Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Sketch, Ground, and Refine: Top-...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 13, 2022
Technology
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Sketch, Ground, and Refine: Top-Down Dense Video Captioning
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 13, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
890
どこまでAIに任せるか 〜確率論と決定論の境界決定〜
shukob
0
450
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
370
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
430
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.3k
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
25
11k
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
480
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
520
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1k
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
480
Featured
See All Featured
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Utilizing Notion as your number one productivity tool
mfonobong
4
450
The Invisible Side of Design
smashingmag
301
52k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Tell your own story through comics
letsgokoyo
1
1k
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
The Curious Case for Waylosing
cassininazir
1
440
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
First, design no harm
axbom
PRO
2
1.2k
The SEO Collaboration Effect
kristinabergwall1
1
510
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Transcript
Sketch, Ground, and Refine: Top-Down Dense Video Captioning Chaorui Deng1,3,
Shizhe Chen2, Da Chen3, Yuan He3, Qi Wu1 1University of Adelaide, 2INRIA, 3Alibaba Group CVPR 2021 杉浦孔明研究室 神原 元就 Deng, C., Chen, S., Chen, D., He, Y., & Wu, Q. (2021). Sketch, ground, and refine: Top-down dense video captioning. In CVPR(pp. 234-243).
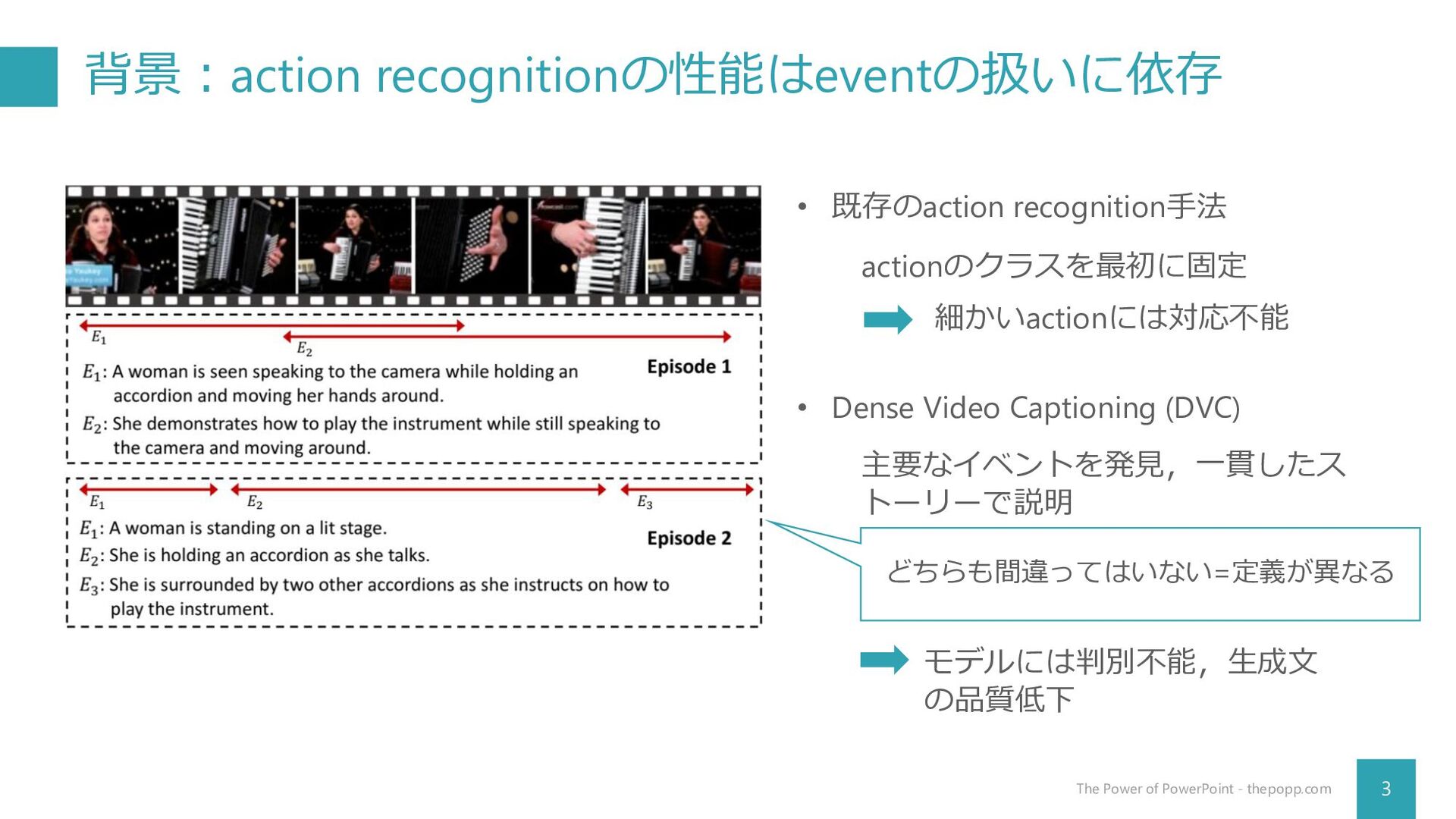
背景:action recognitionの性能はeventの扱いに依存 3 The Power of PowerPoint - thepopp.com actionのクラスを最初に固定
• 既存のaction recognition手法 細かいactionには対応不能 • Dense Video Captioning (DVC) 主要なイベントを発見,一貫したス トーリーで説明 どちらも間違ってはいない=定義が異なる モデルには判別不能,生成文 の品質低下
既存研究 4 The Power of PowerPoint - thepopp.com [Zhou+ CVPR18]
• CNN及びtransformerを用いたend-to-end DVCモデル • “detect-then-describe”フレームワーク • イベントを一通り検出しそれぞれに キャプションを付けるため一貫性がない [Mun+ CVPR19] • RNNを用いたDVCモデル • 時系列順にイベントを検出,並べた後に キャプションを生成 • イベントの定義の差異が生成文の品質 に影響
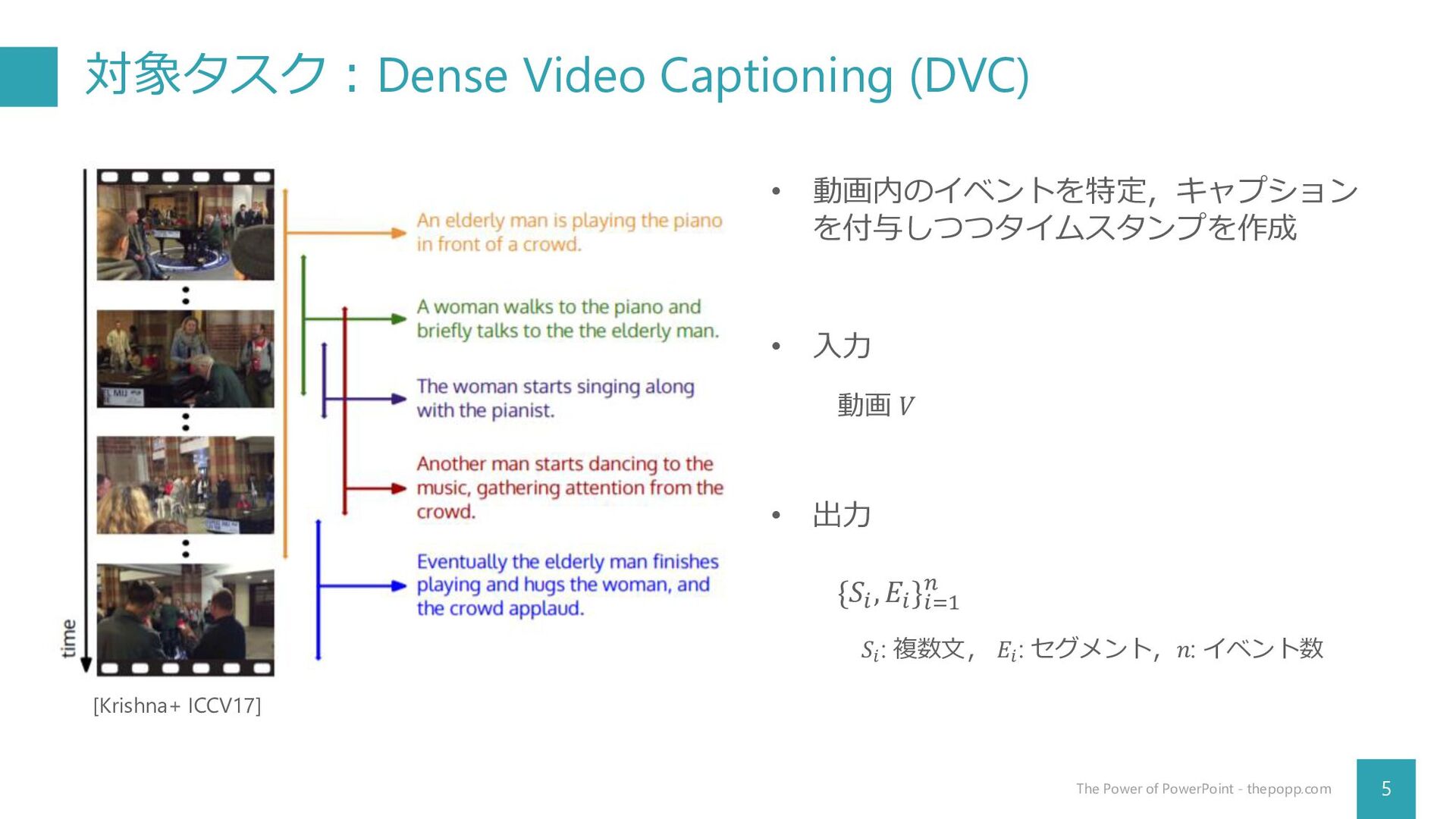
対象タスク:Dense Video Captioning (DVC) 5 The Power of PowerPoint -
