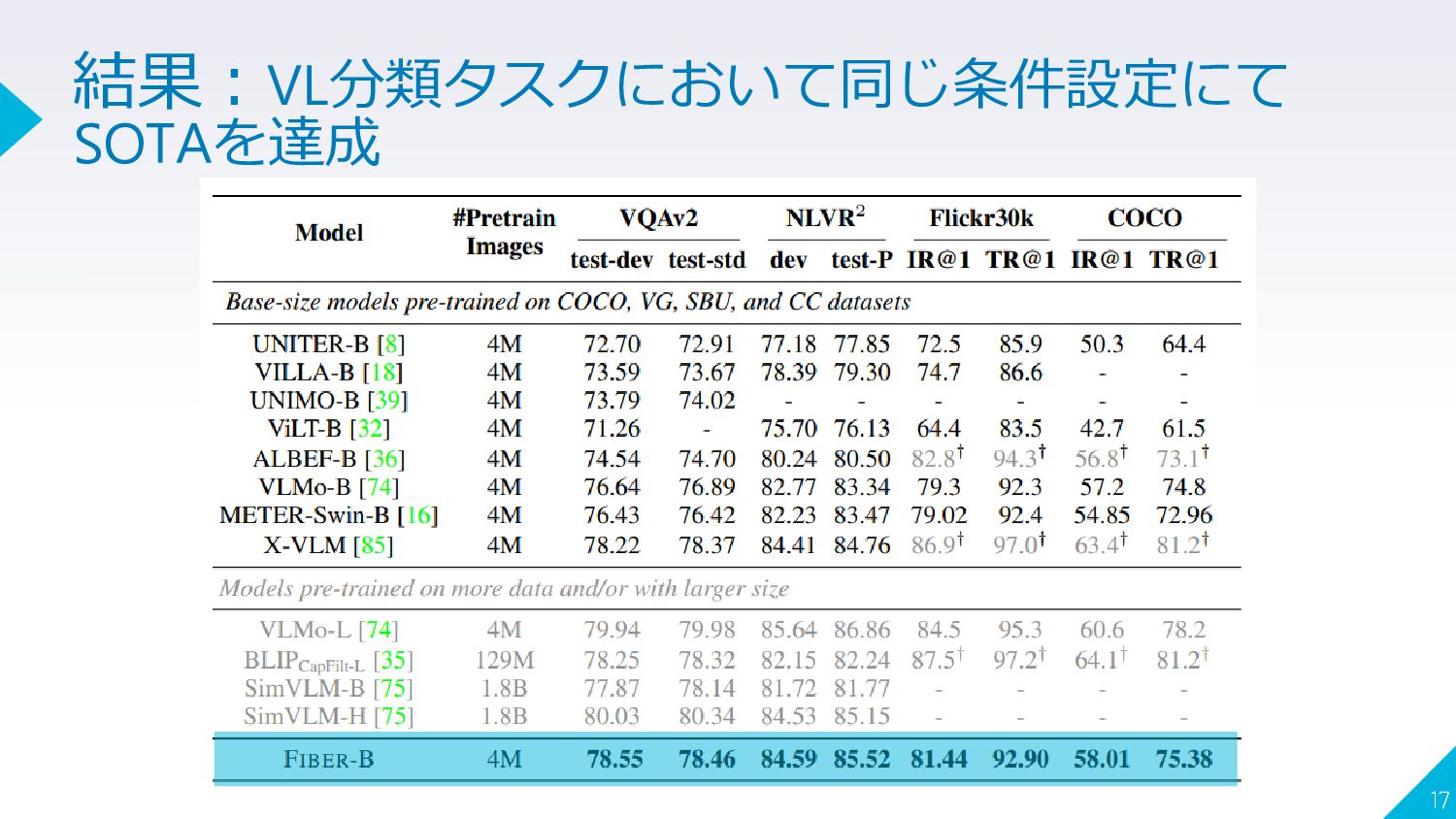{kind=link}
