Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Shifting More Attention to Visua...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 13, 2022
Technology
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Shifting More Attention to Visual Backbone: Query-modulated Refinement Networks for End-to-End Visual Grounding
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 13, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
76
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
84
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
96
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
世界、断片、モデル。そして理解
ardbeg1958
1
130
シンガポールで登壇してきます
yama3133
0
260
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
160
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
公式ドキュメントの歩き方etc
coco_se
1
120
タスクの複雑さでモデルを選ぶ ── Thompson Samplingで動かす“トークン/コスト最適化
satohy0323
0
590
SRE Next 2026 何でも屋からの脱却
bto
0
1k
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
250
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
330
全員がリーダーである世界へ キリマンジャロ登頂とシェアド・リーダー
jinwatanabe
0
100
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
0
190
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
150
Featured
See All Featured
Statistics for Hackers
jakevdp
799
230k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
Marketing to machines
jonoalderson
1
5.6k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
330
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
56k
Writing Fast Ruby
sferik
630
63k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
A Soul's Torment
seathinner
6
3.1k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
Transcript
Shifting More Attention to Visual Backbone: Query-modulated Refinement Networks for
End-to-End Visual Grounding Jiabo Ye1, Jumfemg Tian2, Ming Yan2, Xiaoshan Yang3, Xuwu Wang4, Ji Zhang2, Liang He1, Xin Lin1 1East China Normal University, 2Alibaba Group, 3NLPR, 4Fudan University CVPR 2022 杉浦孔明研究室 神原 元就 Ye, J., Tian, J., Yan, M., Yang, X., Wang, X., Zhang, J., et al. (2022). Shifting More Attention to Visual Backbone: Query-modulated Refinement Networks for End-to-End Visual Grounding. In CVPR (pp. 15502-15512).
背景:言語と画像の接地はマルチモーダル推論に重要 3 The Power of PowerPoint - thepopp.com VQA 画像キャプション生成