thepopp.com • 入力 • 出力 • 動画内のイベントを特定,キャプション を付与しつつタイムスタンプを作成 [Krishna+ ICCV17] 動画 𝑉 {𝑆𝑖 , 𝐸𝑖 }𝑖=1 𝑛 𝑆𝑖 : 複数文, 𝐸𝑖 : セグメント,𝑛: イベント数
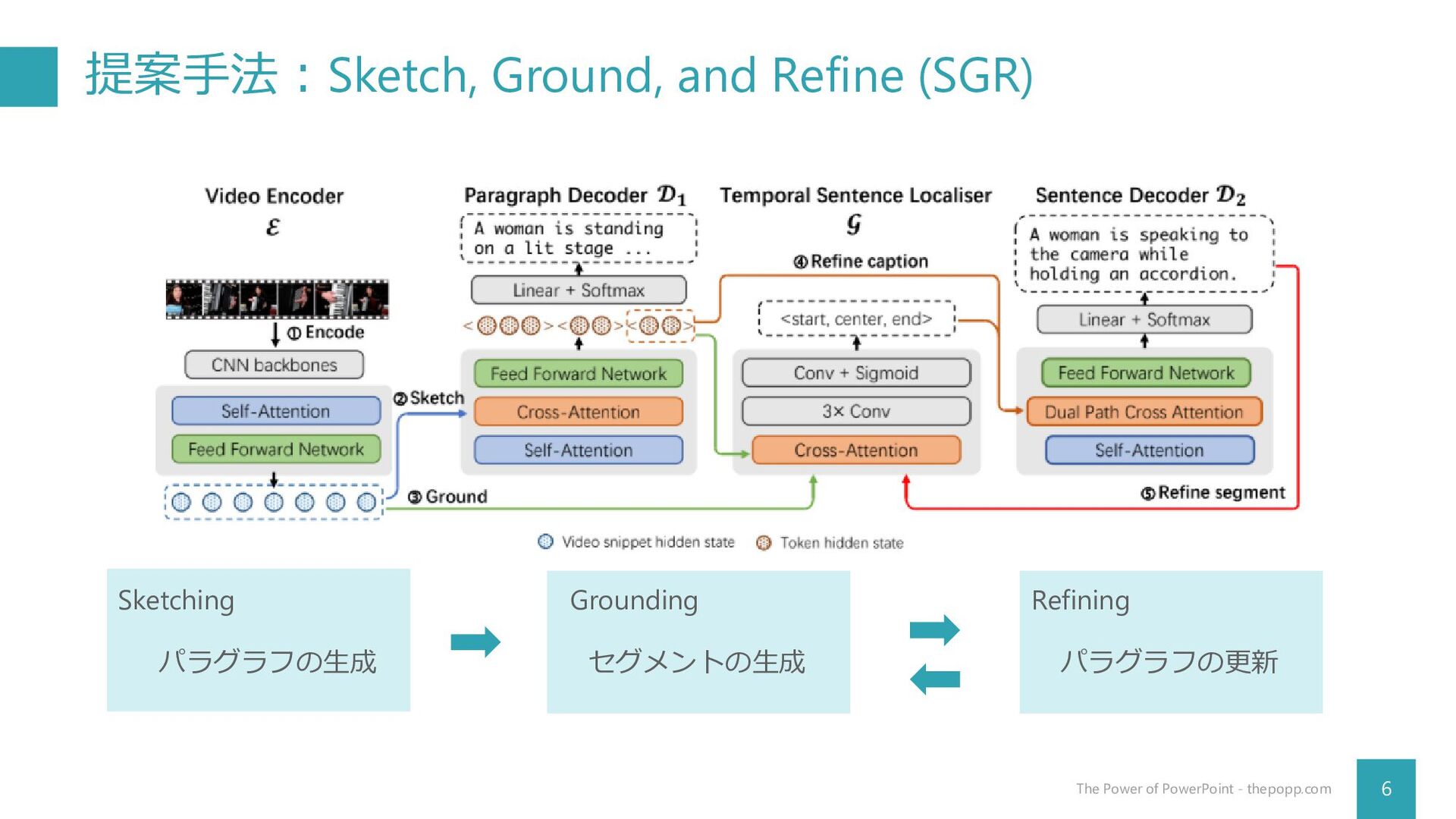
提案手法:Sketch, Ground, and Refine (SGR) 6 The Power of PowerPoint
- thepopp.com Sketching Grounding Refining パラグラフの生成 セグメントの生成 パラグラフの更新
Contextual Video Encoder 7 The Power of PowerPoint - thepopp.com
• 動画のエンコードを行う • 入力: 𝑉 • 出力: 𝑯𝑣 ∈ ℝ𝑇×𝑑𝑚 T: 事前に分割したスニペット数, 𝑑𝑚: 隠れ層のサイズ 1. CNNを用いて特徴量𝑭𝑣 ∈ ℝ𝑇×𝑑𝑓を抽出 2. transformer encoding layerを用いて𝑯𝑣 (𝑙) ∈ ℝ𝑇×𝑑𝑚を計算 𝑯𝑣 (𝑙+1) = 𝑓𝐹𝐹𝑁 (𝑯𝑣 𝑙 + 𝑓𝑀𝐻𝐴 (𝑯𝑣 𝑙 , 𝑯𝑣 𝑙 , 𝑯𝑣 (𝑙)))
Sketching: Paragraph Decoder 8 The Power of PowerPoint - thepopp.com
• 動画から抽出した特徴量より文を生成 • 入力: 𝑯𝑣 • 出力: 𝑯𝑝 ∈ ℝ𝐿𝑝×𝑑𝑚, p(𝑤𝑗 |𝑤<𝑗 , 𝑯𝑣 ) 𝐿𝑝: 生成されるパラグラフの長さ 𝑯𝑝𝑠 (𝑙) = 𝑯𝑝 𝑙 + 𝑓𝑀𝐻𝐴 (𝑯𝑝 𝑙 , 𝑯𝑝 𝑙 , 𝑯𝑝 (𝑙))) 𝑯𝑝𝑐 (𝑙) = 𝑯𝑝𝑠 𝑙 + 𝑓𝑀𝐻𝐴 (𝑯𝑝𝑠 𝑙 , 𝑯𝑣 , 𝑯𝑣 )) 𝑯𝑝𝑐 (𝑙+1) = 𝑯𝑝𝑐 𝑙 + 𝑓𝐹𝐹𝑁 (𝑯𝑝𝑐 𝑙 )) 1. transformer decoder layerを用いて𝑯𝑝 (𝑙)を計算 2. 