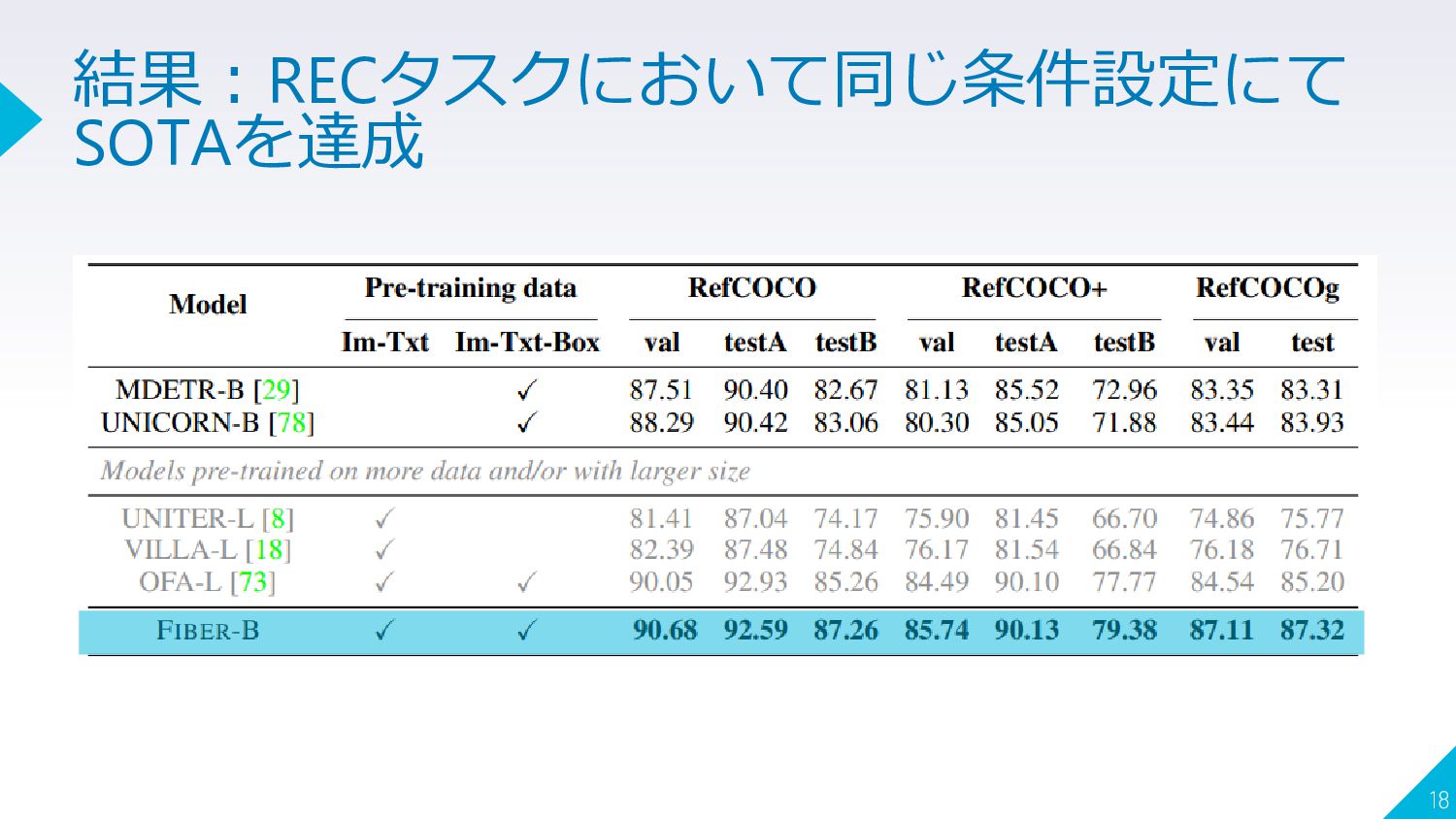{kind=link}