「画像には何が写っているか?」 「2つのリンゴ」 「2つの赤いリンゴがあります」 言語と画像を適切に接地することで推論可能 「画像には何が写っているか?」 「リンゴは全部で何個か?」 「緑のリンゴは何個あるか?」 … 入力されるテキストに基づい た画像特徴量を獲得したい VQA
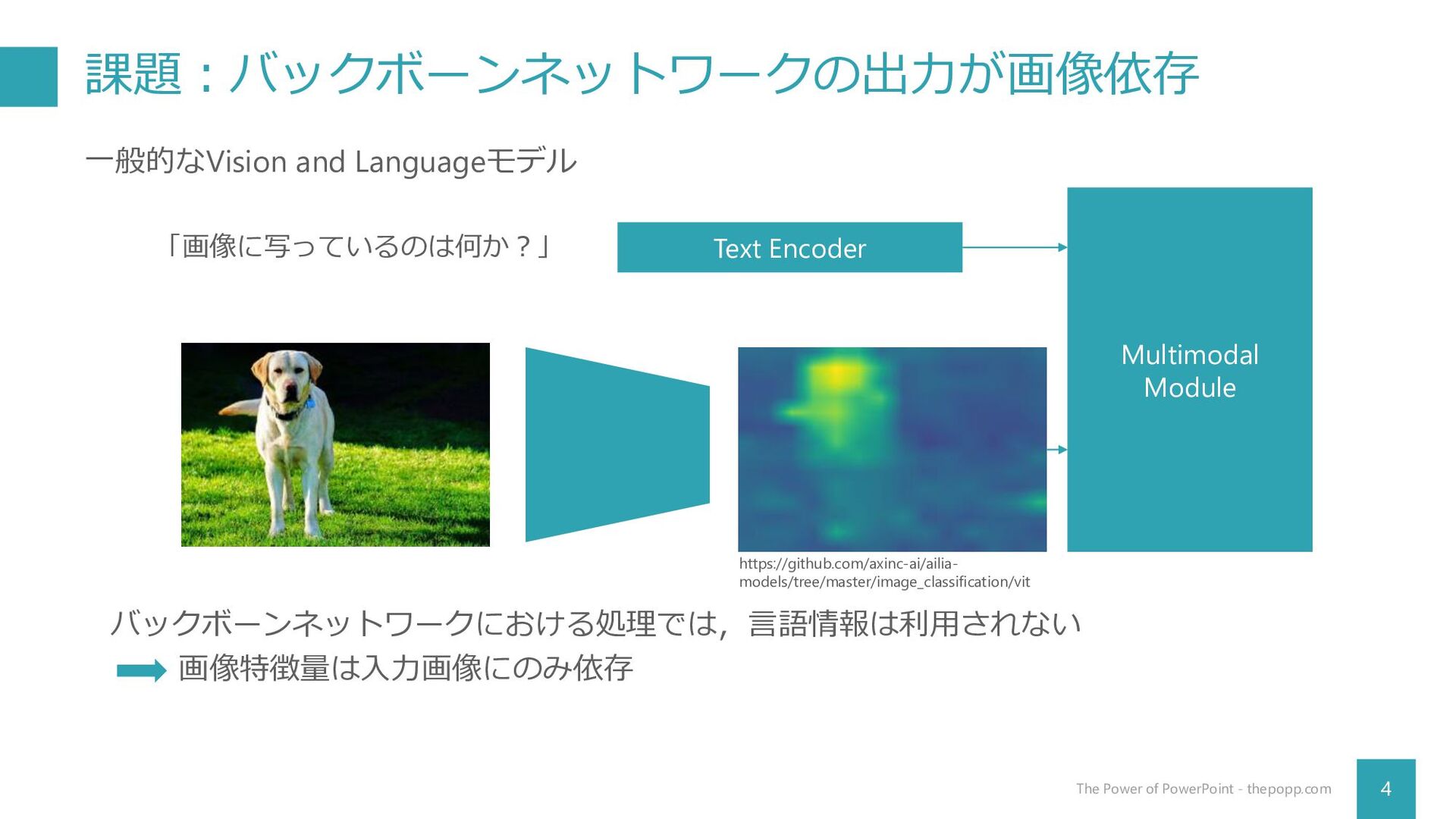
課題:バックボーンネットワークの出力が画像依存 4 The Power of PowerPoint - thepopp.com https://github.com/axinc-ai/ailia- models/tree/master/image_classification/vit
画像特徴量は入力画像にのみ依存 「画像に写っているのは何か?」 Multimodal Module Text Encoder 一般的なVision and Languageモデル バックボーンネットワークにおける処理では,言語情報は利用されない
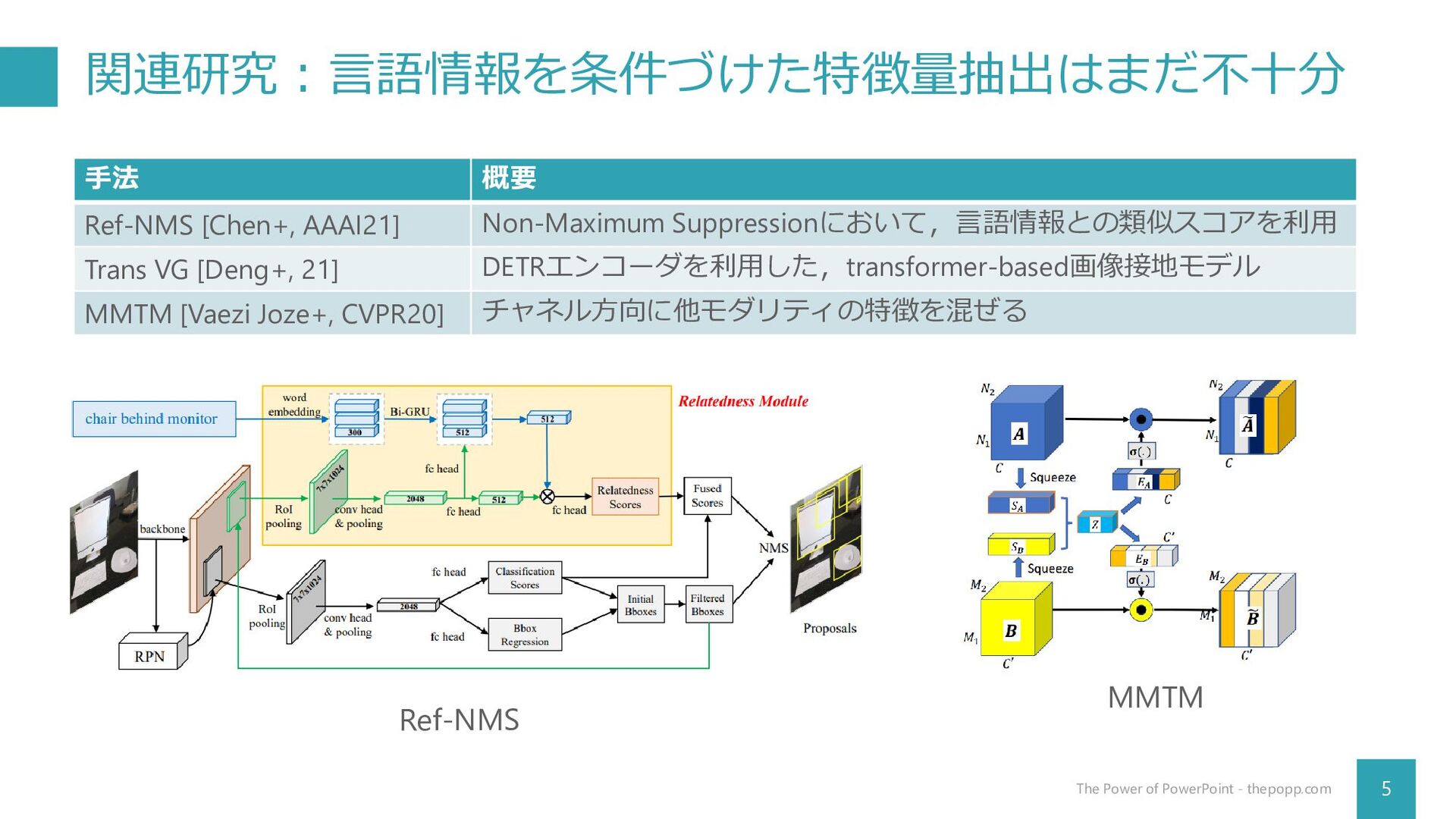
関連研究:言語情報を条件づけた特徴量抽出はまだ不十分 5 The Power of PowerPoint - thepopp.com 手法 概要
Ref-NMS [Chen+, AAAI21] Non-Maximum Suppressionにおいて,言語情報との類似スコアを利用 Trans VG [Deng+, 21] DETRエンコーダを利用した,transformer-based画像接地モデル MMTM [Vaezi Joze+, CVPR20] チャネル方向に他モダリティの特徴を混ぜる Ref-NMS MMTM
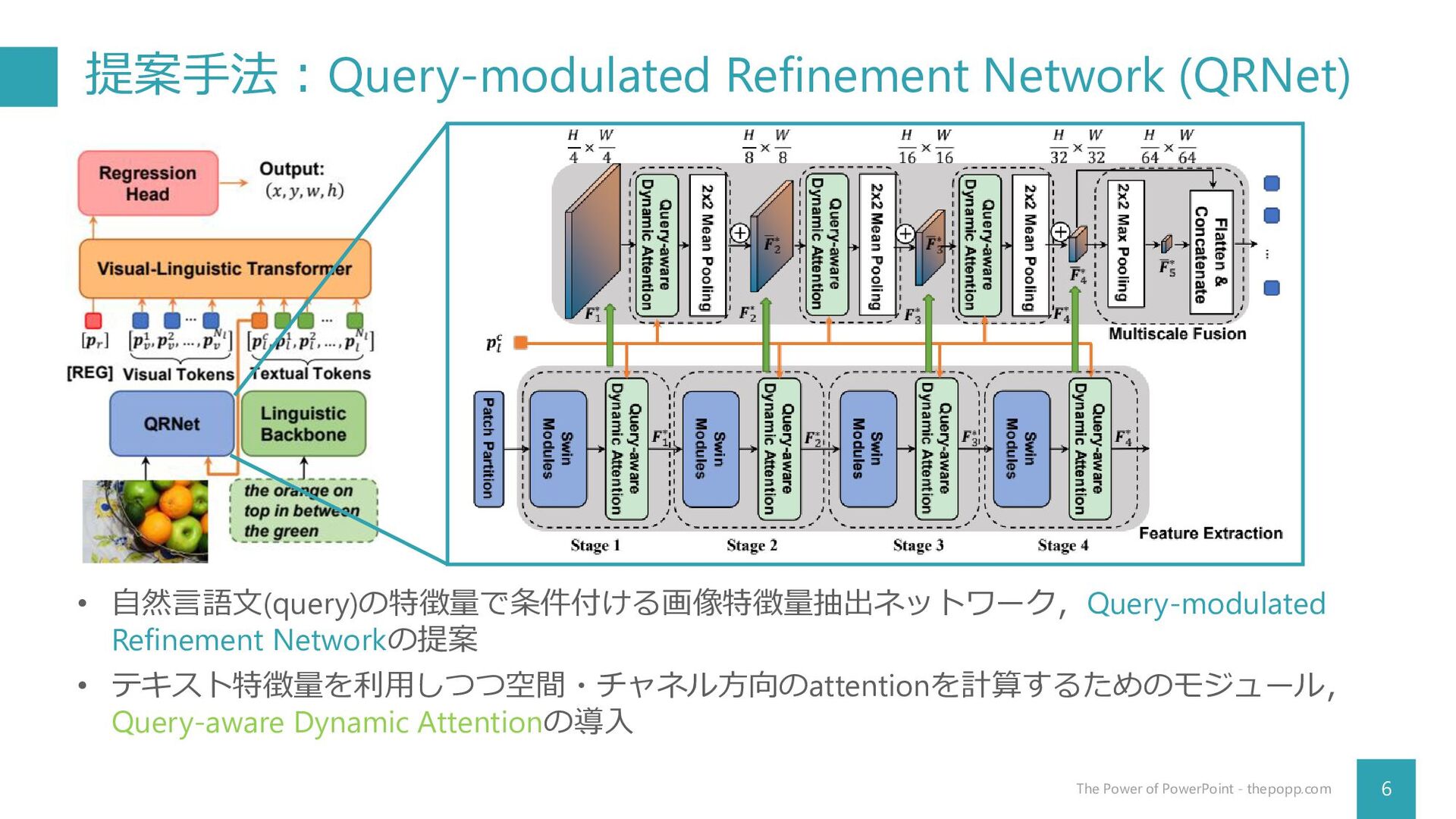
提案手法:Query-modulated Refinement Network (QRNet) 6 The Power of PowerPoint -
thepopp.com • 自然言語文(query)の特徴量で条件付ける画像特徴量抽出ネットワーク,Query-modulated Refinement Networkの提案 • テキスト特徴量を利用しつつ空間・チャネル方向のattentionを計算するためのモジュール, Query-aware Dynamic Attentionの導入
QRNet:自然言語文から獲得した[CLS]トークンを利用 7 The Power of PowerPoint - thepopp.com 画像 𝐼,自然言語文
