- 命令文 - コンテキスト領域 - 候補領域 (候補物体のBounding box) 出力: - 候補物体が対象物体である確率の予測値 Look in the left wicker vase that is next to the potted plant. Faster R-CNN[Ren+, PAMI16] によって自動抽出 - 8 -
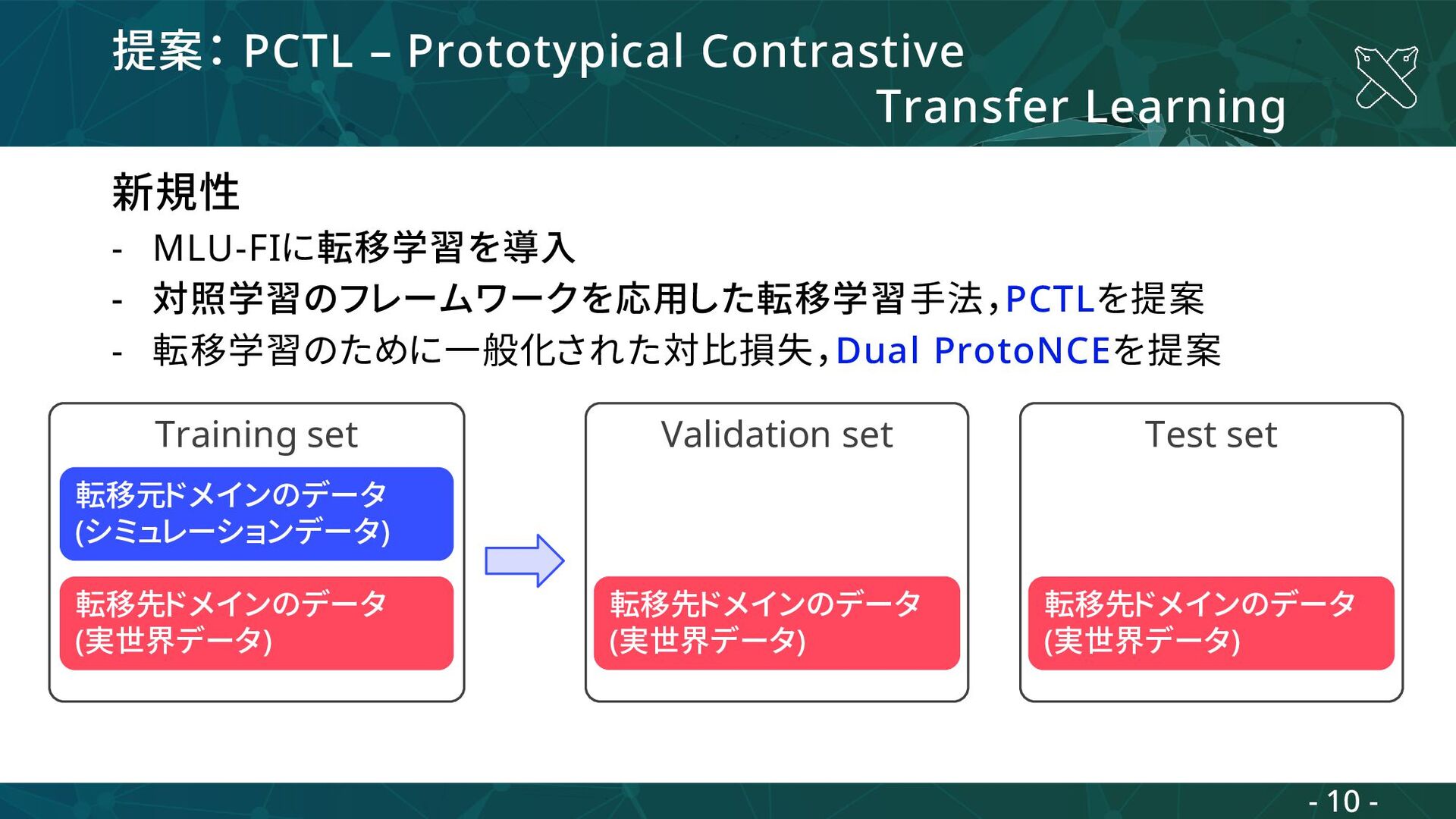
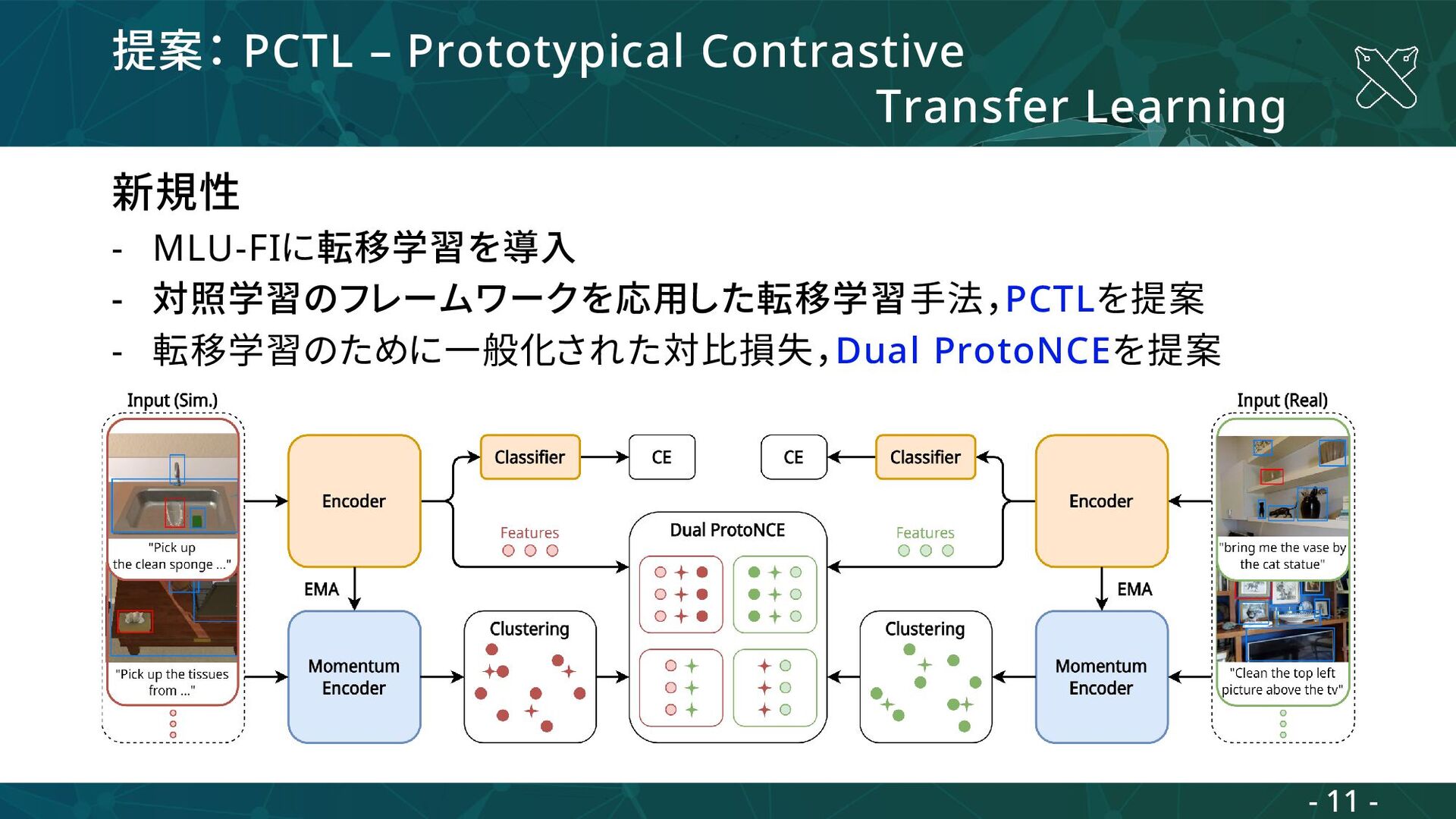