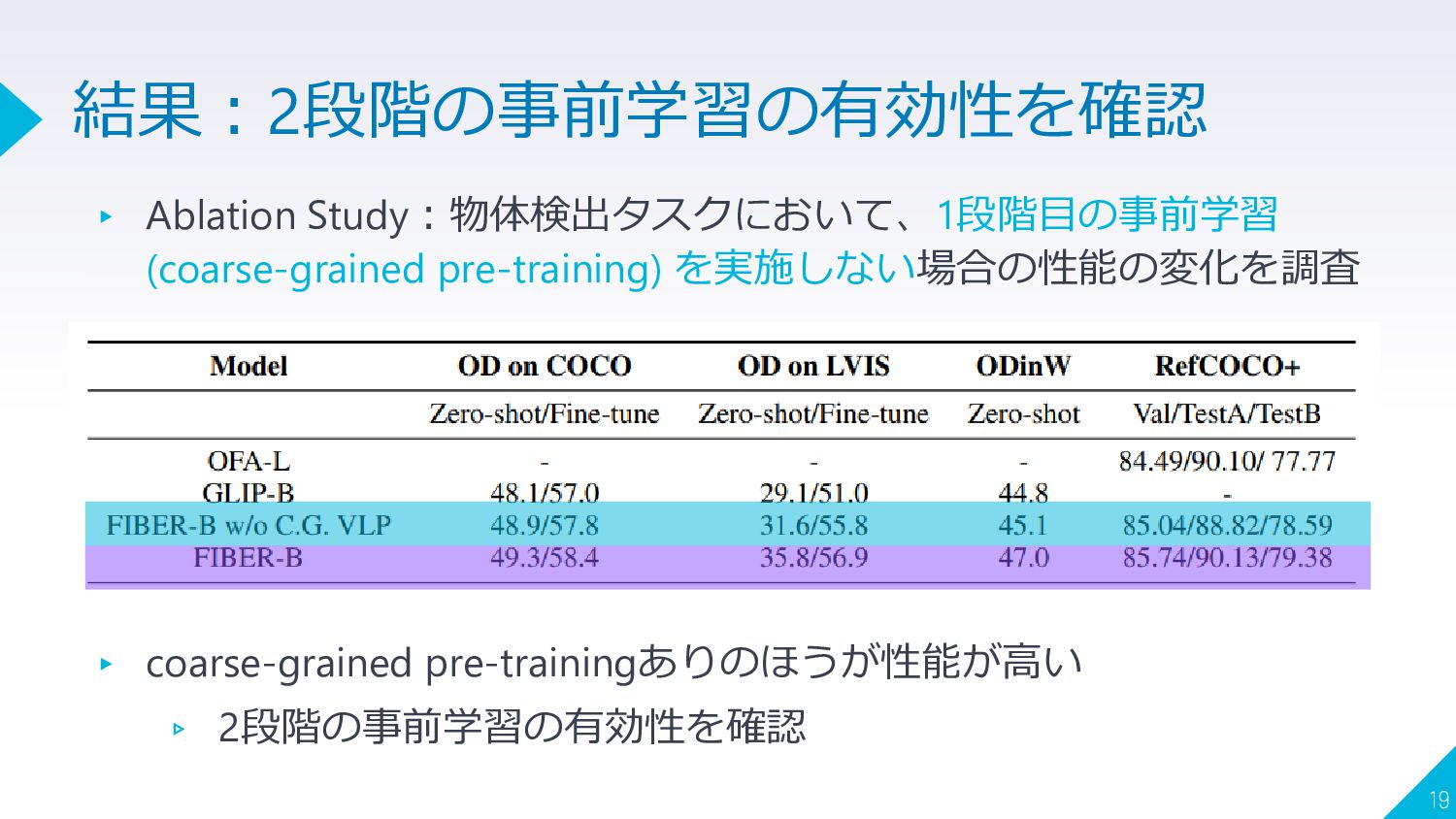{kind=link}
{kind=link}