𝑞 𝑻 = 𝑓BERT 𝑞 = {𝒑𝑙 𝑐, 𝒑𝑙 1, … , 𝒑 𝑙 𝑁𝑣} Linguistic Backbone:BERT Embedder ネットワーク入力 QRNetの入出力 𝑽 = 𝑓QRNet 𝐼, 𝒑𝑙 𝑐
QRNet:2つのモジュールから構成 8 The Power of PowerPoint - thepopp.com Multiscale Fusion
Feature Extraction • 異なる解像度で計算されたattentionを 混ぜ合わせる • 出力𝑽を生成 • Swin-Transformer[Liu+, ICCV21]を拡張 • 言語情報を利用しつつ画像特徴を抽出 • 特徴量はMultiscale Fusionで利用
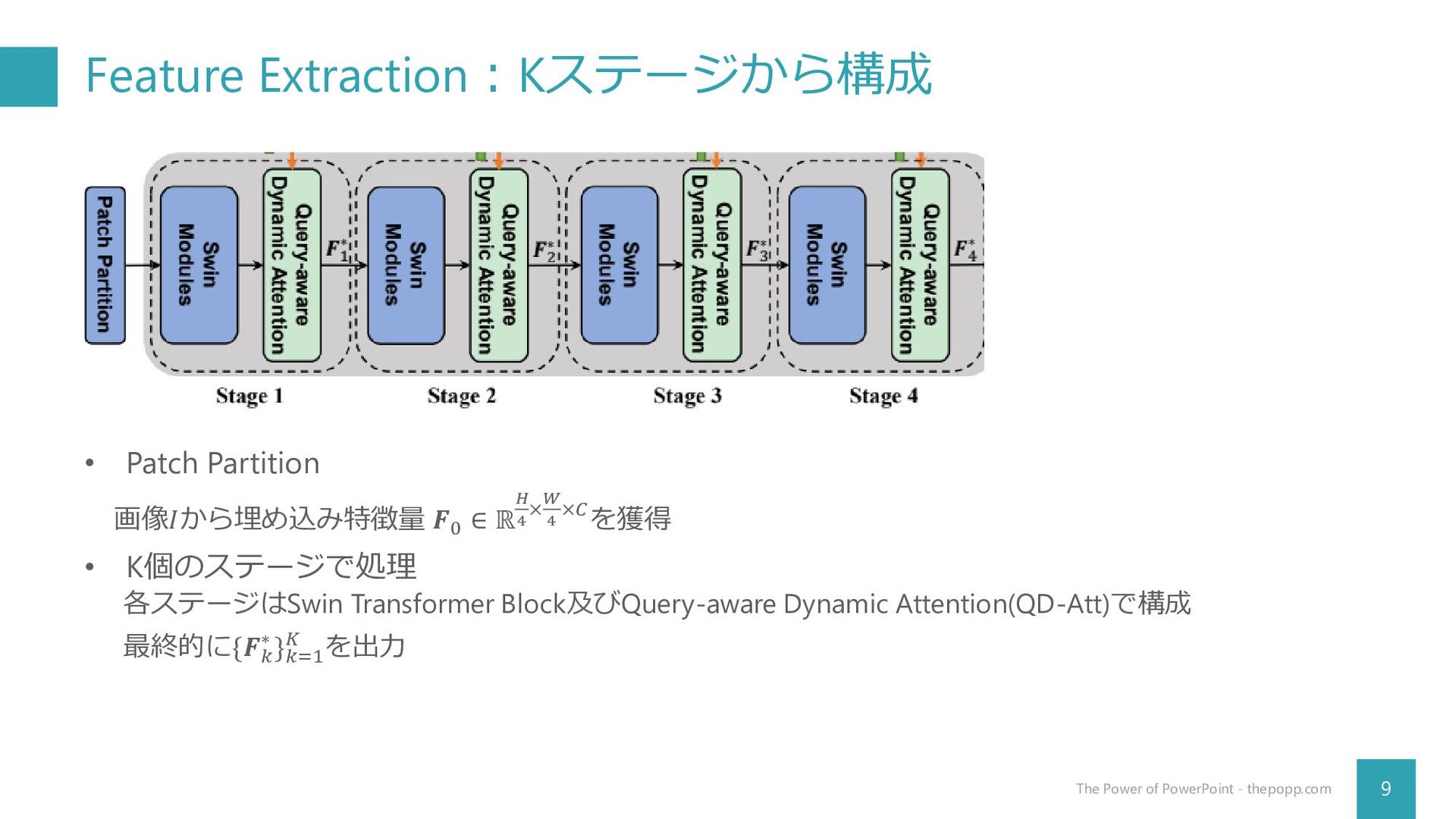
Feature Extraction:Kステージから構成 9 The Power of PowerPoint - thepopp.com •
Patch Partition 画像𝐼から埋め込み特徴量 𝑭0 ∈ ℝ 𝐻 4 ×𝑊 4 ×𝐶を獲得 • K個のステージで処理 各ステージはSwin Transformer Block及びQuery-aware Dynamic Attention(QD-Att)で構成 最終的に{𝑭𝑘 ∗ }𝑘=1 𝐾 を出力
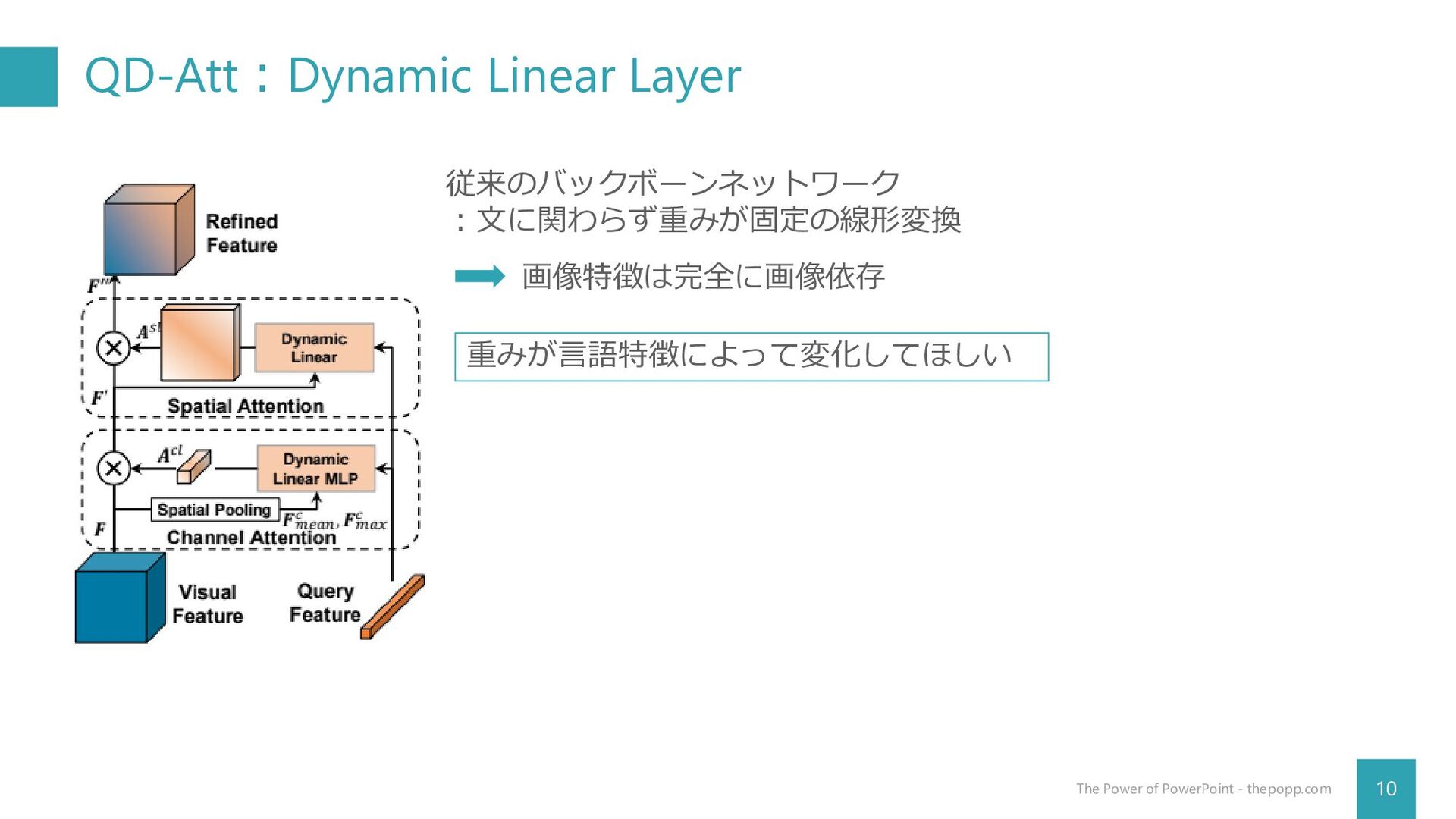
QD-Att:Dynamic Linear Layer 10 The Power of PowerPoint - thepopp.com
従来のバックボーンネットワーク :文に関わらず重みが固定の線形変換 重みが言語特徴によって変化してほしい 画像特徴は完全に画像依存
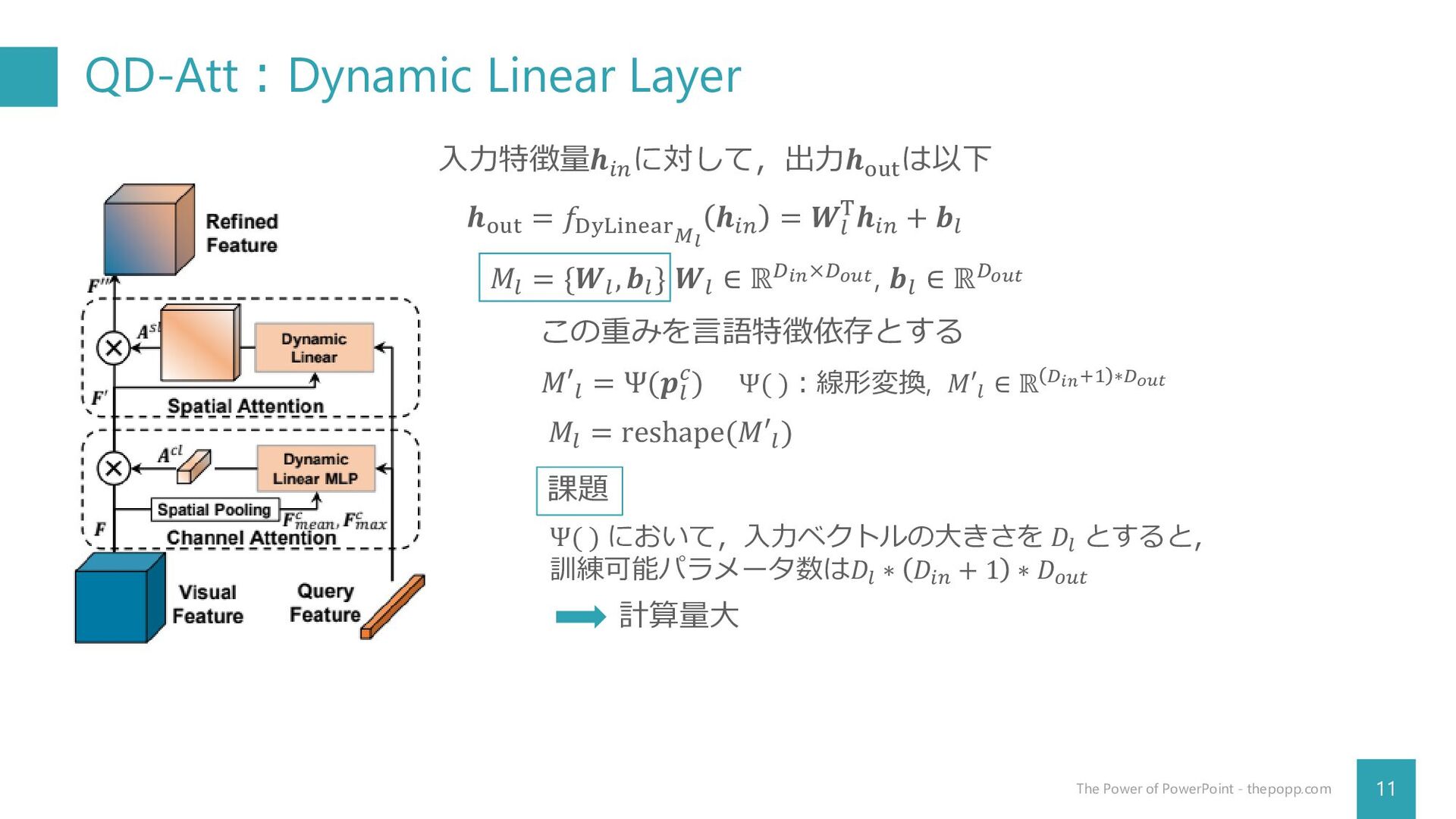
QD-Att:Dynamic Linear Layer 11 The Power of PowerPoint - thepopp.com
𝒉out = 𝑓DyLinear𝑀𝑙 𝒉𝑖𝑛 = 𝑾𝑙 T𝒉𝑖𝑛 + 𝒃𝑙 入力特徴量𝒉𝑖𝑛 に対して,出力𝒉out は以下 𝑀𝑙 = {𝑾𝑙 , 𝒃𝑙 } 𝑾𝑙 ∈ ℝ𝐷𝑖𝑛×𝐷𝑜𝑢𝑡, 𝒃𝑙 ∈ ℝ𝐷𝑜𝑢𝑡 この重みを言語特徴依存とする 𝑀′𝑙 = Ψ(𝒑𝑙 𝑐) Ψ( ):線形変換, 𝑀′𝑙 ∈ ℝ 𝐷𝑖𝑛+1 ∗𝐷𝑜𝑢𝑡 課題 Ψ( ) において,入力ベクトルの大きさを 𝐷𝑙 とすると, 訓練可能パラメータ数は𝐷𝑙 ∗ 𝐷𝑖𝑛 + 1 ∗ 𝐷𝑜𝑢𝑡 計算量大 𝑀𝑙 = reshape(𝑀′𝑙 )