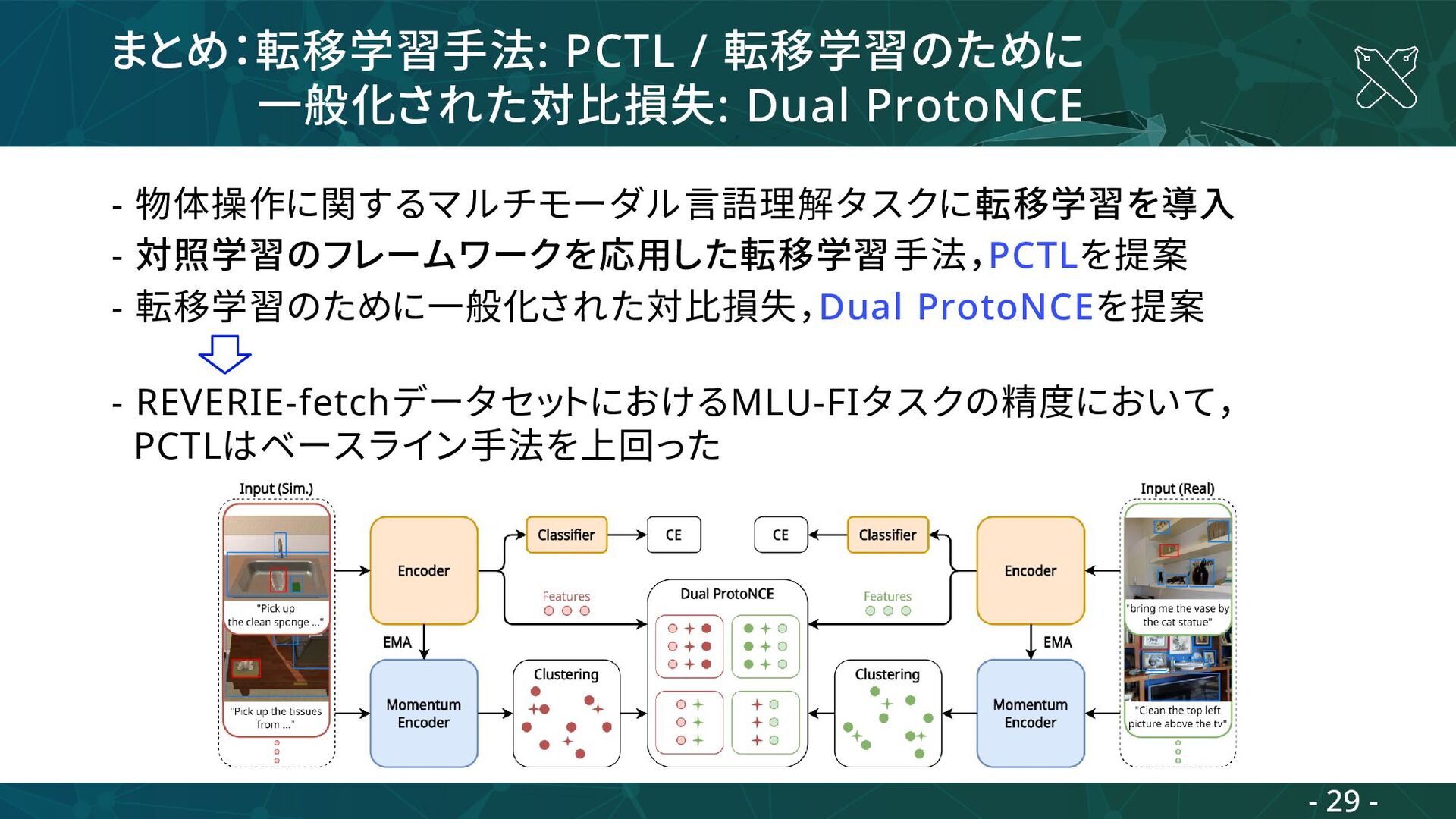
- 対照学習のフレームワークを応用した転移学習手法,PCTLを提案 - 転移学習のために一般化された対比損失,Dual ProtoNCEを提案 転移元ドメインのデータ (シミュレーションデータ) 転移先ドメインのデータ (実世界データ) Training set Validation set 転移先ドメインのデータ (実世界データ) Test set 転移先ドメインのデータ (実世界データ) - 10 -
