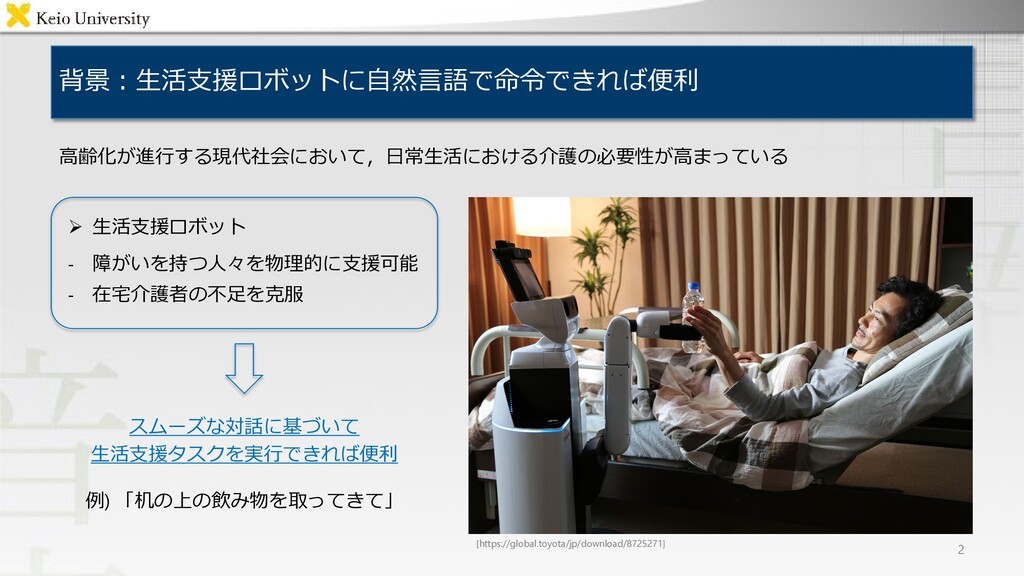
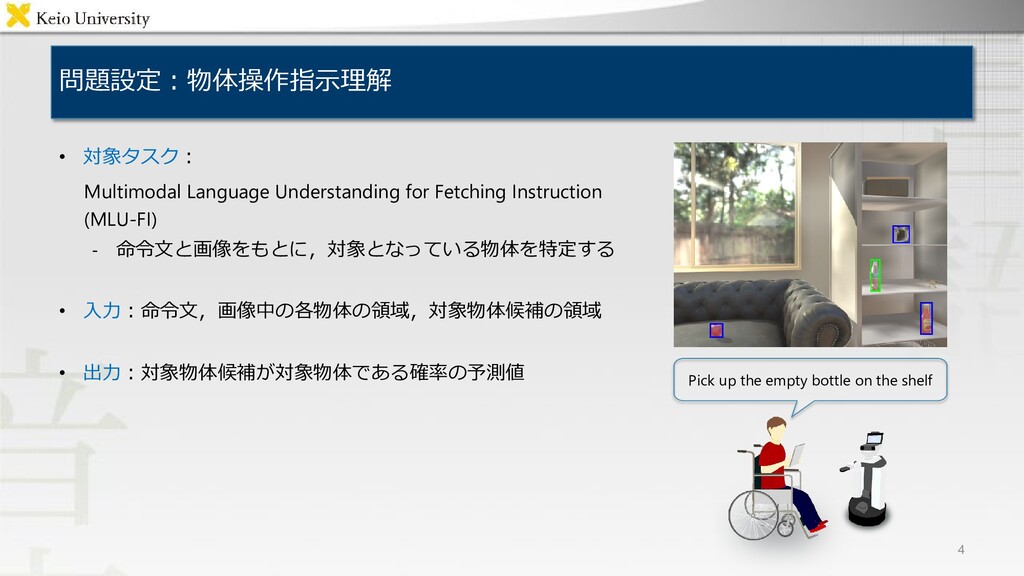
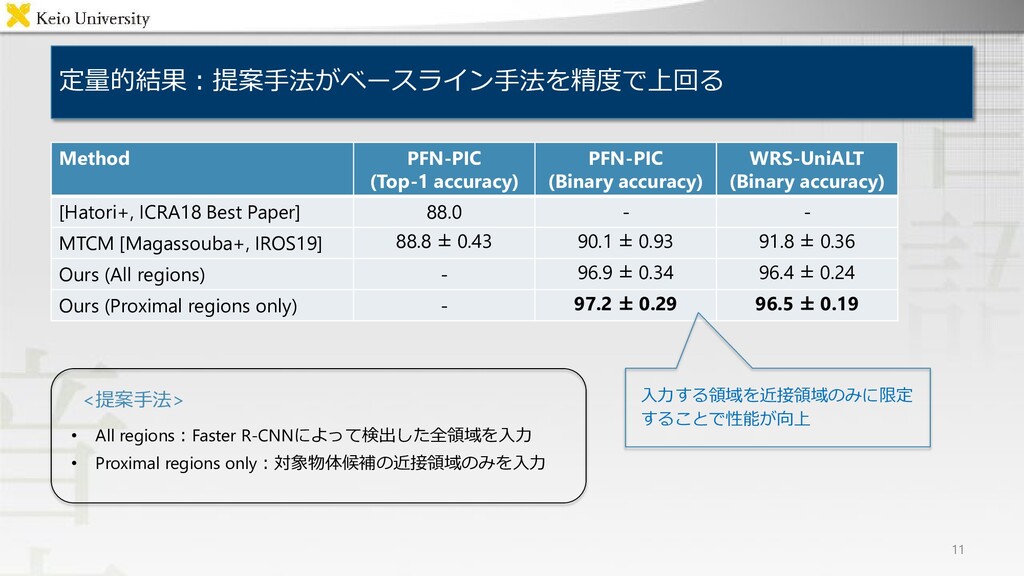
sentence length PFN-PIC [Hatori 18] 1180 90759 4682 14.2 WRS-UniALT 570 1246 167 7.1 “Pick up the white box next to the red bottle and put it in the lower left box” “Pick up the empty bottle on the shelf”
white shelf” 𝑝𝑝 � 𝒚𝒚 = 8.19 × 10−18 “Pick up the black cup in the bottom right section of the box and move it to the bottom left section of the box” 𝑝𝑝 � 𝒚𝒚 = 0.999