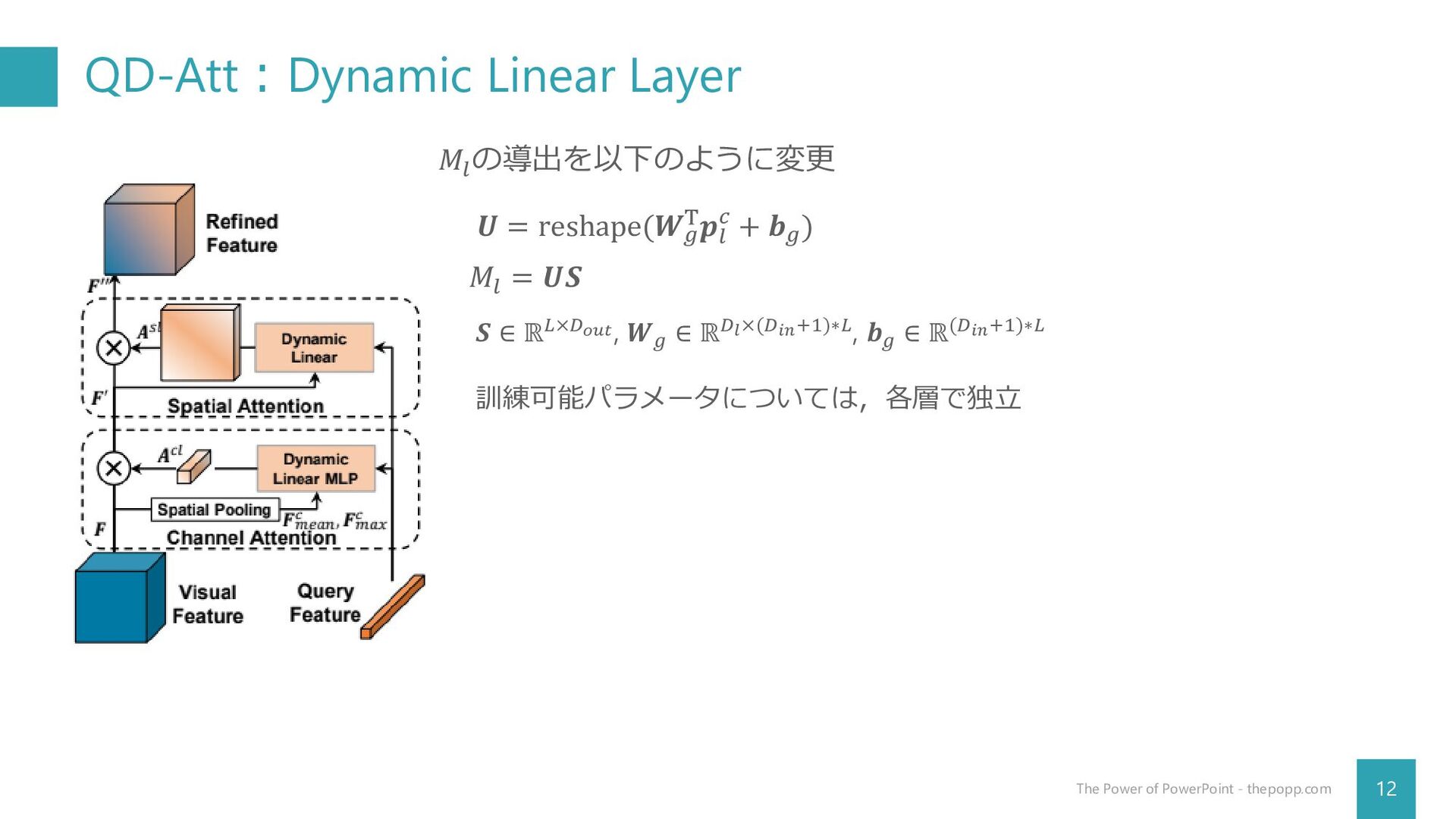
QD-Att:Dynamic Linear Layer 12 The Power of PowerPoint - thepopp.com
𝑀𝑙 の導出を以下のように変更 𝑼 = reshape(𝑾𝑔 T𝒑𝑙 𝑐 + 𝒃𝑔 ) 𝑀𝑙 = 𝑼𝑺 𝑺 ∈ ℝ𝐿×𝐷𝑜𝑢𝑡, 𝑾𝑔 ∈ ℝ𝐷𝑙×(𝐷𝑖𝑛+1)∗𝐿, 𝒃𝑔 ∈ ℝ(𝐷𝑖𝑛+1)∗𝐿 訓練可能パラメータについては,各層で独立
Channel & Spatial Attention 13 The Power of PowerPoint -
thepopp.com 言語情報を利用しつつ,チャネル・空間方向のattentionを計算 1段階目:Channel Attention • 空間方向に最大値/平均プーリング 𝑭max 𝑐 , 𝑭mean 𝑐 ∈ ℝ1×1×𝐷𝑣 • Dynamic Linear Layer 入力:画像特徴量𝑭 ∈ ℝ𝐻×𝑊×𝐷𝑣,言語特徴量𝒑𝑙 𝑐 𝑭mean 𝑐𝑙 = 𝑓DyLinear1 (ReLU(𝑓DyLinear2 (𝑭mean 𝑐 ))) 𝑭max 𝑐𝑙 = 𝑓DyLinear1 (ReLU(𝑓DyLinear2 (𝑭max 𝑐 ))) • Attentionの計算,アダマール積 𝑨𝑐𝑙 = sigmoid(𝑭mean 𝑐𝑙 + 𝑭m𝑎𝑥 𝑐𝑙 ) 𝑭′ = 𝑨𝑐𝑙⨂𝑭
Channel & Spatial Attention 14 The Power of PowerPoint -
thepopp.com 言語情報を利用しつつ,チャネル・空間方向のattentionを計算 2段階目:Spatial Attention 入力:画像特徴量𝑭 ∈ ℝ𝐻×𝑊×𝐷𝑣,言語特徴量𝒑𝑙 𝑐 • Attentionの計算,アダマール積 𝑨𝑠𝑙 = sigmoid(𝑓DyLinear3 𝑭′ ) 𝑭′′ = 𝑨𝑠𝑙⨂𝑭′ 𝑭′′ ∈ ℝ𝐻×𝑊×𝐷𝑣
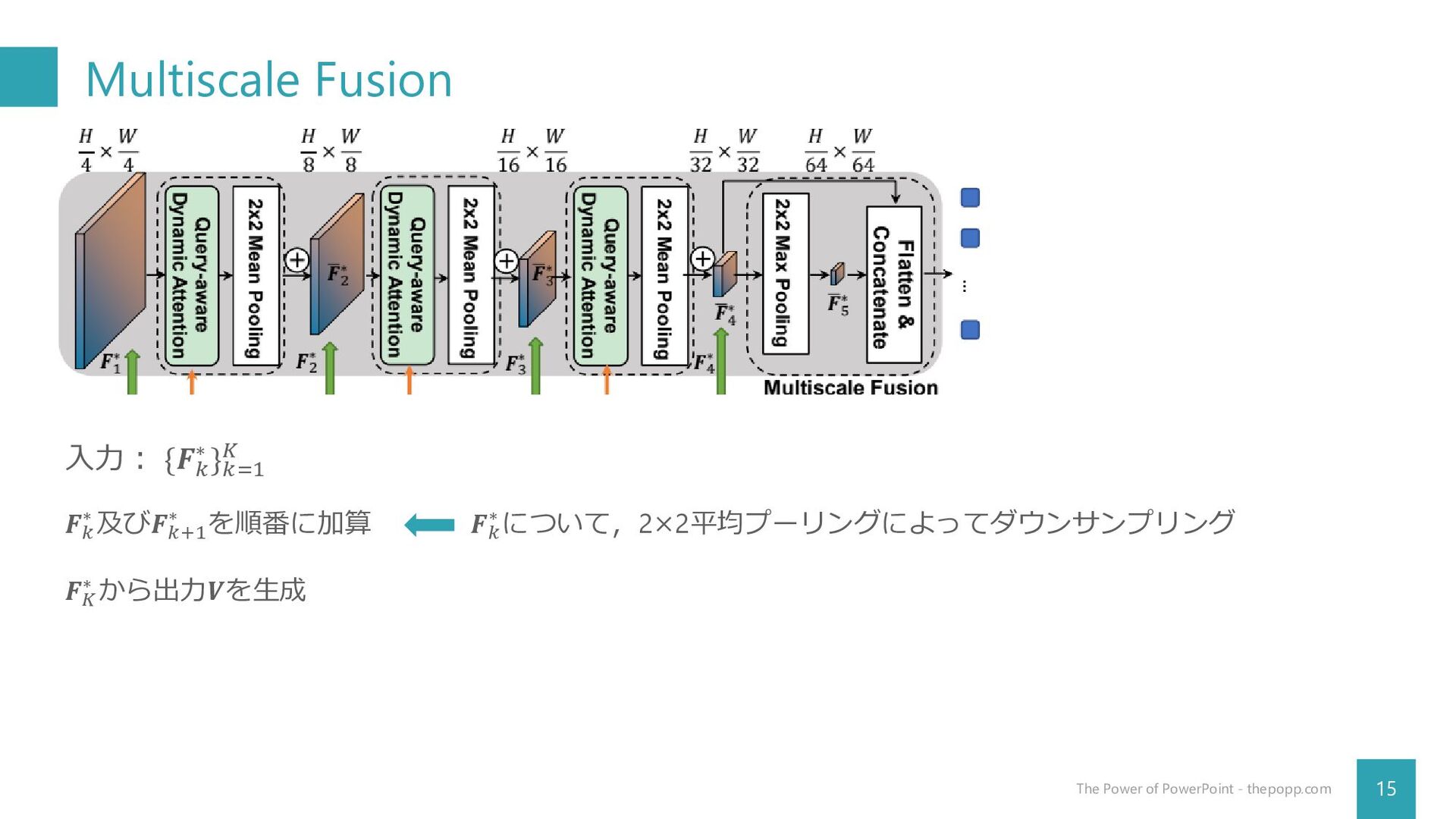
Multiscale Fusion 15 The Power of PowerPoint - thepopp.com 入力:
{𝑭𝑘 ∗ }𝑘=1 𝐾 𝑭𝑘 ∗ 及び𝑭𝑘+1 ∗ を順番に加算 𝑭𝑘 ∗ について,2×2平均プーリングによってダウンサンプリング 𝑭𝐾 ∗ から出力𝑽を生成
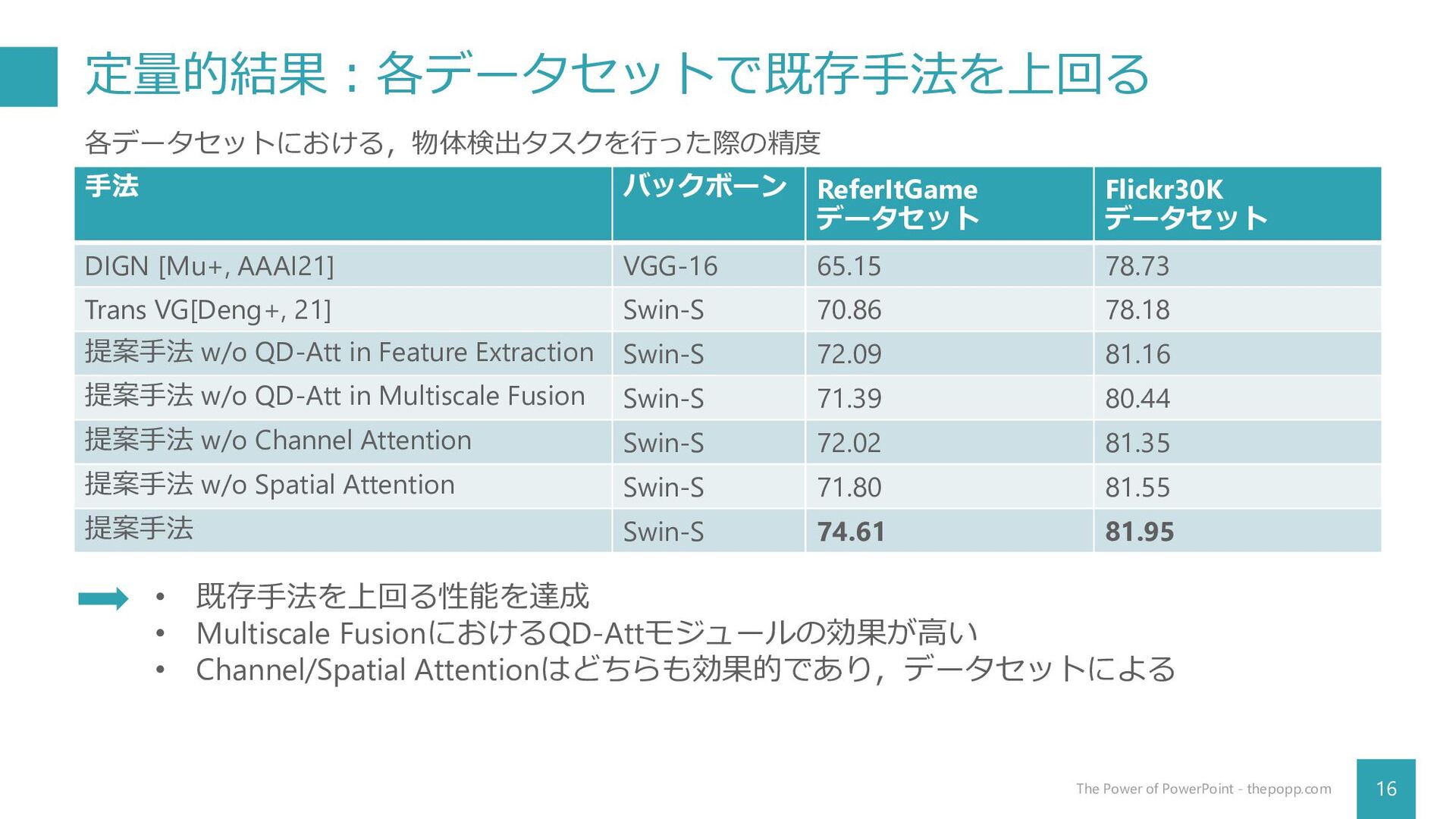
定量的結果:各データセットで既存手法を上回る 16 The Power of PowerPoint - thepopp.com 手法 バックボーン