Vocabulary size 1958 1558 Average sentence length 18.4 11.7 #Sample 10243 34286 #Sample in Training set 8302 27492 #Sample in Validation set 994 3470 #Sample in Test set 947 3324 - 34 -
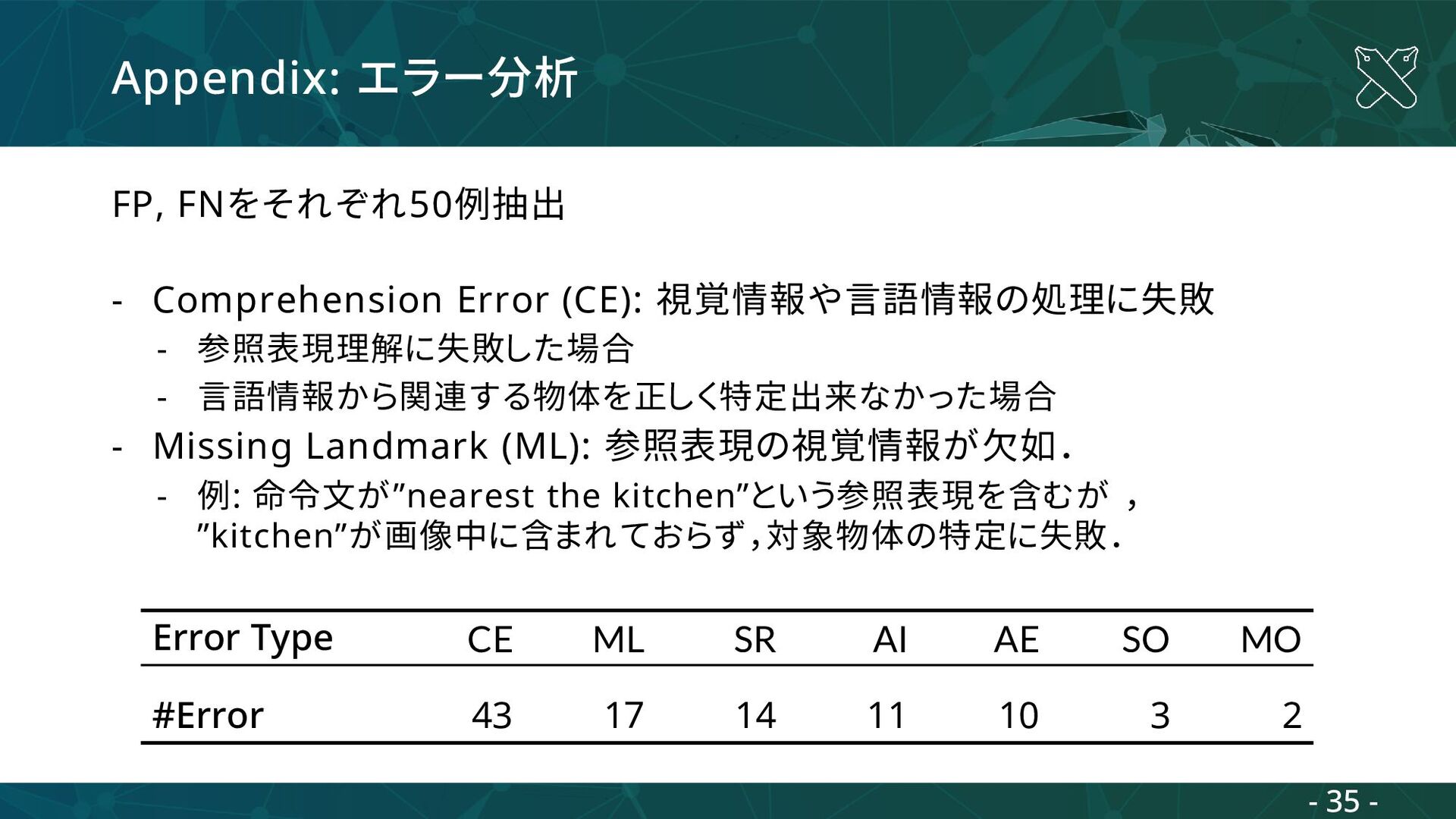
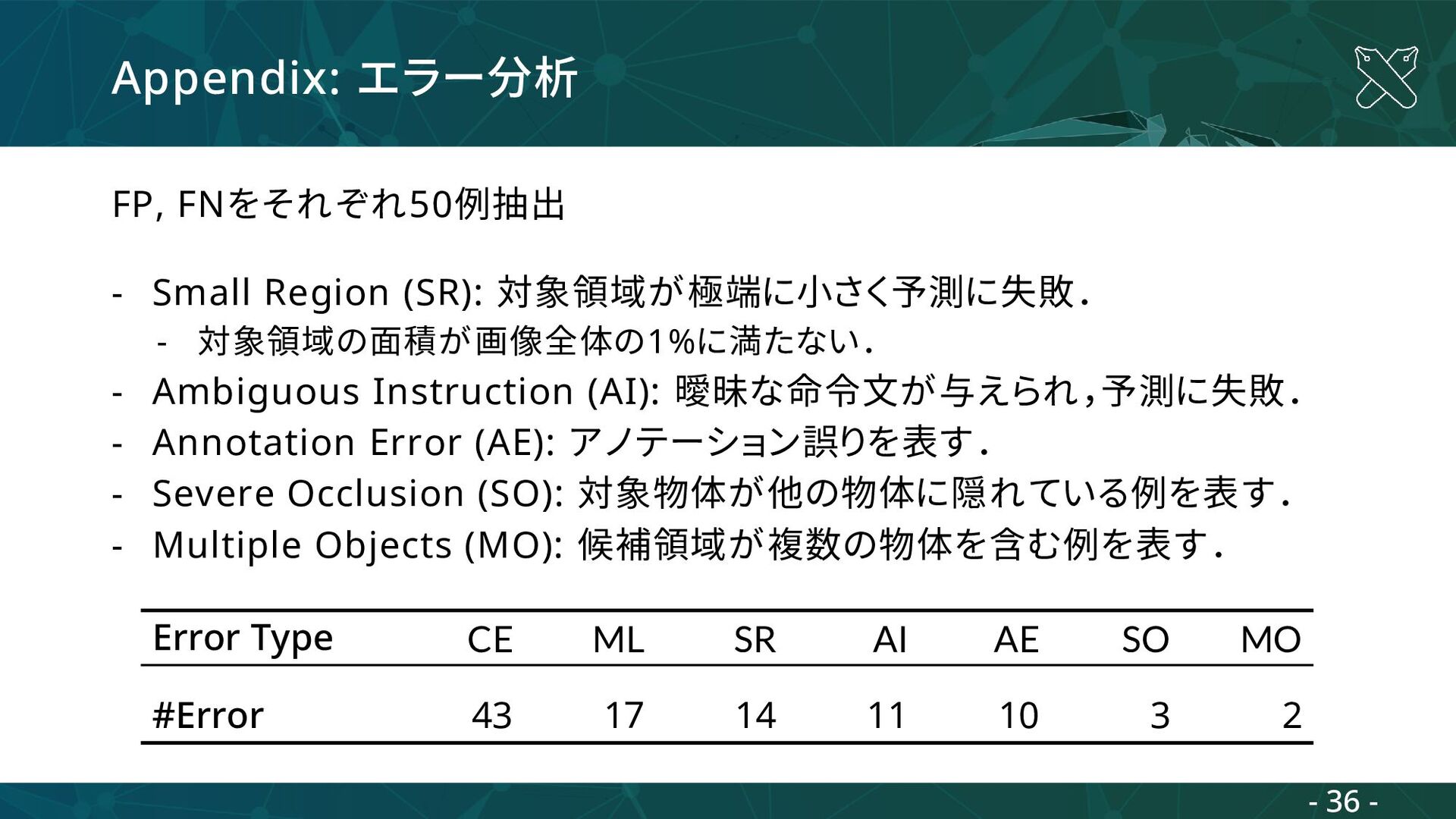