on the side from the upper left box, to the lower left box” 𝑝𝑝 � 𝒚𝒚 = 0.978 “Take the white cup on the corner of the table.” 𝑝𝑝 � 𝒚𝒚 = 0.999 候補領域が非常に小さく,細かい特徴量が 失われているため,予測に失敗
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
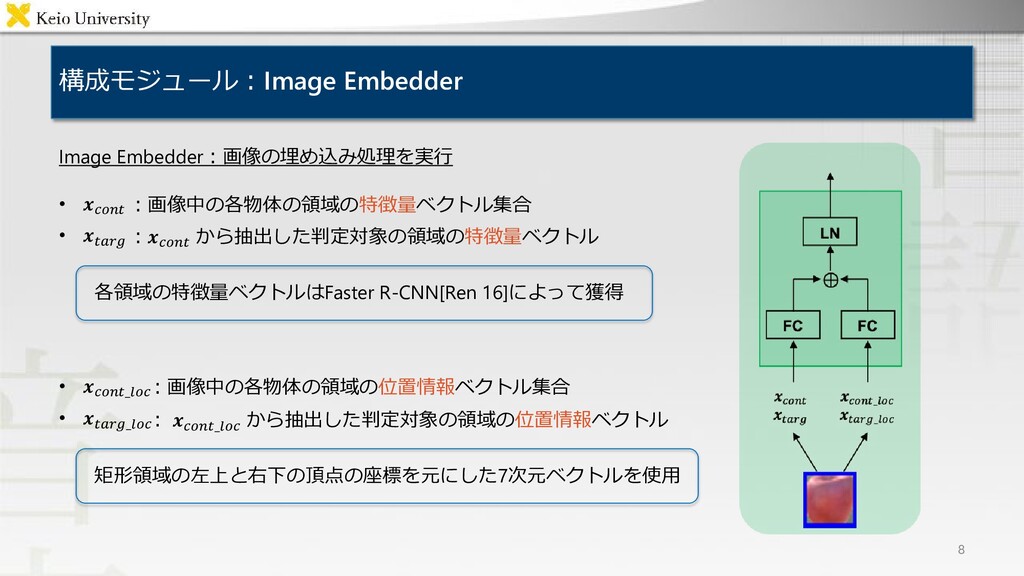
![提案手法:Target-dependent UNITER 6 Target-dependent UNITER:汎用事前学習モデルとUNITER型注意機構 [Chen 20] をMLU-FIタスクに拡張 → 対象物体に関する判定を直接的に行うことが可能](https://files.speakerdeck.com/presentations/e4e76166ad334ffeb402f5b81336b992/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}