ReferItGame データセット Flickr30K データセット DIGN [Mu+, AAAI21] VGG-16 65.15 78.73 Trans VG[Deng+, 21] Swin-S 70.86 78.18 提案手法 w/o QD-Att in Feature Extraction Swin-S 72.09 81.16 提案手法 w/o QD-Att in Multiscale Fusion Swin-S 71.39 80.44 提案手法 w/o Channel Attention Swin-S 72.02 81.35 提案手法 w/o Spatial Attention Swin-S 71.80 81.55 提案手法 Swin-S 74.61 81.95 各データセットにおける,物体検出タスクを行った際の精度 • 既存手法を上回る性能を達成 • Multiscale FusionにおけるQD-Attモジュールの効果が高い • Channel/Spatial Attentionはどちらも効果的であり,データセットによる
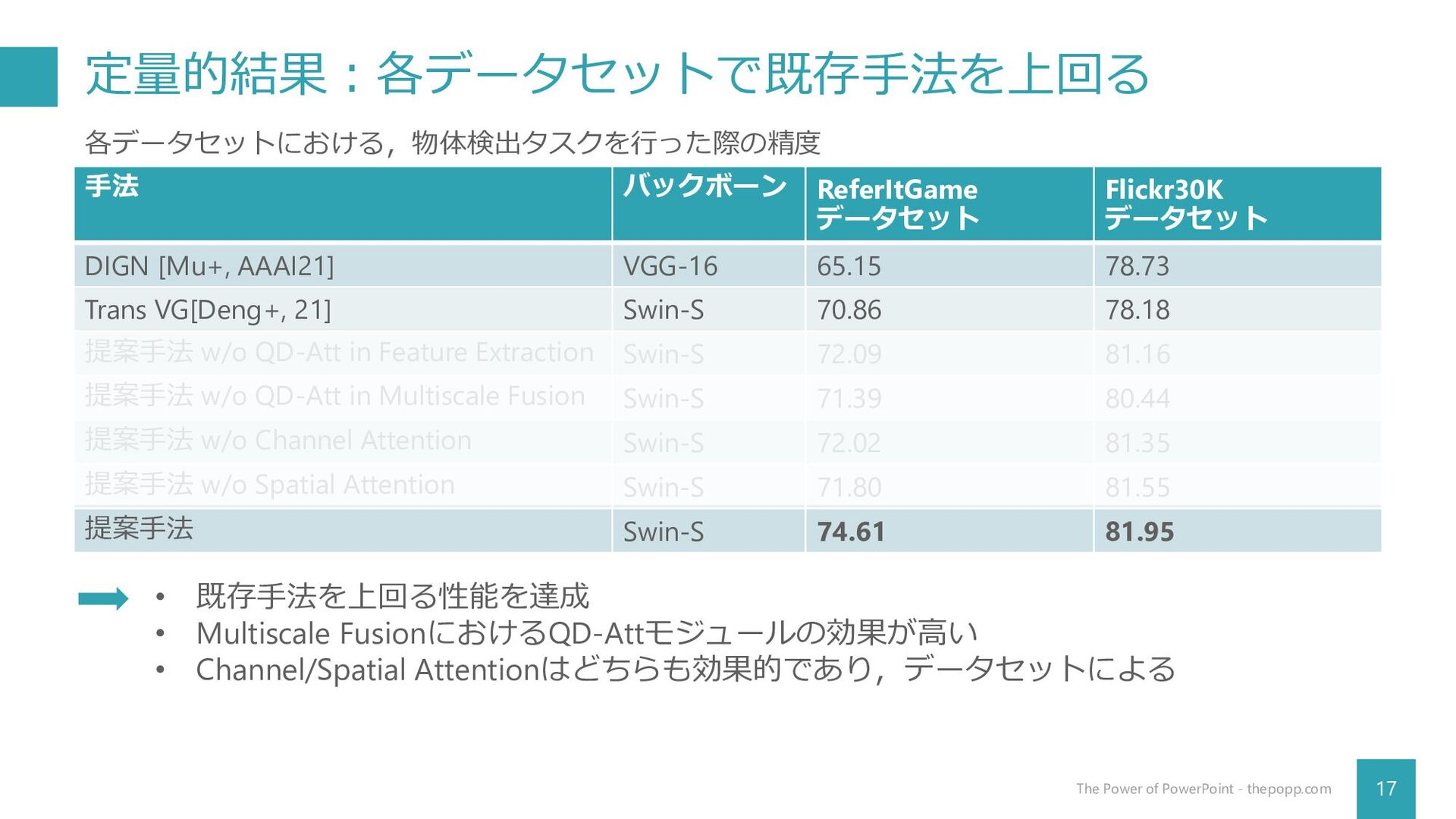
定量的結果:各データセットで既存手法を上回る 17 The Power of PowerPoint - thepopp.com 手法 バックボーン
ReferItGame データセット Flickr30K データセット DIGN [Mu+, AAAI21] VGG-16 65.15 78.73 Trans VG[Deng+, 21] Swin-S 70.86 78.18 提案手法 w/o QD-Att in Feature Extraction Swin-S 72.09 81.16 提案手法 w/o QD-Att in Multiscale Fusion Swin-S 71.39 80.44 提案手法 w/o Channel Attention Swin-S 72.02 81.35 提案手法 w/o Spatial Attention Swin-S 71.80 81.55 提案手法 Swin-S 74.61 81.95 各データセットにおける,物体検出タスクを行った際の精度 • 既存手法を上回る性能を達成 • Multiscale FusionにおけるQD-Attモジュールの効果が高い • Channel/Spatial Attentionはどちらも効果的であり,データセットによる
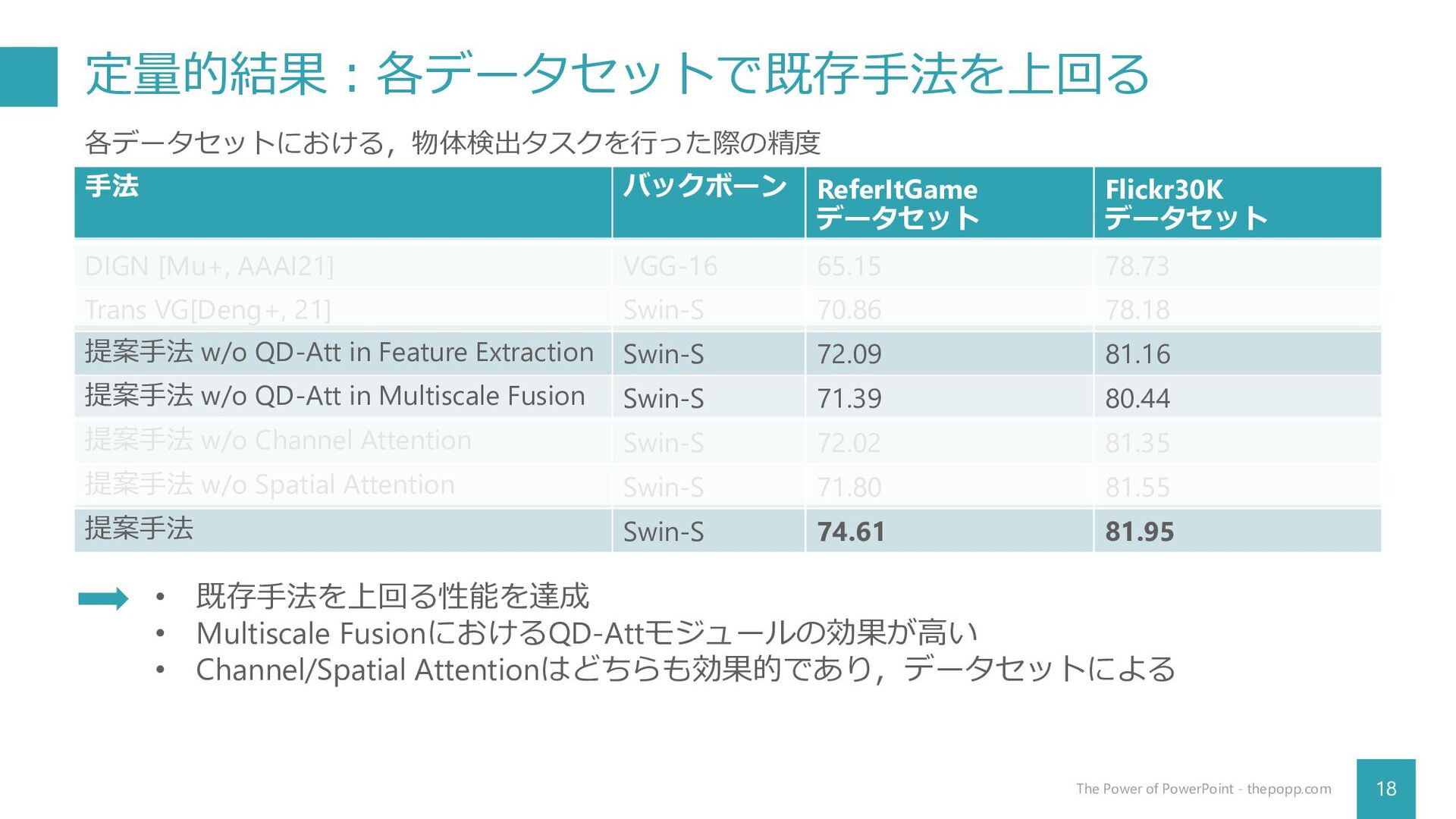