参照表現理解に失敗した場合 - 言語情報から関連する物体を正しく特定出来なかった場合 - Missing Landmark (ML): 参照表現の視覚情報が欠如. - 例: 命令文が”nearest the kitchen”という参照表現を含むが , ”kitchen”が画像中に含まれておらず,対象物体の特定に失敗. Error Type CE ML SR AI AE SO MO #Error 43 17 14 11 10 3 2 - 35 -
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![既存研究は高コストな実世界データのみを用いて学習 →データの大規模化が大変 PFN-PIC [Hatori+, ICRA18] 4つの箱に分け入れられた約20種類の日用品を 対象に,対象物体および目標位置の特定 MTCM [Magassouba+, RA-L19]](https://files.speakerdeck.com/presentations/e7e5039fad1b46b7ac5b5be35cbda10d/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
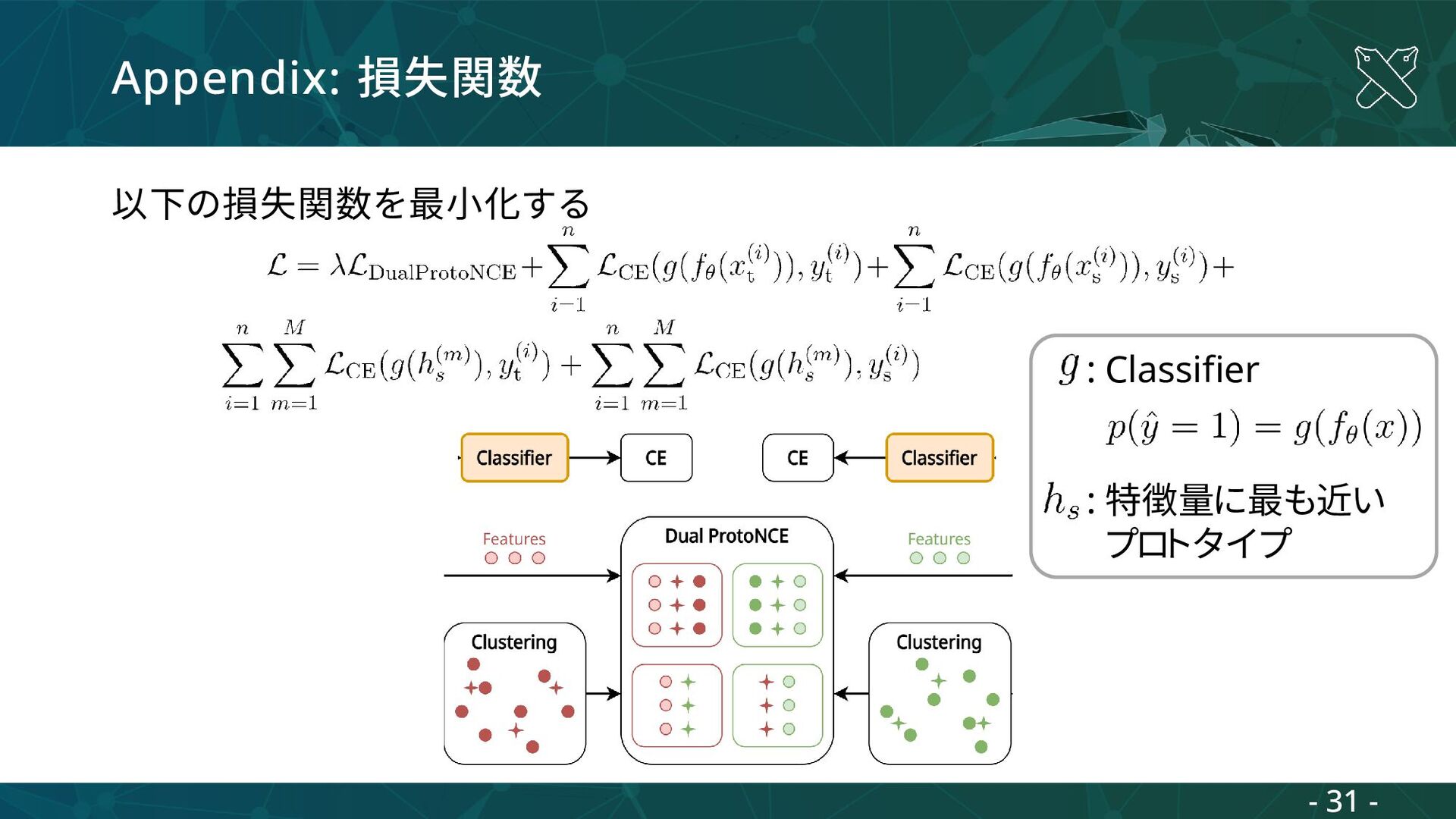
![Appendix: モデル構造 – Encoder Target-Dependent UNITER [Ishikawa+, RA-L21]の構造を採用 Encoderの出力:Multi-Layer Transformerの出力](https://files.speakerdeck.com/presentations/e7e5039fad1b46b7ac5b5be35cbda10d/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}