各単語の生成確率を計算 p 𝑤𝑗 𝑤<𝑗 , 𝑯𝑣 = 𝑓𝑠𝑜𝑓𝑡𝑚𝑎𝑥 (𝑯𝑝,𝑗 𝑾𝑒𝑚𝑏 ) 訓練時はteacher forcing 𝐿𝑠 = 𝑤𝑗 ∗∈𝑃∗ − log 𝑝(𝑤𝑗 ∗|𝑤<𝑗 ∗ , 𝑯𝑣 )
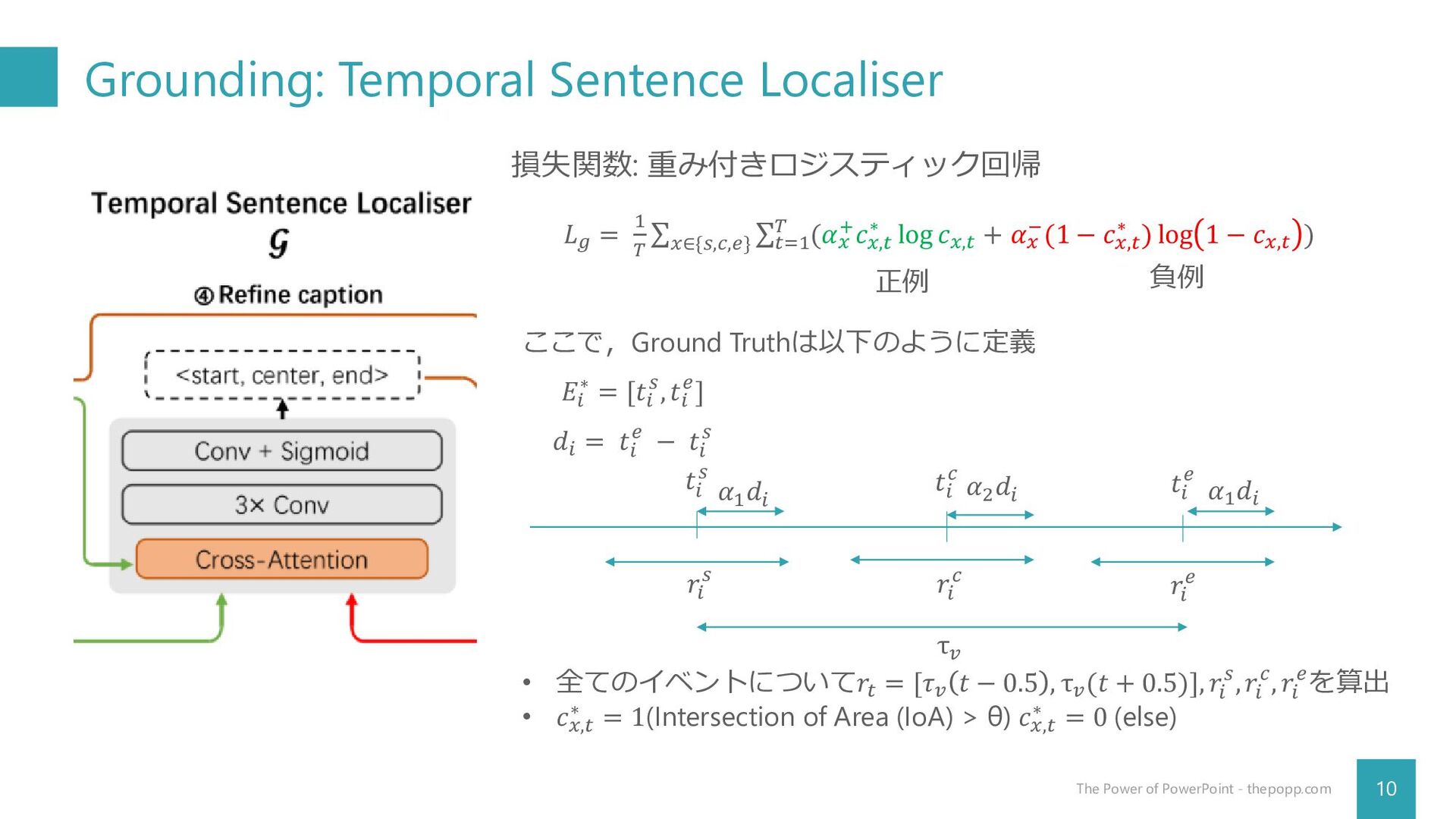
Grounding: Temporal Sentence Localiser 9 The Power of PowerPoint -
thepopp.com • 各文からセグメントのタイムスタンプを予測 • 入力: 𝑯𝑣 , 𝑯𝒔𝒊 ∈ ℝ𝐿𝑠𝑖 ×𝑑𝑚 𝐿𝑠𝑖 : 文𝑆𝑖 の長さ(𝑯𝑝 の一部) • 出力: 𝑐𝑠 , 𝑐𝑐 , 𝑐𝑒 ∈ ℝ𝑇 1. transformerにおける注意機構を用いて𝑯𝑣 (𝑠𝑖)を計算 𝑯𝑣 (𝑠𝑖) = 𝑯𝑣 + 𝑓𝐴𝑇𝑇 (𝑯𝑣 , 𝑯𝒔𝒊 , 𝑯𝒔𝒊 )) 2. 1-D Conv層を適用し ෩ 𝐻𝑣 (𝑠𝑖)とした後,線形分類器により確信度 スコア𝑐𝑠 , 𝑐𝑐 , 𝑐𝑒 を予測 𝑐𝑥 = 𝑓𝑠𝑜𝑓𝑡𝑚𝑎𝑥 (෩ 𝑯𝑣 𝑠𝑖 𝑾𝒙 )) 𝑥 ∈ {𝑠, 𝑐, 𝑒} i番目のセグメント𝐸𝑖 に対する確信度は𝑐𝑠,𝑙𝑠 + 𝑐𝑐,𝑙𝑐 + 𝑐𝑒,𝑙𝑒 確信度が高いものを用いて𝐸𝑖 = [𝑡𝑖 𝑠, 𝑡𝑖 𝑒]とする
Grounding: Temporal Sentence Localiser 10 The Power of PowerPoint -