定量的結果:各データセットで既存手法を上回る 18 The Power of PowerPoint - thepopp.com 手法 バックボーン
ReferItGame データセット Flickr30K データセット DIGN [Mu+, AAAI21] VGG-16 65.15 78.73 Trans VG[Deng+, 21] Swin-S 70.86 78.18 提案手法 w/o QD-Att in Feature Extraction Swin-S 72.09 81.16 提案手法 w/o QD-Att in Multiscale Fusion Swin-S 71.39 80.44 提案手法 w/o Channel Attention Swin-S 72.02 81.35 提案手法 w/o Spatial Attention Swin-S 71.80 81.55 提案手法 Swin-S 74.61 81.95 各データセットにおける,物体検出タスクを行った際の精度 • 既存手法を上回る性能を達成 • Multiscale FusionにおけるQD-Attモジュールの効果が高い • Channel/Spatial Attentionはどちらも効果的であり,データセットによる
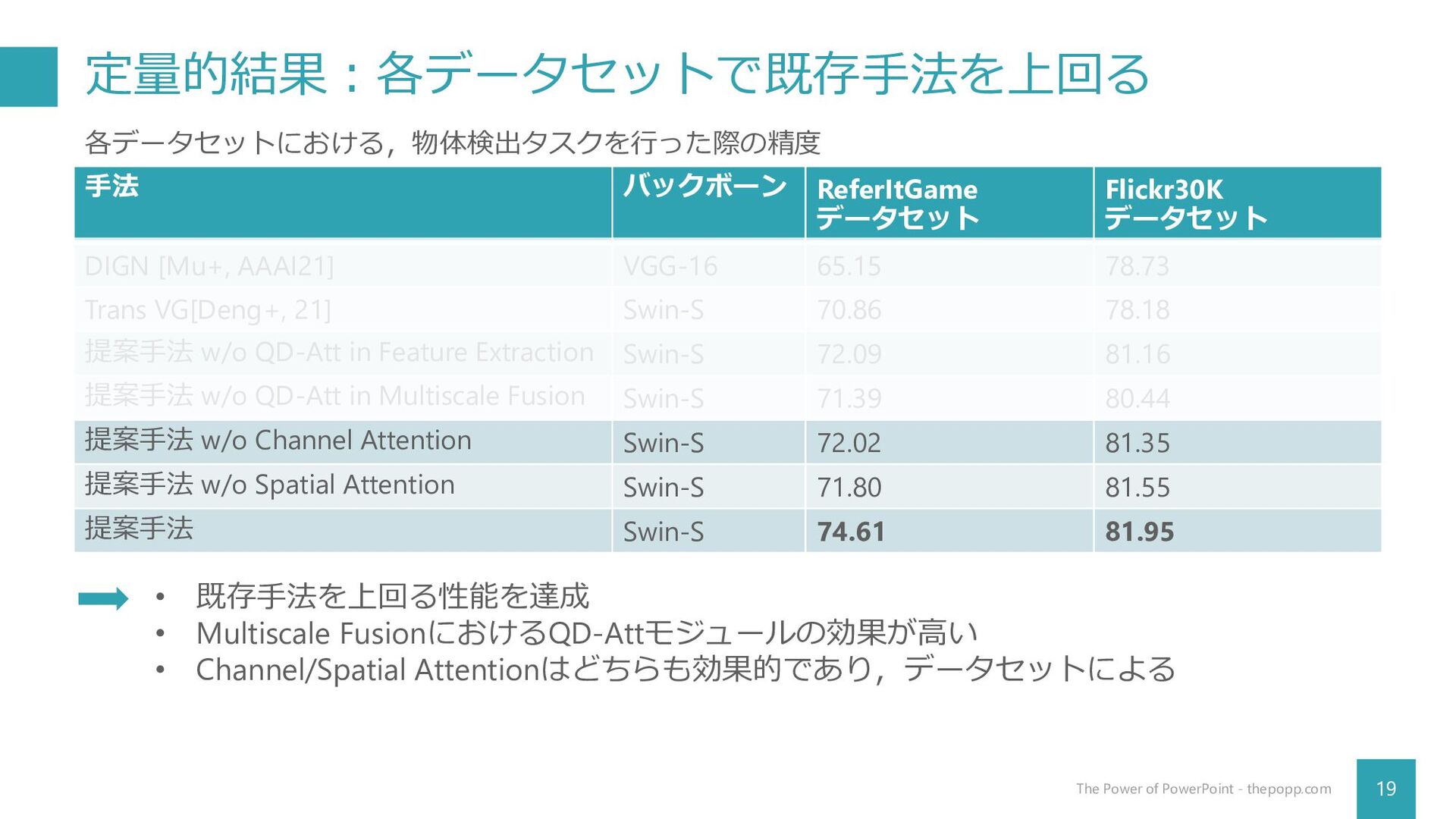
定量的結果:各データセットで既存手法を上回る 19 The Power of PowerPoint - thepopp.com 手法 バックボーン
ReferItGame データセット Flickr30K データセット DIGN [Mu+, AAAI21] VGG-16 65.15 78.73 Trans VG[Deng+, 21] Swin-S 70.86 78.18 提案手法 w/o QD-Att in Feature Extraction Swin-S 72.09 81.16 提案手法 w/o QD-Att in Multiscale Fusion Swin-S 71.39 80.44 提案手法 w/o Channel Attention Swin-S 72.02 81.35 提案手法 w/o Spatial Attention Swin-S 71.80 81.55 提案手法 Swin-S 74.61 81.95 各データセットにおける,物体検出タスクを行った際の精度 • 既存手法を上回る性能を達成 • Multiscale FusionにおけるQD-Attモジュールの効果が高い • Channel/Spatial Attentionはどちらも効果的であり,データセットによる