thepopp.com 損失関数: 重み付きロジスティック回帰 𝐿𝑔 = 1 𝑇 σ 𝑥∈{𝑠,𝑐,𝑒} σ𝑡=1 𝑇 (𝛼𝑥 +𝑐𝑥,𝑡 ∗ log 𝑐𝑥,𝑡 + 𝛼𝑥 −(1 − 𝑐𝑥,𝑡 ∗ ) log 1 − 𝑐𝑥,𝑡 ) 正例 負例 ここで,Ground Truthは以下のように定義 𝐸𝑖 ∗ = [𝑡𝑖 𝑠, 𝑡𝑖 𝑒] 𝑑𝑖 = 𝑡𝑖 𝑒 − 𝑡𝑖 𝑠 𝑡𝑖 𝑠 𝑡𝑖 𝑒 𝑡𝑖 𝑐 𝑟𝑖 𝑠 𝑟𝑖 𝑐 𝑟𝑖 𝑒 𝛼1 𝑑𝑖 𝛼1 𝑑𝑖 𝛼2 𝑑𝑖 τ𝑣 • 全てのイベントについて𝑟𝑡 = [𝜏𝑣 𝑡 − 0.5 , τ𝑣 (𝑡 + 0.5)], 𝑟𝑖 𝑠, 𝑟𝑖 𝑐, 𝑟𝑖 𝑒を算出 • 𝑐𝑥,𝑡 ∗ = 1(Intersection of Area (IoA) > θ) 𝑐𝑥,𝑡 ∗ = 0 (else)
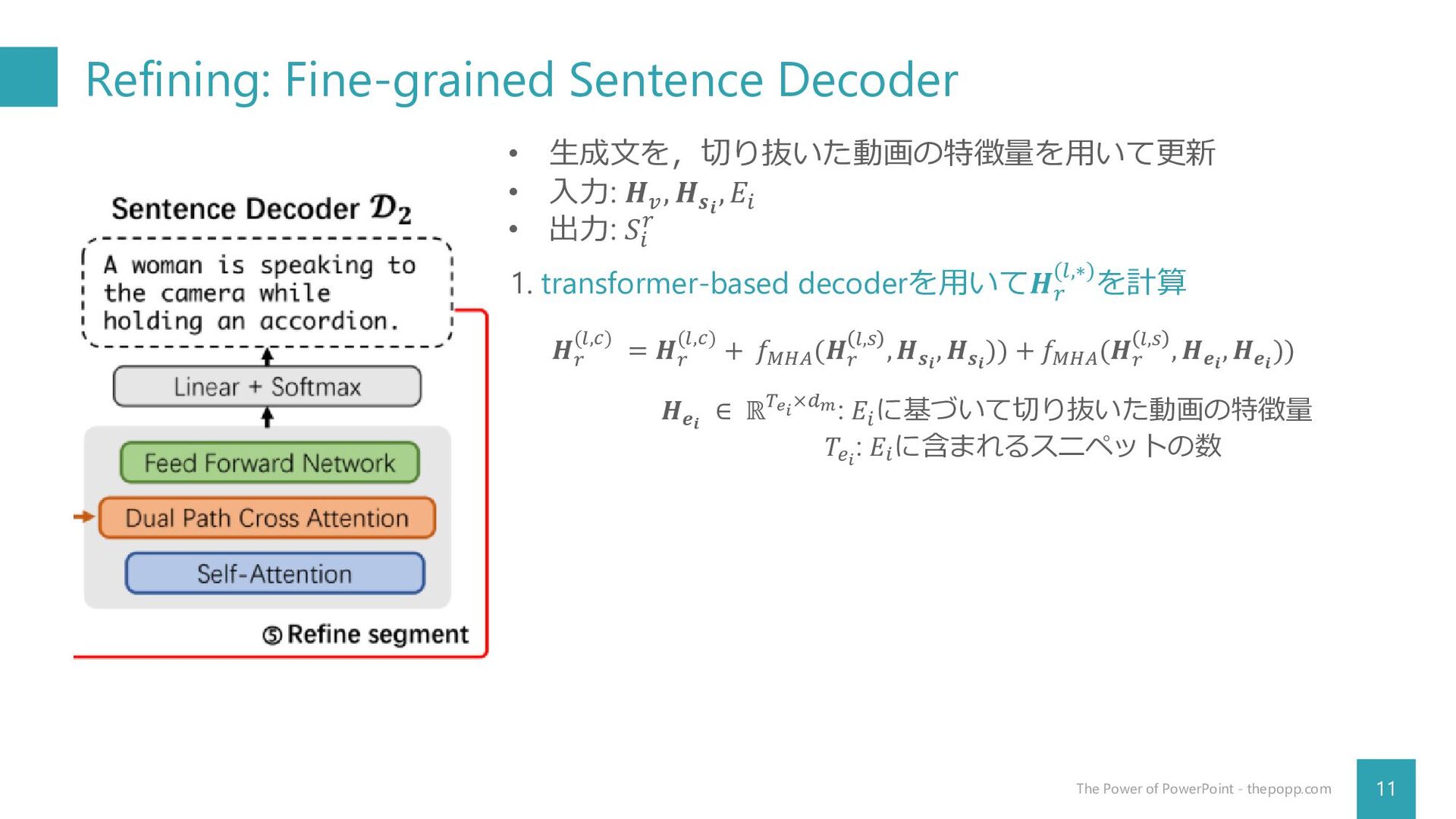
Refining: Fine-grained Sentence Decoder 11 The Power of PowerPoint -
thepopp.com • 生成文を,切り抜いた動画の特徴量を用いて更新 • 入力: 𝑯𝑣 , 𝑯𝒔𝒊 , 𝐸𝑖 • 出力: 𝑆𝑖 𝑟 1. transformer-based decoderを用いて𝑯𝑟 (𝑙,∗)を計算 𝑯𝑟 (𝑙,𝑐) = 𝑯𝑟 (𝑙,𝑐) + 𝑓𝑀𝐻𝐴 (𝑯𝑟 𝑙,𝑠 , 𝑯𝒔𝒊 , 𝑯𝒔𝒊 )) + 𝑓𝑀𝐻𝐴 (𝑯𝑟 𝑙,𝑠 , 𝑯𝒆𝒊 , 𝑯𝒆𝒊 )) 𝑯𝒆𝒊 ∈ ℝ𝑇𝑒𝑖 ×𝑑𝑚: 𝐸𝑖 に基づいて切り抜いた動画の特徴量 𝑇𝑒𝑖 : 𝐸𝑖 に含まれるスニペットの数
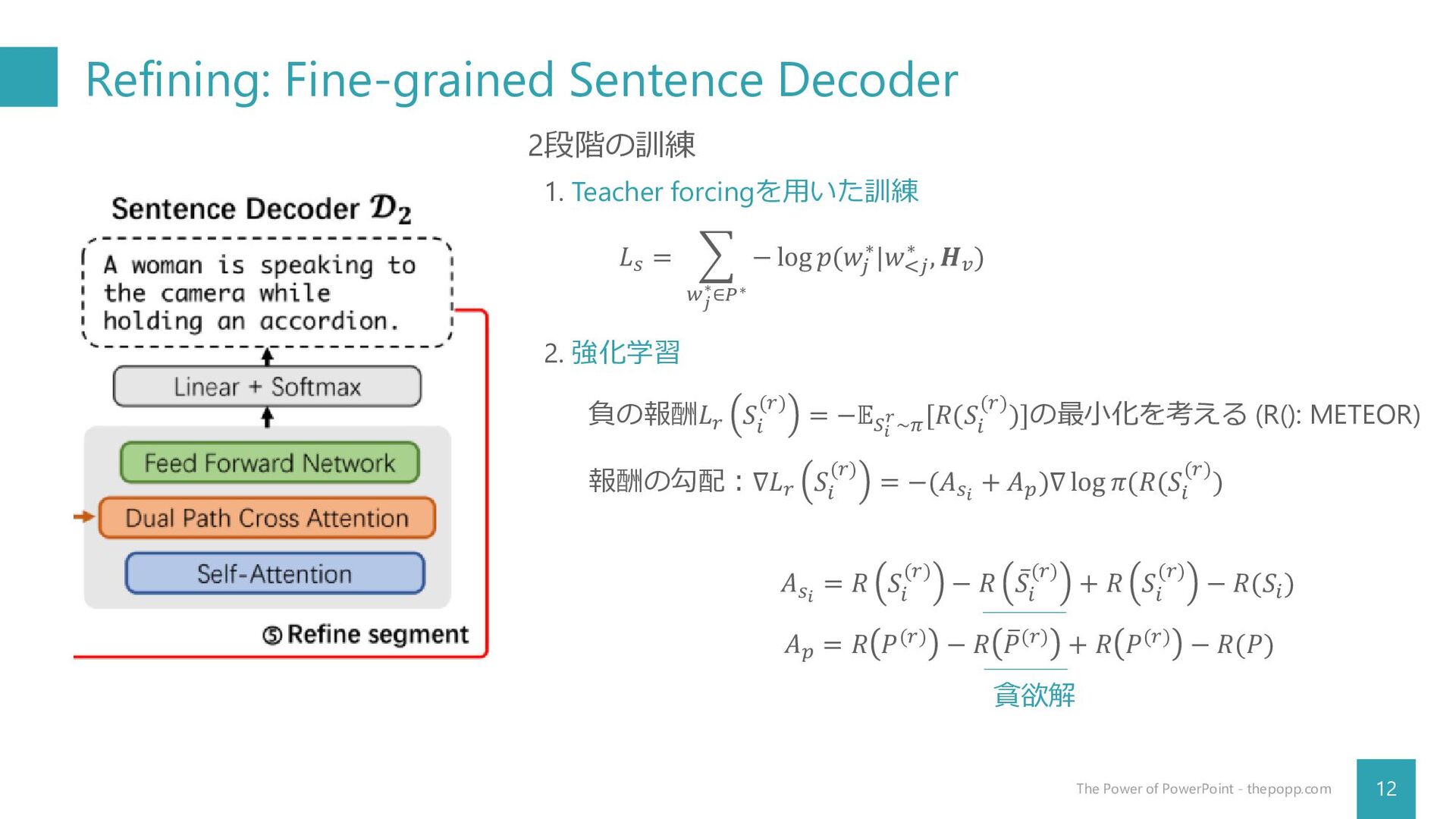
Refining: Fine-grained Sentence Decoder 12 The Power of PowerPoint -
thepopp.com 2段階の訓練 1. Teacher forcingを用いた訓練 𝐿𝑠 = 𝑤𝑗 ∗∈𝑃∗ − log 𝑝(𝑤𝑗 ∗|𝑤<𝑗 ∗ , 𝑯𝑣 ) 2. 強化学習 負の報酬𝐿𝑟 𝑆 𝑖 (𝑟) = −𝔼𝑆𝑖 𝑟~𝜋 [𝑅(𝑆 𝑖 (𝑟))]の最小化を考える (R(): METEOR) 報酬の勾配:∇𝐿𝑟 𝑆 𝑖 (𝑟) = −(𝐴𝑠𝑖 + 𝐴𝑝 )∇ log 𝜋(𝑅(𝑆 𝑖 (𝑟)) 𝐴𝑠𝑖 = 𝑅 𝑆 𝑖 (𝑟) − 𝑅 ҧ 𝑆 𝑖 (𝑟) + 𝑅 𝑆 𝑖 (𝑟) − 𝑅(𝑆𝑖 ) 𝐴𝑝 = 𝑅 𝑃(𝑟) − 𝑅 ത 𝑃(𝑟) + 𝑅 𝑃(𝑟) − 𝑅(𝑃) 貪欲解
定量的結果:タイプの異なる2種類のデータセットでSOTA 13 The Power of PowerPoint - thepopp.com ActivityNet[Krishna+ CVPR17]における結
果(backborn: C3D) 2つのデータセットにおける結果 (backborn: TSN[Xiong+ 16]) • 主要尺度であるMETEORにおいて提案手法 が上回る • キャプションの更新を行うことでw/o Refiningよりも性能向上 • 提案手法はいずれのデータセットにおいても高性能 • SODA: キャプション数に敏感だが,結果より,正し くセグメントに分割できている https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123510511.pdf
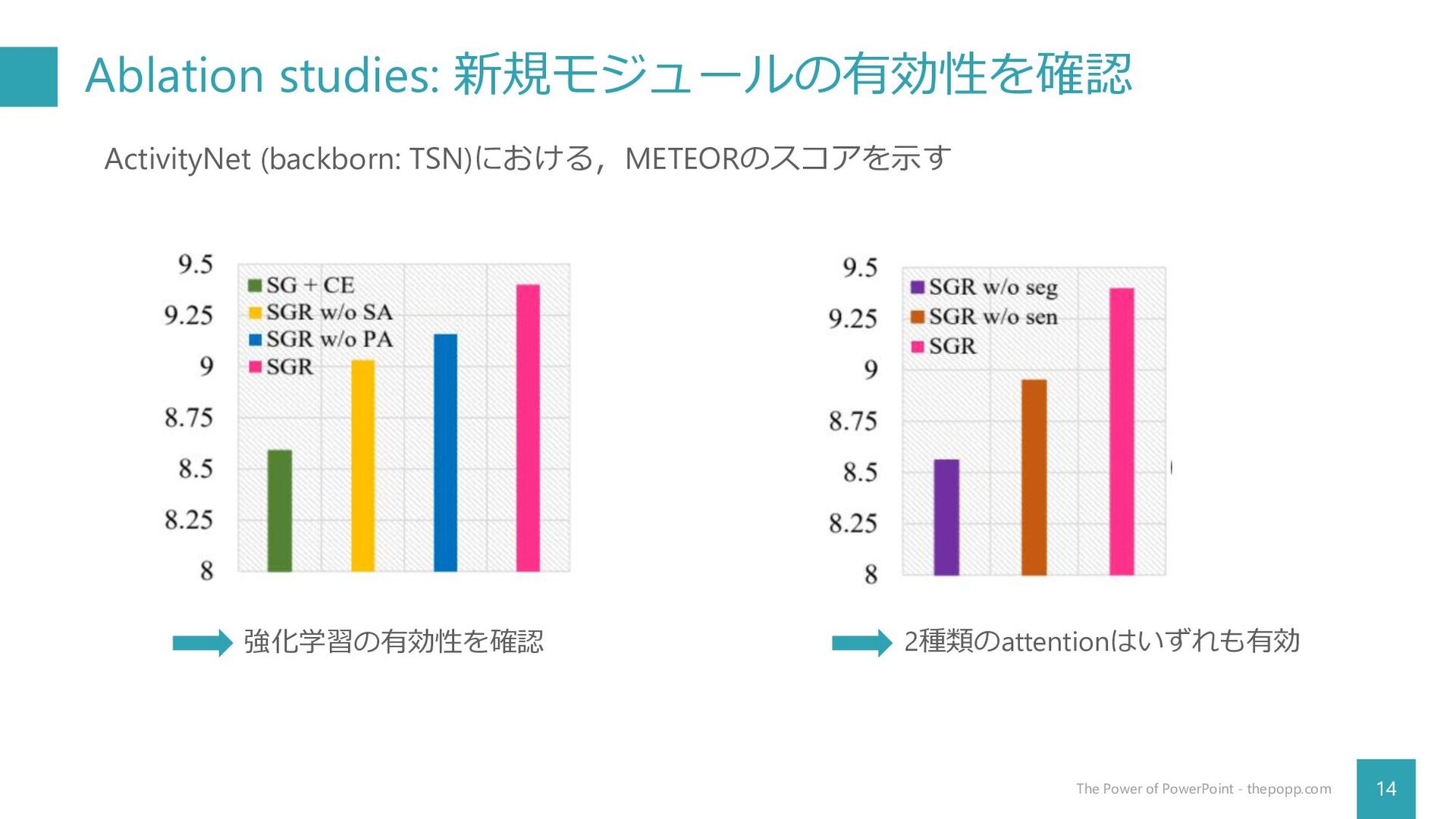
Ablation studies: 新規モジュールの有効性を確認 14 The Power of PowerPoint - thepopp.com
ActivityNet (backborn: TSN)における,METEORのスコアを示す 強化学習の有効性を確認 2種類のattentionはいずれも有効
定性的結果 15 The Power of PowerPoint - thepopp.com 提案手法はRefiningモジュールがない場合よりもGTに近いセグメント及びキャプション生成 に成功
まとめ 16 The Power of PowerPoint - thepopp.com • 背景
Video Dense Captioning (VDC) において,イベント抽出→キャプション生成という手法では性能 に限界があった • 提案手法 生成したキャプションからセグメントのタイムスタンプを作成,キャプションをさらに精錬させ る手法,Sketch, Ground, and Refine (SGR)を提案 • 結果 主要尺度において既存手法を上回ったほか,セグメントのタイムスタンプについても正確性が向 上した
{kind=link}
{kind=link}
![既存研究 4 The Power of PowerPoint - thepopp.com [Zhou+ CVPR18]](https://files.speakerdeck.com/presentations/58681e02ff80482fb2ed953e4740cce9/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![定量的結果:タイプの異なる2種類のデータセットでSOTA 13 The Power of PowerPoint - thepopp.com ActivityNet[Krishna+ CVPR17]における結](https://files.speakerdeck.com/presentations/58681e02ff80482fb2ed953e4740cce9/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}