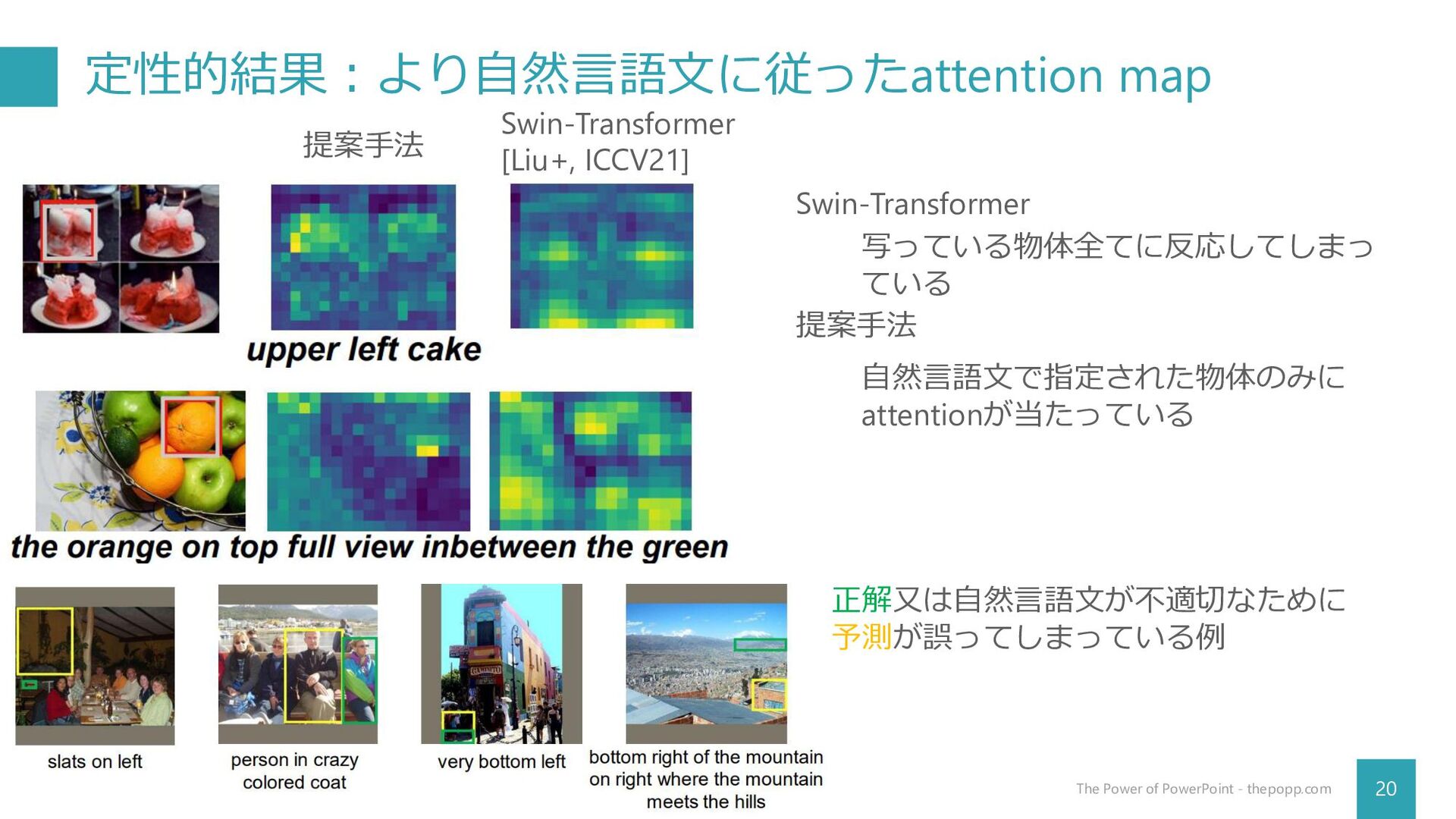
定性的結果:より自然言語文に従ったattention map 20 The Power of PowerPoint - thepopp.com 提案手法
Swin-Transformer [Liu+, ICCV21] Swin-Transformer 提案手法 写っている物体全てに反応してしまっ ている 自然言語文で指定された物体のみに attentionが当たっている 正解又は自然言語文が不適切なために 予測が誤ってしまっている例
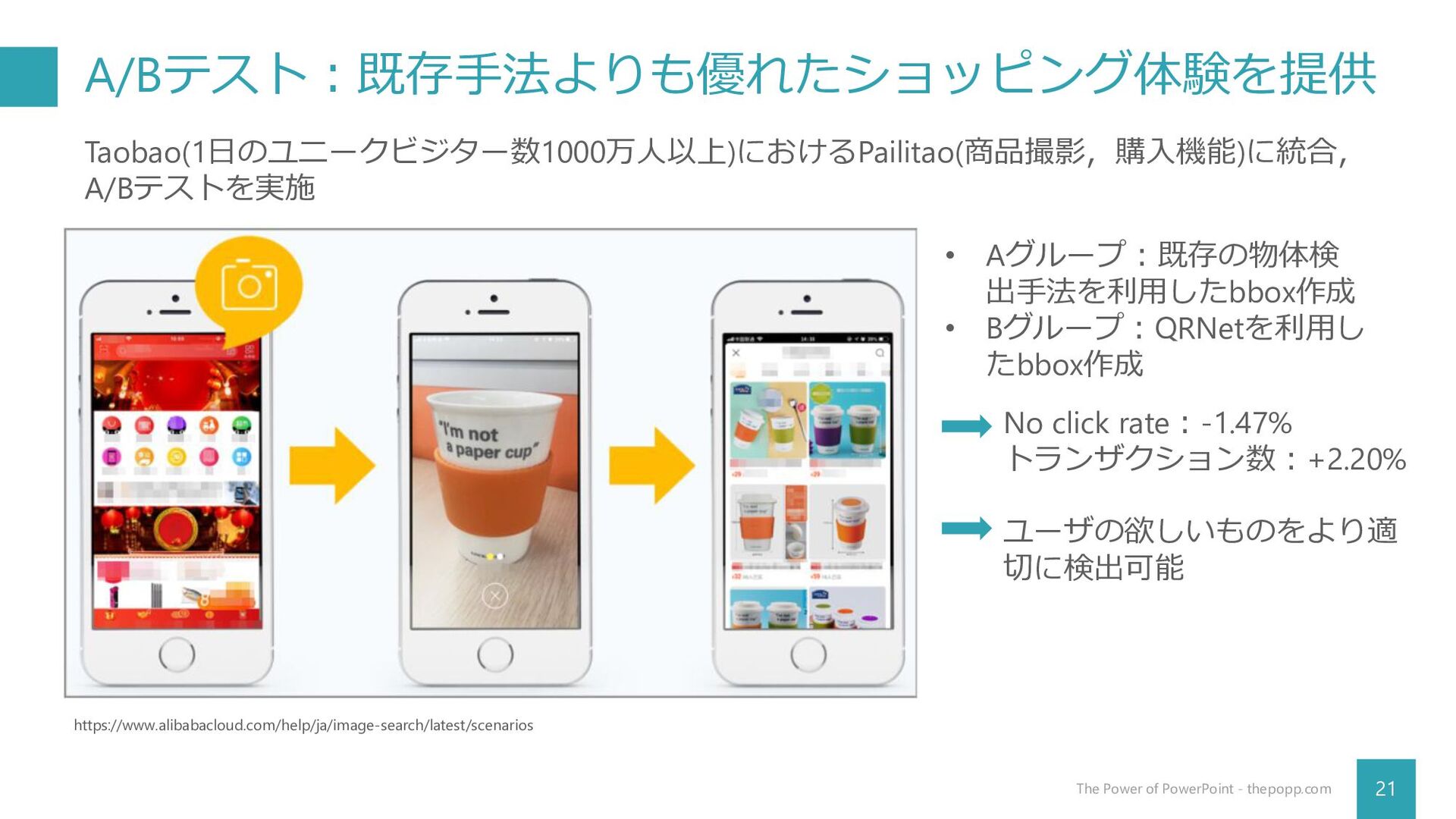
A/Bテスト:既存手法よりも優れたショッピング体験を提供 21 The Power of PowerPoint - thepopp.com Taobao(1日のユニークビジター数1000万人以上)におけるPailitao(商品撮影,購入機能)に統合, A/Bテストを実施
https://www.alibabacloud.com/help/ja/image-search/latest/scenarios • Aグループ:既存の物体検 出手法を利用したbbox作成 • Bグループ:QRNetを利用し たbbox作成 No click rate:-1.47% トランザクション数:+2.20% ユーザの欲しいものをより適 切に検出可能
まとめ 22 The Power of PowerPoint - thepopp.com 背景 提案手法
結果 画像の埋め込みにおいて,言語による条件付けが行われていないため,効果的な特徴量が得ら れていない可能性 自然言語文(query)の特徴量で条件付けつつ画像特徴量の抽出を行うネットワーク,Query- modulated Refinement Networkの提案 各データセットで既存手法を上回る性能.自然言語文に沿ったattentionの生成に成功
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![QRNet:自然言語文から獲得した[CLS]トークンを利用 7 The Power of PowerPoint - thepopp.com 画像 𝐼,自然言語文](https://files.speakerdeck.com/presentations/95e85908429e400db8b129d7f3224958/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}